Set中出现重复元素
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Set中出现重复元素相关的知识,希望对你有一定的参考价值。
我现在遇到一个问题,我的数据库中存在一个重复的值,我用List取出来后,add到一个Set中(查一个add一个),出现了重复的元素,怎么回事呢?
Set list3 = new HashSet<Menu>();
for (int i = 0; i < list.size(); i++)
user2.setId(list.get(i).getId());
ArrayList<Menu> list2 = userDAO.selectAll(user2);
//循环查询数据的时候,查一条加一条进list3
list3.addAll(list2);
Set也要重写equals和hashCode()方法啊,不晓得呢
我明白是为什么了,因为我加进去的是一个list,Set在识别的时候是看list这一个整体,而不是比较list里面的值
set是根据equals和hashCode来比较元素是不是重复的
java数据结构--集合Set
Set接口
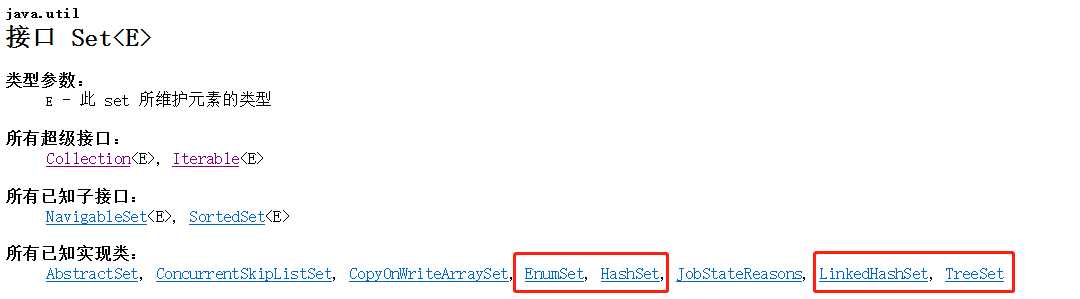
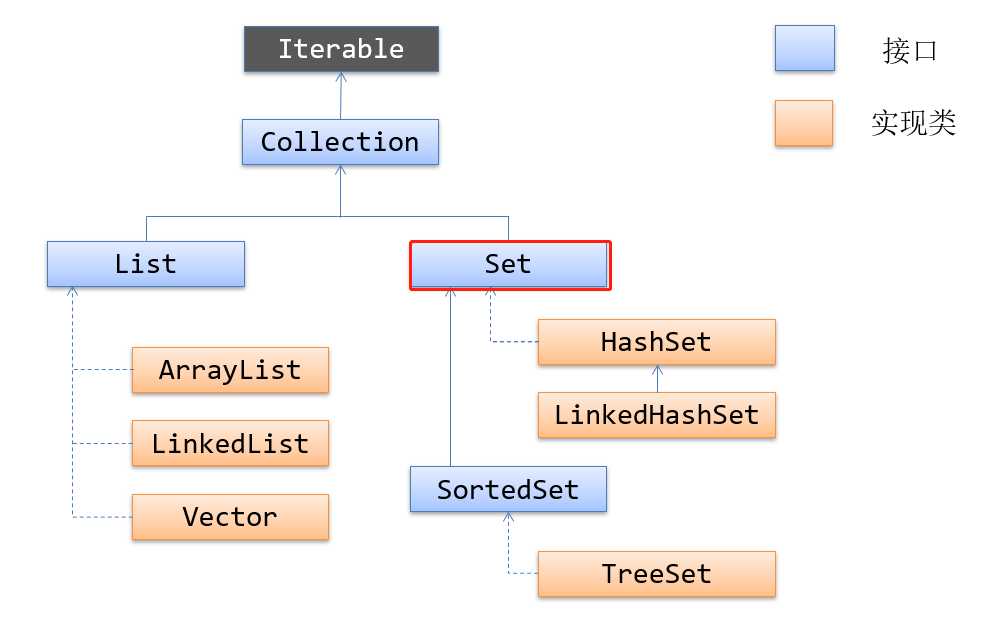
Set接口用来表示:一个不包含“重复元素”的集合
Set接口中并没有定义特殊的方法,其方法多数都和Collection接口相同。
重复元素的理解:
通常理解:拥有相同成员变量的对象称为相同的对象,如果它们出现在同一个集合中的话,称这个集合拥有重复的元素
HashSet中对重复元素的理解:和通常意义上的理解不太一样!
两个元素(对象)的hashCode返回值相同,并且equals返回值为true时(或者地址相同时),才称这两个元素是相同的。
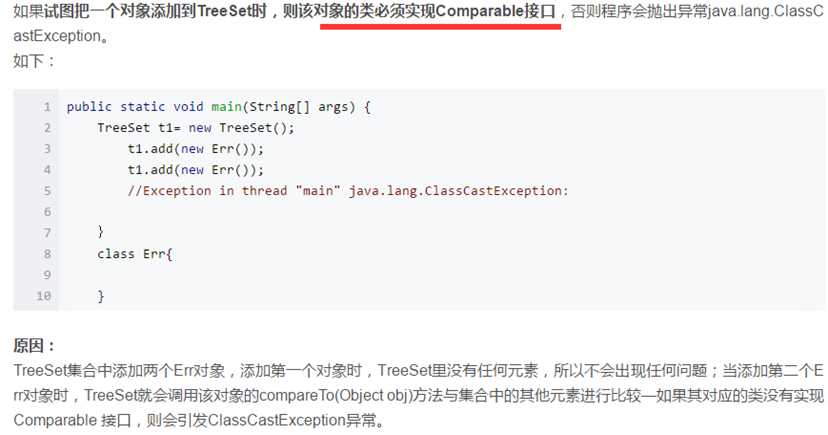
TreeSet中对重复元素的理解:元素的compareTo方法或者集合的比较器compare方法返回值为0则认为这两个元素是相同的元素。
1 Set接口的方法
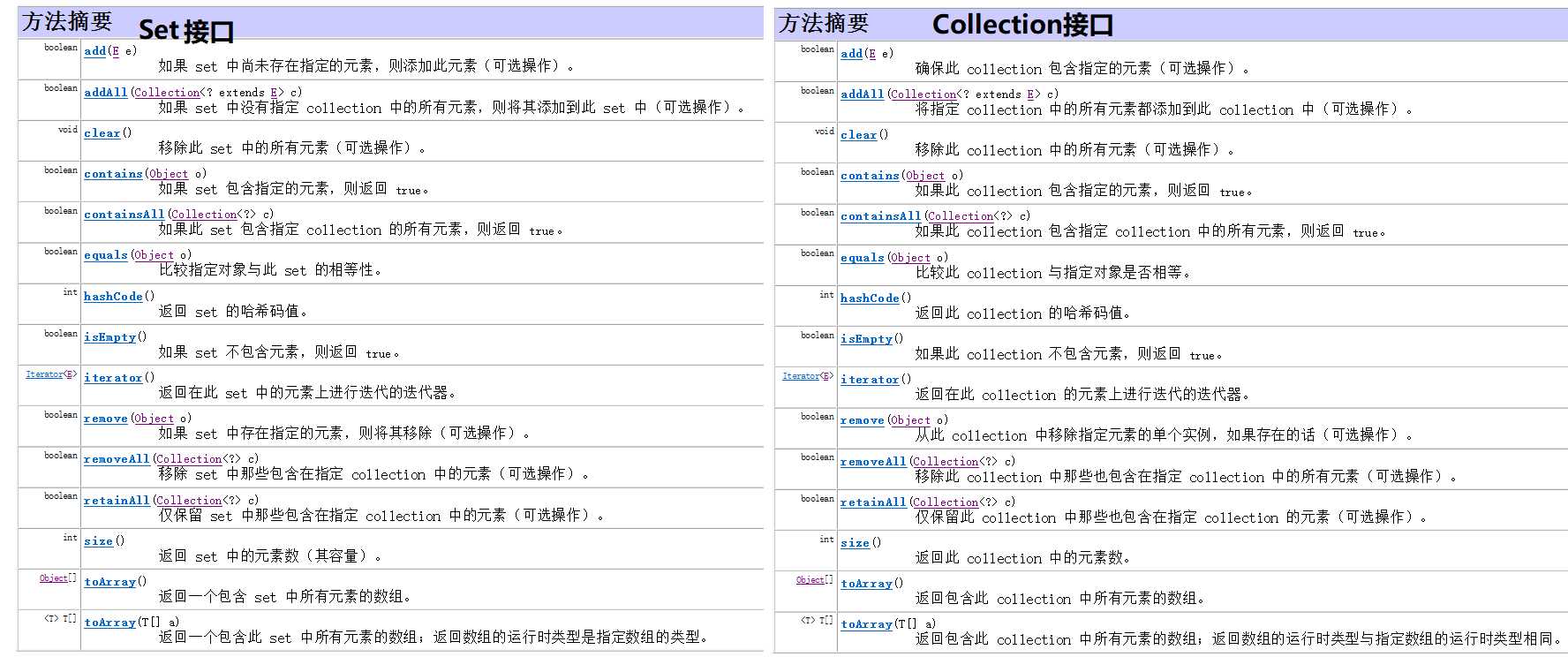
可知Set接口并没有比父类Collection接口提供更多的新方法。
2、HashSet类
线程不安全,存取速度快
它的大多数方法都和Collection相同
它不保证元素的迭代顺序;也不保证该顺序恒久不变
当HashSet中的元素超过一定数量时,会发生元素的顺序重新分配。

2.1HashSet构造方法
public HashSet() map = new HashMap<>(); public HashSet(Collection<? extends E> c) map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16)); addAll(c); public HashSet(int initialCapacity, float loadFactor) map = new HashMap<>(initialCapacity, loadFactor); public HashSet(int initialCapacity) map = new HashMap<>(initialCapacity); HashSet(int initialCapacity, float loadFactor, boolean dummy) map = new LinkedHashMap<>(initialCapacity, loadFactor);
看来set底层是HashMap

2.2成员变量
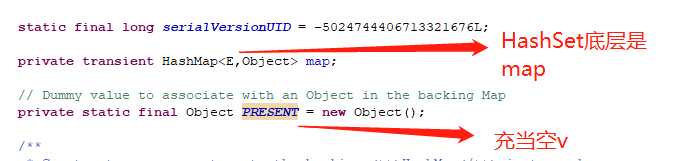
2.3成员方法


2.4HashSet如何保证元素唯一?
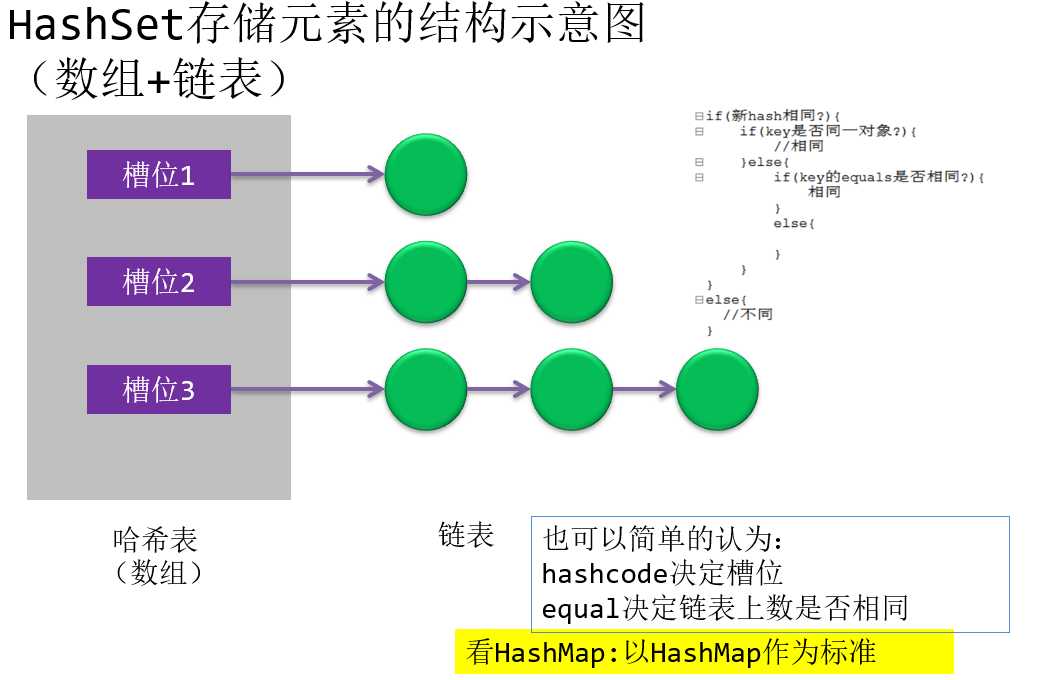
考查add(Object obj)方法的实现过程:
- 先调用obj的hashCode方法,计算哈希值(槽位值slot:bucket)
- 根据哈希值确定存放的位置
- 若位置上没有元素,则这个元素就是第一个元素,直接添加
- 若此位置上已经有元素,说明还有元素的hashCode方法返回值与它相同,则调用它的equals方法与已经存在的元素进行比较
- 若返回值为true,表明两个元素是“相同”的元素,不能添加
- 若返回值为false,表明两个元素是“不同”的元素,新元素将以链表的形式添加到集合中



import java.util.HashSet; /* *自定义对象存储到HashSet中 * *int hashCode:元素被添加时被调用,用于确认元素的槽位值 *boolean equals:当发生碰撞时,调用被添加元素的equals方法和已经存在的元素进行比较, * true:不能添加 * false:可以添加,多个元素占用一个槽位值.以链表形式存在. * */ class Worker // static int i = 0; private String name; private int age; private String id; public String getName() return name; public void setName(String name) this.name = name; public int getAge() return age; public void setAge(int age) this.age = age; public String getId() return id; public void setId(String id) this.id = id; public Worker(String name, int age, String id) super(); this.name = name; this.age = age; this.id = id; public Worker() super(); // TODO Auto-generated constructor stub @Override public int hashCode() final int prime = 31; int result = 1; result = prime * result + age; result = prime * result + ((id == null) ? 0 : id.hashCode()); result = prime * result + ((name == null) ? 0 : name.hashCode()); return result; @Override public boolean equals(Object obj) if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Worker other = (Worker) obj; if (age != other.age) return false; if (id == null) if (other.id != null) return false; else if (!id.equals(other.id)) return false; if (name == null) if (other.name != null) return false; else if (!name.equals(other.name)) return false; return true; @Override public String toString() return "Worker [name=" + name + ", age=" + age + ", id=" + id + "]"; //如何重写hashCode?尽量让所有的成员变量都参与到运算中. //name age id /*@Override public int hashCode() int code1 = name.hashCode(); int code2 = id.hashCode(); return code1 * 3 + age + code2; */ public class HashSetDemo2 public static void main(String[] args) HashSet<Worker> set = new HashSet<>(); Worker w1 = new Worker("tom1", 20, "001"); Worker w2 = new Worker("tom1", 20, "001"); Worker w3 = new Worker("tom2", 22, "003"); Worker w4 = new Worker("tom2", 22, "003"); Worker w5 = new Worker("tom3", 22, "003");// set.add(w1); set.add(w2); set.add(w3); set.add(w4); set.add(w5); for (Worker worker : set) System.out.println(worker);
HashSet注意事项:
1.想要往HashSet中添加的对象,需要在定义类时,重写hashCode和equals方法
2.由于HashSet使用的是散列算法,所以,轻易不要在迭代集合元素的时候改变集合中的元素

2.5并发修改异常
import java.util.HashSet; import java.util.Iterator; /* * 演示HashSet并发修改异常 */ public class HashSetDemo3 public static void main(String[] args) HashSet<String> set = new HashSet<String>(); set.add("hello"); set.add("hello2"); set.add("world"); set.add("world"); Iterator<String> it = set.iterator(); while(it.hasNext()) String str = it.next(); if(str.equals("world")) // set.remove("world");//ConcurrentModificationException it.remove(); for (String s : set) System.out.println(s);
补充技能:
3、LinkedHashSet类
从后缀可以看出:其本质是HashSet,只不过在内部维护了一个链表,可以记住元素放入的顺序,这样就保证了存取的顺序,
但是正是由于多了链表,所以它的效率低些.
- 如何保证元素唯一性:hashCode, equals方法
- 如何保证存取顺序性:链表

没有特殊成员方法全部都是继承而来的。
4、TreeSet类

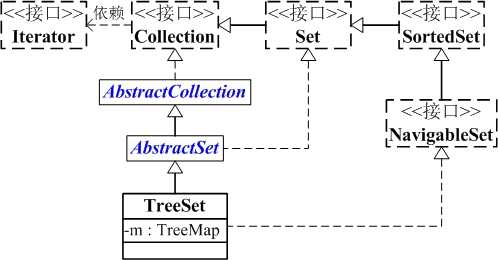

从图中可以看出:
TreeSet继承于AbstractSet,并且实现了NavigableSet接口。
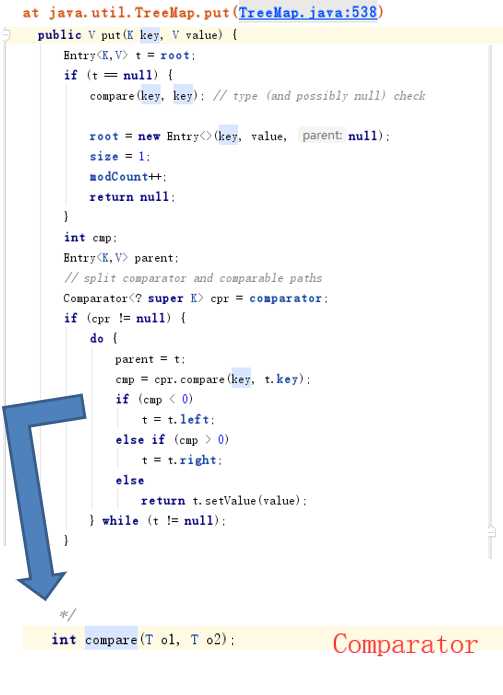
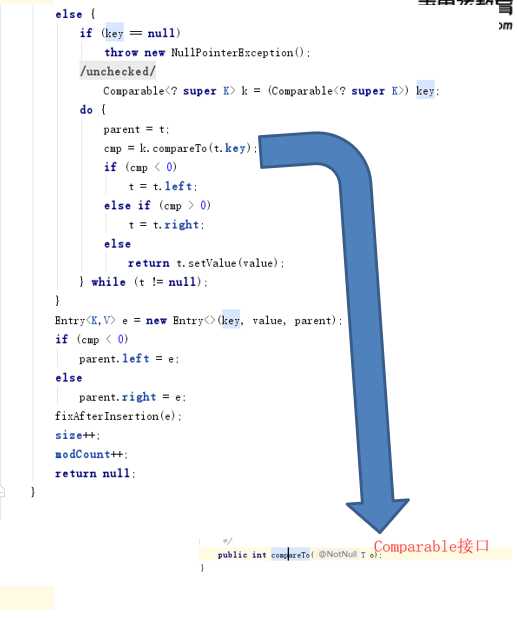
TreeSet的本质是一个"有序的,并且没有重复元素"的集合,它是通过TreeMap实现的(见构造方法)。TreeSet中含有一个"NavigableMap类型的成员变量"m,而m实际上是"TreeMap的实例"。
4.1成员变量

4.2构造方法
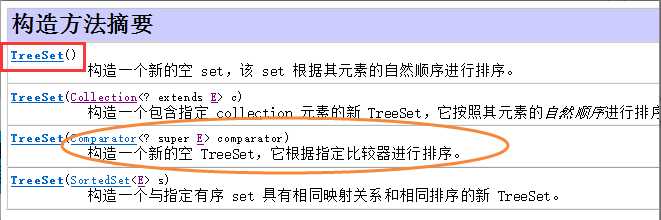
public TreeSet() this(new TreeMap<E,Object>()); public TreeSet(Comparator<? super E> comparator) this(new TreeMap<>(comparator)); public TreeSet(Collection<? extends E> c) this(); addAll(c); public TreeSet(SortedSet<E> s) this(s.comparator()); addAll(s);
4.3TreeSet排序

public static void demoOne() TreeSet<Person> ts = new TreeSet<>(); ts.add(new Person("张三", 11)); ts.add(new Person("李四", 12)); ts.add(new Person("王五", 15)); ts.add(new Person("赵六", 21)); System.out.println(ts);
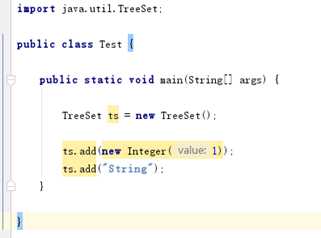


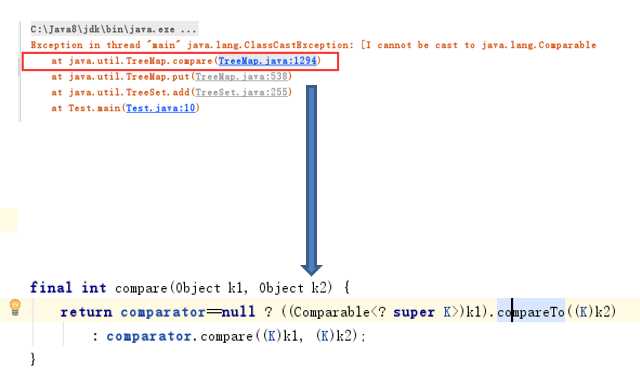

4.3顺序遍历
Iterator顺序遍历
for(Iterator iter = set.iterator(); iter.hasNext(); ) iter.next();
Iterator顺序遍历
// 假设set是TreeSet对象 for(Iterator iter = set.descendingIterator(); iter.hasNext(); ) iter.next();
for-each遍历HashSet
// 假设set是TreeSet对象,并且set中元素是String类型 String[] arr = (String[])set.toArray(new String[0]); for (String str:arr) System.out.printf("for each : %s\\n", str);
TreeSet不支持快速随机遍历,只能通过迭代器进行遍历!
线程不安全,可以对Set集合中的元素进行排序(有序)
如何保证元素(唯一)?排序是如何进行的呢?
树型结构
4、HashMap类
以上是关于Set中出现重复元素的主要内容,如果未能解决你的问题,请参考以下文章