Presto系列 | 三Presto Architecture
Posted 雨钓Moowei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Presto系列 | 三Presto Architecture相关的知识,希望对你有一定的参考价值。
一、Coordinator and Workers in a Cluster
Presto是一个MPP风格的数据库查询引擎,他不依赖于运行Presto服务器的垂直扩展,他可以以水平的方式横向扩展集群,即可以通过增加节点来增大其处理能力。利用这种架构Presto可以跨集群的对大量数据进行处理。Presto的每个节点作为一个单独的服务运行,运行Presto的节点彼此相互协作,构成了Presto集群。
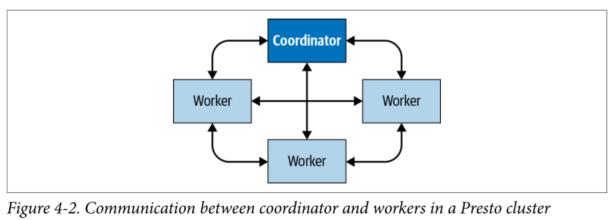
图4-1展示了由一个coordinator和多个Worker组成的集群的简要描述。

Presto通过 客户端连接到coordinator,例如JDBC驱动或者Presto CLI。然后Coordinator与Worker进行协作,Worker负责访问数据源获取数据。
Coordinator是一个Presto服务,主要负责处理收到的查询,并管理Worker处理这些查询。
Worker是Presto中负责执行Task和处理数据的服务。
Discovery service通常运行在coordinator上,允许Worker注册到集群中。
Client ,coordinator以及Worker之间的数据传输和通信都使用基于HTTP/HTTPS的REST接口。
图4-2展示了集群中coordinator和worker之间的通信以及worker和worker之间的通信是如何发生的。coordinator与Worker进行通信以完成固工作的分配,状态的更新,以及获取最终的处理结果返回给用户。Worker之间相互通信主要是为了从运行上游Task的Worker中获取数据。Worker从数据源获取数据。
二、Coordinator
Coordinator负责接收来自用户的查询语句,解析这些语句,安排执行计划,并且管理Worker节点。用于连接客户端,同时也是Presto的大脑。用户可以通过Presto CLI与coordinator进行交互。应用程序可以使用JDBC或者ODBC驱动抑或其他任意语言编写的可用的客户端库。coordinator他接受来自客户端的SQL语句,例如SELECT查询。
每个Presto都必须有一个Coordinator和一个或多个Worker。出于测试和开发的目的一个实例可以充当两种角色。Coordinator会跟踪每个Worker的活动,并安排查询的执行。Coordinator为查询创建一个包含多个Stage的逻辑查询计划。
图4-3展示了client、Coordinator以及Worker之间的通信,一旦接受到SQL查询,Coordinator就会负责parsing,analyzing, planning这个查询,并在Worker节点上进行调度。这个查询会被转化成一系列彼此彼此连接的Task,之后这些Task会在集群的Worker上运行。Worker负责处理数据,处理之后的数据会被Coordinator检索并且通过Output buffer暴露给客户端。一旦客户端成功读取了Output Buffer 中的数据,Coordinator会向Worker获取更多的数据。Worker负责与数据源进行交互以便获取数据。这样,客户端不断的请求数据,Worker不断动数据源获取数据并提供数据,直到查询执行完成。
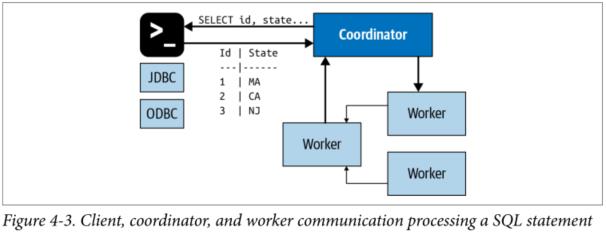
Coordinator与Worker和Clients的交互式基于HTTP协议的。
三、Discovery Service
Presto通过Discovery Service来发现集群中的所有节点。每一个Presto实例在启动的时候都会在Discovery Service中进行注册,并且定时发送心跳信号。因此Coordinator可以拥有一个不断更新的当前可用的Worker列表,以便于为查询安排调度。
如果Worker发送心跳信号失败,Discovery Service出发故障检测,此时该Worker将不会接收之后的Task。
为了简化部署并避免运行额外的服务,Presto Coordinator通常运行一个嵌入版的Discovery Service服务,它使用与Presto相同的HTTP服务,并且使用同一个端口。因此Worker中的discovery service配置通常指向Coordinator的主机名和端口。
四、Workers
Worker是Presto中的一个服务,他负责执行Coordinator分配给他的Tasks并且处理数据,Worker使用Connectors从数据源获取数据,并彼此交换中间数据。最终的结果数据会传送给Coordinator,Coordinator会负责从Worker中收集结构数据,将合并之后的结果数据提供给Client。
在安装期间,需要为Worker配置集群Discovery Server的 HostName和IP地址,当Worker启动的时候,他会通知Discovery Server,这样coordinator才会为期分配执行任务。
Worker与其他Worker以及Coordinator之间的通信是基于HTTP协议的。
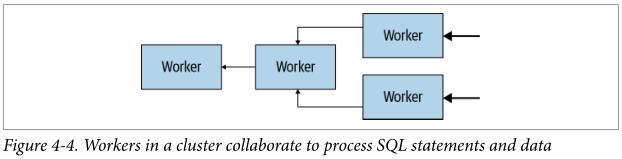
图4-4 展示了多个worker如何从数据源获取数据并且协同处理数据的,直到一个Worker可以向Coordinator提供数据:
五、Connector-Based Architecture
Presto的存储与计算分离的核心在于Connector为基础的架构。connector为Presto提供了一个可以访问任意数据源的接口。
每一个connector在基础数据源之上提供了一个表的抽象。只要数据可以使用Presto可用的类型表示Table,Columns以及Rows那么Connector就了可以被创建并且执行引擎可以使用这些数据进行查询处理。
Presto提供了一个service provider interface(SPI),使用它可以实现一个connector,通过在Connector中实现SPI,Presto可以使用标准的内部操作符连接到任意数据源,以及在任意数据源上执行操作。Connector负责处理对特定数据源的细节信息。
每个connector都会时间API的三个部分:
-
获取 Table/View/Schema 元数据信息的操作
-
生成数据分区对应的逻辑单元的操作,这样Presto 可以并行的读取和写入数据。
-
按照Presto执行引擎需要的方式转换原始数据存入内存,或者从内存中读取数据并转换;
Presto系统已经提供了多个Connector,例如HDFS/Hive ,mysql,PostgreSQL,MSSQL Server ,Kafka,Cassandra,Redis等等。如果目前Presto没有提供你需要的connector那么,你可能需要自己实现一个connector,Presto的SPI允许你创建自己的Connector,这样你便可以使用SQL处理数据,真正实现SQL-On-Anything
图4-5展示了Presto SPI包含的几个coordinator会用到的关于元数据、统计数据、数据存储位置的单独接口,以及worker会用到的数据流接口

Presto connector作为插件会在每个服务启动时被加载,在catalog配置文件中需要单独配置,并且从插件目录中加载。
六、Catalogs, Schemas, and Tables
Presto通过使用基于Connector的架构来处理所有的查询,每个catalog配置使用一个connector来访问一个特定的数据源。这个catalog的数据源会对外暴露一个或多个Schemas,每一个Schema包含一些表,这些表以Row的方式提供数据,每一个Row中包含多个不同数据类型的Columns。
七、Query Execution Model
了解基本组件和概念之后现在我们可以看看实际的SQL查询状态是如何处理的。理解执行模型可以为你提供必要的基础知识,以便于针对特定查询进行优化; 由上面的内容我们知道Coordinator接受来自客户端的SQL语句。然后coordinator触发workers从数据源获取所有数据,创建结果数据集,并使将结果集提供给客户端。
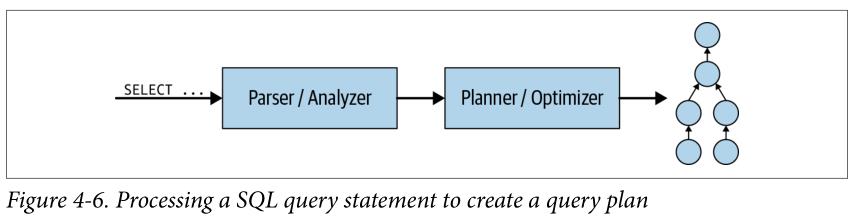
首先,我们看看Coordinator内部发生了什么。 当向SQL以文本的形式被提交到Coordinator之后,Coordinator获取该文本并对其进行解析和分析, 然后,它通过使用Presto中称为 Query Plan 的内部数据结构创建执行计划。如图4-6所示。查询计划大致表示处理数据并返回结果所需的步骤;
如图4-7所示,通常,Query Plan使用MetadataSPI和Data Statistics SPI来创建查询计划, 此外,Coordinator使用Data Location SPI来收集关于数据源的表等元数据信息。
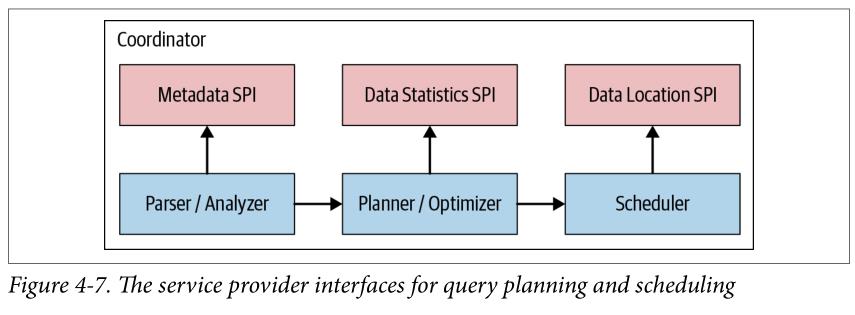
Coordinator使用MetadataSPI获取关于表、列和类型的信息。它们用于验证查询在语义上是否有效,并对原始查询和安全检查中的表达式执行类型检查。
Data Statistics SPI用于获取关于行数和表大小的信息,以便在计划期间执行基于成本(cost-based )的查询优化,
Data Location SPI 是为了用于分布式查询计划的生成。它可以生成关于表内容的逻辑Splits。Splits是工作分配和并行化的最小单位。
换分为不同的SPI,更多的是出于概念上的分离;实际低层Java API以Java包这种更细粒度的方式不同进行划分。
分布式查询计划是由一个或多个Stages组成的,是简单查询计划的一种扩展。简单的查询计划被分成多个计划片段(Plan Fragments)。Stages是Plan Fragments运行时的具体实现,它包含了这个plan fragment所描述的有Tasks、
Coordinator将计划进行打散,以方便在集群中的Worker上并行地处理,加速整体查询速度;当Plan 拥有多个Stages时会导致Stage依赖树的创建。Stages的数量取决于查询的复杂度。例如,查询的Tables,返回的Columns,JOIN,WHERE、GROUP BY和其他SQL语句都会影响创建Stage的数量。
如图4-8 显示如何将逻辑查询计划转换为集群中Coordinator上的分布式查询计划

Task中处理数据的单元被称为 Split ,他是一个描述符,用于描述可以被Worer检索和处理的底层数据的划分,他是并行化和工作分配的最小单元,connector在数据上的特殊操作依赖于底层的数据源。
例如,Hive Connector以文件路径的形式描述Split,其中偏移量和长度表示需要处理文件的哪个部分。
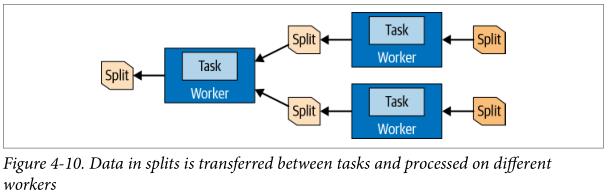
在最开始的Stage中的Task是以Page的形式生产数据的,他是列式存储的行的集合,这些page会流向其他下游Stage中。Page通过Exchange Operator在不同的Stage间转移, Exchange Operator可以从上游Stage 的Task中读取数据。
最底层的Task在coordinator的帮助下使用DataSource SPI 从底层数据源获取数据,这些数据以Page的形式提供给Presto并在Presto执行引擎中流动。不同的Operators根据其语义处理和生成相应的Page。例如 Filter Operators会删除一些Rows,projections Operators产生一些衍生的Columns等等。Task中一些列的Operators被称作 PipeLine ;通常 Pipeline 中最后一个Operators会将他输出的Page放到他所在Task的 Output Buffer中。下游Task中的Exchange operators会消费上游Task Output Buffer中的Page,所有的这些操作是在不同的Worker上并行进行的。如图4-10所示:
因此,Task是分配给Worker的Plan Fragment在运行时的具体实现,当一个Task被创建之后,它将为每一个Split实例化一个 Driver ,每一个Driver是一个pipline的实例,并且执行并处理Split中的数据。一个Task可能会使用一个或多个Driver,这取决于Presto的环境变量的配置,如图4-11所示,一旦一个Drive被创建完成,并且数据被传送到下一个Split之后,这个Driver以及这个Task的任务就完成了,之后他们将会被销毁。

Operator处理输入数据并生成数据供下游的Operator使用。一些常见的Operator例如:Table Scan、Filter,JOIN以及Aggration。Operator Pipeline由一些列的Operator组成。例如,这样一个pipline ,他首先扫描并读取数据,之后对数据进行过滤,最后在数据上执行局部汇总。
为了处理一个查询,coordinator基于从connector中获取的元数据信息创建了一些列的Splits。使用这些Split,Coordinator开始在Worker上调度Task并收集Split中的数据。当查询执行期间,Coordinator会跟踪所有可以执行的Split,以及正在执行的Split位置和正在运行的Task所在的Worker。当Task完成处理并为下游产生跟多的Split时,Coordinator将继续调度Task直到没有可以处理的Split。
一旦Word上的所有的Split都被处理完,所有的数据可用,此时Coordinator就可以将最终结构暴露给客户端。
以上是关于Presto系列 | 三Presto Architecture的主要内容,如果未能解决你的问题,请参考以下文章
Presto系列 | 一Presto SQL On Everything
Presto系列 | 一Presto SQL On Everything