IPv4地址分为哪几个大类?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IPv4地址分为哪几个大类?相关的知识,希望对你有一定的参考价值。
为了便于对IP地址进行管理, 根据IPv4地址的第一个字节,IPv4地址可以分为以下五大类。
A类:0~127。
B类:128~191。
C类:192~223。
D类:224~239,组播地址。
E类:240~254,保留为研究测试使用。
扩展资料:
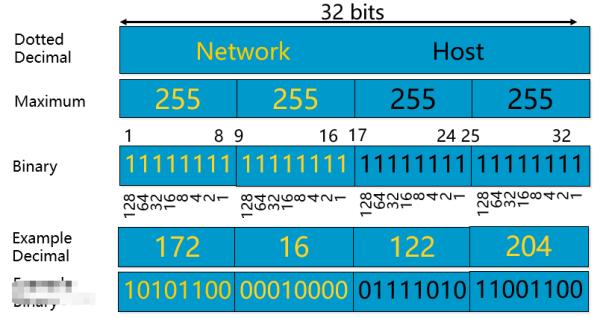
IPv4通常用点分十进制记法书写,例如192.168.0.1,其中的数字都是十进制的数字,中间用实心圆点分隔。
一个IPv4地址可以分为网络地址和主机地址两部分,其中网络地址可以使用如下形式描述:192.168.0.0/16,其中斜线后的数字表示网络地址部分的长度是16位,这对应2个字节,即网络地址部分是192.168.0.0。
参考技术A1、A类IP地址
一个A类IP地址是指, 在IP地址的四段号码中,第一段号码为网络号码,剩下的三段号码为本地计算机的号码。A类IP地址中网络的标识长度为8位,主机标识的长度为24位,A类网络地址数量较少,有126个网络,每个网络可以容纳主机数达1600多万台。
A类IP地址 地址范围1.0.0.1到127.255.255.254。
2、B类IP地址
一个B类IP地址是指,在IP地址的四段号码中,前两段号码为网络号码。B类IP地址中网络的标识长度为16位,主机标识的长度为16位,B类网络地址适用于中等规模的网络,有16384个网络,每个网络所能容纳的计算机数为6万多台。
B类IP地址地址范围128.0.0.1-191.255.255.254。
3、C类IP地址
一个C类IP地址是指,在IP地址的四段号码中,前三段号码为网络号码,剩下的一段号码为本地计算机的号码。C类IP地址中网络的标识长度为24位,主机标识的长度为8位,C类网络地址数量较多,有209万余个网络。适用于小规模的局域网络,每个网络最多只能包含254台计算机。
C类IP地址范围192.0.0.1-223.255.255.254。
4、D类IP地址
D类IP地址在历史上被叫做多播地址,即组播地址。在以太网中,多播地址命名了一组应该在这个网络中应用接收到一个分组的站点。多播地址的最高位必须是“1110”,范围从224.0.0.0到239.255.255.255。
5、E类IP地址
E类IP地址中是以“11110”开头,E类IP地址都保留用于将来和实验使用。
扩展资料
IPv4地址和IP地址的具体区别如下所示:
1、IPv4是一个版本,而IP是一个很大的概念,他们有着本质上的区别。
2、IPv4地址是广电网络的内网IP。
3、IP地址中A类、B类、C类地址的区别,IP地址的长度决定了IPv4的地址空间,决定了地址的有限。
4、IP包含了私网IP、公网IP、IPv4、IPv6。
参考技术BIPv4地址分为A类:1开头、B类:11开头、C类:111开头、D类:1111开头、E类:11111开头。
最初,一个IP地址被分成两部分:网上识别码在地址的高位字节中,主机识别码在剩下的部分中。为了克服这个限制,在随后出现的分类网络中,地址的高位字节被重定义为网络的类(Class),这个系统定义了五个类别:A、B、C、D和E。

扩展资料
IPv4使用32位(4字节)地址,因此地址空间中只有4,294,967,296(2)个地址。不过,一些地址是为特殊用途所保留的,如专用网络和多播地址(约2.7亿个地址),这减少了可在互联网上路由的地址数量。随着地址不断被分配给最终用户,IPv4地址枯竭问题也在随之产生。
基于分类网络、无类别域间路由和网络地址转换的地址结构重构显著地减少了地址枯竭的速度。但在2011年2月3日,在最后5个地址块被分配给5个区域互联网注册管理机构之后,IANA的主要地址池已经用尽。
参考资料来源:百度百科-IPv4
参考技术C A类:1开头B类:11开头
C类:111开头
D类:1111开头
E类:11111开头本回答被提问者采纳 参考技术D A类 0开头
B类 10开头
C类 110开头
D类 1110开头
E类 1111开头
预测模型可分为哪几类?
根据方法本身的性质特点将预测方法分为三类。
1、定性预测方法
根据人们对系统过去和现在的经验、判断和直觉进行预测,其中以人的逻辑判断为主,仅要求提供系统发展的方向、状态、形势等定性结果。该方法适用于缺乏历史统计数据的系统对象。
2、时间序列分析
根据系统对象随时间变化的历史资料,只考虑系统变量随时间的变化规律,对系统未来的表现时间进行定量预测。主要包括移动平均法、指数平滑法、趋势外推法等。该方法适于利用简单统计数据预测研究对象随时间变化的趋势等。
3、因果关系预测
系统变量之间存在某种前因后果关系,找出影响某种结果的几个因素,建立因与果之间的数学模型,根据因素变量的变化预测结果变量的变化,既预测系统发展的方向又确定具体的数值变化规律。
扩展资料:
预测模型是在采用定量预测法进行预测时,最重要的工作是建立预测数学模型。预测模型是指用于预测的,用数学语言或公式所描述的事物间的数量关系。它在一定程度上揭示了事物间的内在规律性,预测时把它作为计算预测值的直接依据。
因此,它对预测准确度有极大的影响。任何一种具体的预测方法都是以其特定的数学模型为特征。预测方法的种类很多,各有相应的预测模型。
趋势外推预测方法是根据事物的历史和现实数据,寻求事物随时间推移而发展变化的规律,从而推测其未来状况的一种常用的预测方法。
趋势外推法的假设条件是:
(1)假设事物发展过程没有跳跃式变化,即事物的发展变化是渐进型的。
(2)假设所研究系统的结构、功能等基本保持不变,即假定根据过去资料建立的趋势外推模型能适合未来,能代表未来趋势变化的情况。
由以上两个假设条件可知,趋势外推预测法是事物发展渐进过程的一种统计预测方法。简言之,就是运用一个数学模型,拟合一条趋势线,然后用这个模型外推预测未来时期事物的发展。
趋势外推预测法主要利用描绘散点图的方法(图形识别)和差分法计算进行模型选择。
主要优点是:可以揭示事物发展的未来,并定量地估价其功能特性。
趋势外推预测法比较适合中、长期新产品预测,要求有至少5年的数据资料。
组合预测法是对同一个问题,采用多种预测方法。组合的主要目的是综合利用各种方法所提供的信息,尽可能地提高预测精度。组合预测有 2 种基本形式,一是等权组合, 即各预测方法的预测值按相同的权数组合成新的预测值;二是不等权组合,即赋予不同预测方法的预测值不同的权数。
这 2 种形式的原理和运用方法完全相同,只是权数的取定有所区别。 根据经验,采用不等权组合的组合预测法结果较为准确。
回归预测方法是根据自变量和因变量之间的相关关系进行预测的。自变量的个数可以一个或多个,根据自变量的个数可分为一元回归预测和多元回归预测。同时根据自变量和因变量的相关关系,分为线性回归预测方法和非线性回归方法。
回归问题的学习等价于函数拟合:选择一条函数曲线使其很好的拟合已知数据且能很好的预测未知数据。
参考资料:百度百科——预测模型
参考资料:百度百科——定性预测
参考技术A1、趋势外推预测方法
趋势外推预测方法是根据事物的历史和现实数据,寻求事物随时间推移而发展变化的规律,从而推测其未来状况的一种常用的预测方法。
趋势外推法的假设条件是:
(1)假设事物发展过程没有跳跃式变化,即事物的发展变化是渐进型的。
(2)假设所研究系统的结构、功能等基本保持不变,即假定根据过去资料建立的趋势外推模型能适合未来,能代表未来趋势变化的情况。
由以上两个假设条件可知,趋势外推预测法是事物发展渐进过程的一种统计预测方法。简言之,就是运用一个数学模型,拟合一条趋势线,然后用这个模型外推预测未来时期事物的发展。
2、回归预测方法
回归预测方法是根据自变量和因变量之间的相关关系进行预测的。自变量的个数可以一个或多个,根据自变量的个数可分为一元回归预测和多元回归预测。同时根据自变量和因变量的相关关系,分为线性回归预测方法和非线性回归方法。回归问题的学习等价于函数拟合:选择一条函数曲线使其很好的拟合已知数据且能很好的预测未知数据。

3、卡尔曼滤波预测模型
卡尔曼滤波是以最小均方误差为估计的最佳准则,来寻求一套递推估计的模型,其基本思想是: 采用信号与噪声的状态空间模型,利用前一时刻地估计值和现时刻的观测值来更新对状态变量的估计,求出现时刻的估计值。
它适合于实时处理和计算机运算。卡尔曼滤波器问题由预计步骤,估计步骤,前进步骤组成。 在预计步骤中, t时状态的估计取决于所有到t-1 时的信息。在估算步骤中, 状态更新后, 估计要于时间t的实际观察比较。更新的状态是较早的推算和新观察的综合。 置于每一个成分的权重由“ Kalmangain”(卡尔曼增益) 决定,它取决于噪声 w 和 v。(噪声越小,新的观察的可信度越高,权重越大,反之亦然)。前进步骤意味着先前的“新”观察在准备下一轮预计和估算时变成了“旧” 观察。 在任何时间可以进行任何长度的预测(通过提前状态转换)。
4、组合预测模型
组合预测法是对同一个问题,采用多种预测方法。组合的主要目的是综合利用各种方法所提供的信息,尽可能地提高预测精度。组合预测有 2 种基本形式,一是等权组合, 即各预测方法的预测值按相同的权数组合成新的预测值;二是不等权组合,即赋予不同预测方法的预测值不同的权数。 这 2 种形式的原理和运用方法完全相同,只是权数的取定有所区别。 根据经验,采用不等权组合的组合预测法结果较为准确。
5、BP神经网络预测模型
BP网络(Back-ProPagation Network)又称反向传播神经网络, 通过样本数据的训练,不断修正网络权值和阈值使误差函数沿负梯度方向下降,逼近期望输出。它是一种应用较为广泛的神经网络模型,多用于函数逼近、模型识别分类、数据压缩和时间序列预测等。点击打开链接(BP神经网络预测实例)
参考资料:百度百科-趋势外推法
百度百科-回归预测法
百度百科-卡尔曼滤波法
百度百科-组合预测法
百度百科-神经网络模型
参考技术B 根据方法本身的性质特点将预测方法分为三类。1、定性预测方法
根据人们对系统过去和现在的经验、判断和直觉进行预测,其中以人的逻辑判断为主,仅要求提供系统发展的方向、状态、形势等定性结果。该方法适用于缺乏历史统计数据的系统对象。
2、时间序列分析
根据系统对象随时间变化的历史资料,只考虑系统变量随时间的变化规律,对系统未来的表现时间进行定量预测。主要包括移动平均法、指数平滑法、趋势外推法等。该方法适于利用简单统计数据预测研究对象随时间变化的趋势等。
3、因果关系预测
系统变量之间存在某种前因后果关系,找出影响某种结果的几个因素,建立因与果之间的数学模型,根据因素变量的变化预测结果变量的变化,既预测系统发展的方向又确定具体的数值变化规律。 参考技术C http://www.sues.edu.cn/jpkc/xt/ja/3.htm
3.1.2预测方法的分类
由于预测的对象、时间、范围、性质等不同,预测方法可以形成不同的分类,但可根据方法本身的性质特点将预测方法分为三类。
1、定性预测方法
根据人们对系统过去和现在的经验、判断和直觉进行预测,其中以人的逻辑判断为主,仅要求提供系统发展的方向、状态、形势等定性结果。
该方法适用于缺乏历史统计数据的系统对象,利用诸如市场调查、专家打分、主观评价等作出预测。
2、时间序列分析
根据系统对象随时间变化的历史资料,只考虑系统变量随时间的变化规律,对系统未来的表现时间进行定量预测。主要包括移动平均法、指数平滑法、趋势外推法等。
该方法适于利用简单统计数据预测研究对象随时间变化的趋势,例如企业的总产值,商品的销售额、城市的用电量、地区的降雨量等。
3、因果关系预测
系统变量之间存在某种前因后果关系,找出影响某种结果的几个因素,建立因与果之间的数学模型,根据因素变量的变化预测结果变量的变化,既预测系统发展的方向又确定具体的数值变化规律。一般因果关系模型中的因变量与自变量在时间上是同步的。
其方法主要包括时间序列分析、线性回归分析、概率统计方法、计量经济学方法、系统动力学仿真、神经网络技术等。
几类预测模型模拟精度的比较
The Comparison with Several Prediction Models in Accuracy of Simulation
<<华北水利水电学院学报 >>2004年03期
罗党 , 吕健
依据创新产品的扩散特性,建立了残差Verhulst模型及优化Verhulst模型,通过实例对Bass模型、残差Verhulst模型及优化Verhulst模型的模拟精度进行比较,发现残差Verhulst模型模拟精度较高.本回答被提问者采纳 参考技术D 预测学是一门研究预测理论,方法,评价及应用的新型科学,是软件学中的重要分支。纵观预测的思维方式,其基本理论主要有惯性原理,类推原理和相关原理。预测的核心问题是预测的技术方法,或者说是预测的数学模型。预测的方法种类繁多,例如灰色预测法,神经网络法等。本文将综合数学模型使用的几种基本的预测模型,并总结各模型的优缺点和适用范围。
(1)自回归AR(P)模型
(2)滑动平均MA(q)模型
以上是关于IPv4地址分为哪几个大类?的主要内容,如果未能解决你的问题,请参考以下文章