遗传算法 (Genetic Algorithm)
Posted Joe-Han
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了遗传算法 (Genetic Algorithm)相关的知识,希望对你有一定的参考价值。
1. 求最值问题常用方法
- 爬山法:从搜索空间中随机产生邻近的点,从中选择对应解最优的个体,替换原来的个体,不断 重复上述过程。因为只对“邻近”的点作比较,所以目光比较“短浅”,常常只能收敛到离开初始位置比较近的局部最优解上面。对于存在很多局部最优点的问题,通过一个简单的迭代找出全局最优解的机会非常渺茫。(在爬山法中不能保证该山顶是一个非常 高的山峰。因为一路上它只顾上坡,没有下坡)
模拟退火:这个方法来自金属热加工过程的启发。在金属热加工过程中,当金属的温度超过它的熔点(Melting Point)时,原子就会激烈地随机运动。与所有的其它的物理系统相类似,原子的这种运动趋向于寻找其能量的极小状态。在这个能量的变迁过程中,开始时。温度非常高, 使得原子具有很高的能量。随着温度不断降低,金属逐渐冷却,金属中的原子的能量就越来越小,最后达到所有可能的最低点。利用模拟退火的时候,让算法从较大的跳跃开始,使到它有足够的“能量”逃离可能“路过”的局部最优解而不至于限制在其中,当它停在全局最优解附近的时候,逐渐的减小跳跃量,以便使其“落脚 ”到全局最优解上。
遗传算法:模拟达尔文生物进化论的过程,按照优胜劣汰进行繁衍,过程中会发生基因交叉( Crossover ) ,基因突变 ( Mutation ) ,适应度( Fitness )低的个体会被逐步淘汰,而适应度高的个体会越来越多。那么经过N代的自然选择后,保存下来的个体都是适应度很高的
2. 遗传算法基本思想
遗传算法有3个基本操作:选择,交叉,变异。
- 选择(Select):可理解为优胜劣汰,部分适应能力强的个体被保留,而较弱的则逐渐消失。常用的选择策略是 “比例选择”,也就是个体被选中的概率与其适应度函数值成正比。
- 交叉(Crossover): 即繁衍后代,两个个体的DNA进行交叉融合,从而产生下一代。
- 变异(Mutation):在繁殖过程中,下一代染色体的基因会有一定概率产生变异。变异发生的概率记为P。
例如,使用遗传算法解决“0-1背包问题”的思路:0-1背包的解可以编码为一串0-1字符串(0:不取,1:取) ;首先,随机产生M个0-1字符串,然后评价这些0-1字符串作为0-1背包问题的解的优劣;然后,随机选择一些字符串通过交叉、突变等操作产生下一代的M个字符串,而且较优的解被选中的概率要比较高。这样经过G代的进化后就可能会产生出0-1背包问题的一个“近似最优解”。
3. 0-1背包问题
- 给定:n种物品和一个背包 ,物品 i 的重量是 wi,其价值为 vi,背包的容量为:Capacity
- 约束条件: 对于每种物品,旅行者只有两种选择(放入或舍弃),每种物品只能放入背包一次
- 目标:如何选择物品,使背包中物品的总价值最大?
使用遗传算法逼近最优解:
- 定义DNA:0-1序列(序列长度为物品总数),1表示对应物品被选取,0则表示未被选。
- 定义适应度:以背包中物品的总价值作为基础测度,若总重量超过背包的Capacity,则适应度置为0
代码:
# -*- coding: utf-8 -*-
import numpy as np
N_ITEMS = 20 # 物品数量
CROSS_RATE = 0.5 # DNA交叉概率
MUTATE_RATE = 0.01 # 变异概率
POP_SIZE = 400 # 个体数量
N_GENERATIONS = 20 # 迭代轮数
class GA:
def __init__(self, DNA_size, cross_rate, mutate_rate, pop_size, n_generations):
self.DNA_size = DNA_size
self.cross_rate = cross_rate
self.mutate_rate = mutate_rate
self.pop_size = pop_size
self.n_generations = n_generations
# 初始化每个个体的DNA
self.pop = np.random.randint(0, 2, size=(pop_size, DNA_size))
def get_fitness(self, w, v, c):
fitness = np.empty(shape=self.pop_size, dtype=np.float32)
for i, individual in enumerate(self.pop): # 计算每个个体的fitness和weight
weight = w[individual.astype(np.bool)].sum()
value = v[individual.astype(np.bool)].sum()
# 若物品总重量超过capacity,则fitness为0
fitness[i] = 0 if weight > c else value
return np.exp(fitness/self.DNA_size)
def select(self, fitness): # 适应度高的DNA有更大的概率保留
index = np.random.choice(np.arange(self.pop_size), size=self.pop_size, replace=True, p=fitness/fitness.sum())
return self.pop[index]
def mutate(self, dna):
for point in range(self.DNA_size):
if np.random.rand() < self.mutate_rate:
dna[point] = 0 if dna[point] == 0 else 1 # 变异
def crossover(self, pop):
pop_copy = pop.copy()
for i in range(self.pop_size):
if np.random.rand() < self.cross_rate:
i_ = np.random.randint(self.pop_size, size=1) # 选择另一个体
cross_points = np.random.randint(2, size=self.DNA_size).astype(np.bool) # 确定DNA交叉点
pop[i, cross_points] = pop_copy[i_][0][cross_points]
self.mutate(pop[i])
c = 40 # 背包容量
w = np.array([4, 5, 6, 2, 2, 3, 7, 8, 6, 9, 1, 5, 6, 8, 3, 4, 4, 9, 4, 2]) # 物品重量
v = np.array([6, 4, 5, 3, 6, 2, 4, 4, 9, 5, 3, 7, 8, 3, 6, 8, 4, 2, 3, 9]) # 物品价值
ga = GA(N_ITEMS, CROSS_RATE, MUTATE_RATE, POP_SIZE, N_GENERATIONS)
for generation in range(N_GENERATIONS):
fitness = ga.get_fitness(w, v, c)
pop = ga.select(fitness)
ga.crossover(pop)
best_idx = np.argmax(fitness)
print('Gen:', generation, '| best fit: %.2f' % (np.log(fitness[best_idx])*ga.DNA_size), '| items:', ga.pop[best_idx])
ga.pop = pop运行结果:

4. 旅行商问题
旅行商从某城市出发,要经过给定的所有城市,且每个城市只访问一次,如何规划路径,使总路径最短。
使用遗传算法求解:
- 定义DNA:城市从0开始编号,经历的城市顺序按编号排序,每种访问顺序作为一个DNA序列(DNA长度为城市总数),例如,4个城市的DNA序列有:[0,1,2,3,4],[4,2,1,3,0]…
- 定义适应度:以路径长度(distance)作为基础测度,且为了增大不同路径fitness值的差异,将定义适应度为 esize of DNA∗2/distance e s i z e o f D N A ∗ 2 / d i s t a n c e
- 进化与变异:由于DNA序列中的基因值不能重复,因此无法随意进行cross over,这里采取的方法是先确定其中一方遗传到下一代的基因,然后再从另一方中选取余下的基因片段(不与前者重复)按顺序拼接;另外,变异的方式是交换两个基因的位置。
该部分参考Morvan大神的代码:
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
N_CITIES = 20 # 城市数量
CROSS_RATE = 0.1 # DNA交叉概率
MUTATE_RATE = 0.02 # 变异概率
POP_SIZE = 500 # 个体数量
N_GENERATIONS = 500 # 迭代轮数
class GA:
def __init__(self, DNA_size, cross_rate, mutation_rate, pop_size):
self.DNA_size = DNA_size
self.cross_rate = cross_rate
self.mutate_rate = mutation_rate
self.pop_size = pop_size
# 初始化每个个体的DNA
self.pop = np.vstack([np.random.permutation(DNA_size) for _ in range(pop_size)])
def translateDNA(self, DNA, city_position): # 获得每个城市的坐标
line_x = np.empty_like(DNA, dtype=np.float64)
line_y = np.empty_like(DNA, dtype=np.float64)
for i, d in enumerate(DNA):
city_coord = city_position[d]
line_x[i, :] = city_coord[:, 0]
line_y[i, :] = city_coord[:, 1]
return line_x, line_y
def get_fitness(self, line_x, line_y):
total_distance = np.empty(self.pop_size, dtype=np.float64)
for i, (xs, ys) in enumerate(zip(line_x, line_y)):
total_distance[i] = np.sum(np.sqrt(np.square(np.diff(xs)) + np.square(np.diff(ys))))
fitness = np.exp(self.DNA_size * 2 / total_distance)
return fitness, total_distance
def select(self, fitness): # 适应度高的DNA有更大的概率保留
idx = np.random.choice(np.arange(self.pop_size), size=self.pop_size, replace=True, p=fitness / fitness.sum())
return self.pop[idx]
def crossover(self, parent, pop):
if np.random.rand() < self.cross_rate:
i_ = np.random.randint(0, self.pop_size, size=1) # 选择另一个体
cross_points = np.random.randint(0, 2, self.DNA_size).astype(np.bool) # 确定DNA如何交叉
keep_city = parent[~cross_points]
swap_city = pop[i_, np.isin(pop[i_].ravel(), keep_city, invert=True)]
parent[:] = np.concatenate((keep_city, swap_city))
return parent
def mutate(self, child):
for point in range(self.DNA_size):
if np.random.rand() < self.mutate_rate: # 变异:交换两个基因
swap_point = np.random.randint(0, self.DNA_size)
swapA, swapB = child[point], child[swap_point]
child[point], child[swap_point] = swapB, swapA
return child
def evolve(self, fitness):
pop = self.select(fitness)
pop_copy = pop.copy()
for parent in pop: # for every parent
child = self.crossover(parent, pop_copy)
child = self.mutate(child)
parent[:] = child
self.pop = pop
class TravelSalesPerson:
def __init__(self, n_cities):
self.city_position = np.random.rand(n_cities, 2) # 初始化每个城市的坐标
plt.ion()
def plotting(self, lx, ly, total_d):
plt.cla()
plt.scatter(self.city_position[:, 0].T, self.city_position[:, 1].T, s=100, c='k')
plt.plot(lx.T, ly.T, 'r-')
plt.text(-0.05, -0.05, "Total distance=%.2f" % total_d, fontdict='size': 20, 'color': 'red')
plt.xlim((-0.1, 1.1))
plt.ylim((-0.1, 1.1))
plt.pause(0.01)
ga = GA(DNA_size=N_CITIES, cross_rate=CROSS_RATE, mutation_rate=MUTATE_RATE, pop_size=POP_SIZE)
env = TravelSalesPerson(N_CITIES) # 初始化每个城市的坐标
for generation in range(N_GENERATIONS):
lx, ly = ga.translateDNA(ga.pop, env.city_position) # 将DNA中的城市id转换为城市坐标
fitness, total_distance = ga.get_fitness(lx, ly)
ga.evolve(fitness) # 模拟进化过程
best_idx = np.argmax(fitness)
print('Gen:', generation, '| best fit: %.2f' % fitness[best_idx],)
env.plotting(lx[best_idx], ly[best_idx], total_distance[best_idx])
plt.ioff()
plt.show()运行结果:
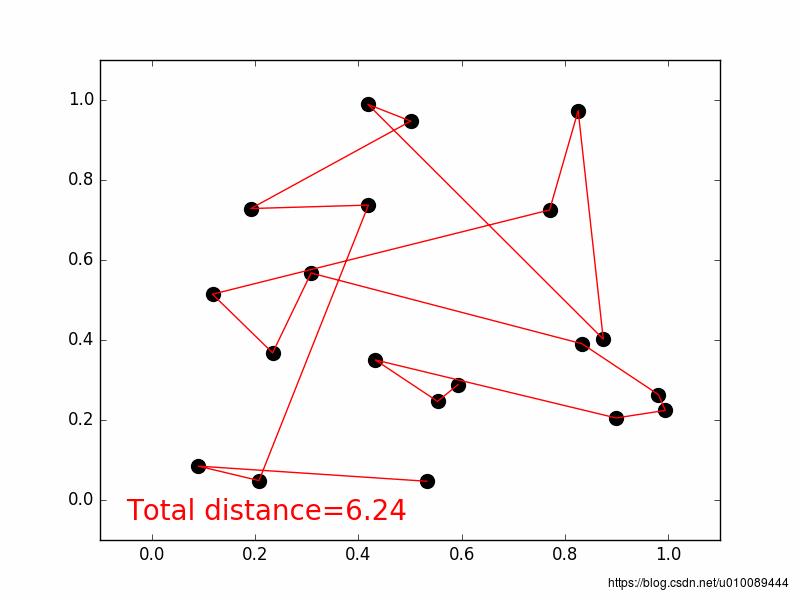
以上是关于遗传算法 (Genetic Algorithm)的主要内容,如果未能解决你的问题,请参考以下文章