Map类型:ClickHouse中对动态字段的支持
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Map类型:ClickHouse中对动态字段的支持相关的知识,希望对你有一定的参考价值。
参考技术A 在交互式分析场景下,很多时候除了固定字段之外,还会有一些动态字段的需求。比如,在游戏场景下,需要动态存储用户每个游戏的play时长。这种场景下,我们希望在一张表中同时存储固定字段和动态字段的信息,并且可以高效地使用动态字段做过滤查询。
CREATE TABLEuser_game_play
(
mid UInt64,
buvidString,
game_play_durationMap(String, UInt32),
log_dateString
)
ENGINE=MergeTree()
PARTITION BY log_date
ORDER BYmid;
insert into user_game_play values (1, '123', map(' 王者荣耀 ',3600, 'FGO', 1800), '2021-11-14');
SELECT game_play_duration[' 王者荣耀 '] AS duration FROM test.user_game_play
┌─duration─┐
│ 3600 │
└──────────┘
ClickHouse从 v21.1.2.15-stable 版本开始支持Map类型(详见PR #1586 ),其读取key对应value的实现逻辑大致如下:
1. 内部用两个数组(ColumnArray)分别存储key和value值,我们分别称之为 key_array和value_array。
2. 对于Map的取值操作(即map[‘key’]操作),先在从key_array中找到要找的key的下标,然后根据这个下标到value_array里获取对应的值。
具体实现细节详见源码 FunctionArrayElement::executeMap .
从上述分析可知,Map类型的工作方式本质上和用两个数组分别存储key和value的方式是一样的。只是在功能上做了封装,提高了用户使用的便捷性,但在性能上并没有变化。
为了提升map操作的性能,我们在社区版本的Map类型基础上,给其加上了多种类型的skipping
index,包括 bloom_filter ,tokenbf_v1,ngrambf_v1
上面这三种skipping index本质上都是用bloom filter存储每个索引粒度的索引值。其中,tokenbf_v1和ngrambf_v1只支持String类型,bloom_filter可支持各种类型。
1. ngrambf_v1是对字符串中固定长度的substring做bloom filter存储和检索。
2. tokenbf_v1是对由非字母数字符号分隔开的token做bloom filter存储和检索。
3. bloom_filter则是直接对字段取值做bloom filter存储和检索。
在数据写入到Map类型字段时,所有的key会被抽取出来生成每个索引粒度对应的bloom filter。
对于针对Map类型字段的过滤条件,如:
where game_play_duration[‘王者荣耀’] >= 1800 and game_play_duration[‘王者荣耀’] <=3600
会做以下处理:
1. 从filtering condition中提取map的key。
2. 分析过滤操作符(如 = , >=, <=, >, <, like , in , not in),如果该过滤条件在map不包含对应key时不可能成立,则利用bloom filter过滤掉不可能包含对应key的数据块(索引粒度)。
具体实现细节详见源码PR #28634 。
CREATE TABLEuser_game_play
(
mid UInt64,
buvidString,
game_play_durationMap(String, UInt32),
log_dateString,
Index idx game_play_duration TYPE bloom_filter GRANULARITY 2,
)
ENGINE=MergeTree()
PARTITION BY log_date
ORDER BY mid;
在我们的性能测试中,给Map类型添加skipping index可以收获的性能提升差异很大。
效果好的case可以十几到几十倍的性能提升,而效果不好的则没有明显提升。
跳数索引的过滤效果和两个数据特性相关:
1. 索引值的cardinality:这个比较好理解,当索引值cardinality很小(比如性别,可取值只有男和女),那么过滤效果通常有限。
2. 索引值的分布是否聚集:ClickHouse的跳数索引和主键索引一样,也是稀疏索引。当索引值分布非常离散时,即使包含查询值的记录占比很小,但可能每个数据块(索引粒度)都包含查询值,那么所有数据都需要读进内存做过滤判断。
ClickHouse社区版本中已经实现了一些map类型相关的函数,包括:
1. map : 基于传入的键值对生成Map类型对象。
2. mapKeys : 获取map对象的所有keys。
3. mapValues : 获取map对象的所有values
4. mapContains : 检查map对象是否包含指定的key。
更多map相关函数细节详见 这里 。
另外,我们添加了两个map函数mapContainsKeyLike和mapExtractKeyLike(已合并进社区版本,详见 这里 ) 。其中mapContainsKeyLike函数支持通过tokenbf_v1索引进行跳数过滤。
客快物流大数据项目(八十九):ClickHouse的数据类型支持

文章目录
十六、IPv4类型与IPv6类型
ClickHouse的数据类型支持
ClickHouse与常用的关系型数据库MySQL或Oracle的数据类型类似,提供了丰富的数据类型支持。
一、整型
ClickHouse支持Int和Uint两种固定长度的整型,Int类型是符号整型,Uint类型是无符号整型。
| 分类 | 数据类型 | 取值范围 |
| 整型 | Int8 | -128 ~ 127 |
| Int16 | -32768 ~ 32767 | |
| Int32 | -2147483648 ~ 2147483647 | |
| Int64 | -9223372036854775808 ~ 223372036854775807 | |
| 无符号整型 | UInt8 | 0 ~ 255 |
| Uint16 | 0 ~ 65535 | |
| Uint32 | 0 ~ 4294967295 | |
| Uint64 | 0 ~ 18446744073709551615 |
二、浮点型
ClickHouse支持Float32和Float64两种浮点类型,浮点型在运算时可能会导致一些问题,例如计算的结果取决于计算机的处理器和操作系统、可能是正无穷或负无穷等问题,官方建议尽量以整数形式存储数据。例如,将固定精度的数字转换为整数值,例如货币数量或页面加载时间用毫秒为单位表示。
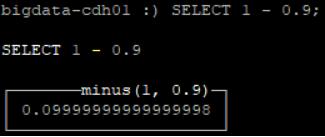
select 1-0.9 的结果是0.09999999999999998
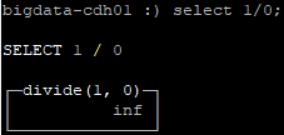
select 1/0的结果是 inf(正无穷)
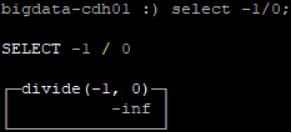
select -1/0的结果是 -inf(负无穷)
select 0/0的结果是 nan(非数字)

三、Decimal
ClickHouse支持Decimal类型的有符号定点数,可在加、减和乘法运算过程中保持精度。对于除法,最低有效数字会被丢弃,但不会四舍五入。数据采用与自身位宽相同的有符号整数存储。这个数在内存中实际范围会高于上述范围,从 String 转换到十进制数的时候会做对应的检查。由于现代CPU不支持128位数字,因此 Decimal128 上的操作由软件模拟。
所以 Decimal128 的运算速度明显慢于 Decimal32/Decimal64。
Decimal(P,S),P参数指的是精度,有效范围:[1:38],决定可以有多少个十进制数字(包括分数);S参数指的是小数长度,有效范围:[0:P],决定数字的小数部分中包含的小数位数。
| 数据类型 | 十进制的范围 |
| Decimal32(S) | Decimal32(S): ( -1 * 10^(9 - S), 1 * 10^(9 - S) ) |
| Decimal64(S) | Decimal64(S): ( -1 * 10^(18 - S), 1 * 10^(18 - S) ) |
| Decimal128(S) | Decimal128(S): ( -1 * 10^(38 - S), 1 * 10^(38 - S) ) |
对Decimal的二进制运算导致更宽的结果类型,两个不同的Decimal类型在运算时精度的变化规则如下:
| 例子 | Decimal64(S1) Decimal32(S2) -> Decimal64(S) Decimal128(S1) Decimal32(S2) -> Decimal128(S) Decimal128(S1) Decimal64(S2) -> Decimal128(S) |
| 小数变化规则 | 加法,减法:S = max(S1, S2) 乘法:S = S1 + S2 除法:S = S1 |
四、布尔型
ClickHouse中没有定义布尔类型,可以使用UInt8类型,取值限制为0或1。
五、字符串类型
ClickHouse中的String类型没有编码的概念。字符串可以是任意的字节集,按它们原本的方式进行存储和输出。若需存储文本,建议使用UTF-8编码。至少,如果你的终端使用UTF-8,这样读写就不需要进行任何的转换。对不同的编码文本ClickHouse会有不同处理字符串的函数。比如,length函数可以计算字符串包含的字节数组的长度,然而lengthUTF8函数是假设字符串以 UTF-8编码,计算的是字符串包含的Unicode字符的长度。
| 数据类型 | 十进制的范围 |
| String | 字符串可以任意长度的。它可以包含任意的字节集,包含空字节。ClickHouse中的String类型可以代替其他DBMS中的VARCHAR、BLOB、CLOB等类型。 |
| FixedString(N) | 固定长度 N 的字符串,N必须是严格的正自然数。当服务端读取长度小于N的字符串时候,通过在字符串末尾添加空字节来达到N字节长度。当服务端读取长度大于N的字符串时候,将返回错误消息。与String相比,极少会使用FixedString,因为使用起来不是很方便。 1)在插入数据时,如果字符串包含的字节数小于N,将对字符串末尾进行空字节填充。如果字符串包含的字节数大于N,将抛Too large value for FixedString(N)异常。 2)在查询数据时,ClickHouse不会删除字符串末尾的空字节。如果使用WHERE子句,则须要手动添加空字节以匹配FixedString的值(例如:where a=’abc\\0’)。 注意,FixedString(N)的长度是个常量。仅由空字符组成的字符串,函数length返回值为N,而函数empty的返回值为1。 |
六、UUID
ClickHouse支持UUID类型(通用唯一标识符),该类型是一个16字节的数字,用于标识记录。ClickHouse内置generateUUIDv4函数来生成UUID值,UUID数据类型仅支持String数据类型也支持的函数(例如,min,max和count)。
七、Date类型
ClickHouse支持Date类型,这个日期类型用两个字节存储,表示从 1970-01-01 (无符号) 到当前的日期值。允许存储从 Unix 纪元开始到编译阶段定义的上限阈值常量(目前上限是2106年,但最终完全支持的年份为2105),最小值输出为0000-00-00。日期类型中不存储时区信息。
八、DateTime类型
ClickHouse支持DataTime类型,这个时间戳类型用四个字节(无符号的)存储Unix时间戳。允许存储与日期类型相同范围内的值,最小值为0000-00-00 00:00:00。时间戳类型值精确到(不包括闰秒)。
使用客户端或服务器时的系统时区,时间戳是从文本转换为二进制并返回。在文本格式中,有关夏令时的信息会丢失。
默认情况下,客户端连接到服务的时候会使用服务端时区。您可以通过启用客户端命令行选项--use_client_time_zone 来设置使用客户端时间。
因此,在处理文本日期时(例如,在保存文本转储时),请记住在夏令时更改期间可能存在歧义,如果时区发生更改,则可能存在匹配数据的问题。
九、枚举类型
ClickHouse支持Enum8和Enum16两种枚举类型。Enum保存的是'string'=integer的对应关系。在 ClickHouse中,尽管用户使用的是字符串常量,但所有含有Enum 数据类型的操作都是按照包含整数的值来执行,这在性能方面比使用String数据类型更有效。
在ORDER BY、GROUP BY、IN、DISTINCT等函数中,Enum 的行为与相应的数字作用相同。例如,按数字排序。对于等式运算符和比较运算符,Enum 的工作机制与它们在底层数值上的工作机制相同。
Enum中的字符串和数值都不允许为NULL,当声明表字段时使用Nullable类型包含Enum类型时,在插入数据时允许NULL值。Enum类型提供toString函数来返回字符串值;toT函数可以转换为数值类型,T表示一个数值类型,如果T恰好对应Enum底层的数值类型则这个转换是0成本的。Enum类型可以使用Alter无成本修改对应集合的值,可以使用Alter来添加或删除Enum的成员(出于安全保障,如果改变之前用过的Enum会报异常),也可以用Alter将Enum8转换为Enum16或反之。
| 数据类型 | String=Integer对应关系 | 取值范围 |
| Enum8 | 'String'= Int8 | -128 ~ 127 |
| Enum16 | 'String'= Int16 | -32768 ~ 32767 |
- 创建tbl_test_enum表
create table tbl_test_enum(e1 Enum8('male'=1, 'female'=2),e2 Enum16('hello'=1,'word'=2), e3 Nullable(Enum8('A'=1, 'B'=2)),e4 Nullable(Enum16('a'=1,'b'=2))) engine=TinyLog;
- 插入字符串数据
insert into tbl_test_enum values('male', 'hello', 'A', null),('male', 'word', null, 'a');
insert into tbl_test_enum values(2, 1, 'C', null);
- 查询结果
select * from tbl_test_enum; 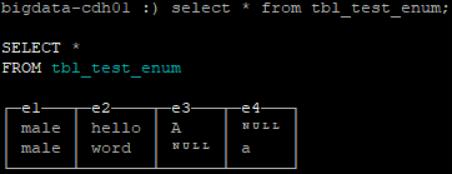
十、数组类型
ClickHouse支持Array(T)类型,T可以是任意类型,包括数组类型,但不推荐使用多维数组,因为对其的支持有限(MergeTree引擎表不支持存储多维数组)。T要求是兼容的数据类型,因为ClickHouse会自动检测并根据元素内容计算出存储这些数据的最小数据类型,如:不能使用array(1,’hello’)。
- 数组声明的两种方式
select array(1,3,5) as arr1,[2,4,6] as arr2, toTypeName(arr1) as arrType1, toTypeName(arr2) as arrType2;
十一、AggregateFunction类型
AggregateFunction(name,type_of_arguments)
create table aggMT (whatever Date default '2019-12-18',key String,value String,first AggregateFunction(min, DateTime),last AggregateFunction(max, DateTime),total AggregateFunction(count,UInt64)) ENGINE=AggregatingMergeTree(whatever,(key,value),8192);
insert into aggMT (key,value,first,last,total) select 'test','1.2.3.4',minState(toDateTime(1576654217)),maxState(toDateTime(1576654217)),countState(cast(1 as UInt64));
insert into aggMT (key,value,first,last,total) select 'test','1.2.3.5',minState(toDateTime(1576654261)),maxState(toDateTime(1576654261)),countState(cast(1 as UInt64));
insert into aggMT (key,value,first,last,total) select 'test','1.2.3.6',minState(toDateTime(1576654273)),maxState(toDateTime(1576654273)),countState(cast(1 as UInt64));
select key, value,minMerge(first),maxMerge(last),countMerge(total) from aggMT group by key, value;十二、元组类型
ClickHouse提供Tuple类型支持,Tuple(T1,T2...)中每个元素都可以是单独的类型。除了内存表以外,元组中不可以嵌套元组,但可以用于临时列分组。在查询中,使用IN表达式和带特定参数的lambda函数可以来对临时列进行分组。元组可以是查询的结果。在这种情况下,对于JSON以外的文本格式,括号中的值是逗号分隔的。在JSON格式中,元组作为数组输出(在方括号中)。在动态创建元组时,ClickHouse 会自动为元组的每一个参数赋予最小可表达的类型。如果参数值为NULL则这个元组对应元素类型是Nullable。
- 使用元组的例子1:
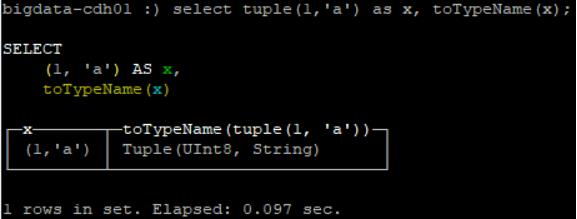
select tuple(1, 'a') as x, toTypeName(x);- 使用元组传入null值时自动推断类型例子2:

select tuple(1, null) as x, toTypeName(x);
十三、Nullable类型
ClickHouse支持Nullable类型,该类型允许用NULL来表示缺失值。Nullable字段不能作为索引列使用,在ClickHouse的表中存储Nullable列时,会对性能产生一定影响。
默认情况下,字段是不允许为NULL的。例如有个Int8类型的字段,在插入数据时有可能为NULL,需要将字段类型声明为Nullable(Int8)。
- 创建测试表tbl_test_nullable
create table tbl_test_nullable(f1 String, f2 Int8, f3 Nullable(Int8)) engine=TinyLog;
- 插入非null值到tbl_test_nullable表(成功)
insert into tbl_test_nullable(f1,f2,f3) values('NoNull',1,1);
- f1字段为null值时插入到tbl_test_nullable表(失败)
insert into tbl_test_nullable(f1,f2,f3) values(null,2,2);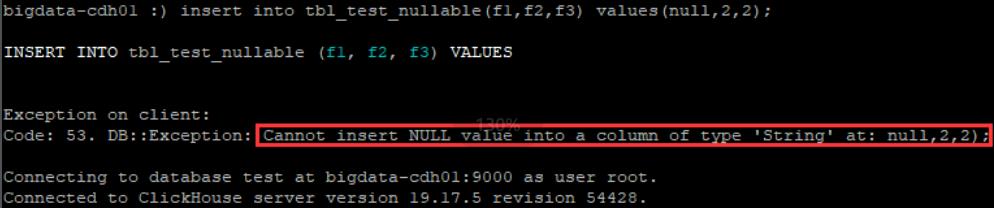
- f2字段为null值时插入到tbl_test_nullable表(失败)
insert into tbl_test_nullable(f1,f2,f3) values('NoNull2',null,2);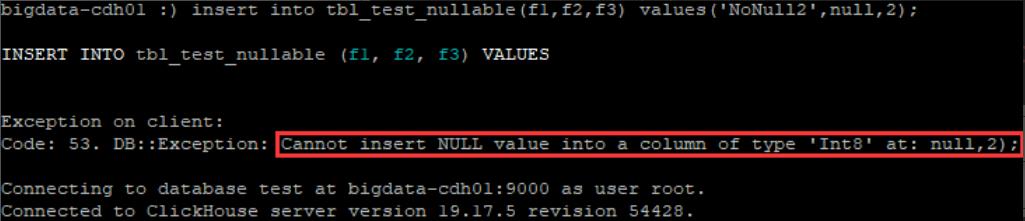
- f3字段为null值时插入到tbl_test_nullable表(成功)
insert into tbl_test_nullable(f1,f2,f3) values('NoNull2',2,null);
- 查询tbl_test_nullable表(有2条记录)
select * from tbl_test_nullable;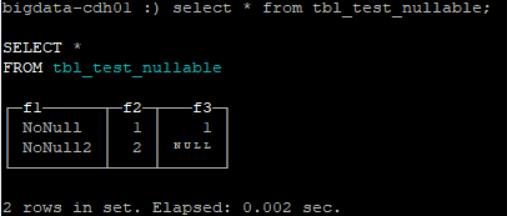
十四、嵌套数据结构
ClickHouse支持嵌套数据结构,可以简单地把嵌套数据结构当做是所有列都是相同长度的多列数组。创建表时,可以包含任意多个嵌套数据结构的列,但嵌套数据结构的列仅支持一级嵌套。嵌套列在insert时,需要把嵌套列的每一个字段以[要插入的值]格式进行数据插入。
- 创建带嵌套结构字段的表
create table tbl_test_nested(uid Int64, ctime date, user Nested(name String, age Int8, phone Int64), Sign Int8) engine=CollapsingMergeTree(ctime,intHash32(uid),(ctime,intHash32(uid)),8192,Sign);
- 插入数据
insert into tbl_test_nested values(1,'2022-12-3',['zhangsan'],[23],[13800138000],1);- 查询uid=1并且user嵌套列的age>=20的数据
select * from tbl_test_nested where uid=1 and arrayFilter(u -> u >= 20, user.age) != [];
- 查询user嵌套列name=zhangsan的数据
select * from tbl_test_nested where hasAny(user.name,['zhangsan']);
- 模糊查询user嵌套列name=zhang的数据
select * from tbl_test_nested where arrayFilter(u -> u like '%zhang%', user.name) != [];
十五、interval
Interval是ClickHouse提供的一种特殊的数据类型,此数据类型用来对Date和Datetime进行运算,不能使用Interval类型声明表中的字段。
Interval支持的时间类型有SECOND、MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER和YEAR。对于不同的时间类型参数,都有一个单独的数据类型,如下表格。
| 时间类型参数 | 查询Interval类型 | Interval类型 |
| SECOND | SELECT toTypeName(INTERVAL 4 SECOND); | IntervalSecond |
| MINUTE | SELECT toTypeName(INTERVAL 4 MINUTE); | IntervalMinute |
| HOUR | SELECT toTypeName(INTERVAL 4 HOUR); | IntervalHour |
| DAY | SELECT toTypeName(INTERVAL 4 DAY); | IntervalDay |
| WEEK | SELECT toTypeName(INTERVAL 4 WEEK); | IntervalWeek |
| MONTH | SELECT toTypeName(INTERVAL 4 MONTH); | IntervalMonth |
| QUARTER | SELECT toTypeName(INTERVAL 4 QUARTER); | IntervalQuarter |
| YEAR | SELECT toTypeName(INTERVAL 4 YEAR); | IntervalYear |
- 获取当前时间+4天的时间
select now() as cur_dt, cur_dt + interval 4 DAY plus_dt;
- 获取当前时间+4天+3小时的时间
select now() as cur_dt, cur_dt + interval 4 DAY + interval 3 HOUR as plus_dt;
十六、IPv4类型与IPv6类型
ClickHouse支持IPv4和Ipv6两种Domain类型,Ipv4类型是与UInt32类型保持二进制兼容的Domain类型,其用于存储IPv4地址的值;
IPv6是与FixedString(16)类型保持二进制兼容的Domain类型,其用于存储IPv6地址的值。
这两种Domain类型提供了更为紧凑的二进制存储的同时支持识别可读性更加友好的输入输出格式。
- 创建tbl_test_domain表
create table tbl_test_domain(url String, ip4 IPv4, ip6 IPv6) ENGINE = MergeTree() ORDER BY url;
- 插入IPv4和IPv6类型字段数据到tbl_test_domain表
insert into tbl_test_domain(url,ip4,ip6) values('https://www.lansonli.com','127.0.0.1','2a02:aa08:e000:3100::2');- 查询tbl_test_domain表数据
select * from tbl_test_domain;
- 查询类型和二进制格式
select url,toTypeName(ip4) as ip4Type, hex(ip4) as ip4Hex,toTypeName(ip6) as ip6Type, hex(ip6) as ip6Hex from tbl_test_domain;
- 使用IPv4NumToString和IPv6NumToString将Domain类型转换为字符串
select url,IPv4NumToString(ip4) as ip4Str,IPv6NumToString(ip6) as ip6Str from tbl_test_domain;
十七、默认值处理
在ClickHouse中,对于某些类型的列,在没有显示插入值时,会自动填充默认值处理。
| 数据类型 | 默认值 |
| Int和Uint | 0 |
| String | 空字符串 |
| Array | 空数组 |
| Date | 0000-00-00 |
| DateTime | 0000-00-00 00:00:00 |
| NULL | 不支持 |
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于Map类型:ClickHouse中对动态字段的支持的主要内容,如果未能解决你的问题,请参考以下文章
使用brokercap / Bifrost将mysql数据 迁移到 clickhouse20.12.3.3