Hive中4个By的区别以及如何调优?你知道么?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive中4个By的区别以及如何调优?你知道么?相关的知识,希望对你有一定的参考价值。
参考技术A 1、Sort By:分区内有序2、Order By:全局排序,只有一个Reducer
3、Distrbute By:类似MR中的Partition,进行分区,结合sort by使用
4、Cluster By:当Distrbute By和Sort By字段相同时,可以使用Cluster By方式。Cluster By除了具有Distrbute By的功能还有Sort By的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
窗口函数:
RANK()排序相同时会重复,总数不会变
DENSE_RANK()排序相同时会重复,总数会减少
ROW_NUMBER()根据顺序计算
调优方案:
Fetch抓取
Hive针对某些情况的查询可以不必使用MapReduce计算。例如select * from score;在这种情况下,Hive可以简单地读取source对应的存储目录下的文件,然后输出查询结果到控制台。通过设置hive.fetch.task.conversion参数,可以控制查询语句是否走了MapReduce。
假如hive.fetch.task.conversion设置成none,表示所有执行的查询语句都会走mr程序
假如hive.fetch.task.conversion设置成more,表示所有执行的查询语句都会走mr程序
本地模式
大多数的Hadoop Job是需要Hadoop提供完整的可扩展性来处理大数据集的。不过,有时候Hive的输入数据流是非常小的。在这种情况下,为查询触发执行任务时消耗可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
用户可以设置hive.exec.mode.local.auto的值为true,来让Hive在适当的时候自动启动这个优化。
MapJoin
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器就会在Reduce阶段完成join,容易发生数据倾斜。可以用MapJoinba把小表全部加载到内存在map端进行join,避免reducer处理。
set hive.auto.convert.join = true
大表小表的阈值设置(默认25M以下认为是小表)
set hive.mapjoin.smalltable.filesize = 25123456
Group By
默认情况下,Map阶段同一key数据分发给一个reduce,当一个key数据过大时就倾斜了。并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出结果。
是否在Map端进行聚合,默认为True
set hive.map.aggr = true;
在Map端进行聚合操作的条目数据
set hive.groupby.mapaggr.checkinterval = 100000;
有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true
当选项设定为true,生成的查询计划会有两个MR Job,相当于相同的Group By Key会被分到不同的Reduce中
Count(distinct)
数据量大的时候,由于Count Distinct操作需要一个Reduce Task完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般Count Distinct使用先Group By再Count的方式替换
笛卡尔积
尽量避免笛卡尔积,意思就是避免join的时候不加on条件或者无效的on条件,Hive只能使用1个reducer来完成笛卡尔积。
Hive之GROUP BY详解
一,GROUP BY 执行理解
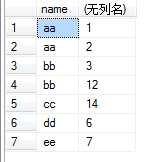
先来看下表1,表名为test:
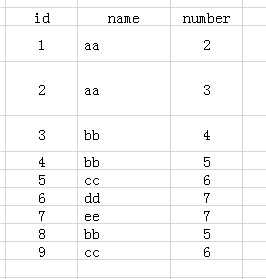
表1
执行如下SQL语句:
SELECT name from test GROUP BY name ;
你应该很容易知道运行的结果,没错,就是下表2:

表2
可是为了能够更好的理解“group by”多个列“和”聚合函数“的应用,我建议在思考的过程中,由表1到表2的过程中,增加一个虚构的中间表:虚拟表3。下面说说如何来思考上面SQL语句执行情况:
1.FROM test:该句执行后,应该结果和表1一样,就是原来的表。
2.FROM test Group BY name:该句执行后,我们想象生成了虚拟表3,如下所图所示,生成过程是这样的:group by name,那么找name那一列,具有相同name值的行,合并成一行,如对于name值为aa的,那么<1 aa 2>与<2 aa 3>两行合并成1行,所有的id值和number值写到一个单元格里面。
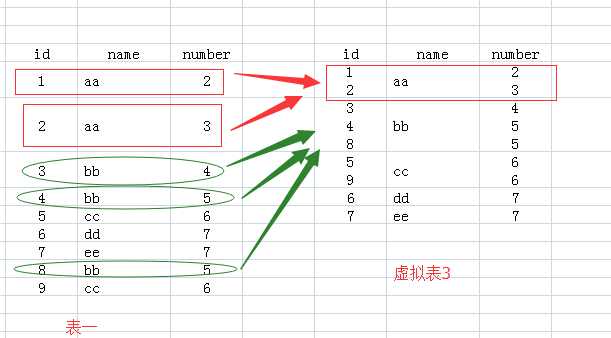
3.接下来就要针对虚拟表3执行Select语句了:
(1)如果执行select *的话,那么返回的结果应该是虚拟表3,可是id和number中有的单元格里面的内容是多个值的,而关系数据库就是基于关系的,单元格中是不允许有多个值的,所以你看,执行select * 语句就报错了。
(2)我们再看name列,每个单元格只有一个数据,所以我们select name的话,就没有问题了。为什么name列每个单元格只有一个值呢,因为我们就是用name列来group by的。
(3)那么对于id和number里面的单元格有多个数据的情况怎么办呢?答案就是用聚合函数,聚合函数就用来输入多个数据,输出一个数据的。如cout(id),sum(number),而每个聚合函数的输入就是每一个多数据的单元格。
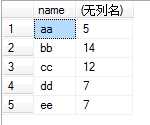
(4)例如我们执行select name,sum(number) from test group by name,那么sum就对虚拟表3的number列的每个单元格进行sum操作,例如对name为aa的那一行的number列执行sum操作,即2+3,返回5,最后执行结果如下:
(5)group by 多个字段该怎么理解呢:如group by name,number,我们可以把name和number 看成一个整体字段,以他们整体来进行分组的。如下图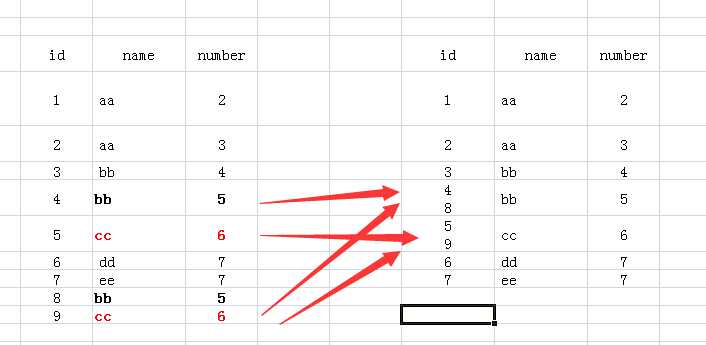
(6)接下来就可以配合select和聚合函数进行操作了。如执行select name,sum(id) from test group by name,number,结果如下图:
二 ,GROUP BY 与 DISTINCT 去重比较
GROUP BY 与 DISTINCT都有去重的功能,具体例子如下:
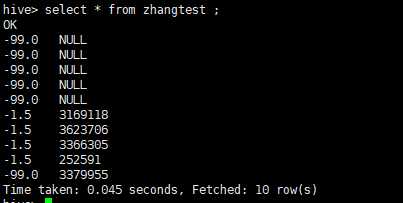
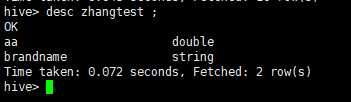
SELECT aa from zhangtest WHERE aa is not NULL GROUP BY aa ;
如果在select 中加入其它字段 ,而在GROUP BY中没有,则会报错,如下。

select col1,col2,count(1),sel_expr(聚合操作) from tableName where condition group by col1,col2 having...
注意:
(1):select后面的非聚合列必须出现在group by中(如上面的col1和col2)。
(2):除了普通列就是一些聚合操作。
group的特性:
(1):使用了reduce操作,受限于reduce数量,通过参数mapred.reduce.tasks设置reduce个数。
(2):输出文件个数与reduce数量相同,文件大小与reduce处理的数量有关。
问题:
(1):网络负载过重。
(2):出现数据倾斜(我们可以通过hive.groupby.skewindata参数来优化数据倾斜的问题)。
下面,看下hive group by distinct区别以及性能比较
有兴趣的可以看下这篇博文,讲解的比较清楚。
https://blog.csdn.net/xiaoshunzi111/article/details/68484426
结论:能用GROUP BY 的 不用 DISTINCT。
参考:https://blog.csdn.net/lzm1340458776/article/details/43231707
部分转自:https://blog.csdn.net/hao1066821456/article/details/69556644
以上是关于Hive中4个By的区别以及如何调优?你知道么?的主要内容,如果未能解决你的问题,请参考以下文章