1.0初识机器学习
Posted xuepangzi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了1.0初识机器学习相关的知识,希望对你有一定的参考价值。
1.欢迎参加《机器学习》
当我们使用谷歌或者必应搜索网页的时候,当我们搜索相册中老友的照片的时候,当我们的电子邮箱收到许多邮件,而垃圾邮件被自动的过滤的时候,都有机器学习在起作用。
但最值得我们兴奋的是,我们可以梦想有一天,我们可以通过机器学习制造出像我们一样智能的AI,虽然这个目标距离我们还很远,但是已经有许多人,在通过机器学习,采用学习算法尝试模拟人类大脑的学习方式。
本套课程就是里介绍这些算法。通过本套课程,你将学习到最先进的机器学习算法。但仅知道算法及其数学含义,却不知道如何用来解决用它来解决你所关心的问题是远远不够的。
我们需要花长时间来设计一套算法,让机器学习,然后通过让机器自己编程,来帮我们解决问题。
如今众多领域都在受着机器学习的影响,比如数据挖掘领域(通过收集诸如用户点击等数据,让公司更加了解用户;电子病历;计算生物学,对DNA的分析让我们对人类的奥秘知之更多,还有工程学领域……),无法手动编程的领域(如自动直升机,无人驾驶汽车,手写识别,自然语言的处理,计算机视觉理解图像),同时为百万人根据每个人的喜好私人订制程序,实现真正的人脑级别的智能。
12种最受欢迎的IT技术,机器学习位列第一,就业需求远远大于人才被培养出来的数目。
2.什么是机器学习
试图定义机器学习,并了解在什么情况下使用机器学习。
机器学习的学界对机器学习也尚未有一个统一的定义,在这里介绍一些被广泛认同的定义。
首先,Arthur Samuel 给出的定义为:在没有明确设置的情况下,使计算机拥有学习能力的研究领域。
Samuel成名于1950年,他使用机器学习,让计算机通过算法学习,成为了一个比他棋艺更高的跳棋玩家。他所做的是让计算机自己跟自己下棋几万次,让程序观察哪些布局容易赢,从而成为一个比Samuel更会跳棋的棋手。
Samuel给出的定义显然显得陈旧而狭隘,Tom Mitchell更新了定义,他提出:计算机程序从经验E中学习,解决某一任务T,进行某一性能度量P,通过P测定在T上的表现因经验E而提高。
机器学习的课程,不仅仅要交给你一些工具,更重要的是要教给你怎样使用这些工具。就像吴恩达举的例子:想象别人教你如何成为一个木匠,他说这是一个榔头,这是一个螺丝刀,这是一个锯,祝你好运。这样可不好,对吧?虽然这种教学方法,似乎跟国内大学的教学方法不谋而合,但如果这么课程想要让你真正的学会机器学习,更重要的是教你怎样正确的使用这些工具,知道如何使用机器学习算法的人,与不知道机器学习工具如何使用的人,用很大的不同。
3.监督学习
在定义监督学习之前,最好先举一个例子来解释。
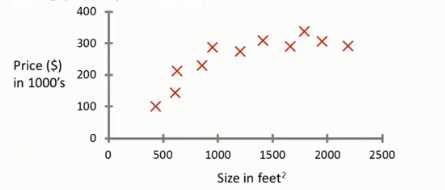
根据相关数据分析,预测房价。横轴代表房屋的面积(平方英尺),纵轴代表房屋每平尺均价。
如果想要预测750平方英尺的房子的均价,可以做一条斜线,将所有数据拟合,然后根据很坐标750,找到对应的纵坐标价格。
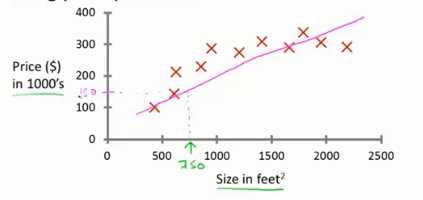
除了用一条直线进行拟合,还可以通过二次函数或者二阶多项式来拟合数据会更好
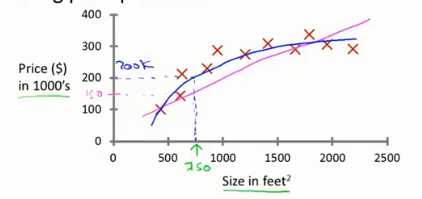
那应该使用一条直线进行拟合数据,还是二次函数曲线进行拟合数据?在这个问题中,不论哪种模型,显然并没有绝对的对错。
这是监督学习算法的一个例子。
监督学习是指:我们给算法一个数据集,其中包含了正确答案,也就是说我们给它一个房价的数据集,在这个数据集中的每个样本,我们都给出正确的价格,这个房子的实际卖价,算法的目的就是给出更多的正确答案,例如,为你朋友想卖掉的这所新房子给出估价,用更专业的术语来定义,它也被称为回归问题,这里的回归问题是指:我们想要预测连续的数值输出,也就是价格,技术上而言,价格能够被等分,因此价格实际上是一个离散值,但通常我们认为房价是一个实数,标量或是连续值,回归这个术语是指:我们设法预测连续值的属性。
另一个例子,根据电子病历肿瘤的尺寸来判断肿瘤是恶性肿瘤还是良性肿瘤。
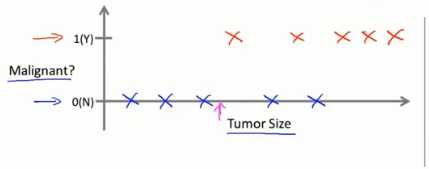
横轴代表肿瘤尺寸,纵轴1代表是恶性肿瘤,0代表良性肿瘤,坐标系中,我们输入了五个恶性肿瘤样本,五个良性肿瘤样本。
假设我们有个朋友不幸患了肿瘤,机器学习就是判断出肿瘤是恶性的概率,用更专业的术语讲,这就是一个分类问题。
分类是指:我们设法预测一个离散值输出,0或1,恶性或良性。
在实际中遇到的问题,有时你也有两个以上可能的输出值,在实际的肿瘤分类中,可能有三种类型的肿瘤癌,因此,你可能要设预测值0,1,2或3.
另一种分类方法,良性用圈代表,恶性用叉代表,横轴代表肿瘤,纵轴代表年龄,我们将恶性区和良心区用一条直线分开,用了两个特征来进行机器学习分类,实际中,还可以加入更多的特征(肿瘤厚度,肿瘤细胞的分布均匀程度等无穷多特征的算法)。
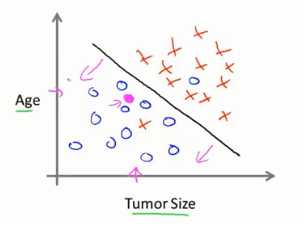
监督学习,我们给算法一个数据值,其中包含了正确答案,算法给出更多的正确答案。其中包含回归问题和分类问题,回归问题是给出连续值,分类问题是给出离散值。
4.无监督学习
聚类算法属于无监督学习的一种,根据簇群,将相关的内容分为一个群。比如经常给你发邮件的人,会被分为一个簇群,认为你们之间是互相认识的,或者基因组中,颜色相近的分为一个簇群。
鸡尾酒会问题:假设在一个小型鸡尾酒宴会上,有两个人同时说话,有两个麦克风,放在距离两个人不同的地方进行声音收集采样,通过算法,我们可以将两个人所说话的声音音频源分离开来。同时如果将其中一个人,换成背景音乐,通过算法,我们依然可以将人说话的声音与背景音乐两段叠加在一起的音频源分离开。
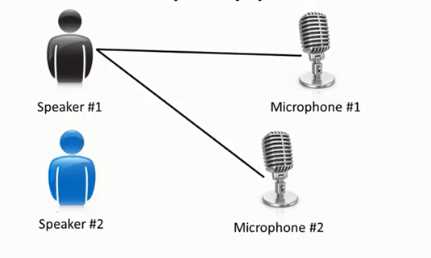
想要达到这个功能,需要敲多少代码呢?只要在特定的编程环境下,只需要一行代码:
[W,s,v]=svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x‘);
当然很多研究人员花费了很长时间才想出了这样一行代码,这并不是一个简单的问题。
实际上,在适合的编程环境下,许多学习算法都可以是很简短的程序。
这也是为什么本套课程,要以Octave的编程环境。Octave是一个免费开源的软件,使用Octave和MATLAB这类的工具,许多的学习算法,都可以通过几行代码来实现,在后续的课程中,将教给大家如何使用Octave,在Octave中实现这些算法。实际上,在硅谷的许多项目机器学习算法,我们都是先用Octave建立软件原型,因为在Octave中实现这些学习算法,速度快得惊人。这里每个函数,如svd函数,即奇异值分解的缩写,其实这个已经作为线性代数的常规函数,内置到Octave当中了,如果你想使用C++或Java做这个,将需要很多的代码,还要链接复杂的C++或Java库。当然,你使用C++,java或者python,一样可以实现这个函数,只不过要更加的复杂罢了。使用Octave作为你的学习工具和原型工具,它将使你更快的学习算法,建立模型。而事实上很多在硅谷大公司工作的人,会先用Octave来建立学习算法原型,只有在这个算法可以工作后,才将其迁移到C++、java或者其他编译环境,事实证明这样做,比你一开始就用C++更快的实现算法。
作为一个开发者,时间是你最宝贵的资源之一,所以使用Octave是必需的。
总结一下,我们谈到了无监督学习,实际上它是一种学习机制,你给算法大量数据,要求它找出数据的类型结构。
例子:
根据被你标记为垃圾邮件的特点,判断新发来的邮件是否是垃圾邮件,属于监督学习。
谷歌根据新闻网页,推送跟相似内容的新闻网页,采用了聚类算法,属于非监督学习。
市场的细分,属于非监督学习。
根据电子病历的样本数据,判断是否患有糖尿病,属于监督学习。
以上是关于1.0初识机器学习的主要内容,如果未能解决你的问题,请参考以下文章