记录一次批量插入的优化历程
Posted jmcui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记录一次批量插入的优化历程相关的知识,希望对你有一定的参考价值。
一、前言
测试妹子反馈了一个bug,说后台报了个服务器异常——保存一个数量比较大的值时,比如 9999,一直在转圈圈,直到最后报了一个服务器异常。我接过了这个bug,经过仔细查看代码后发现,代码卡在了一个批量插入的SQL语句上,就是比如前端保存 9999 的时候,后端的业务逻辑要进行 9999 次的批量插入。
二、方案一
最开始的SQL语句是这样的,传入一个List,由MyBatis 处理这个 List 拼接成一个SQL语句并执行,看着也没有什么大问题呀!


INSERT INTO yy_marketing_coupon ( uuid, no, name, type, money, status, instruction, astrict, total_number, remain_number, send_mode, get_mode, use_mode, user_rank_lower, send_start_time, send_end_time, use_start_time, use_end_time, use_expire_time, discount, user_mobiles, create_time, creater, update_time, updater, appid, use_car_type, highest_money, term_type, coupon_template_uuid, gift_uuid, city_uuids, city_names ) VALUES <foreach collection="list" item="item" index="index" separator=","> ( #{item.uuid}, (select FN_CREATE_COUPON_NO(1)), #{item.name}, #{item.type}, #{item.money}, #{item.status}, #{item.instruction}, #{item.astrict}, #{item.totalNumber}, #{item.remainNumber}, #{item.sendMode}, #{item.getMode}, #{item.useMode}, #{item.userRankLower}, #{item.sendStartTime}, #{item.sendEndTime}, #{item.useStartTime}, #{item.useEndTime}, #{item.useExpireTime}, #{item.discount}, #{item.userMobiles}, #{item.createTime}, #{item.creater}, #{item.updateTime}, #{item.updater}, #{item.appid}, #{item.useCarType}, #{item.highestMoney}, #{item.termType}, #{item.couponTemplateUuid}, #{item.giftUuid}, #{item.cityUuids}, #{item.cityNames} ) </foreach>
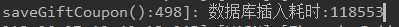
这个仅仅是插入1000条数据的耗时量,快两分钟了,这怎么得了?
三、方案二
经过我们公司的架构师介绍说,要不用 Spring 的 jdbcTemplate 的 batchUpdate() 方法来执行批量插入吧!听过会走二级缓存?
1、applicationContext.xml
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate"> <property name="dataSource" ref="dataSource"/> </bean>
2、数据库连接配置 url 中需要加上允许执行批量插入:rewriteBatchedStatements=true
3、jdbcTemplate 的批量插入代码如下:
String sql = "INSERT INTO " +
" yy_marketing_coupon(uuid,no,name,type,money,status,instruction,astrict,total_number," +
"remain_number,send_mode,get_mode,use_mode,user_rank_lower,send_start_time,send_end_time," +
"use_start_time,use_end_time,use_expire_time,discount,user_mobiles,create_time,creater," +
"update_time,updater,appid,use_car_type,highest_money,term_type,coupon_template_uuid,gift_uuid," +
"city_uuids,city_names) " +
" values (?,(select FN_CREATE_COUPON_NO(1)),?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)";
List<Object[]> batchArgs = new LinkedList<>();
int size = marketingCouponListDo.size();
for (int i = 0; i < size; i++) {
MarketingCouponDto dto = marketingCouponListDo.get(i);
Object[] objects = {
dto.getUuid(),
dto.getName(),
dto.getType(),
dto.getMoney(),
dto.getStatus(),
dto.getInstruction(),
dto.getAstrict(),
dto.getTotalNumber(),
dto.getRemainNumber(),
dto.getSendMode(),
dto.getGetMode(),
dto.getUseMode(),
dto.getUserRankLower(),
dto.getSendStartTime(),
dto.getSendEndTime(),
dto.getUseStartTime(),
dto.getUseEndTime(),
dto.getUseExpireTime(),
dto.getDiscount(),
dto.getUserMobiles(),
dto.getCreateTime(),
dto.getCreater(),
dto.getUpdateTime(),
dto.getUpdater(),
dto.getAppid(),
dto.getUseCarType(),
dto.getHighestMoney(),
dto.getTermType(),
dto.getCouponTemplateUuid(),
dto.getGiftUuid(),
dto.getCityUuids(),
dto.getCityNames()
};
batchArgs.add(objects);
}
jdbcTemplate.batchUpdate(sql, batchArgs);

怎么会这样呢?我几乎是崩溃的,怎么还越来越慢了?!
四、数据库优化
现在我就在考虑了,会不会不是程序问题导致的呢?会不会是数据库性能导致的呢?联想到最近公司刚从云服务上撤了下来,改成自己搭建服务器和数据库。数据库并没有经过什么优化参数设置。所以,我觉得我这个猜想还是有可行性的!
1、> vim /etc/my.cnf
2、数据库参数做了如下优化设置:
#缓存innodb表的索引,数据,插入数据时的缓冲,操作系统内存的70%-80%最佳 innodb_buffer_pool_size = 4096M #配置成cpu的线程数 innodb_thread_concurrency = 24 #查询缓存大小,必须设置成1024的整数倍 query_cache_size = 128M #为一次插入多条新记录的INSERT命令分配的缓存区长度(默认设置是8M)。 bulk_insert_buffer_size = 256M #上传的数据包大小(默认是4M) max_allowed_packet=16M #join语句使用的缓存大小,适当增大到1M左右,内存充足的话可以增加到2MB join_buffer_size = 2M #数据进行排序的时候用到的缓存,一般设置成2-4M sort_buffer_size = 4M #随机读缓存区大小,最大2G read_rnd_buffer_size = 32M
3、重启数据库 > service mysqld restart
好,再来试一下,结果发现并没有什么卵用,插入数据库还是一样的龟速!那么,到底问题出在哪里呢?!
五、方案三
架构师又介绍了我一种 Spring+Mybatis 的 sqlSessionTemplate 来批量插入数据,闻言效率更高!
1、applicationContext.xml
<bean id="sqlSessionTemplate" class="org.mybatis.spring.SqlSessionTemplate"> <constructor-arg index="0" ref="sqlSessionFactory" /> </bean>
2、依赖注入
@Autowired private SqlSessionTemplate sqlSessionTemplate;
3、sqlSessionTemplate 的批量插入代码如下:
SqlSession session = sqlSessionTemplate.getSqlSessionFactory().openSession(ExecutorType.BATCH, false); MarketingCouponMapper mapper = session.getMapper(MarketingCouponMapper.class); int size = marketingCouponListDo.size(); try { for (int i = 0; i < size; i++) { MarketingCouponDto marketingCouponDto = marketingCouponListDo.get(i); mapper.add(marketingCouponDto); if (i % 1000 == 0 || i == size - 1) { //手动每1000个一个提交,提交后无法回滚 session.commit(); //清理缓存,防止溢出 session.clearCache(); } } }catch (Exception e){ session.rollback(); }finally { session.close(); }
测试后发现速度依然没有什么有效的提升,我要炸了!到底问题出在哪里呢?我想我是不是方向走错了?是不是根本不是程序的效率问题?
六、解决问题
最后,我发现,那条简单的插入语句有个不起眼的地方,(select FN_CREATE_COUPON_NO(1)) — 调用执行过程,我试着把这个调用换成了一个字符串 ‘111111‘ 插入,一下子执行速度就提升上来了,我的天,终于找到这个罪魁祸首了!接着怎么优化呢?仔细看看这个存储过程的逻辑,发现也没做什么大的业务,那何不把它提出来写在程序中呢?存储过程的业务代码我就不贴了。

这才是1000条插入应该有的速度嘛!棒棒哒~
七、结语
走了这么多弯路,才醒悟,最被忽略的才是最重要的!
该文旨在介绍多种处理批量插入的方式,解决问题的思路不一定适用,毕竟最后发现完全走错了路...
以上是关于记录一次批量插入的优化历程的主要内容,如果未能解决你的问题,请参考以下文章