巧用MySQL InnoDB引擎锁机制解决死锁问题[2]
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了巧用MySQL InnoDB引擎锁机制解决死锁问题[2]相关的知识,希望对你有一定的参考价值。
参考技术A索引 KEY_TSKTASK_MONTIME (STATUS_ID MON_TIME)
分析 涉及的两条语句应该不会涉及相同的TSK_TASK记录 那为什么会造成死锁呢?
查询mysql官网文档 发现这跟MySQL的索引机制有关 MySQL的InnoDB引擎是行级锁 我原来的理解是直接对记录进行锁定 实际上并不是这样的
要点如下:
不是对记录进行锁定 而是对索引进行锁定
在UPDATE DELETE操作时 MySQL不仅锁定WHERE条件扫描过的所有索引记录 而且会锁定相邻的键值 即所谓的next key locking
如语句UPDATE TSK_TASK SET UPDATE_TIME = NOW() WHERE ID > 会锁定所有主键大于等于 的所有记录 在该语句完成之前 你就不能对主键等于 的记录进行操作
当非簇索引(non cluster index)记录被锁定时 相关的簇索引(cluster index)记录也需要被锁定才能完成相应的操作
再分析一下发生问题的两条SQL语句 就不难找到问题所在了
当 update TSK_TASK set STATUS_ID= UPDATE_TIME=now () where STATUS_ID= and MON_TIME
假设 update TSK_TASK set STATUS_ID= UPDATE_TIME=now () where ID in ( ) 几乎同时执行时 本语句首先锁定簇索引(主键) 由于需要更新STATUS_ID的值 所以还需要锁定KEY_TSKTASK_MONTIME 的某些索引记录
这样第一条语句锁定了KEY_TSKTASK_MONTIME 的记录 等待主键索引 而第二条语句则锁定了主键索引记录 而等待KEY_TSKTASK_MONTIME 的记录 在此情况下 死锁就产生了
笔者通过拆分第一条语句解决死锁问题
先查出符合条件的ID select ID from TSK_TASK where STATUS_ID= and MON_TIME < date_sub(now() INTERVAL minute) 然后再更新状态 update TSK_TASK set STATUS_ID= where ID in (… )
至此 死锁问题彻底解决
lishixinzhi/Article/program/MySQL/201311/29601
MySQL锁(死锁)
死锁的概念
死锁是指两个或者两个以上的事务在执行过程中,因争夺锁资源而造成的一种互相等待的现象。
解决死锁问题最简单的一种方法是超时,即当两个事务互相等待时,当一个等待时间超过设置的某一阀值时,其中一个事务进行回滚,另一个等待的事务就能继续进行。在InnoDB存储引擎中,参数Innodb_lock_wait_timeout用来设置超时的时间
超时机制虽然简单,但是其仅通过超时后对事务进行回滚的方式来处理,或者说其是根据FIFO的顺序选择回滚事务。但若超时的事务所占权重比较大,如事务更新了很多行,占用了较多的undo log ,这时采用FIFO的方式,就显得不合适了,因为回滚这个事务的时间相对于另一个事务所占的时间可能会很多。
因此除了超时机制,当前数据库还都普遍采用wait-for graph(等待图)的方式来进行死锁检测。较之前超时的解决方案,这是一种更为主动的死锁检测方法。InnoDB存储引擎也采用这种方式。
wait-for graph要求数据库保存以下两种信息: 锁的信息链表,事务等待链表
在图中,事务T1指向T2 的定义为:
事务T1 等待事务T2所占用的资源
事务T1 最终等待T2 所占用的资源,也就是事务之间在等待相同的资源,而事务T1发生在事务T2的后面
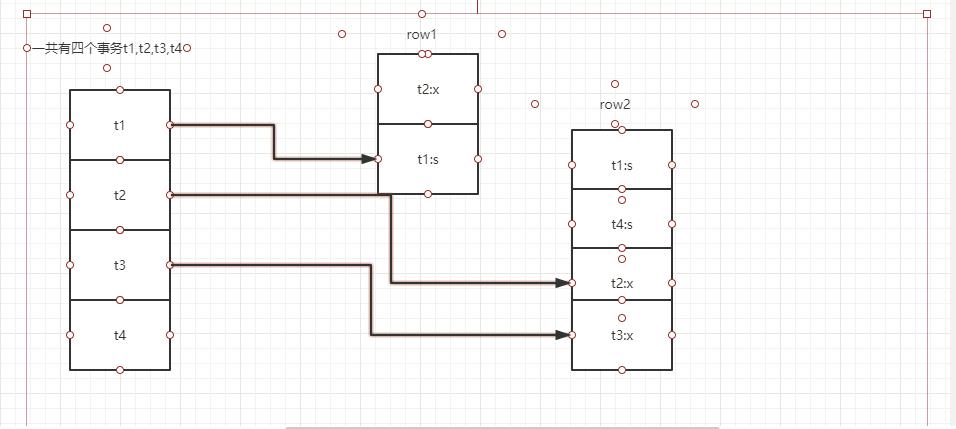

由此,可以发现wait-for graph是一种较为主动的死锁检测机制,在每个事务请求锁并发生等待时都会判断是否存在回路,若存在则有死锁,通常来说InnoDB存储引擎选择回滚undo量最小的事务。
死锁的概率
假设当前数据库中共有 n+1 个线程执行,即当前总共有n+1个事务。并假设每个事务所做的操作相同。
若每个事务由r+1 个操作组成,每个操作作为从R行数据中随机地操作一行数据,并占用对象的锁。
每个事务在执行完最后一个步骤释放所占用的所有锁资源。
最后假设 nr << R,即线程操作的数据只占所有数据的一小部分。
在上述的模型下,事务获取一个锁需要等待的概率是多少?当事务获得一个锁,其他任何一个事务获得锁的情况为:
(1+2+3+....+r)/(r+1) ≈ r/2
由于每个操作为从R行数据中取一条数据, 每行数据被取到的概率为1/R ,因此,事务中每个操作需要等待的概率PW为:
PW = nr/2R
事务是由r个操作所组成,因此事务发生等待的概率PW(T)为:
PW(T) = 1-(1-PW)r ≈ r*PW ≈ nr² / 2R
死锁是由于产生回路,也就是事务互相等待而发生的,若死锁的长度为2 ,即两个等待节点间发生死锁,那么其概率为:
一个事务发生死锁的概率 ≈ PW(T)² /n ≈ nr4 / 4R2
由于大部分死锁发生的长度为2,因此上述公式基本代表了一个事务发生死锁的概率因此,任何一个事务发生死锁的概率为:
系统中任何一个事务发生死锁的概率 ≈ n²r4 / 4R2
从上述的公式中可以发现,由于 nr<< R,因此事务发生死锁的概率是非常低的。同时,事务发生死锁的概率与以下几点因素有关:
系统中事务的数量 (n),数量越多发生死锁的概率越大
每个事务操作的数量(r),每个事务操作的数量越多,发生死锁的概率越大
操作数据的集合(R),越小则发生死锁的概率越大
死锁示例
如果程序是串行的,那么不可能发生死锁。死锁只存在与并发的情况,而数据库本身就是一个并发运行的程序,因此可能发生死锁。
| 时间 | 会话A | 会话B |
| 1 | begin; | |
| 2 |
mysql> select * from test.t where a =1 for update; |
gegin; |
| 3 |
mysql> select * from test.t where a = 2 for update; |
|
| 4 |
mysql> select * from test.t where a =2 for update; |
|
| 5 |
mysql> select * from test.t where a = 1 for update; |
|
| 6 | +---+ | a | +---+ | 2 | +---+ 1 row in set |
会话B事务抛出1213这个错误提示,即表示事务发生了死锁,死锁的原因是会话A和B的资源在互相等待。
会话B中的事务抛出死锁异常后,会话A中马上得到了记录为2 的这个资源,这其实是因为会话B中的事务发生了回滚,否则会话A中的事务是不可能得到资源的。
InnoDB存储引擎并不会回滚大部分的错误异常,但是死锁除外。发现死锁后,InnoDB存储引擎会马上回滚一个事务。因此如果在应用程序中捕获了1213这个错误,其实并不需要对其进行回滚。
此外还存在另一种死锁,即当前事务持有待插入记录的下一个记录的X锁,但是在等待队列中存在一个S锁的请求,则可能发生死锁。
| 时间 | 会话A | 会话B |
| 1 | begin | |
| 2 | begin | |
| 3 | select * from t where a = 4 for update | |
| 4 |
select * from t where a <= 4 lock in share mode; 等待 |
|
| 5 |
insert into t value (3); error 1213 deadlock found when trying to get lock;try restarting transaction |
|
| 6 | 事务获得锁,继续执行 |
可以看到,会话A已经对记录4持有了X锁,但是会话A中插入记录3时会导致死锁的发生。
这个问题的产生是由于会话B中请求记录4的S锁而发生等待,但之前请求的锁对于主键值记录 1、2都已经成功,若在事件点3能插入记录,那么会话B在获得记录4持有的S锁后,还需要向后获取记录3的记录,这样就显得优点不合理。因此InnoDB存储引擎在这里主动选择了死锁,而回滚的是undo log记录大的事务,这与AB-BA死锁的处理又有所不同。
以上是关于巧用MySQL InnoDB引擎锁机制解决死锁问题[2]的主要内容,如果未能解决你的问题,请参考以下文章