ZooKeeper: 简介, 配置及运维指南
Posted neooelric
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ZooKeeper: 简介, 配置及运维指南相关的知识,希望对你有一定的参考价值。
1. 概览
ZooKeeper是一个供其它分布式应用程序使用的软件, 它为其它分布式应用程序提供所谓的协调服务. 所谓的协调服务, 是指ZooKeeper的如下能力
- naming 命名
- configuration management 配置管理
- synchronization 同步
- group service 分组服务
上面四个功能可能现在不太好说清, 但大致上目前你需要明白ZooKeeper就是为其它分布式应用程序提供一些基础功能的程序就好了. 我们以其中的配置管理为例. 假设你在写一个可横向扩容的集群应用程序, 在你的预想里, 你的应用程序最终将部署到成千上万台机器上去, 那么, 这成千上万台机器上的成千上万个实例如何保持配置文件的一致性呢? 简单: 你的分布式应用程序不要自己处理配置管理的问题, 而是把配置管理交给ZooKeeper去做, 如果某个实例需要取配置文件, 去访问ZooKeeper就好了, ZooKeeper向你保证一致性.
并且用上面说到的四种功能, 还能组合实现出其它高级玩法, 比如:
- implement consensus. 在需要一致性的时候, 由ZooKeeper实现一致性
- group management. 分组管理
- leader election. 集群选爹或组内选爹
- presence protocols. 探测集群中各个实例的死活
下面各个章节将详细叙述相关内容.
需要说明的是, ZooKeeper本身的官方文档虽然质量上乘(Apache产品的一贯风格), 但内容上并不完整, 我的这篇译文也有两个缺陷: 一是可能错译, 由于我本身对ZooKeeper的理解出现了偏差导致的. 二是可能有废话, 我并不是照章一字一句翻译的. 总之请作为参考来阅读, 不要作为标准来阅读.
1.1 简介
1.1.1 一个为分布式应用程序提供服务的 分布式协调服务
ZooKeeper是:
- 开源的
- 为其它分布式应用程序提供服务的
- 它本身也是分布式的
- 向其它创面式应用程序提供
协调功能
ZooKeeper对外提供了一系列的原语(primitives), 其它分布式应用程序利用这些原语, 可以很方便的实现一些高级抽象功能, 比如: 同步, 配置管理维护, 分组, 命名等. ZooKeeper的设计宗旨就有两条:
- 简单易用, 使用时的编码难度低.
- 使用树型逻辑结构组织数据.
ZooKeeper是用Java写的, 其对外的API有Java版本的, 也有C的binding版.
1.1.2 ZooKeeper的设计原则
ZooKeeper是简单易用的
如果将使用ZooKeeper的分布式应用程序看做是千千万万个独立的进程实例, ZooKeeper则是构建了一个共享的, 层级式的名称空间(shared hierarchal namespace)以供这千千万万个进程实例去访问. 这个所谓的层级式的名称空间逻辑上和*nix中的文件系统很像. 名称空间由数据寄存器(data register)构成, 数据寄存器也被称谓节点(node), 类比于文件系统的话, 节点相当于文件系统中的文件, 或目录. 不过与文件系统不同的是: 文件系统是在持久化存储设备上抽象数据存储的一层, 但ZooKeeper是把所有数据都放在内存中的.
ZooKeeper是既快又稳的
数据全扔在内存里, 保证的ZooKeeper很快, 性能很好. ZooKeeper的设计实现中, 除了简单易用, 还把以下三点列进了宗旨里:
- 性能要高. 要快, 所以数据扔内存里.
- 要高可用. 要稳, 所以ZooKeeper本身是分布式的, 并且挂掉一小半实例都不影响服务.
- 严格有序的访问. 保证客户端使用原语可以实现可靠的同步服务.
ZooKeeper本身是分布式的
ZooKeeper本身是分布式的. 我们把ZooKeeper寄生的多台机器集合称为一个ensemble, 这个词不是很好翻译, 干脆不翻译了, 这个单词的意思和集群差不多.
在下图中, 每个Server是一个ZooKeeper实例进程, 每个Client是一个使用ZooKeeper服务的客户端, 这个客户端一般是另外一个分布式程序的一个实例. 一个有效的ZooKeeper服务是由多个Server构成的(实际上并没有限定每个Server独占一台机器). 每个ZooKeeper服务中的Server都必须知道其它所有Server的位置. 每个Server都在内存中保存了一些数据(in-memory image of state), 并且在磁盘上保存着事务日志(transaction logs)与快照(snapshot). 只要整个ZooKeeper服务中的大多数Server正常工作着, 那么整个Server就能正常的向外提供服务.
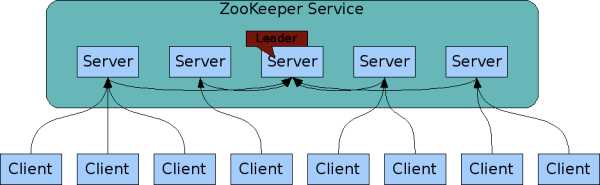
而对于ZooKeeper的使用者, 也就是图中的Client来说, 也就是另外一个分布式应用程序(中的一个实例), 要使用ZooKeeper的服务, 只需要通过TCP连接到ZooKeeper服务中的一个Server上即可, 将这个连接置为长连接, 由Client负责TCP连接的维护, 并通过这个TCP连接向Server发送请求, 接收回应, 发送心跳, 获取监控事件等. 当Server不幸挂掉的时候, Client需要自己来将连接切换到另外一个Server上去.
ZooKeeper是严格有序的
ZooKeeper对每次内部变更都有一个版本戳一样的机制, 这也就是简单的事务机制. 它保证了ZooKeeper整个服务对外提供的原语是原子性的, 并且是严格有序的.
ZooKeeper很快
当读写比例超过10:1的时候, ZooKeeper的性能表现很好. 低于这个比例的话, 可能就不是很适合使用ZooKeeper了.
1.1.3 ZooKeeper中的数据模型与层级式名称空间
ZooKeeper中的层级式名称空间和文件系统很类似, 每个节点都有独一无二的一个路径, 和文件系统一样, 如下图所示:
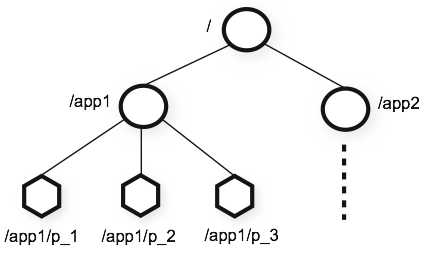
长期节点与短期节点
和文件系统不同, 每个ZooKeeper节点都有自己的数据, 而文件系统中, 目录是不存储数据的. ZooKeeper中的节点也被简称为znode.
znode本身除了数据之外, 还存储着:
- 数据变更的版本号
- ACL变更的版本号
- 时间戳
每次znode中的数据有变更, 版本号都会递增, 并且, Client向znode获取数据时, 实际上不光获取了数据本身, 还获取了数据的版本号.
znode中数据的读写是原子性的, 读, 会读到整个znode中的所有数据, 写, 会替换掉znode中的所有数据. 每个znode还额外有一个ACL(访问控制表. Access Control List)来限定读写的.
普通的znode是持久性的, 这意味着只要ZooKeeper服务健在, 那么这个znode就存在着. 但有一种znode不是这样的: 它随着某个创建znode的会话的开始, 被创建, 而一旦这个会话被撤除掉, 这个znode就会自动被ZooKeeper删除. 这个特性在某些场合特别有用.
监控
ZooKeeper支持一个叫监控(watches)的概念: Client可以对某个znode设置监控, 当这个znode有变更的时候, 就会产生监控事件, 这个事件会由ZooKeeper通知至Client, 即是Client会收到来自Server的通知.
另外如果在监控过程中, Client和Server之间的连接挂掉了, 那么Client会收到一个连接挂掉的通知.
1.1.4 ZooKeeper对使用者的承诺
- Sequential Consistency 顺序一致性. 同一个Client发送的多个请求, 会按请求发送的顺序被应用到Server上
- Atomicity 原子性. 请求要么成功, 要么失败, 没有中间状态
- Single System Image 单系统镜像. 无论Client接的是哪个Server, ZooKeeper保证Client获得的服务是完全相同的.
- Reliability 可靠性. 一旦一个更新操作被ZooKeeper接受且应用实施, 那么直至某个Client再次更新之前, ZooKeeper会保持住这个状态.
- Timeliness 及时性. ZooKeeper保证Client看到的都是及时更新的数据.
1.1.5 ZooKeeper的API
| API名称 | 语义 |
|---|---|
| create | 在名称空间树中的指定位置创建一个节点 |
| delete | 删除一个指定节点 |
| exists | 查询指定节点是否存在 |
| get data | 获取指定节点上的数据 |
| set data | 向指定节点写数据 |
| get children | 获取一个指定节点的所有子节点 |
| sync | 等待数据传播完成 |
1.1.5 ZooKeeper的实现
下图是ZooKeeper的组件图: ZooKeeper是由下面图中的几个组件(component)构成的, 除了图中的request processor(请求接收器)组件之外, ZooKeeper的每个Server都有着其它组件的单独实例.
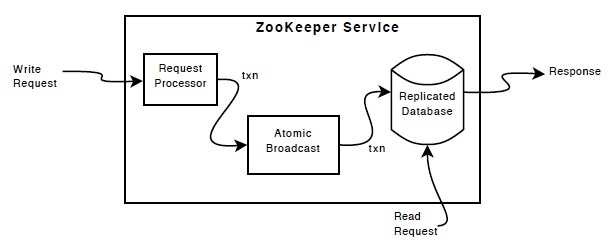
replicated database(数据库), 这里的replicated是指, 这个数据库在每个Server中都有一个独立的实例. 并且每个Server中的数据库都存储着整个名称空间树, 另外注意这个数据库是内存数据库. 每当数据树要更新的时候, 都会向磁盘写入日志(为了故障恢复使用), 并且对数据树的写操作, 是先将数据序列化后写入磁盘, 再写入数据库的.
每个ZooKeeper Server都对外向多个Client提供服务, 而Client只能接一个Server来收发请求回应. 当Client发出读请求的时候, 数据是直接从本地数据库返回的, 而如果Client发送的是一个写请求, 那就有点麻烦了, 这个写请求的处理要经过一个协商协议(agreement protocol)的处理. 这个逻辑很自然, 因为写操作是要维持多个Server之间数据的一致性的.
那么核心问题就是, 这个所谓的agreement protocol是如何保证写操作全局一致的呢? 它有两个策略:
- ZooKeeper中的所有Server, 有一个是爹(leader), 其它都是儿子(follower)
- 爹向儿子传达什么信息, 儿子毫不迟疑的执行.
- ZooKeeper内部有一个选爹机制, 保证在爹出现意外(进程挂死, 机器断网)的情况下, 选出一个新爹
- 儿子接收到写请求时, 先将写请求交给爹. 之后爹再将写请求广播给所有儿子.
ZooKeeper在消息通信上使用了一个自定义的原子消息协议, 消息协议的原子性保证了ZooKeeper中每个Server, 无论是爹还是儿子, 数据库中存储的数据都是实时的. 当爹收到由儿子递交的一个写请求后, 会做如下事情:
- 对比数据库中的当前状态, 预计写操作执行后的预期状态, 把两个状态之间的差额做成一个事务请求
- 将这个事务请求分发给所有儿子
1.1.6 ZooKeeper的用法
ZooKeeper的编程接口十分简单, 这部分内容会在后续章节涉及到. 简单意味着API数量少, 容易被理解, 但也有一点坏处, 就是接口能实现的功能十分基本基础, 要实现高级一点的功能, 你需要自己写逻辑, 当然这也不会十分困难.
1.1.7 ZooKeeper的性能
前面吹了那么多ZooKeeper的好处, 是时候用一些证据来支撑前面吹的逼了. ZooKeeper的实际性能到底有多少? 我相信很多传统的C/C++后台开发人员在看到ZooKeeper是跑在JVM上的Java程序的时候都在内心默默的鄙视了一下ZooKeeper.
但反直觉的是, 根据雅虎的ZooKeeper研发团队报告, ZooKeeper的性能确实十分强劲, 但性能强劲是有前提条件的: 那就是对数据的读取操作量远大于数据写入操作量. 当然作为一个供其它应用程序使用的协调服务, 读量大于写量应该是一个典型现象.
下图是ZooKeeper的性能图表, 其中横轴是指请求量中读操作的占比, 纵轴是每秒能处理的请求量. 颜色不同的线代表ZooKeeper的实例个数(显然每个实例独占一台机器). 可以直观的看到, 在读操作占比超过80%后, ZooKeeper的吞吐量就起飞了. 并且5个实例构成的ensemble在性能的提升上对比3个实例构成的ensemble有显著提升, 但超过5之后, 增加实例个数对ZooKeeper的整体性能提升就不是很明显了. 当然这只是一个参考图表, 应用实施的时候, 各家都有各家的特殊国情, 还需要自行探究.
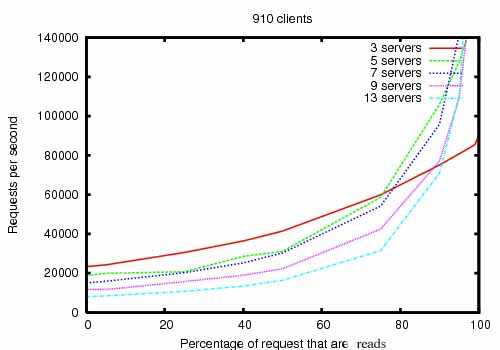
上面这边图的测试现场大致是这样的:
- 用的ZooKeeper版本为3.2
- 每个ZooKeeper实例独占一台机器, 每台机器双核心2GHz Xeon处理器, 磁盘两块, 磁盘的性能规格是 SATA 盘. 15K RPM. 其中一块硬盘专用于存放ZooKeeper的日志, 另一块磁盘专用于存储快照.
- 读写的数据量均是1k字节. 模块client的机器大约有30台.
- ensemble被设置为爹不允许直连client.
这大致能解释为什么ensemble中实例的数量从3到5的时候, 性能有一个飞跃: 因为3个实例组成的ensemble中, 干活的只有两个, 另外一个是爹. 变成5个实例组成的ensemble后, 干活的就有四个了, 提升了一倍.
1.1.8 ZooKeeper的可靠性
除开吞吐量外, 使用者另外关心的一个指标就是可靠性, 下面这张图依然出自雅虎团队, 搭建了一个7个实例组成的ensemble, 然后用910个client去疯狂怼这个ZooKeeper集群, 怼ZooKeeper时其它参数和上面的性能测试一致, 不同的是写操作的比例为30%, 读操作为70%. 在怼的过程中, 依次手动模块了如下情况:
- 一个儿子挂了, 被恢复
- 另外一个儿子挂了, 被恢复
- 爹挂了, 被恢复
- 两个儿子挂了, 被恢复
- 另外一个爹挂了, 被恢复
图中橫轴是时间, 单位是秒, 纵轴是吞吐量. 图中带圆圈的数字分别代表了有上面对应的错误发生.
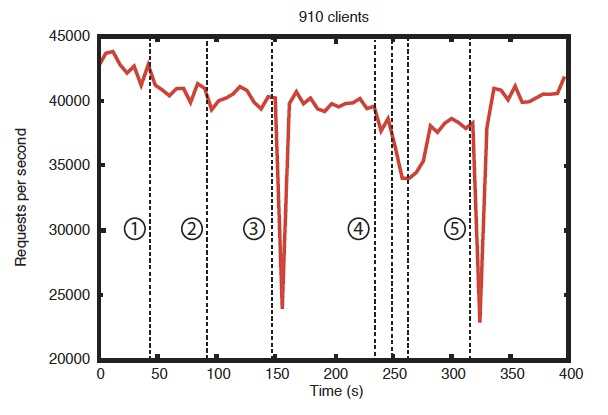
client共有910个, 所以比起上一张图来说, 吞吐图下降了不少. 从图中可以看出:
- 单个儿子实例有异常波动基本不影响ZooKeeper的性能, 对使用者来讲, 基本感觉不到.
- 爹挂的时候会影响ZooKeeper的性能, 但很快就能恢复. ZooKeeper在爹挂了之后重新选举一个爹的时间大致在200ms左右.
1.1.9 ZooKeeper的应用前景
ZooKeeper的版本号, 直至我翻译这个文档的时候, 稳定版已经到3.4.12了, beta版已经到3.5.4了. 能迭代到这个程序说明Apache对这个项目的态度已经显然不止于玩票了. 实际上ZooKeeper已经成功的应用在许多业界的产品上了. 雅虎用ZooKeeper做Message Broker的协调和错误恢复服务, 这应当是ZooKeeper能傍上的最粗的大腿了.雅虎的这个消息队列是一个很基础的发布-订阅消息系统, 规模很大. 受这个成功案例的影响, 雅虎里的一标广告系统在在用ZooKeeper做可靠性服务.
1.2 快速上手指南
这一小节主要是面向开发者的, 大致阅读本小节的内容, 能让你快速上手, 在你的代码中使用上ZooKeeper的功能, 并且为了配合自测, 这一小节大致会简单的讲一下如何搭建一个由单个实例组成的ZooKeeper ensemble(仅供开发调试使用的部署模式), 并且讲几个小命令用以检测你的ZooKeeper是否搭建成功, 再附上一些代码片断帮助你直观的理解ZooKeeper接口的用法.
这一节不会涉及生产环境中多Server模式的部署方法, 也不会涉及部署中的详细配置参数等. 这一节只是一个快速上手指南: 并且是面向开发人员的快速上手指南.
1.2.1 系统要求
请参考第四章
1.2.2 下载ZooKeeper
从这里下载ZooKeeper的最新的稳定版.
1.2.3 单实例模式
搭一个单实例模式的ZooKeeper很简单,
- 下载ZooKeeper的安装包, 解压
- 写一个配置文件, 建议把这个配置文件放在
zookeeper/conf/zoo.cfg这个位置, 配置文件是一个文本文件, 鉴于现在搭的是一个开发环境, 所以配置文件里简单的写下面这三行就可以了
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181- 来稍微解释一下这个配置文件中的配置项, 总共有三个
tickTime: 这是一个基本的时间单位, 后面的值的单位是毫秒, 比如上面我们设置为2000, 意思是一个tickTime代表了2000毫秒. tickTime主要用于发送心跳, 以及默认的最小会话超时时间是两个tickTimedataDir: 这个目录是用于存储内存数据库的快照的, 并且默认情况下除非特别指定, 事务日志也会存在这里clientPort: 这是开发给client用于连接的端口号
- 在写完配置文件, 并且把配置文件放在
zookeeper/conf/zoo.cfg后, 运行zookeeper/bin/zkServer.sh这个脚本就会启动一个单实例ZooKeeper服务.
另外需要注意的还有以下几点:
- ZooKeeper用
log4j接口来输出运行日志. 注意这里说的是运行日志, 而不是前面提到的事务日志. 更多的细节在第二章会涉及. 默认情况下日志会输出至控制台, 如果你希望把日志写进一个文件里, 需要自行配置log4j - 注意按上面步骤搭的是一个单实例ZooKeeper服务, 没有什么可靠性可言, 生产环境中千万不要这么干, 这只是给使用ZooKeeper接口写程序的开发人员用的一个本地测试环境, 而且由于是单实例, 一旦这个唯一的ZooKeeper server进程挂了, 整个ZooKeeper服务就不可用了.
1.2.4 管理ZooKeeper的存储
ZooKeeper有两个地方使用到了本地磁盘存储, 如果你仔细阅读了之前的章节的话, 会知道这两个点分别是:
- 事务日志
- 内存数据库快照
生产环境建议这两个东西分开存储, 并且最好是物理上分开存储: 分别使用一块独立的硬盘. 但具体细节这一章节就不说了, 后续在运维相关的章节会讲到.
1.2.5 连接至ZooKeeper服务
执行安装包里的这个脚本可以连接至上面搭建好的ZooKeeper本地单实例服务上去:
$ zookeeper/bin/zkCli.sh -server 127.0.0.1:2181这打开了一个交互式命令行程序, 连接成功后, 大致会有类似于以下的输出:
Connecting to localhost:2181
log4j:WARN No appenders could be found for logger (org.apache.zookeeper.ZooKeeper).
log4j:WARN Please initialize the log4j system properly.
Welcome to ZooKeeper!
JLine support is enabled
[zkshell: 0]在这个命令行程序内部, 键入help获取一些基本命令的用法, 比如这样:
[zkshell: 0] help
ZooKeeper host:port cmd args
get path [watch]
ls path [watch]
set path data [version]
delquota [-n|-b] path
quit
printwatches on|off
createpath data acl
stat path [watch]
listquota path
history
setAcl path acl
getAcl path
sync path
redo cmdno
addauth scheme auth
delete path [version]
setquota -n|-b val path类似于mysql的命令行工具, 你可以在这个命令行工具里向ZooKeeper服务发出一些指令, 比如你想查看目前ZooKeeper的层级名称空间里都存储了些啥玩意, 你可以使用ls命令
[zkshell: 8] ls /
[zookeeper]初始状态下, 层级名称空间里啥都没有, 根/下只有一个名为zookeeper的节点, 也就是znode. 你可以使用命令create来创建一个节点, 也就是znode, 像下面这样
[zkshell: 9] create /zk_test my_data
Created /zk_test上面这个命令创建了一个znode, 这个znode的路径是/zk_text, 并且把一个字符串"my_data"存在了这个znode中. 现在再用ls查看节点, 输出会类似如下:
[zkshell: 11] ls /
[zookeeper, zk_test]现在根名称空间/下有两个节点, 一个是默认存在的zookeeper, 一个是我们刚才创建好的zk_text节点.
如果你想取出znode中的数据, 可以使用get命令来获取, 如下:
[zkshell: 12] get /zk_test
my_data
cZxid = 5
ctime = Fri Jun 05 13:57:06 PDT 2009
mZxid = 5
mtime = Fri Jun 05 13:57:06 PDT 2009
pZxid = 5
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0
dataLength = 7
numChildren = 0输出了不少东西, 正如我们在简介里提到的那样, 当你向znode写入数据时, znode不光会保存数据本身, 还会保存一些其它玩意, 比如数据的创建时间, 数据的版本号之类的, 上面的输出很丰富, 第一行当然是我们在创建/zk_text节点时写入的字符串"my_data", 余下的行则是与这个数据有关的其它信息. 详细细节这里先略过.
当你想修改一个znode下的数据的时候, 你可以使用set命令, 就像下面这样, 我们把上面/zk_text节点里的数据, 从原先的"my_data"字符串, 修改为新字符串"junk":
[zkshell: 14] set /zk_test junk
cZxid = 5
ctime = Fri Jun 05 13:57:06 PDT 2009
mZxid = 6
mtime = Fri Jun 05 14:01:52 PDT 2009
pZxid = 5
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0
dataLength = 4
numChildren = 0修改数据也会输出节点的额外信息, 接下来再用get命令查看一下刚才的修改效果:
[zkshell: 15] get /zk_test
junk
cZxid = 5
ctime = Fri Jun 05 13:57:06 PDT 2009
mZxid = 6
mtime = Fri Jun 05 14:01:52 PDT 2009
pZxid = 5
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0
dataLength = 4
numChildren = 0可以看到, 数据已经被修改了.
当你想删除一个znode的时候, 你可以使用delete命令, 就像下面这样, 我们删除上面我们创建的/zk_text节点, 在删除后再用ls命令查看一下删除效果
[zkshell: 16] delete /zk_test
[zkshell: 17] ls /
[zookeeper]
[zkshell: 18]你看, 这样是不是就很直观, 简介里说了一大堆, 比不上你自己动手感受一下. 在这个交互式命令行程序里的各个命令, 其它都对应着ZooKeeper API里的各个接口, 有了上面的直观认识, 再参照着编程手册使用ZooKeeper就很容易理解了.
1.2.6 在代码中使用ZooKeeper
ZooKeeper对外提供的API有Java版和C语言两个版本, 功能上是完全一样的. C语言的API还有两个子版本: 一个用于在单线程环境中使用, 一个用于在多线程环境中使用. 更多的具体信息请参考后续章节.
1.2.7 搭建多实例的ZooKeeper ensemble
生产环境中显然不能使用单实例的ZooKeeper, 这里简单提一下如何搭建多实例构成的ZooKeeper ensemble. 多个实例构成的ensemble中, 每个ZooKeeper server进程都有自己的内存数据库, 但所有实例的内存数据库里的内容是一毛一样的, 这也是为什么官方文档里把多实例模式的ZooKeeper ensemble称为Replicated ZooKeeper的原因. 有一点小蛋疼的地方是, 每个ZooKeeper server进程在启动时都需要一个配置文件, 在多实例ZooKeeper ensemble中, 这多个实例使用的配置文件必须一毛一样, 多个实例正常情况下应当分布在多个不同的机器上, 所以这个配置文件的一致性嘛, 就需要运维部署人员手工维护了.
在这篇翻译的文档里, 我始终坚持把这种多个ZooKeeper server进程构成的ZooKeeper服务称为多实例模式ZooKeeper, 而不叫集群, 原因是: ZooKeeper并没有严格限制你, 必须每个ZooKeeper server独占一台机器. 虽然从逻辑上讲, 多实例模式下应当为每个ZooKeeper server分配一台独立的机器, 但你非要在一台机器上启动100个ZooKeeper server, 这是完全行得通的.
在多实例模式下, 实例的数量是有最低要求的: 最少要有3个实例. 并且强烈建议你, 实例的数目设定为奇数: 我们在简介中提到过, ZooKeeper服务运行时, 如果有少量实例挂掉了, 整个ZooKeeper服务还会正常运转. 这里对于少量的定义, 其实就是看挂掉的实例数量有没有达到二分之一. 奇数数目的实例, 比较容易判定二分之一.
多实例模式下的配置文件, 依然建议放在zookeeper/conf/zoo.cfg中, 内容与单实例模式稍有不同
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888其中tickTime, dataDir, clientPort三个配置项的含义这里不再重复, 新增的字段的含义如下:
initLimit: 这是一个超时时间, 它的单位是tickTime, 它限制了ZooKeeper中儿子与爹建立连接的超时时间. 比如上面设置为5, 且tickTime的值设置为2000毫秒, 意思是: 儿子与爹建立连接必须在10秒内完成, 超过10秒, 就会认为这个儿子废掉了.syncLimit: 这也是一个超时时间, 单位依然是tickTime. 上面设置为2, 意思是指, 当儿子执行数据同步的时候, 在4秒内必须完成, 超过4秒, 就会认为这个儿子废掉了.server.X: 配置文件里共有三行这种配置, 每一行描述了当前多实例ZooKeeper服务内的一个实例. 当每个ZooKeeper server实例进程启动的时候, 它先去dataDir目录下找一个名为myid的文本文件, 这个文件里写着一个数字, 这个数字为1, 就代表当前启动的server 进程是配置文件里的server.1. 然后进程就会读取配置文件里server.1的值, 这里值为zoo1:2888:3888, 2888是用于儿子和爹建立连接使用的端口, 3888是用于选举爹的时候使用的端口号. 注意, 如果你在一台机器上启动多个ZooKeeper server实例, 那么注意多个实例间不能使用相同的端口号.
1.2.8 简单的优化建议
为了获取更好的性能, 建议在配置文件中额外配置一个配置项, 名为dataLogDir, 值为一个目录地址. 配置该配置项之后, 会导致当前实例会将事务日志写向对应地址. 否则会直接写向dataDir中去.
更多的优化建议, 与更细节的多实例ZooKeeper部署指导会在后续运维章节仔细说明.
2. 面向开发者的文档
// TODO
3. BookKeeper
// TODO
4. 面向系统管理员与运维人员的文档
4.1 系统管理员指南
4.1.1 部署
4.1.1.1 系统要求
支持的操作系统平台
ZooKeeper下有多个组件. 有些组件在各大平台上都能跑, 有些则只能跑在指定的一部分平台上. 这些组件包括:
- Client. 指的是ZooKeeper的客户端库, 用于其它应用程序与ZooKeeper ensemble建立连接并使用ZooKeeper的功能
- Server. 指的是ZooKeeper server. 跑在ZooKeeper ensemble中各个机器上的应用程序, 也就是ZooKeeper server进程.
- Native Client. 一个用C语言实现的库, 功能和Client一样, 只不过面向的是C系开发者.
- Contrib. 其它可选的组件.
下表展示了各个组件在各个操作系统平台上的受支持程度:
| 操作系统 | Client组件 | Server组件 | Native Client组件 | Contrib其它组件 |
|---|---|---|---|---|
| GNU/Linux | 可用于开发及生产 | 可用于开发及生产 | 可用于开发及生产 | 可用于开发及生产 |
| Solaris | 可用于开发及生产 | 可用于开发及生产 | 不支持 | 不支持 |
| FreeBSD | 可用于开发及生产 | 可用于开发及生产 | 不支持 | 不支持 |
| Windows | 可用于开发及生产 | 可用于开发及生产 | 不支持 | 不支持 |
| Max OS X | 仅可用于开发 | 仅可用于开发 | 不支持 | 不支持 |
其它没提到的操作系统平台就自求多福吧.
需要的软件
ZooKeeper是用Java写的, 所以需要一个版本在1.6或更高的JDK. 对于多实例模式的部署建议使用多台机器.
4.1.1.2 多实例模式
我们在第一章的快速上手指南中提到过, 生产环境建议使用多实例模式部署ZooKeeper, 并且建议单个实例独占一台机器, 且建议实例的个数为奇数. 个中缘由这里不再重复.
下面是如何部署多实例模式中的一个实例的步骤. 在多台机器上重复以上步骤, 就能搭起一个多实例模式的ZooKeeper服务.
- 安装JDK
- 设置Java运行时的"heap size"(堆容量). 额外设置这个是由于当内存不足时, swapping操作会严重拖慢zookeeper的性能(wtf? 2018年了好吧!). 一般情况下, 如果机器是zookeeper独占的, 那么内存多大就设置多大就可以了.
- 下载ZooKeeper, 点这里
- 解压下载好的压缩包
- 写一个配置文件, 配置文件的路径和文件名随便啥都行. 内容如下. 配置文件中各个配置项的具体含义在
4.1.2.10 配置参数中有详细说明. 如下的配置文件对应的使用要求是:- 三台机器, 每个实例独占一台机器. 实例的编号分别为
1,2,3 - 机器的2888端口用于儿子和爹通信, 3888端口用于爹的选举
对外提供服务的端口号为2181
tickTime=2000 dataDir=/var/lib/zookeeper/ clientPort=2181 initLimit=5 syncLimit=2 server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888
- 三台机器, 每个实例独占一台机器. 实例的编号分别为
- 在配置文件指定的
dataDir路径下创建一个名为myid的文件, 这是一个文本文件, 文件内容只有一个数字: 实例的编号 使用类似于下面的命令行启动实例:
java -cp zookeeper.jar:lib/log4j-1.2.15.jar:conf org.apache.zookeeper.server.quorum.QuorumPeerMain zoo.cfg- ZooKeeper server是Java程序, 所以用
java命令启动 - -cp 参数指示JVM虚拟机去哪里找需要的class文件. 这里指定了两个jar包文件, 和一个目录地址. 用分号
:隔开- zookeeper.jar. 这个jar包里存着ZooKeeper server的主要class文件
- lib/log4j-1.2.15.jar. 这个jar包里存着ZooKeeper输出运行日志所需要的
log4j的class文件 - conf. 这个目录里的jar包存着其它启动ZooKeeper所需要的class文件
org.apache.zookeeper.server.quorum.QuorumPeerMain是main函数所在的类路径zoo.cfg是配置文件路径- 简单点, 你可以把配置文件放在
zookeeper/conf/zoo.cfg中, 然后直接运行zookeeper/bin/zkServer.sh脚本来启动. 这个脚本中的内容更丰富. 但核心命令和上面那行基本一样. 这样的好处是很无脑, 很方便.
- ZooKeeper server是Java程序, 所以用
要测试当前ZooKeeper Server实例进程是否正确运行, 可以使用下面的脚本进行测试:
$ bin/zkCli.sh -server 127.0.0.1:21814.1.1.3 单实例模式
单实例模式一般仅用于开发自测使用, 具体的部署步骤在1.2.3 单实例模式章节有描述, 请翻回去看.
4.1.2 系统管理
4.1.2.1 部署设计
ZooKeeper的可靠性依赖于两个假设
- 假设你的ZooKeeper以多实例模式部署, 且每个实例占用一台机器. 这些机器在运行过程中, 不可能出现在同一时间有超过二分之一的机器宕机的可能.
- 每台机器有网络状况与磁盘状况良好, 多实例进程启动时运行的jar包代码是一致的.
要使第一个假设尽可能的成立, 你可以做如下的事情:
- 预估你的机器宕机的频率与持续时间, 恢复时间, 算出基本不可能同时宕机的机器台数. 比如你根据去年的运维记录, 查一下去年的宕机概率, 然后根据这个概率估算出整个机房同时有指定的1台机器宕机的概率, 同时有指定的两台机器宕机的概率. 把这个概率降低到你能接受的程度, 比如你估算出你的机房中, 同时有指定的5台机器同时宕机的概率不足千万分之一, 这个你可以接受, 那么将ZooKeeper多实例的规则设置为 2*5 + 1 == 11个, 即在11台机器上部署ZooKeeper, 这样保证在估算正确的情况下, 即便有千万分之一的概率发生了同时有五台机器宕机, ZooKeeper服务依然能正常工作.
- 尽可能的保证uklfZooKeeper的机器之间的宕机没有关联性. 比如如果你使用云主机, 尽量保证所有vm都分属不同的host, 使用实体机, 尽可能的将机器分散至多个IDC之类的.
要使第二个假设尽可能的成立, 你可以做如下的事情:
- 如果有条件, 尽可能的使部署的机器上只有一个ZooKeeper server进程.
- 如果没有条件做到上面一条, 那么尽量避免ZooKeeper server进程与其它进程争用网络资源或存储资源. 即预留给ZooKeeper server进程足够的带宽或独占网卡, 为ZooKeeper预留足够的IO资源以及内存空间
- ZooKeeper里很拖性能的两个点就是写
事务日志与内在数据库快照, 尽量将这两部分日志写向不同的物理磁盘. 即是在启动配置中, 独立配置dataDir与dataLogDir, 并将两个配置的路径指向不同的物理磁盘. - 运行时为JVM分配合理的heap size, 以防止发生swapping拖慢进程.
4.1.2.2 Provisioning
// TODO, 官方文档这里留空了
4.1.2.3 Things to Consider: ZooKeeper Strengths and Limitations
// TODO, 官方文档这里留空了
4.1.2.4 Administering
// TODO, 官方文档这里留空了
4.1.2.5 运维
对于长期运行的ZooKeeper ensemble来说, 运维工作是必须做的, 运维人员需要注意以下几点:
清理磁盘文件
ZooKeeper中有两处使用到了磁盘: 事务日志与内存数据库快照. ZooKeeper名称空间里的节点发生变更的时候, 就会有内容写入事务日志. 通常情况下, 当单个事务日志文件变的越来越大的时候, 事务日志就需要创建一个新的文件. 但在创建新的事务日志文件之前, ZooKeeper会先把当前的内存数据库的状态写入磁盘先做快照, 然后再生成一个新的事务日志文件. 这样就保证了快照文件和事务日志文件是一一对应的. 但快照落地需要时间, 在快照落地期间如果还有事务来临, 那么这部分事务的日志依然会写向旧的事务日志文件里. 这就导致, 快照文件对应的那个事务日志文件里, 存储的事务日志可能要比当前快照文件要新.
ZooKeeper server进程在默认启动的情况下, 是不会自动删除事务日志文件和快照文件的. 当然这是可配置的, 配置项分别是autopurge.snapRetainCount和autopurge.purgeInterval. 这两个配置项的具体含义在4.1.2.10章节有详细描述. 但需要注意: 如果你要这样做, 那么最好为每台部署的机器提供不同的配置值, 除非这些机器的规格是完全一毛一样的!
除过在配置文件中设定, 还有一种方法就是调用一个ZooKeeper提供的小工具, 大致如下:
java -cp zookeeper.jar:lib/log4j-1.2.15.jar:conf org.apache.zookeeper.server.PurgeTxnLog <dataDir> <snapDir> -n <count>其中<dataDir>是事务日志的保存目录, <snapDir>是快照文件的保存目录, <count>是要保留的个数. 建议大于3. 运行该命令后, 除过最近的<count>对事务日志文件与快照文件, 其它文件都将被删除. 这是一个一次性命令. 如果你想定期清理, 那么只能自己写个脚本咯.
注意两点:
- 永远不建议手动删除事务日志文件与快照文件
- 通过配置项使ZooKeeper server自动删除, 只有在ZooKeeper版本大于3.4后才可用
- PrugeTxnLog工具是一个一次性工具, 如果需要定期清理, 你需要自己写一个脚本.
- 当机器规格不同的时候, 建议按照不同规格定制不同的清楚阈值
清理运行日志
ZooKeeper用log4j来输出运行日志. 如果要更改运行日志的相关配置, 你需要独立为log4j提供配置文件. 建议使用log4j提供的滚动日志特性, 这样就免去了清理运行日志的问题. 更多详细信息请参阅4.1.2.8 运行日志
4.1.2.6 监控ZooKeeper server进程的死活
ZooKeeper的server进程在错误发生的时候会立即自杀, ZooKeeper的设计哲学是这样的:
- 单个实例挂掉, 或少量实例挂掉不影响整体服务
- 当单个实例遇到错误的时候, 实例会立即挂掉
- 实例被重启后会自动加入ensemble
- 但实例不会自动重启
所以搞一个监控进程, 在实例进程挂掉之后将其立即拉起是一个很好的做法. 比如daemontools或SMF. 还比如我们亲爱的织云.
4.1.2.7 监控ZooKeeper server服务的状态
要监控ZooKeeper服务的状态, 有两个选择
- 用4字命令去检查. 这个在
4.1.2.11 ZooKeeper4字命令中有详情 - JMX. 这个在
4.3 JMX中有详情
4.1.2.8 运行日志
ZooKeeper使用log4j 1.2来输出运行日志. 默认的配置文件在zookeeper/conf/log4j.properties中. log4j的配置文件要求要么放在工作目录里, 要么放在类路径里.
详情请查看log4j的官方手册
4.1.2.9 问题定位
由于文件损坏导致实例不能启动
ZooKeeper的server进程在事务日志文件被损坏的情况下是起不来的. 这时运行日志会说在载入ZooKeeper database时出现IOException. 这种情况下, 你需要做的是:
- 通过四字命令
stat检查ensemble中的其它实例是否正常工作 - 如果其它实例正常, 那么把当前实例
dataDir目录下的version-2子目录中的所有文件删除, 再把dataLogDir下的version-2子目录下的所有文件删除, 然后重启就可以了.
这种情况是当前实例的事务文件损坏, 不能重建内存数据库, 删除掉事务日志和数据库快照后, 当前的实例在重启后会通过其它实例拉取内在数据库, 重建事务日志和快照文件.
4.1.2.10 配置参数
ZooKeeper的行为受配置文件影响. 所有同一个ensemble中的实例建议使用完全相同的配置文件. 但使用完全相同的配置文件有一个前提条件: 就是所有实例所属的机器上的磁盘布局是相同的. 磁盘布局不同意味着不同的机器下的实例在配置dataDir和dataLogDir的时候配置值可能有差异, 但除此之外, 一个ensemble中的所有实例的配置文件必须保证server.x=xxxx这些配置值是完全一致的.
最小配置
下面列出来的是要让ensemble正常工作, 每个实例都需要配置的配置项
| 配置项 | 含义 |
|---|---|
| clientPort | 当前实例对外提供服务的端口号. 即是client通过该端口号连接到该实例上. 建议所有实例都配置为相同的值. |
| dataDir | 内在数据库快照的存储地址. 如果没有配置dataLogDir的话, 该目录还会存储事务日志 |
| tickTime | ZooKeeper中计量时间的最基本单位. 配置值的单位是毫秒 |
高级可选配置
下面列出来的是一此可选配置, 属于高级选项. 你可以用这些配置项进一步个性化ZooKeeper server的行为. 其中一些配置项的值可以通过在启动server进程的时候写入Java 系统属性来设置.
| 配置项 | 对应的Java系统属性名 | 含义 |
|---|---|---|
| dataLogDir | 无 | 事务日志的写入地址 |
| globalOutstandingLimit | zookeeper.globalOutstandingLimit | client向ZooKeeper server递交请求的速度可以比ZooKeeper server处理请求的速度快, 特别是有多个client访问同一个ZooKeeper server的时候. 通常情况下对于不能及时处理的请求, server都会将其缓存到队列中. 但这个队列也不是无限长的, 这个配置项就是在设置这个队列的长度, 默认值是1000, 超过队列长度后, 再发请求请求就会被丢弃 |
| preAllocSize | zookeeper.preAllocSize | 为了避免频繁的seek操作, ZooKeeper的事务日志文件默认是以64M为基本单位的. 设置这个值就可以改写这个默认的块大小, 这个配置项的单位是kb |
| snapCount | zookeeper.snapCount | 默认值是100000, 这是指每向事务日志里记录十万个事务, 内存数据库就会被快照一次, 同时事务日志会开新文件. 但为了避免所有的ZooKeeper server在同一时刻落地快照更换事务日志文件, 为了把这个操作错开, 所以真实的值是 位于区间 [50001, 100000] 区间的一个随机数. 即是 [snapCount/2 + 1, snapCount]区间 |
| maxClientCnxns | 无 | 同一个个client是可以和同一个ZooKeeper ensemble之间建立多个连接的, 这个配置项就是在限制同一个client与ZooKeeper ensemble之间建立的连接数. 这可以有效预防DoS攻击, 还可以预防ZooKeeper server所在的机器文件描述符耗尽. 这个值默认是60, 当这个值被设置为0时, 是取消掉这个限制的意思 |
| clientPortAddress | 无 | 这是一个3.3版本后的新配置项, 这是一个IP地址, 当配置了之后, ZooKeeper server在监听端口的时候, 就会绑定到这个地址上. 而默认情况下, 在监听clientPort端口的时候, 绑定的是ANYADDR |
| minSessionTimeout | 无 | 这也是一个3.3版本后的新配置项, 这个配置项的单位是毫秒, 而不是tickTime. 指的是会话超时r的最小时间, 默认的会话超时时间是2个tickTime. 这个值可以和client协商. |
| maxSessionTimeout | 无 | 这依然是一个3.3版本后的新配置项. 和minSessionTimeout类似, 但这是会话超时的最大时间. 默认是20个tickTime |
| fsync.warningthresholdms | zookeeper.fsync.warningthresholdms | 3.3.4版本后的一个新配置项. 这是一个时间量, 单位是毫秒, 默认是1000, 也就是一秒. 这指的是当fsync 事务日志的耗时大于1秒时, 就会向运行日志里输出一条warning日志. 注意这个配置项只能通过Java系统属性设置 |
| autopurge.snapRetainCount | 无 | 3.4版本后的一个新配置项, 当设置了该配置项后, ZooKeeper将会自动清理快照文件和对应的事务日志文件. 仅保留最近的autopurge.snapRetainCount个. 默认值是3, 最小值是3, 不能设置比3更小的值 |
| autopurge.purgeInterval | 无 | 这是一个开关配置项, 也是一个时间配置项. 当设置为0的时候, 是关闭自动清理快照和事务日志文件的功能的意思. 当设置为1或更高的值时, 是指每隔autopurge.purgeInterval个小时, 就执行一次自动清理任务 |
| syncEnabled | zookeeper.observer.syncEnabled | 3.4.6有这个配置项, 3.5.0和更高的版本有. observer在默认情况下会和participants一样记录事务日志, 落地快照. 将这个值设置为false就是关掉了observer记录事务日志落地快照的行为, 默认是true. observer和participants的概念会在4.4章节介绍 |
多实例模式下的配置项
下面列出来的配置项是多实例模式下的一些配置项. 有一些配置项可以通过在启动server进程的时候写入Java系统属性来设置.
| 配置项 | 对应的Java系统属性名 | 含义 |
|---|---|---|
| electionAlg | 无 | 选爹算法. 0 - 原始的基于UDP的选爹算法. 1 - 不带身份认证的, 基于UDP的快速选爹算法. 2 - 带身份认证的, 基于UDP的快速选爹算法. 3 - 基于TCP的快速选爹算法. 默认值是3. 其中, 0, 1, 2被官方文档标记为了deprecated, 也就是说, 除非有特殊需求, 不要动手配置这个配置项 |
| initLimit | 无 | 时间值, 单位是tickTime, 指的是儿子与爹建立连接并同步数据的超时时限. 当ZooKeeper管理的数据特别多特别大的话, 建议适当增加这个配置值. 这个配置项没有默认值, 所以配置文件里必写 |
| leaderServes | zookeeper.leaderServes | 控制爹是否也向client提供服务, 默认是允许的. 如果client的业务比较复杂的话, 建议关闭这个功能, 让爹专心管儿子 |
| server.x=[hostname]:nnnn[:nnnn] | 无 | ensemble中的每一个实例都要这样登记在配置文件里. x是dataLog目录下的myid文件里的数字, 即是实例的编号. hostname是对应的实例所在的机器名, 或者直接写成IP地址, 前一个nnnn是用于爹和儿子通信用的. 第二个nnnn 是用于选举爹用的. |
| syncLimit | 无 | 时间值, 单位是tickTime, 儿子向爹报平安的时限, 如果儿子在超过这个时间值后没有给爹报平安, 爹就认为儿子死了. 关于initLimit和syncLimit这两个配置项之间的不同, 请参考这个邮件列表里的解释. 官方文档里写的简直让人怀疑是不是复制粘贴过来的. |
| group.x=nnnn[:nnnn] | 无 | 给server实例分组. x是组编号. nnnn则是实例编号. 注意如果你给ensemble中的实例分组的话, 各个组之间不能有交集, 并且要保证所有组的并集就是整个ZooKeeper ensemble. (换句话说你不能单独为其中某一些实例分组, 所有的实例都必须从属于一个组), 这里有一个例子 |
| weight.x=nnnn | 无 | 为一个组设置权重. ZooKeeper只有在少量的一些场合才需要考虑权重, 已知的两个场合, 一个是选爹的时候, 权重影响实例投票的影响力, 另外一个是atomic broadcast protocol. 默认情况下权重值是1 |
| cnxTimeout | zookeeper.cnxTimeout | 时间值, 单位是秒. 爹选出来后, 所有人都需要知道爹是谁, 这个时间就是选爹时每个机器都会把选爹端口打开的时间, 在这个时间内应当有一个结果, 并且结果将通知到每个实例的选爹端口上. 这个配置项仅在electionAlg的值为3时才有用. 默认值是5秒 |
| 4lw.commands.whitelist | zookeeper.4lw.commands.whitelist | 四字命令白名单, 未出现在名单上的四字命令, ZooKeeper将不处理. 默认值包括除过wchp和wchc两个之外的所有四字命令. 如果要设置这个配置项的值, 注意各个四字命令之间要以逗号区分, 比如: r4lw.commands.whitelist=stat, ruok, conf, isro, 如果你需要开启所有四字命令, 可以简单的使用通配符4lw.commands.whitelist=* |
| ipReachableTimeout | zookeeper.ipReachableTimeout | 3.4.11版本后的新配置项, 时间值, 单位是毫秒. 当一个server的hostname不是IP地址时, 并且恰巧DNS服务或者hosts表里这个名字后面挂着多个ip地址时, 这个值就有用了. 默认情况下, ZooKeeper会默认使用名字解析出来的第一个IP地址, 而不检查这个IP是否可达, 而如果这个值设置成了一个大于0的值, 那么ZooKeeper就会使用InetAddress.isReachable(ipReachableTimeout)来判断这个IP是否可达, 如果不可达, 就换下一个, 如果全都不可达, 那么就会绝望的使用第一个IP地址 |
| tcpKeepAlive | zookeeper.tcpKeepAlive | 3.4.11版本后的新配置项. 如果这个配置项被设置为true, 那么server之间用来选举的TCP连接就会被置为长连接, 默认情况下这个值是false |
身份认证与授权相关的配置项
下面这些配置项与身份认证授权相关.
为了避免看不懂下面的配置项都在干嘛, 先大致说一下Zookeeper里的认证与授权
在ZooKeeper server端, 每个znode存储两部分内容: 数据和状态. 状态中包含ACL信息. 创建一个znode会产生一个ACL表, 每个ACL记录有以下内容:
- 验证模式(scheme)
- 具体内容(id). 比如当scheme=="digest"的时候, id为是用户名和密码, 比如"root:J0sTy9BCUKubtK1y8pkbL7qoxSw="
- 这个ACL拥有的权限
ZooKeeper提供了如下几种验证模式(scheme)
- digest. 就是用户名+密码.
- auth. 不使用任何id, 表示任何已确认用户
- ip. 用client连接至server时使用的IP地址进行验证
- world. 固定ID为"anyone", 为所有client端开放权限
- super. 在这种scheme下, 对应的id拥有超级权限.
注意的是, exists操作的getAcl操作不受ACL控制, 任何client都可以执行这两个操作.
znode的权限主要有以下几种:
- create
- read
- write
- delete
- admin. 允许对本节点执行setAcl操作
| 配置项 | 对应的Java系统属性名 | 含义 |
|---|---|---|
| zookeeper.DigestAuthenticationProvider.superDigest | 仅能通过Java系统属性设置 | 3.2版本中的新配置项. 允许管理员以超级用户的身份来访问ZooKeeper中的层级名称空间. 当以超级用户访问时, znode的ACL完全放行. 以参数"super:<password>"来调用org.apache.zookeeper.server.auth.DigestAuthenticationProvider可以生成一个超级用户. 然后用前面命令生成的"super:<data>"作为Java系统属性, 在启动各个server的时候传递给进程, 就开启了这个功能. 注意当一个client通过scheme=digest的方式来认证, 并且提供的认证数据是超级用户的认证数据, 也就是前面提到的"super: |
实验性的配置项
| 配置项 | 对应的Java系统属性名 | 含义 |
|---|---|---|
| Read Only Mode Server | readonlymode.enabled | 显然这个值只能有过Java系统属性来设置. 将其设置为true, 配置ZooKeeper为只读模式. 具体细节参见ZOOKEEPER-784 |
不安全的配置项
| 配置项 | 对应的Java系统属性名 | 含义 |
|---|---|---|
| forceSync | zookeeper.forceSync | 默认情况下, ZooKeeper强制要求在有数据变更请求时, 先写事务日志, 再执行变更. 如果将这个配置设置为no, ZooKeeper在执行数据变更时就不会等事务日志写完再执行了. |
| jute.maxbuffer | jute.maxbuffer | 这个配置项仅能通过 Java系统属性设置. 这设置的是一个znode中能存储的数据的容量. 默认值是0xfffff, 也就是1M. 注意如果要更改这个值, 所有server都要同步更改. 注意如果你要改这个值, 请先反思一下你使用ZooKeeper的姿势是不是有点不正确 |
| skipACL | zookeeper.skipACL | 跳过ACL检查, 这能带来极大的性能提升, 但很不安全 |
| quorumListenOnAllIPs | 无 | 如果设置为true, server在监听端口的时候, 将尝试监听所有本地可用的IP+端口的组合. 默认情况下这个配置是false, 这个行为是关闭的 |
使用Netty框架进行通信
这是3.4版本后的一个特性. Netty是一个基于NIO的客户端-服务器通信框架, 这个框架简化了Java在网络通信层上的很多繁操作, 并且内置支持SSL和认证授权, 当然SSL和认证授权是额外的可选功能.
3.4之前, ZooKeeper是直接用NIO的, 在3.4之后, NIO只是一个可选项, 但依然是默认选项, 如果要使用Netty的话, 需要把zookeeper.serverCnxnFactory替换为org.apache.zookeeper.server.NettyServerCnxnFactory. 你可以只在client上使用Netty, 也可以在server上使用Netty, 但通常情况下, 建议要改一起改.
蛋疼的是相关的文档官方还没有写.
4.1.2.11 四字命令
ZooKeeper支持一系列的四字命令, 你可以在client上通过telnte或nc直接向server发送这些四字命令.
使用一个四字命令如下所示, 下面使用echo和nc将四字命令ruok发送给本机的server
$ echo ruok | nc 127.0.0.1 5111下表是所有支持的四字命令, 注意有些命令仅在特定版本之后才受支持:
| 命令 | 语义 |
|---|---|
| conf | 3.3版本后支持. 打印出server的配置信息 |
| cons | 3.3版本后支持. 打印出server上的所有连接/会话 |
| crst | 3.3版本后支持. 重置有关连接/会话的统计数据 |
| dump | 这个命令只有发给ensemble中的爹有才效. 列出所有重要的会话和生命周期随会话的znode |
| envi | 打印出server运行环境 |
| ruok | are you ok, 如果回复 imok, 则说明这个server很健康. 如果server有问题, 则不会收到回复. 需要注意的是, 一个server回复了ruok不代表这个server在ensemble中的状态是正常的, 这仅代表server进程正常启动了. 要查看ensemble的概况需要用stat命令 |
| srst | 重置server上的所有统计数据 |
| srvr | 3.3后的新命令. 列出server的全部信息 |
| stat | 列出server的细节信息和与之相连的clients |
| wchs | 3.3后的新命令, 列出对该server的所有监控(watch) |
| wchc | 3.3后的新命令, 列出监控这个server的所有会话, 并列出每个会话监控的名称空间路径. 注意, 在会话较多的server上, 这个命令可能会相当耗时 |
| wchp | 3.3后的新命令, 列出被监控的所有层级名称空间路径, 以及相关的会话. 注意同上, 这个命令也可能会相当耗时 |
| mntr | 3.4后的新命令. 列出有关ensemble的一系列状态值. 通过这些状态值可以查看整个ensemble是不是正常 |
| isro | 3.4后的新命令. 检查server是否运行在只读状态, 回复ro代表server在只读状态, 回复rw代表server在可读可写状态 |
| gtmk | 获取当前的trace mask值, 以10进制64位有符号数值形式返回, 具体trace mask的含义下面会讲 |
| stmk | 设置trace mask |
这里需要注意的有:
- mntr命令的输出大致长下面这样. 输出格式符合java属性格式, 如果你要写个脚本定时发送这个命令以监控ensemble的运行状态, 注意输出的字段的数量可能会有变化, 写脚本的时候注意这一点. 另外有一些字段是与操作系统平台相关的, 有些字段则只有爹才会回复. 输出每一行的格式是
key value, 下面是一个示例
$ echo mntr | nc localhost 2185
zk_version 3.4.0
zk_avg_latency 0
zk_max_latency 0
zk_min_latency 0
zk_packets_received 70
zk_packets_sent 69
zk_outstanding_requests 0
zk_server_state leader
zk_znode_count 4
zk_watch_count 0
zk_ephemerals_count 0
zk_approximate_data_size 27
zk_followers 4 - only exposed by the Leader
zk_synced_followers 4 - only exposed by the Leader
zk_pending_syncs 0 - only exposed by the Leader
zk_open_file_descriptor_count 23 - only available on Unix platforms
zk_max_file_descriptor_count 1024 - only available on Unix platforms- trace mask是一个64位的数值, 按位设flag表示一些运行日志开关. 另外log4j必须设置运行日志级别为
TRACE才能看到trace日志信息. trace mask中各位的含义如下:
| trace mask bit | 含义 |
|---|---|
| 0b0000000001 | 保留位 |
| 0b0000000010 | 记录client的请求, 不包括ping |
| 0b0000000100 | 保留位 |
| 0b0000001000 | 记录client的ping请求 |
| 0b0000010000 | 记录来自爹的信息, 不包括ping |
| 0b0000100000 | 记录会话的创建, 销毁和核实 |
| 0b0001000000 | 记录监控事件发生时向client报告的日志 |
| 0b0010000000 | 记录来自爹的ping |
| 0b0100000000 | 保留位 |
| 0b1000000000 | 保留位 |
默认的trace mask是0b0100110010. 另外stmk的用法也稍微复杂一点, 还要注意将trace mask的值通过stmk命令传递给server的时候, 要使用大端字节序, 也就是网络序. 下面是一个使用perl调用stmk命令的例子:
$ perl -e "print ‘stmk‘, pack(‘q>‘, 0b0011111010)" | nc localhost 2181
250调用stmk命令时, server会将设置后的trace mask以十进制数值的形式返回回来.
4.1.2.12 数据文件管理
将事务日志文件和快照文件存储在不同的物理磁盘上, 可以提升系统性能.
快照存储目录
配置项dataDir指向的目录路径中主要存储两种文件:
myid: 这个文件里写着当前server实例的编号snapshot.<zxid>: 这里存储着内存数据库的快照
server实例的编号用在两个场合: myid文件里, 以及配置文件里的server.X配置项中. 当前server实例在启动的时候, 先去配置文件里看dataDir的值, 然后去找dataDir/myid这个文件, 查看文件内容, 得知自己的编号, 然后在配置文件里再找对应的server.x查看要开的端口号.
快照文件的后缀, <zxid>, 是一个事务ID. 这是在落地内存数据库这个过程开始时, 成功执行的最后一个事务的ID号, 但蛋疼的是, 在落地快照的过程中, server还在接受请求, 执行事务, 也就是在落地的过程中, 内存数据库中的数据还处于一个变动的过程中, 这就导致落地后的快照文件像是一个扭曲的文件. 像是你在用手机拍摄全景照片的过程中, 有一只猫随着你的镜头走, 然后最终拍摄出来的照片里有一只长度为17米的猫. 最终落地生成的快照文件里的数据状态可能和任何一个时刻内存数据库的状态都对不上, 就是因为这个原因. 但ZooKeeper依然可以用这种扭曲的快照文件重建内存数据库, 这是因为ZooKeeper中的update操作是幂等的, 这就保证了在扭曲的快照文件之上重放事务日志里的日志, 就可以将进程的内存状态恢复到日志结束时的那个时刻.
事务日志目录
在有update请求的时候, server的默认行为是先写事务日志, 再执行update操作. 单个事务日志里存储的事务个数超过一个阈值的时候, 就会导致事务日志新开一个文件, 同时会导致内在数据库落地快照, 这个阈值在上面的配置项中有提. 日志文件的后缀是日志文件里第一个日志的ID
文件管理
快照文件的格式和事务日志文件的格式是死的, 这就允许你从现网的server机器上将事务日志和内存快照拷贝至你的开发机, 在你的开发环境重现现网的情景, 从而进行一些调试或问题定位操作.
使用旧的事务日志文件和快照文件还能重建过去某个指定时刻server的状态, LogFormatter类可以用来访问事务日志文件, 以获取可读的信息. 当然使用的时候需要有管理员权限, 因为数据是加密的.
server进程本来是没有删除事务日志和快照文件的能力的, 但这在3.4版本中也随着新的配置项autopurge.snapRetainCount和autopurge.purgeInterval添加上了.
4.1.2.13 要避免的事情
下面是几个你应当在部署运维的时候极力避免的事情:
- ensemble中各个server使用的配置文件中,
server.X配置表不一致. 所有的配置文件中, 都要以server.X配置项的形式列出当前ensemble中的所有server, 包括自己. 如果这个东西不一致, 会炸. - 事务日志目录设置不合理. 将事务日志目录指向一个IO繁忙的磁盘, 会导致server始终处于一个半死不活的状态.
- 不正确的java heap size. 频繁的swap操作会严重拖慢性能. 保守起见, 如果你的机器有4G内存, 把java heap size设置为3G就好了.
- 部署的时候不考虑安全性. 建议在生产环境中合理配置防火墙.
以上是关于ZooKeeper: 简介, 配置及运维指南的主要内容,如果未能解决你的问题,请参考以下文章