Scrapy是一个高级的Python爬虫框架,它不仅包含了爬虫的特性,还可以方便的将爬虫数据保存到csv、json等文件中。
首先我们安装Scrapy。
其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
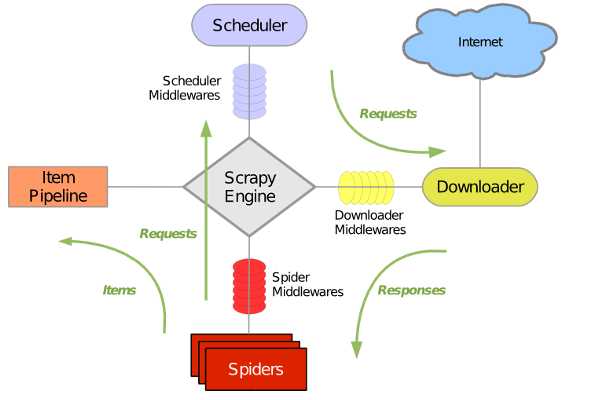
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
安装
linux或者mac
pip3 install scrapy
windows
#下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted #安装wheel模块之后才能安装.whl文件 pip3 install wheel #安装twisted pip install Twisted?18.4.0?cp36?cp36m?win_amd64.whl pip3 install pywin32 #安装scrapy pip3 install scrapy
使用
创建项目
格式:scrapy startproject 项目名
scrapy startproject spider
创建项目之后就会生成一个目录,如下:
项目名称/ - spiders # 爬虫文件 - chouti.py - cnblgos.py .... - items.py # 持久化 - pipelines # 持久化 - middlewares.py # 中间件 - settings.py # 配置文件(爬虫) scrapy.cfg # 配置文件(部署)
创建爬虫
格式:
cd 项目名
scrapy genspider 爬虫名 将要爬的网站
cd spider scrapy genspider chouti chouti.com
创建完爬虫之后会在spiders文件夹里生成一个文件
打开chouti.py之后如下:
运行爬虫
scrapy crawl chouti scrapy crawl chouti --nolog # 不打印日志
示例
# -*- coding: utf-8 -*-
import scrapy
class ChoutiSpider(scrapy.Spider):
‘‘‘
爬去抽屉网的帖子信息
‘‘‘
name = ‘chouti‘
allowed_domains = [‘chouti.com‘]
start_urls = [‘http://chouti.com/‘]
def parse(self, response):
# 获取帖子列表的父级div
content_div = response.xpath(‘//div[@id="content-list"]‘)
# 获取帖子item的列表
items_list = content_div.xpath(‘.//div[@class="item"]‘)
# 打开一个文件句柄,目的是为了将获取的东西写入文件
with open(‘articles.log‘,‘a+‘,encoding=‘utf-8‘) as f:
# 循环item_list
for item in items_list:
# 获取每个item的第一个a标签的文本和url链接
text = item.xpath(‘.//a/text()‘).extract_first()
href = item.xpath(‘.//a/@href‘).extract_first()
# print(href, text.strip())
# print(‘-‘*100)
f.write(href+‘
‘)
f.write(text.strip()+‘
‘)
f.write(‘-‘*100+‘
‘)
# 获取分页的页码,然后让程序循环爬去每个链接
# 页码标签对象列表
page_list = response.xpath(‘//div[@id="dig_lcpage"]‘)
# 循环列表
for page in page_list:
# 获取每个标签下的a标签的url,即每页的链接
page_a_url = page.xpath(‘.//a/@href‘).extract()
# 将域名和url拼接起来
page_url = ‘https://dig.chouti.com‘ + page_a_url
# 重要的一步!!!!
# 导入Request模块,然后实例化一个Request对象,然后yield它
# 就会自动执行Request对象的callback方法,爬去的是url参数中的链接
from scrapy.http import Request
yield Request(url=page_url,callback=self.parse)