怎样查一个字符的unicode编码
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎样查一个字符的unicode编码相关的知识,希望对你有一定的参考价值。
你好,访问https://unicode-table.com/cn/输入想要的查看的字符,然后点击搜索图标,最后点击搜索到的某个结果。这里我们搜索的是2
然后就可以看到该字符的详细介绍了(这里只截取了一部分信息,下面还有很多,详细可查看:https://unicode-table.com/cn/0032/)
ANSI编码是一种对ASCII码的拓展:ANSI编码用0x00~0x7f (即十进制下的0到127)范围的1 个字节来表示 1 个英文字符,超出一个字节的 0x80~0xFFFF 范围来表示其他语言的其他字符。也就是说,ANSI码仅在前128(0-127)个与ASCII码相同,之后的字符全是某个国家语言的所有字符。值得注意的是,两个字节最多可以存储的字符数目是2的16次方,即65536个字符,这对于一个语言的字符来说,绝对够了。还有ANSI编码其实包括很多编码:中国制定了GB2312编码,用来把中文编进去另外,把编到Shift_JIS里,韩把韩文编到Euc-kr里,各国有各国的标准。受制于当时的条件,不同语言之间的ANSI码之间不能互相转换,这就会导致在多语言混合的文本中会有乱码仅供参考 参考技术A
现在有很多工具可以辅助查询。
可以通过这个工具:http://tool.oschina.net/encode
或者推荐这个网址: http://bianma.supfree.net/ Unicode
另外UNICODE官网上也提供了对照表的下载,只不过那个东西是PDF,可以搜索字的对应unicode
delphi7中 怎样把文件保存成unicode编码保存
delphi7中不支持。用windows自带的记事本程序打开文件,然后在菜单中选择“另存为”,并在弹出窗口的编码选择中选择“unicode”。 参考技术A 很多年前就不用D7了,不过原理都差不多,你可以用TStringStream来保存数据,该有个编码的属性,自己查一查吧追问
D7中的TStringStream 所有方法都看过了, 没有要穿编码属性的方法。
D2009以后的 可以用SaveToFile(fileName,EnCodeing)。
就是D7的不知道该怎么弄。
TStringStream.Create(?)
检查构造函数参数没?
function AnsiToUnicode(s:string):WideString;
var
lpWideChar:PWideChar;
len:Integer;
begin
len := ( Length(s) + 1 ) * 2;
GetMem(lpWideChar, len);
ZeroMemory(lpWideChar, len);
MultiByteToWideChar(CP_ACP,MB_PRECOMPOSED,
PChar(s), Length(s),lpWideChar, Len);
Result := lpWideChar;
FreeMem(lpWideChar);
end;
function UnicodeToAnsi(s:WideString):string;
var
lpChar:PChar;
len:integer;
begin
len := Length(s) * 2;
GetMem(lpChar,len);
ZeroMemory(lpChar, len);
WideCharToMultiByte(CP_ACP, WC_COMPOSITECHECK, PWideChar(s),
Length(s),lpChar,Len, nil, nil );
Result := lpChar;
FreeMem(lpChar);
end;本回答被提问者和网友采纳 参考技术C 用AnsiToUtf8
函数原型:function AnsiToUtf8(const S: string): UTF8String;追问
和utf8没关系把?
追答唉,补补课
Unicode和UTF-8
为了统一全世界各国语言文字和专业领域符号(例如数学符号、乐谱符号)的编码,ISO制定了ISO 10646标准,也称为UCS(Universal Character Set)。UCS编码的长度是31位,可以表示231个字符。如果两个字符编码的高位相同,只有低16位不同,则它们属于一个平面(Plane),所以一个平面由216个字符组成。目前常用的大部分字符都位于第一个平面(编码范围是U-00000000~U-0000FFFD),称为BMP(Basic Multilingual Plane)或Plane 0,为了向后兼容,其中编号为0~256的字符和Latin-1相同。UCS编码通常用U-xxxxxxxx这种形式表示,而BMP的编码通常用U+xxxx这种形式表示,其中x是十六进制数字。在ISO制定UCS的同时,另一个由厂商联合组织也在着手制定这样的编码,称为Unicode,后来两家联手制定统一的编码,但各自发布各自的标准文档,所以UCS编码和Unicode码是相同的。
有了字符编码,另一个问题就是这样的编码在计算机中怎么表示。现在已经不可能用一个字节表示一个字符了,最直接的想法就是用四个字节表示一个字符,这种表示方法称为UCS-4或UTF-32,UTF是Unicode Transformation Format的缩写。一方面这样比较浪费存储空间,由于常用字符都集中在BMP,高位的两个字节通常是0,如果只用ASCII码或Latin-1,高位的三个字节都是0。另一种比较节省存储空间的办法是用两个字节表示一个字符,称为UCS-2或UTF-16,这样只能表示BMP中的字符,但BMP中有一些扩展字符,可以用两个这样的扩展字符表示其它平面的字符,称为Surrogate Pair。无论是UTF-32还是UTF-16都有一个更严重的问题是和C语言不兼容,在C语言中0字节表示字符串结尾,库函数strlen、strcpy等等都依赖于这一点,如果字符串用UTF-32存储,其中有很多0字节并不表示字符串结尾,这就乱套了。
我是想把文本保存成Unicode的编码 不是保存成utf-8. 你的方法只能转成utf-8的。
追答UTF-8是将字符对应的unicode十六进制进行存储,存储的字节可能是1、2、3、4个字节。它是Unicode的实现方式之一,其它还有UTF-16、UTF-32
追问
那文本另存为 显示的unicode 他是utf-多少的? 我被你说糊涂了。
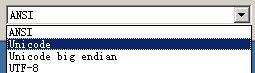
function Utf8ToUnicode(Dest: PWideChar; Source: PChar; MaxChars: Integer): Integer;
追问你说的好像不是我想要的结果。Utf8ToUnicode 返回的是integer类型的。。
我想实现的就是D9以后的这个种效果
sl.SaveToFile(dlgSave1.FileName, TEncoding.Unicode);
把内容以unicode编码的形式存储。
以上是关于怎样查一个字符的unicode编码的主要内容,如果未能解决你的问题,请参考以下文章