linux kernel 文件系统编程接口
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux kernel 文件系统编程接口相关的知识,希望对你有一定的参考价值。
参考技术A进程读写文件之前需要 打开文件 ,得到 文件描述符 ,然后 通过文件描述符读写文件 .
内核提供了两个打开文件的系统调用 open 和 openat .
打开文件的主要步骤如下:
(1)需要 在父目录的数据中查找文件对应的目录项 , 从目录项得到索引节点的编号,然后在内存中创建索引节点的副本 .因为各种文件系统类型的物理结构不同,所以需要提供索引节点操作集合的 lookup 方法和文件操作集合的 open 方法.
(2)需要分配文件的一个打开实例-- file 结构体,关联到文件的索引节点.
(3)在进程的打开文件表中 分配一个文件描述符 , 把文件描述符和打开实例的映射添加到进程的打开文件表 中.
进程可通过使用系统调用 close 关闭文件.
系统调用close的执行流程如下:
(1)解除打开文件表和file实例的关联.
(2)在close_on_exec位图中清楚文件描述符对应的位.
(3)释放文件描述符,在文件描述符位图中清除文件描述符对应的位.
(4)调用函数fput释放file实例:把引用计数减1,如果引用计数是0,那么把file实例添加到链表delayed_fput_list中,然后调用延迟工作项delayed_fput_work.
延迟工作项delayed_fput_work的处理函数是flush_delayed_fput,遍历链表delayed_fput_list,针对每个file实例,调用函数__fput来加以释放.
创建不同类型的文件,需要使用不同的命令.
(1) 普通文件 :touch FILE ,这条命令本来用来更新文件的访问时间和修改时间,如果文件不存在,创建文件.
(2) 目录 :mkdir DIRECTORY .
(3) 符号链接(软链接) :ln -s TARGET LINK_NAME 或ln --symbolic TARGET LINK_NAME .
(4) 字符或块设备文件 :mknod NAME TYPE [MAJOR MINOR] .
(5) 命名管道 :mkpipe NAME .
(6) 硬连接 :命令"ln TARGET LINK_NAME ".给已经存在的文件增加新的名称,文件的索引节点有一个硬链接计数,如果文件有n个名称,那么硬链接计数是n.
创建文件需要在文件系统中 分配一个索引节点 ,然后 在父目录的数据中增加一个目录项来保存文件的名称和索引节点编号 .
删除文件的命令如下:
(1)删除任何类型文件:unlink FILE .
(2)rm FILE ,默认不删除目录,如果使用"-r""-R"或"-recursive",可以删除目录和目录的内容.
(3)删除目录:rmdir DICTIONARY .
内核提供了unlink,unlinkat用来删除文件的名称,如果文件的硬链接计数变成0,并且没有进程打开这个文件,那么删除文件.提供了rmdir删除目录.
删除文件需要从父目录的数据中删除文件对应的目录项, 把文件的索引节点的硬链接计数减1(一个文件可以有多个名称,Linux把文件名称称为硬链接),如果索引节点的硬链接计数变成0,那么释放索引节点 .因为各种文件系统的物理结构不同,所以需要提供索引节点操作集合的 unlink 方法.
设置文件权限的命令如下:
(1)chmod [OPTION]... MODE[, MODE]... FILE...
mode : 权限设定字串,格式[ugoa...][[+-=][rwxX]...][,...]
其中:
(2)chmod [OPTION]... OCTAL-MODE FILE...
参数OCTAL-MODE是八进制数值.
系统调用chmod负责修改文件权限.
修改文件权限需要修改文件的索引节点的文件模式字段,文件模式字段包含文件类型和访问权限.因为各种文件系统类型的索引节点不同,所以需要提供索引节点操作集合的 setattr 方法.
访问外部存储设备的速度很慢,为了避免每次读写文件时访问外部存储设备, 文件系统模块为每个文件在内存中创建一个缓存 ,因为 缓存的单位是页 ,所以称为 页缓存 .
(1) 索引节点的成员i_mapping 指向地址空间结构体(address_space).进程在打开文件的时候, 文件打开实例(file结构体)的成员f_mapping 也会指向文件的地址空间.
(2)每个文件有一个地址空间结构体 address_space ,成员 page_tree 的类型是结构体radix_tree_root:成员 gfp_mask是分配内存页的掩码,成员rnode指向基数树的根节点 .
(3)使用基数树管理页缓存,把文件的页索引映射到内存页的页描述符.
每个文件都有一个地址空间结构体address_space,用来建立数据缓存(在内存中为某种数据创建的缓存)和数据来源(即存储设备)之间的关联.结构体address_space如下:
地址空间操作结合address_space_operations的主要成员如下:
页缓存的常用操作函数如下:
(1)函数find_get_page根据文件的页索引在页缓存中查找内存页.
(2)函数find_or_create_page根据文件的页索引在页缓存中查找内存页,如果没有找到内存页,那么分配一个内存页,然后添加到页缓存中.
(3)函数add_to_page_cache_lru把一个内存页添加到页缓存和LRU链表中.
(4)函数delete_from_page_cache从页缓存中删除一个内存页.
进程读文件的方式有3种:
(1)调用内核提供的 读文件的系统调用 .
(2)调用glibc库封装的读文件的 标准I/O流函数 .
(3)创建基于文件的内存映射,把 文件的一个区间映射到进程的虚拟地址空间,然后直接读内存 .
第2种方式在用户空间创建了缓冲区,能减少系统调用的次数,提高性能.第3种方式可以避免系统调用,性能最高.
读文件的主要步骤如下:
(1)调用具体文件系统类型提供的文件操作集合的read和read_iter方法来读文件.
(2) read或read_iter方法根据页索引在文件的页缓存中查找页,如果没有找到,那么调用具体文件系统类型提供的地址空间集合的readpage方法来从存储设备读取文件页到内存中 .
为了提高读文件的速度,从存储设备读取文件页到内存中的时候,除了读取请求的文件页,还会预读后面的文件页.如果进程按顺序读文件,预读文件页可以提高读文件的速度;如果进程随机读文件,预读文件页对提高读文件的速度帮助不大.
进程写文件的方式有3种:
(1)调用内核提供的 写文件的系统调用 .
(2)调用glibc库封装的写文件的 标准I/O流函数 .
(3)创建基于文件的内存映射,把 文件的一个区间映射到进程的虚拟空间,然后直接写内存 .
第2种方式在用户空间创建了缓冲区,能够减少系统调用的次数,提高性能.第3种方式可以避免系统调用,性能最高.
写文件的主要步骤如下:
(1)调用具体文件系统类型提供的文件操作集合的write或write_iter方法来写文件.
(2)write或write_iter方法调用文件的地址空间操作集合的 write_begin 方法, 在页缓存查找页,如果页不存在就分配页;然后把数据从用户缓冲区复制到页缓存的页中 ;最后调用文件的地址空间操作集合的 write_end 方法.
进程写文件时,内核的文件系统模块把数据写到文件的页缓存,没有立即写回到存储设备.文件系统模块会定期把脏页写回到存储设备,进程也可以调用系统调用把脏页强制写回到存储设备.
管理员可以执行命令"sync",把内存中所有修改过的文件元数据和文件数据写回到存储设备.
内核提供了 sync , syncfs , fsync , fdatasync , sync_file_range 等系统调用用于文件写回.
把文件写回到存储设备的时机如下:
(1)周期回写.
(2)当脏页的数量达到限制的时候,强制回写.
(3)进程调用sync和syncfs等系统调用.
对于类似内存的块设备,例如NVDIMM设备,不需要把文件从存储设备复制到页缓存.DAX绕过页缓存,直接访问存储设备,对于基于文件的内存映射,直接把存储设备映射到进程的虚拟地址空间.
调用系统调用mmap创建基于文件的内存映射,把文件的一个区间映射到进程的虚拟地址空间,这会调用具体文件系统类型提供的文件操作集合的mmap方法.mmap方法针对设置了标志位S_DAX的索引节点,处理方法如下:
(1)给虚拟内存区域设置标志位VM_MIXEDMAP和VM_HUGEPAGE.
(2)设置虚拟内存操作集合,提供fault,huge_fault,page_mkwrite和pfn_mkwrite方法.
Linux系统编程:基础IO 上简单复习C语言文件接口 | 学习系统文件接口 | 认识文件描述符 | Linux下,一切皆文件 | 重定向原理
文章目录
写在前面
关于进程,我们还要再往下学习进程间通信、进程信号,但是在这之前,我们先学习基础 IO,这篇文章穿插在进程中并不奇怪,因为它有着承上启下的作用。
-
文件的宏观理解
那么文件在哪呢 ?—— 广义上理解,键盘、显示器等都是文件,因为我们说过 “ Linux 下,一切皆文件 ”,当然我们现在对于这句话的理解是片面的;狭义上理解,文件在磁盘上,磁盘是一种永久存储介质,不会受断电的影响,磁盘也是外设之一,所以对文件的所有操作,都是对外设的输入输出,简称 IO(Input、Output)。
-
文件的组成
当我们在 Windows 下新建一个文本文件,它是否占用磁盘空间 ?—— 虽然它是一个空的文本文件,并且这里显示是 0KB,但是它依旧会占用磁盘空间,因为一个文件新建出来,它有很多数据信息都需要维护,包括文件名、修改日期、类型、大小、权限等。
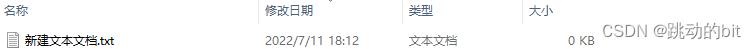
而当我们对空文本写入字符时,这里可以直观的看到文本的大小由 0KB 到 1KB。
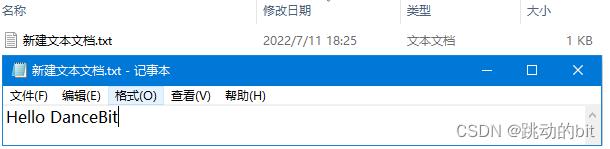
所以说一个文件 = 属性(元数据) + 内容,也就是说我们要学习的所有的文件操作,无外乎就是对文件的属性和内容操作。比如说之前所学的 fread、fwrite、fgets、fputs、fgetc、fputc 是对文件的内容操作;fseek、ftell、rewind 是对文件的属性操作;
-
系统看待文件操作
我们以前写的 fread、fwrite 等对文件操作的 C 程序 ➡ 经过编译形成可执行程序 ➡ 双击或 ./ 运行程序,把程序加载到内存。所以对文件的操作本质就是进程对文件的操作。
我们在操作文件时所使用到的接口,如 fread、fwrite,这是 C 语言提供的接口,而要操作的文件是在磁盘这个硬件上,同时我们很明确磁盘的管理者是操作系统,用户不可能直接去访问硬件,在计算机体系结构中我们知道用户是通过 C 语言所提供的这些接口来贯穿式的访问硬件(用户 ➡ 库函数 ➡ 系统调用接口 ➡ 操作系统 ➡ 驱动程序 ➡ 硬件)。所以本质并不是 C 语言帮我们把数据写到磁盘文件中,C 语言只提供方便用户使用的接口,真正干活的是操作系统所提供的文件相关的系统调用接口。
所以基础 IO 系列文章中主要学的是进程和系统调用接口这两个角度看待文件的方式。
一、简单复习文件操作
💦 写文件
#include<stdio.h>
int main()
FILE* fp = fopen("./log.txt", "w");//以写的方式打开当前目录下的log.txt文件,没有就新建文件,如果目标文件存在,w写时会清空目标文件
//FILE* fp = fopen("log.txt", "w");//没有./,它默认是在当前路径下新建文件
if(fp == NULL)
perror("fopen");
return 1;
int count = 0;
while(count < 10)
fputs("hello DanceBit\\n", fp);//往log.txt文件中写数据
count++;
fclose(fp);//关闭文件
return 0;
-
FILE* fp = fopen(“log.txt”, “w”);
虽然没有 ./ 指定路径,但是它还是在当前路径下新建文件了,因为每个进程都有一个内置的属性 cwd(可以在 /proc 目录下查找对应进程的属性信息),cwd 可以让进程知道自己当前所处的路径,这也解释了在 VS 中不指明路径,它也能新建对应的文件在对应的路径,换言之,进程在哪个路径运行,文件的新建就哪个路径。
这里把 ctrl_file 可执行程序移动到上级路径,此时在上级路径下 ./ctrl_file 后,就可以看到新建的文件夹与可执行程序在同一路径。

💦 读文件
#include<stdio.h>
int main()
FILE* fp = fopen("./log.txt", "r");//以读的方式打开当前目录下的log.txt文件,没有就报错
if(fp == NULL)
perror("fopen");
return 1;
int count = 0;
char buffer[128];
while(count < 10)
fgets(buffer, 128, fp);//从log.txt文件中读128个字符到buffer,\\n会使fgets停止读取
printf("%s\\n", buffer);
count++;
fclose(fp);//关闭文件
return 0;
💦 追加文件
#include<stdio.h>
#include<string.h>
int main()
FILE* fp = fopen("./log.txt", "a");//以追加的打开当前目录下的log.txt文件,没有就新建,如果目标文件存在,a写时不会清空目标文件,在文件内容最后写入
if(fp == NULL)
perror("fopen");
return 1;
const char* msg = "Hello DanceBit\\n";
//fwrite(msg, strlen(msg) + 1, 1, fp);//乱码
fwrite(msg, strlen(msg), 1, fp);
fclose(fp);
return 0;
-
size_t fwrite ( const void* ptr, size_t size, size_t count, FILE* stream );
size 表示你要写入的基本单元是多大(以字节为单位),count 表示你要写入几个这样的基本单元。换言之,最终往文件中写的字节数是 = size * count,比如要写入 10 个字节,那么 size = 1 && count = 10、size = 2 && count = 5,不过一般建议把 size 写大点,count 写小点。
fwrite 的返回值是成功写入元素的个数,也就是期望写 count 个,每个是 size,那么实际返回的是你实际写入成功了几组 size,比如你期望 size 是 10,count 是 1,大部分情况下都会把这 1 个单元都写入的,写入成功,返回值是 1;这里的你期望写入多少和实际写入多少,好比:
你:爸,我要 10 块钱。(这是你期望的)
爸:我只有 5 块钱,给你 3 块钱吧。(这是实际的)
当然,这里是网络部分才会涉及到的,目前在往磁盘文件中写入时,大部分情况下,硬件设备是能满足你的要求的,所以我们这里不关心 fwrite 的返回值。 -
fwrite(msg, strlen(msg) + 1, 1, fp);
strlen(msg) + 1 -> 乱码,也就是把 \\0 也追加会造成,因为 \\0 是 C 的规定,和文件无关。这里 cat log.txt 并没有看到乱码的原因是 \\0 是不可见的,所以这里 vim log.txt 才可以看到乱码。
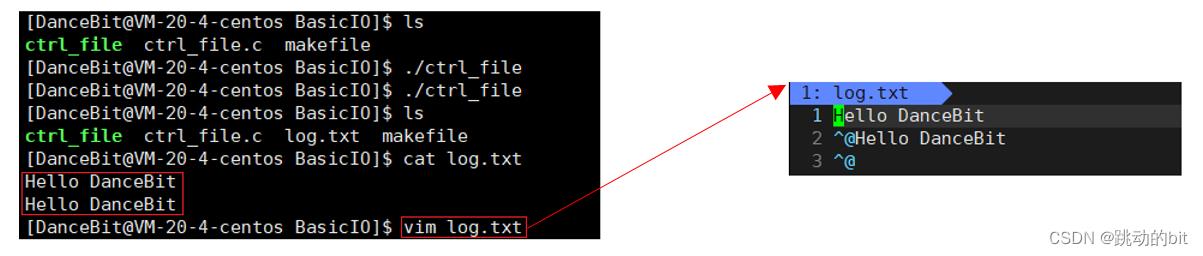
💦 理解 “ Linux 下,一切皆文件 ”
-
这里我们就要校准一个概念,不是任何 C 程序运行会默认打开,而是进程在启动时,会默认三个 “ 文件 ”,分别是标准输入(stdin)、标准输出(stdout)、标准错误(stderr)。这里可以看到它们三个的类型与用于接收 fopen 的返回值类型是一样的。

-
默认情况下,标准输入是键盘文件,标准输出是显示器文件,标准错误是显示器文件。而这三个本身是硬件,如何理解 Linux 中,一切皆文件❓
所有的外设硬件,本质对应的核心操作无外乎是 read 或 write。对于键盘文件,它的读方法就是从键盘读取数据到内存;它的写方法设置为空,因为没有把数据写到键盘上这种说法。
对于显示器文件,如调用 printf 函数时,操作系统是要往显示器上写入的;理论上操作系统是不会往显示器上读数据的,所以设置为空?不对呀,我们在命令行输入命令显示在 Xshell 上,系统要执行命令时不就是往显示器上读吗?—— 如果是往显示器上读,那么你在输入密码时,密码是不显示的,系统也能往显示器上读吗。其实你输入的命令是你通过键盘输入的,所以系统应该是往键盘读数据。至于用户能看到输入的命令,仅仅是为了方便用户,操作系统把从键盘输入的数据,一方面给了系统读取,一方面给显示器方便用户。
所以不同的硬件,对应的读写方式肯定是不一样的,但是它们都有 read 和 write 方法,换言之,这里的硬件可以统一看作一种特殊的文件。比如这里设计一种结构叫做 struct file,它包括文件的属性、文件的操作或方法等,Linux 说一切皆文件,Linux 操作系统就必须要保证这点。在 C 语言中,怎么让一个结构体既有属性,也有方法呢?—— 函数指针。此时每一个硬件都对应这样一个结构,硬件一多,操作系统要对它们进行管理 —— 六字箴言,先描述,在组织。所谓的描述就是 struct file;组织就是要把每一个硬件对应的结构体关联起来,并用 file header 指向。所以在操作系统的角度,它看到的就是一切皆文件,也就是说所有硬件的差异,经过描述,就变成了同一种东西,只不过当具体访问某种设备时,使用函数指针执行不同的方法,就达到了不同的行为。现在就能理解为什么可以把键盘、显示器当作文件,因为本质不同设备的读写方法是有差异的,但我们可以通过函数指针让不同的硬件包括普通文件在操作系统看来是同样的方法、同样的文件。
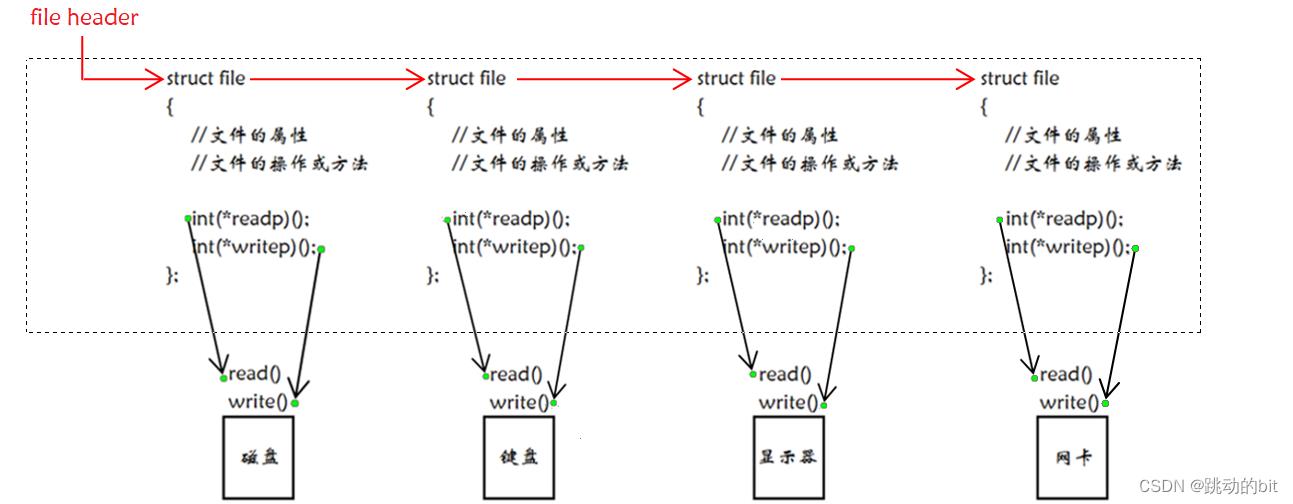
#include<stdio.h>
#include<string.h>
int main()
const char* msg = "Hello DanceBit\\n";
fwrite(msg, strlen(msg), 1, stdout);
char buffer[64];
fread(buffer, 1, 10, stdin);//你输入时没有写\\0,fread时也不会加,所以一旦超过10,就会出现乱码
buffer[10] = '\\0';
printf("%s\\n", buffer);
return 0;
-
这里可以直接使用 fwrite 这样的接口,向显示器写数据的原因是因为 C 程序一运行,stdout 就默认打开了。同理 fread 能从键盘读数据的原因是 C 程序一运行,stdin 就默认打开了。
-
也就是说 C 接口除了对普通文件进行读写之外(需要打开),还可以对 stdin、stdout、stderr 进行读写(不需要打开)。
为什么 C 程序运行,就会默认打开 stdin、stdout、stderr?仅仅是 C 吗 ❓
scanf -> 键盘、printf -> 显示器、perror -> 显示器,换言之,如果不打开,那么作为程序员是不能直接调用这些接口的,所以默认打开的原因是便于程序员直接上手,且大部分编码都会有输入输出的需求。也就是说 scanf、printf、perror 这样的库函数,底层一定使用了 stdin、stdout、stderr 文件指针来完成不同的功能。此外还有些接口和 printf、scanf 很像,它本身是把使用的过程暴露出来,比如 fprintf(stdout, “%d, %d, %c\\n”, 12, 24, b)。

这里可以否定的,C 程序运行才会打开 stdin、stdout、stderr。而几乎所有语言都是这样的,C++ 中是 cin、cout、cerr,所以你会发现一个现象,不管是学习啥语言,第一个程序永远是 Hello World!。这里说几乎所有语言都这样的,意味着不仅仅是语言层提供的功能了,比如一条人山人海的路从头到尾只有个别商贩在摆摊,那么我们认为这是商贩的个人行为,当地的管理者是排斥这种行为的;但如果一条人山人海的路从头到尾都有商贩在摆摊,那么我们认为当地的管理者是支持这种行为的;同样不同语言彼此之间没有进行过任何商量,而最终都会默认打开,所以这不仅仅是语言支持的,也一定是操作系统支持的,一会再细谈。
二、系统文件I/O
💦 为什么要学习文件系统接口
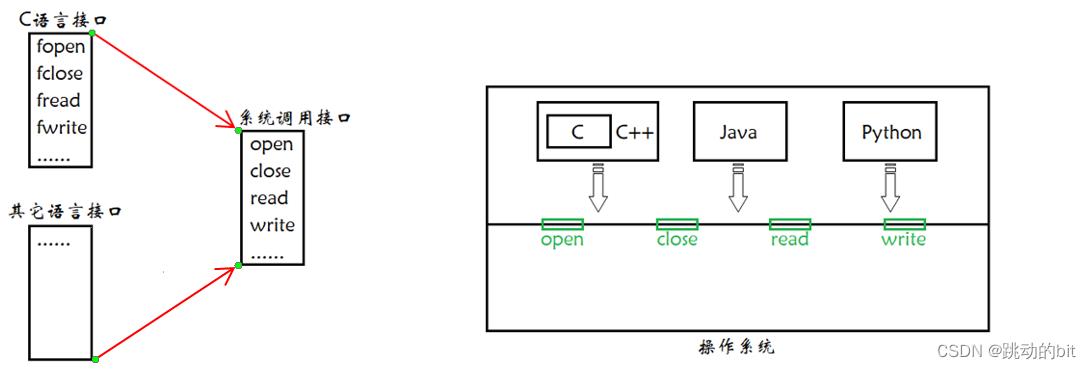
根据之前所说,在 C 语言中要访问硬件,必须贯穿计算机体系结构,而 fopen、fclose 等系列的库函数,其底层都要调用系统接口,这里它们对应的系统接口也很好记 —— 去掉 " f " 即为系统接口。不同语言所提供的接口本质是对系统接口封装,学习封装的接口本质学的就是语言级别的接口,换言之要学习不同的语言,就得会不同语言操作文件的方法,但实际上对特定的操作系统,最终都会调用系统提供的接口。
所以接下来我们当然是要学习系统接口,我们要学习它的原因主要有两点:其一,只要把它学懂了,以后学习其它语言上的文件操作,只是学习它的语法,底层就不用学习了;其二,这些系统接口,更贴近于系统,所以我们就能通过接口,来学习文件的若干特性。
💦 测试用例一
#include<stdio.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
int main()
int fd = open("log.txt", O_WRONLY|O_CREAT, 0644);//打开
if(fd < 0)
perror("open");
return 1;
//操作
const char* msg = "Hello System Call!\\n";
write(fd, msg, strlen(msg));
write(fd, msg, strlen(msg));
write(fd, msg, strlen(msg));
write(fd, msg, strlen(msg));
close(fd);//关闭
return 0;
-
使用 open 需要包含三个头文件,它有两个版本。版本一:以 flags 方式打开 pathname;版本二:以 flags 方式打开 pathname,并设置 mode 权限。

flags 可以是 O_RDONLY(read-only)、O_WRONLY(write-only)、O_RDWR(read/write),且必须包含以上访问模式之一。此外访问模式还可以带上 |标志位,下面会介绍一两个标志位,实际还要看场景使用。

-
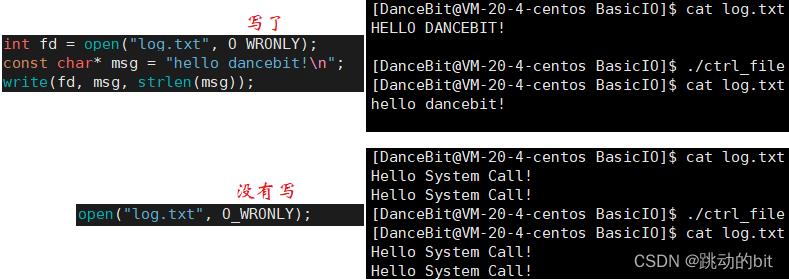
open(“log.txt”, O_WRONLY);
以写的方式打开一个存在的文件,它同 fopen 一样,如果没有写操作,原文件的内容不会被覆盖;如果写操作,原文件的内容会被覆盖成写的内容。
-
open(“log.txt”, O_WRONLY, 0644);
以写的方式打开不存在的文件,权限是 644,运行程序发现没有新建文件 。

这里我们看到概要,我们发现 open 的返回值不是 FILE*,而是 int,接着我们再看下返回值说明,它说 open 会返回一个新的文件描述符(file descriptor),如果打开失败,返回 -1。在 C 语言中我们把 FILE* 称为文件指针,FILE* 和 file descriptor 必然有联系,下面再谈。

我们发现它的返回值是 -1,所以这里打开文件失败了。

O_CREATE 发现文件不存在,将会新建文件,且必须指定 mode 权限(如果没有指定,那么新建的文件会变成可执行程序),如果没有 O_CREATE,说明文件是存在的,则可忽略 mode 权限(就算写了权限也不会对原来的文件更改权限)。


-
open(“log.txt”, O_WRONLY|O_CREAT, 0644);
很明显,它和 fopen 不一样,fopen 如果以写的方式打开,文件不存在,则会新建文件,而这里的 open 想做到类似的效果,需要带上 O_CREAT 标志位。这里我们运行程序,发现文件描述符是 3,说明文件打开成功,而且权限被设置成了 644。

C 接口对比系统接口 ❗
fopen 的底层一定调用 open 的,系统是怎么保证这里如果没有目标文件,会自动新建呢?—— w 的底层就是 O_WRONLY|O_CREAT;另外 fopen 默认创建文件的权限是系统默认的;关于 fopen 和 open 的返回值类型为什么是 FILE* 和 int 一会再谈。

-
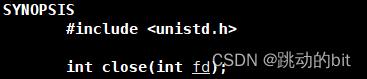
使用 close 关闭文件,需要包含 unistd 头文件。fd 是 open 的返回值。
-
使用 write 写入文件,需要包含 unistd 头文件。write 向 fd 文件描述符中写入 buf,写 count 个字节,返回值是写了多少个。

💦 测试用例二
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
int main()
int fd = open("log.txt", O_RDONLY);//打开
if(fd < 0)
perror("open");
return 1;
//操作
char buffer[1024];
ssize_t sz = read(fd, buffer, sizeof(buffer) - 1);//期望读1023个,但实际可能只有100个,是从文件读,文件并不遵守字符串\\0的规则,所以要主动\\0
if(sz > 0)
buffer[sz] = '\\0';//利用read的返回值,实际读到的个数就是该被\\0的位置
printf("%s\\n", buffer);
close(fd);//关闭
return 0;
-
要使用 read 读文件,需要包含 unistd 头文件。read 从 fd 文件描述符中读数据到 buf,读 count 个字节,返回值是实际读到的数据。

💦 测试用例三
#include<string.h>
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
int main()
int fd = open("log.txt", O_WRONLY|O_APPEND);//打开
if(fd < 0)
perror("open");
return 1;
//操作
const char* msg = "Hello System Call!\\n";
write(fd, msg, strlen(msg));
write(fd, msg, strlen(msg));
close(fd);//关闭
return 0;
-
open(“log.txt”, O_WRONLY|O_APPEND);
以写的方式追加一个存在的文件。

💦 标志位
为什么传两个标志位时需要使用 ‘ | ’ 操作符 ❓
O_WRONLY、 O_RDONLY、O_CREATE、O_APPEND 都是标志位。如果我们自己在设计 open 接口时,这里通常是使用整数,0 表示不要,1 表示要。而系统是怎么做的呢?—— 一个整数有 32 个比特位,所以一个标志位传一个整数是有点浪费的,所以这里可以用最低比特位表示是否读、第二低比特位表示是否写、第三低比特位表示是否追加等等,之后这里我们可以定义一些宏来,将来传入了 flags,系统要检测是什么标志位,它只需要 falgs & O_RDONLY,这也解释了为什么上面需要两个标志位时是 O_WRONLY|O_APPEND。

grep -ER 'O_CREAT|O_RDONLY' /usr/include/筛选标志位。
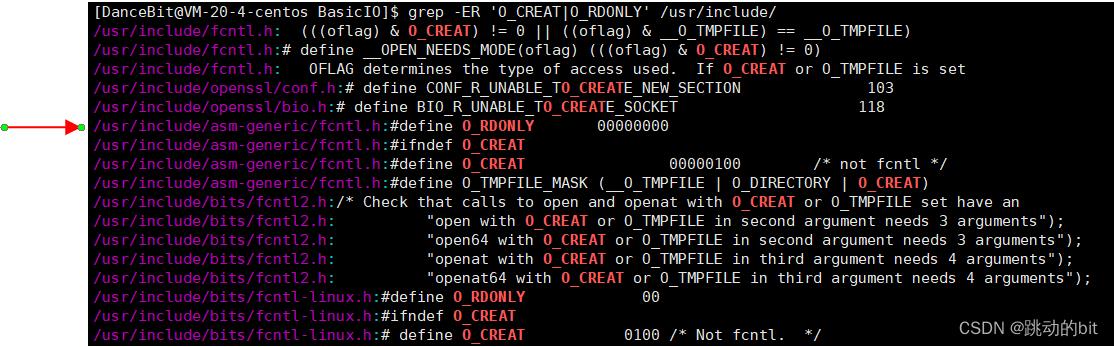
接着我们 vim 标志位所在路径,发现默认是只读,而 O_CREAT 以下是使用了八进制,不管如何,它们经过转换后,最终只有一个唯一比特位。我们也可以通过组合标志位,传入多个选项。
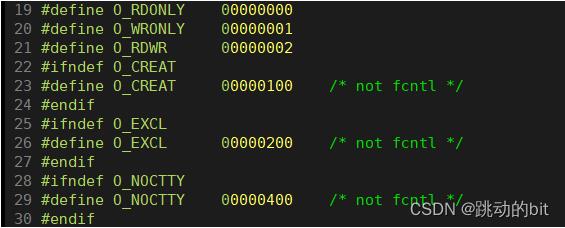
这里语言都要对系统接口做封装,本质是对兼容自身语法特性,系统调用使用成本较高,而且不具备可移植性,如果所有语言都用 open 这一套接口, 那么这套接口在 windows 下是不能运行的,所以你写的程序是不具备可移植性的,而 fopen 能在 Windows 和 Linux 下运行的原因是 C 语言对 open 进行了封装,也就是说这些接口会自动根据平台,选择底层对应的文件接口, 同样的 fopen,它在 Windows 和 Linux 中头文件的实现是不同的 。
💦 open的返回值
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int main()
int fd1 = open("log1.txt", O_WRONLY|O_APPEND|O_CREAT, 0644);
int fd2 = open("log2.txt", O_WRONLY|O_APPEND|O_CREAT, 0644);
int fd3 = open("log3.txt", O_WRONLY|O_APPEND|O_CREAT, 0644);
int fd4 = open("log4.txt", O_WRONLY|O_APPEND|O_CREAT, 0644);
int fd5 = open("log5.txt", O_WRONLY|O_APPEND|O_CREAT, 0644);
printf("fd1: %d\\n", fd1);
printf("fd2: %d\\n", fd2);
printf("fd3: %d\\n", fd3);
printf("fd4: %d\\n", fd4);
printf("fd5: %d\\n", fd5);
return 0;

我们说过返回小于 0 的数,则代表 open 失败,显示这里 open 都成功了。但是这里为什么不从 0 开始依次返回?—— 上面我们说过 C 程序运行起来,默认会打开三个文件(stdin、stdout、stderr),所以 0, 1, 2 分别与之对应。
为什么这里每打开一个文件所返回的文件描述符是类似数组下标的呢?—— 这里返回的文件描述符就是数组下标。一个进程是可以打开多个文件的,且系统内被打开的文件,一定是有多个的,那么这些多个被打开的文件,操作系统使用 “ 先描述,后组织 ” 的方式管理起来,描述一个打开文件的数据结构叫做 struct file,组织一堆 struct file 就是在 task_struct 中有一个 struct files_struct* files 指针,指向 struct files_struct,它的作用就是构建进程和文件之间的对应关系,其中包含了一个指针数组,这里我们可以理解为定长数组,struct file* fd_array[NR_OPEN_DEFAULT] ➡ #define NR_OPEN_DEFAULT BITS_PER_LONG ➡ #define BITS_PER_LONG 32。所以用户层看到的 fd 返回值,本质是系统中维护进程和文件对应关系的数组的下标。比如创建一个文件,会多一个 struct file,再把地址存储于指针数组中最小的且没有使用过的数组中,这里对应是 6 下标,然后把 6 作为返回值,返回给用户,所以当用户后续要对文件进行操作时就可以使用 fd 返回值作为参数,比如 read(fd) ,当前进程就会拿着 fd 去 struct files_struct* 指向的指针数组中找 fd 下标,根据 fd 下标对应的地址找到对应的文件,再在文件中找到对应的 read 方法,对 disk 中的数据进行读取。

Linux 2.6 内核源码验证:
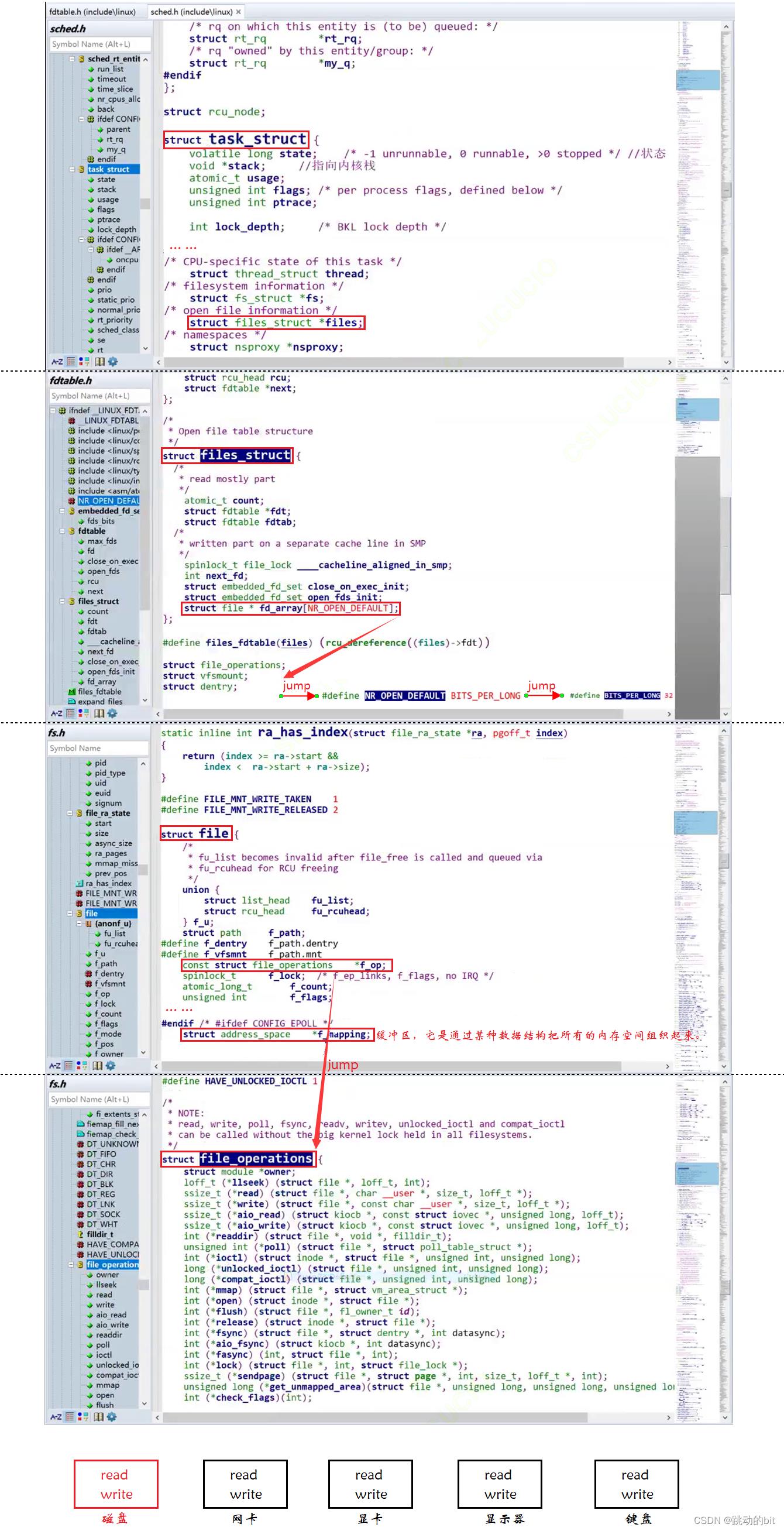
对于 file_operations,不同硬件是有不同的方法的,大部分情况方法是和你的硬件驱动匹配的,虽然如此,但是最终文件通过函数指针实现你要打开的是磁盘,那就让所有的方法指向磁盘的方法,你要打开的是其它硬件,那就让所有的方法指向其它硬件的方法,而这里底层的差异,在上层看来,已经被完全屏蔽了。所以对进程来讲,对所有的文件进行操作,统一使用一套接口(现在我们明确了它是一组函数指针),换言之,对进程来说,你的操作和属性接口统一使用 struct file 来描述,所以在进程看来,就是 “ 一切皆文件 ”。
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
int main()
//close(0);
//close(1);
int fd1 = open("log.txt", O_CREAT|O_WRONLY, 0644);
int fd2 = open("log.txt", O_CREAT|O_WRONLY, 0644);
printf("hello bit!: %d\\n", fd1);
printf("hello bit!: %d\\n", fd2);
//fflush(stdout);
close(fd1);
close(fd2);
return 0;
-
毫无疑问,这里 open 一个文件后的返回值是从 3 开始,但是这里进程一运行,close 0,此时再 open 一个文件后的返回值是 0,再 open 一个文件后的返回值是 3,从这里我们就可以知道,系统中,分配文件描述符的规则是按最小的,且没有被使用的下标进行分配。
-
当我们 close 1,1 就不再指向显示器文件,此时 fd1 应该是 1,fd2 应该是 3,确实如此,然后再 printf 时,本来应该往显示器里写入,现在却往普通文件里写入,这种技术叫做输出重定向(echo “hello bit!” > temp.txt)。这里它输出重定向到了新打开的文件?—— 并没有,这里要先搞明白 fopen 和 open 之间的耦合关联。
这里可以看下 FILE 结构体是被 _IO_FILE typedef 的(typedef struct_IO_FILE FILE),_IO_FILE 在 /usr/include/libio.h 下,在 _IO_FILE 结构中包含两个重要的成员:
其一,底层对应的文件描述符下标 int _fileno,它是封装的文件描述符。换言之,在 C 的文件接口中,一定是使用 fileno 来调用系统接口 read(fp->fileno),所以 fopen 和 open 是通过 C 语言结构体内的文件描述符耦合的。
其二,应用层 C 语言提供的缓冲区。记得曾经写进度条时,没有 \\n,数据在缓冲区中不显示,必须以 fflush 强制刷新,其中数据所处的缓冲区就是由 __IO_FILE 维护的。
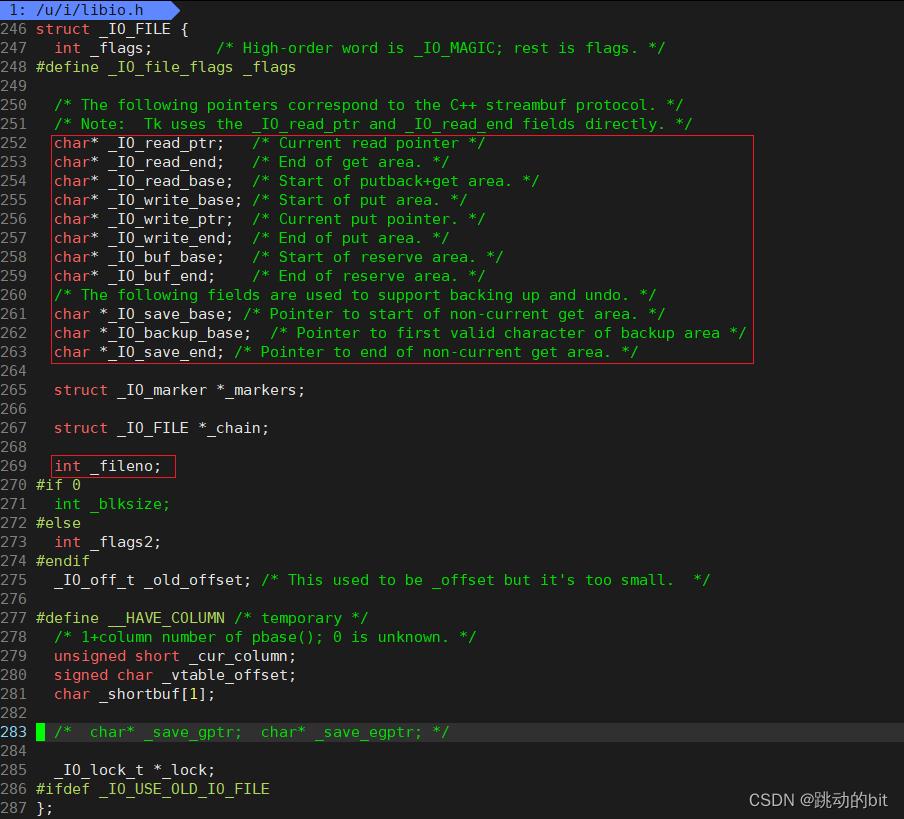
这里 close 1 后,1 下标就不再指向显示器文件,而是指向 log1.txt,FILE* stdout 当然还在,stdout 依然认为它的文件描述符值是 1,这里 printf 时会先把数据放到 C 语言提供的 __IO_FILE 缓冲区中,还没来得及刷新,已经把 fd1 关闭了,所以操作系统是没有办法由用户语言层刷新到操作系统底层的,所以自然也没看到结果。咦!这里不是有 \\n 吗,为什么没有往操作系统刷新,因为此时 1 指向的是磁盘文件,磁盘文件是全缓冲,必须等待缓冲区满了再刷新,或者 fflush 强制刷新。显示器文件,无论是用户层还是内核层,都是行刷新,因为它无论怎样,最终都会往显示器上刷新的。
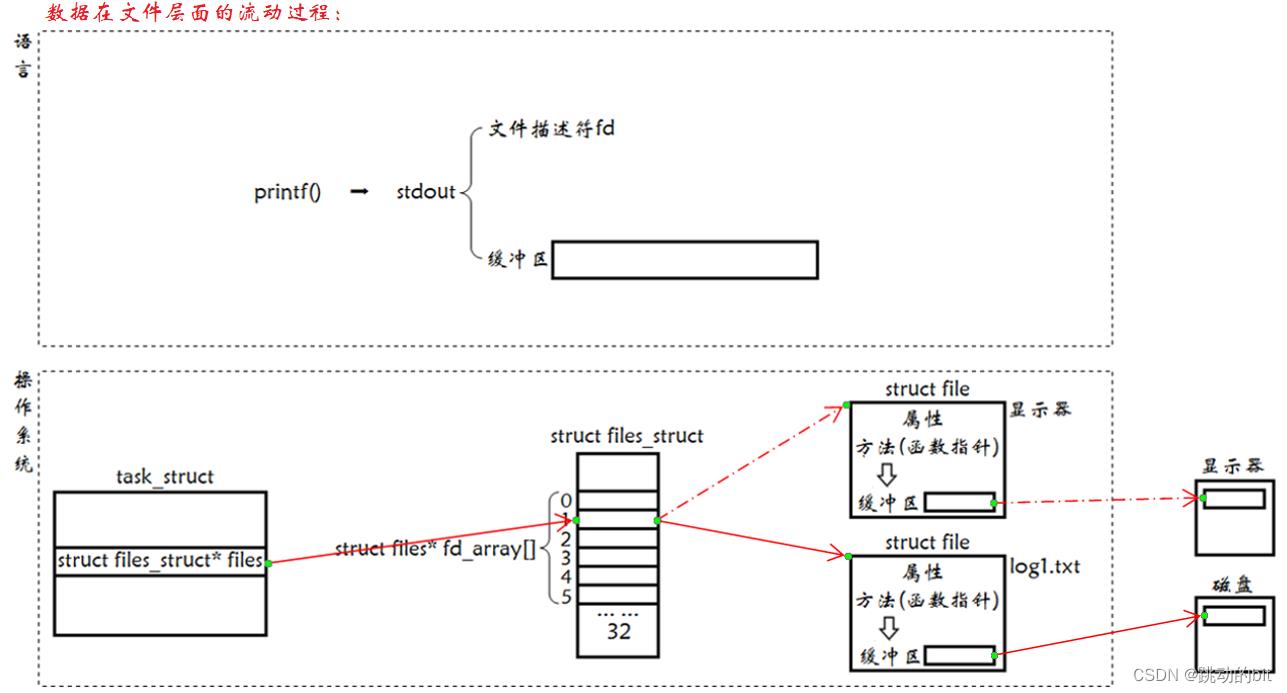
💦 重定向原理
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
int main()
//close(0);
close(1);
int fd1 = open("log1.txt", O_CREAT|O_WRONLY, 0644);
int fd2 = open("log2.txt", O_CREAT|O_WRONLY, 0644);
printf("hello bit!: %d\\n", fd1);
printf("hello bit!: %d\\n", fd2);
fflush(stdout);
close(fd1);
close(fd2);
return 0;
-
要想看到数据也
以上是关于linux kernel 文件系统编程接口的主要内容,如果未能解决你的问题,请参考以下文章
Linux系统编程:基础IO 上简单复习C语言文件接口 | 学习系统文件接口 | 认识文件描述符 | Linux下,一切皆文件 | 重定向原理
Linux系统编程:基础IO 上简单复习C语言文件接口 | 学习系统文件接口 | 认识文件描述符 | Linux下,一切皆文件 | 重定向原理
Linux系统编程:基础IO 壹简单复习C语言文件接口 | 学习系统文件接口 | 认识文件描述符 | Linux下,一切皆文件 | 重定向原理
Linux系统编程:基础IO 上简单复习C语言文件接口 | 学习系统文件接口 | 认识文件描述符 | Linux下,一切皆文件 | 重定向原理