cgroup 的整体结构
cgroup 是容器当中对资源进行限制的机制,完整的名称是叫 control group。经常提到的 hierarchy 对应的是一个层级,而subsystem 对应的是一个子系统,都是可以望文生意的。创建一个层级是通过挂载完成的,也就是说层级对应的是文件系统 root 目录的结构。
子系统目前有下列几种
- devices 设备权限
- cpuset 分配指定的 CPU 和内存节点
- cpu 控制 CPU 占用率
- cpuacct 统计 CPU 使用情况
- memory 限制内存的使用上限
- freezer 暂停 Cgroup 中的进程
- net_cls 配合 tc(traffic controller)限制网络带宽
- net_prio 设置进程的网络流量优先级
- huge_tlb 限制 HugeTLB 的使用
- perf_event 允许 Perf 工具基于 Cgroup 分组做性能检测
创建层级通过 mount -t cgroup -o subsystems name /cgroup/name,/cgroup/name 是用来挂载层级的目录(层级结构是通过挂载添加的),-o 是子系统列表,比如 -o cpu,cpuset,memory,name 是层级的名称,一个层级可以包含多个子系统,如果要修改层级里的子系统重新 mount 即可。子系统和层级之间满足几个关系。
- 同一个 hierarchy 可以附加一个或多个 subsystem
- 一个 subsystem 可以附加到多个 hierarchy,当且仅当这些 hierarchy 只有这唯一一个 subsystem
- 系统每次新建一个 hierarchy 时,该系统上的所有 task 默认构成了这个新建的 hierarchy 的初始化 cgroup,这个 cgroup 也称为 root cgroup。对于你创建的每个 hierarchy,task 只能存在于其中一个 cgroup 中,即一个 task 不能存在于同一个 hierarchy 的不同 cgroup 中,但是一个 task 可以存在在不同 hierarchy 中的多个 cgroup 中。如果操作时把一个 task 添加到同一个 hierarchy 中的另一个 cgroup 中,则会从第一个 cgroup 中移除
/proc/self 对应的是当前进程的 proc 目录,比如当前进程 pid 是1,那么/proc/1和/proc/self是等价的。运行man proc可以看到/proc/self/cgroup的解释。
/proc/[pid]/cgroup (since Linux 2.6.24)
This file describes control groups to which the process/task belongs. For each cgroup hierarchy there is one entry
containing colon-separated fields of the form:5:cpuacct,cpu,cpuset:/daemonsThe colon-separated fields are, from left to right:
1. hierarchy ID number 2. set of subsystems bound to the hierarchy 3. control group in the hierarchy to which the process belongsThis file is present only if the CONFIG_CGROUPS kernel configuration option is enabled.
这个展示的是当前进程属于的 control groups, 每一行是一排 hierarchy,中间是子系统,最后是受控制的 cgroup,可以通过这个文件知道自己所属于的cgroup。
cgroup 的创建
创建一个独立的 cgroup 则是在层级结构下面创建一个目录。
先看一下创建目录做了什么
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
static int cgroup_mkdir(struct inode *dir, struct dentry *dentry, int mode)
{
struct cgroup *c_parent = dentry->d_parent->d_fsdata;
/* the vfs holds inode->i_mutex already */
return cgroup_create(c_parent, dentry, mode | S_IFDIR);
}
static long cgroup_create(struct cgroup *parent, struct dentry *dentry,
mode_t mode)
{
/* 获取父cgroup对应的层级hierarchy */
/* 这里叫做 cgroupfs 其实是匹配的,因为创建 hierachy 就是 mount 了一个文件系统的动作 */
struct cgroupfs_root *root = parent->root;
/* 初始化一个cgroup结构 cgrp */
init_cgroup_housekeeping(cgrp);
cgrp->parent = parent; /* 设置父 cgroup */
cgrp->root = parent->root; /* 继承 parent 的 hierachy */
cgrp->top_cgroup = parent->top_cgroup; /* 继承父 parent 对应 hierachy 的root cgroup */
/* 继承父 parent 的 notify_on_release 设置 */
if (notify_on_release(parent))
set_bit(CGRP_NOTIFY_ON_RELEASE, &cgrp->flags);
/* 对所属的hierachy的子系统进行初始化 */
for_each_subsys(root, ss) {
struct cgroup_subsys_state *css = ss->create(ss, cgrp);
if (IS_ERR(css)) {
err = PTR_ERR(css);
goto err_destroy;
}
init_cgroup_css(css, ss, cgrp);
if (ss->use_id)
if (alloc_css_id(ss, parent, cgrp))
goto err_destroy;
/* At error, ->destroy() callback has to free assigned ID. */
}
/* 加入到父 cgroup 的子列表里 */
cgroup_lock_hierarchy(root);
list_add(&cgrp->sibling, &cgrp->parent->children);
cgroup_unlock_hierarchy(root);
/* 创建 cgroup 目录 */
cgroup_create_dir(cgrp, dentry, mode);
/* 创建目录下对应的文件,比如common的部分(tasks),或者子系统的部分(cpu.shares,freezer.state)*/
cgroup_populate_dir(cgrp);
|
看一下 cgroup_subsys_state->create 的实现,举个例子比如kernel/cpuset.c的cpuset子系统的创建。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
static struct cgroup_subsys_state *cpuset_create(
struct cgroup_subsys *ss,
struct cgroup *cont)
{
struct cpuset *cs;
struct cpuset *parent;
if (!cont->parent) {
return &top_cpuset.css;
}
parent = cgroup_cs(cont->parent);
cs = kmalloc(sizeof(*cs), GFP_KERNEL);
if (!cs)
return ERR_PTR(-ENOMEM);
if (!alloc_cpumask_var(&cs->cpus_allowed, GFP_KERNEL)) {
kfree(cs);
return ERR_PTR(-ENOMEM);
}
cs->flags = 0;
if (is_spread_page(parent))
set_bit(CS_SPREAD_PAGE, &cs->flags);
if (is_spread_slab(parent))
set_bit(CS_SPREAD_SLAB, &cs->flags);
set_bit(CS_SCHED_LOAD_BALANCE, &cs->flags);
cpumask_clear(cs->cpus_allowed);
nodes_clear(cs->mems_allowed);
fmeter_init(&cs->fmeter);
cs->relax_domain_level = -1;
cs->parent = parent;
number_of_cpusets++;
return &cs->css ;
}
|
其实就是一系列 cgroup 初始化动作,填充目录的部分作为接口留给子系统实现。
总结一下:
hierarchy 对应的是 cgroup 的一个根,拥有一个top_cgroup,之后 hierarchy 下面的目录(cgroup)都是继承这些内容。
真正起作用的入口其实是对文件的读写操作,关于这一块VFS的内容可以看一下我之前的博客,这也是由子系统实现的,接下来看看子系统的实现。
freezer 子系统
freeze tasks 的相关内容可以在内核文档当中找到,简单来说是为了提供一种机制能够让进程挂起。这些函数在电源控制里面有很多用到的地方,比如我们常说的挂起,就是让所有进程进入冬眠状态。
首先看这个子系统是因为它比较简单,属性比较少,实现的代码也比较少。
这里铺垫一些知识,说明内核是如何睡眠和唤醒进程的。
一般内核进程进入睡眠需要进入wait_queue,然后调用 schedule。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
/* wait 是我们想要让 task 睡眠的 queue entry, q 是等待队列 */
DEFINE_WAIT(wait);
/* 添加到等待队列中 */
add_wait_queue(q, &wait);
/*
* 这里要检查condition是因为可能在唤醒之后这个condition的条件又不成立了,
* 这个和条件变量一样,即使条件满足被wake up了,也可能被其他进程修改了该条件.
*/
while (!condition) {
prepare_to_wait(&q, &wait, TASK_INTERRUPTIBLE);
if (signal_pending(current))
/* 处理信号 */
/* 进行调度 */
schedule();
}
finish_wait(&g, &wait);
|
内核当中进入睡眠都是这个模板,这里的 schedule,会触发调度器遍历 scheduler class,选择优先级最高的调度类。
一般就是CFS(Complete Fair Scheduler),接下来会进行 context 切换,注意不是像一般理解的那样,函数调用增长栈空间,而是把栈和寄存器都换掉,刷掉缓存等等,由此进入另外一个进程的上下文。直到被唤醒从恢复保存的 IP 重新开始执行。
唤醒的过程则是,调用wake_up()函数把 task 的状态重新设置为 TASK_RUNNING,并且把task从等待队列移除。
它会使用 enqueue_task() 把任务从新加入到调度器中。如果是 CFS 调度器的话就是加入到红黑树中,当need_resched设置了的话会显式调用调用schedule()调度,不然还会继续执行唤醒者的上下文。
然后说一下Freezing of tasks,就是通过发送信号唤醒用户态的进程和内核进程,所有这些进程需要响应这个信号并且最后调用 refrigerator() 进入睡眠,也就上面的那个循环。
下图是进入冬眠进程的过程.
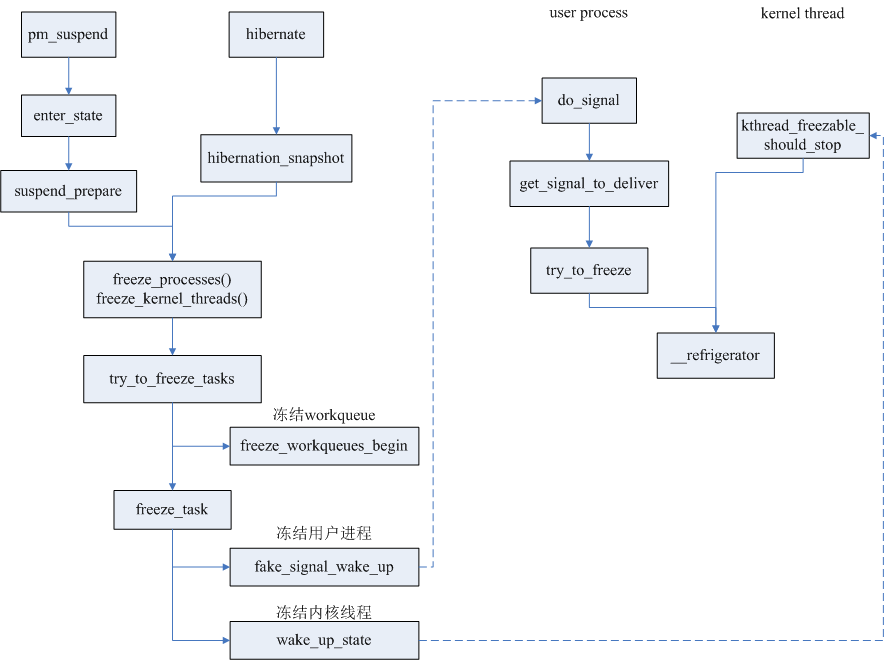
“冰箱”这个函数名称很形象,就是把当前 task 丢入睡眠状态直到解封。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
/* Refrigerator is place where frozen processes are stored :-). */
void refrigerator(void)
{
/* Hmm, should we be allowed to suspend when there are realtime
processes around? */
long save;
task_lock(current);
if (freezing(current)) {
frozen_process();
task_unlock(current);
} else {
task_unlock(current);
return;
}
save = current->state;
pr_debug("%s entered refrigerator
", current->comm);
spin_lock_irq(¤t->sighand->siglock);
recalc_sigpending(); /* We sent fake signal, clean it up */
spin_unlock_irq(¤t->sighand->siglock);
/* prevent accounting of that task to load */
current->flags |= PF_FREEZING;
for (;;) {
set_current_state(TASK_UNINTERRUPTIBLE);
if (!frozen(current))
break;
schedule();
}
/* Remove the accounting blocker */
current->flags &= ~PF_FREEZING;
pr_debug("%s left refrigerator
", current->comm);
__set_current_state(save);
}
|
所以 freezer subsystem 干的事情就是这样一件事情,把 cgroup 中的进程进行挂起和恢复。现在具体看一下实现。
|
1
2
3
4
5
6
7
8
9
10
11
|
enum freezer_state {
CGROUP_THAWED = 0,
CGROUP_FREEZING,
CGROUP_FROZEN,
};
struct freezer {
struct cgroup_subsys_state css;
enum freezer_state state;
spinlock_t lock; /* protects _writes_ to state */
};
|
freezer 有三种状态,THAWED,FREEZING,FROZEN,分别代表正常状态,停止中和停止。
freezer 对应的文件有state,cftype是对vfs的file结构的一个封装,最后加上子系统的name,文件名对应的就是”freezer.state”。
对freezer.state更改文件内容的操作就可以更改cgroup当中task的挂起和恢复.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
/* 文件的读写函数 */
static struct cftype files[] = {
{
.name = "state",
.read_seq_string = freezer_read,
.write_string = freezer_write,
},
};
/* 添加子系统文件到cgroup目录中 */
static int freezer_populate(struct cgroup_subsys *ss, struct cgroup *cgroup)
{
if (!cgroup->parent)
return 0;
return cgroup_add_files(cgroup, ss, files, ARRAY_SIZE(files));
}
|
首先看一下freezer_read.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
static int freezer_read(struct cgroup *cgroup, struct cftype *cft,
struct seq_file *m)
{
struct freezer *freezer;
enum freezer_state state;
if (!cgroup_lock_live_group(cgroup))
return -ENODEV;
freezer = cgroup_freezer(cgroup);
spin_lock_irq(&freezer->lock);
state = freezer->state;
if (state == CGROUP_FREEZING) {
/* We change from FREEZING to FROZEN lazily if the cgroup was
* only partially frozen when we exitted write. */
update_freezer_state(cgroup, freezer);
state = freezer->state;
}
spin_unlock_irq(&freezer->lock);
cgroup_unlock();
seq_puts(m, freezer_state_strs[state]);
seq_putc(m, ‘
‘);
return 0;
}
|
整个函数就是把 freezer 的 state 转换成字符换然后读取出来。
再看下 freezer_write 是如何改变进程状态的。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
static int freezer_write(struct cgroup *cgroup,
struct cftype *cft,
const char *buffer)
{
int retval;
enum freezer_state goal_state;
if (strcmp(buffer, freezer_state_strs[CGROUP_THAWED]) == 0)
goal_state = CGROUP_THAWED;
else if (strcmp(buffer, freezer_state_strs[CGROUP_FROZEN]) == 0)
goal_state = CGROUP_FROZEN;
else
return -EINVAL;
if (!cgroup_lock_live_group(cgroup))
return -ENODEV;
retval = freezer_change_state(cgroup, goal_state);
cgroup_unlock();
return retval;
}
|
其实只是把写入的字符串转换成对应的枚举类型,然后调用freezer_change_state(cgroup, goal_state);
为了不贴过多的代码,这里略写,其实是根据类型不同进行调用了unfreeze_cgroup和try_to_freeze_cgroup。
try_to_freeze_cgroup 遍历每个task执行freeze操作,而unfreeze也是类似
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
static int try_to_freeze_cgroup(struct cgroup *cgroup, struct freezer *freezer)
{
struct cgroup_iter it;
struct task_struct *task;
unsigned int num_cant_freeze_now = 0;
freezer->state = CGROUP_FREEZING;
cgroup_iter_start(cgroup, &it);
while ((task = cgroup_iter_next(cgroup, &it))) {
/* 尝试freeze task */
if (!freeze_task(task, true))
continue;
if (is_task_frozen_enough(task))
continue;
if (!freezing(task) && !freezer_should_skip(task))
num_cant_freeze_now++;
}
cgroup_iter_end(cgroup, &it);
return num_cant_freeze_now ? -EBUSY : 0;
}
|
所以,这里我们看最后的freeze和unfreeze某个task的动作。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
bool freeze_task(struct task_struct *p, bool sig_only)
{
/*
* We first check if the task is freezing and next if it has already
* been frozen to avoid the race with frozen_process() which first marks
* the task as frozen and next clears its TIF_FREEZE.
*/
if (!freezing(p)) {
rmb();
/* 如果frozen标记了
* 说明已经冻结,就返回失败
*/
if (frozen(p))
return false;
if (!sig_only || should_send_signal(p))
set_freeze_flag(p);
else
return false;
}
if (should_send_signal(p)) {
if (!signal_pending(p))
fake_signal_wake_up(p);
} else if (sig_only) {
return false;
} else {
wake_up_state(p, TASK_INTERRUPTIBLE);
}
return true;
}
|
停止的方式就是通过标记 freeze_flag,然后通过发送信号或者唤醒 task 来处理TIF_FREEZE标记(取决于是否设置了PF_FREEZER_NOSIG)。
最后又回到了之前给的那张流程图,等处理函数运行又会try_to_freeze()检查信号或者标志位,然后进入冰箱,而唤醒的方式则是反过来,把标记清除并且wake_up进程即可。
cpu 子系统
cpu子系统是对CPU时间配额进行限制的子系统,属性在这里列举一下
- cpu.cfs_period_us 完全公平调度器的调整时间配额的周期
- cpu.cfs_quota_us 完全公平调度器的周期当中可以占用的时间
- cpu.stat 统计值
- nr_periods 进入周期的次数
- nr_throttled 运行时间被调整的次数
- throttled_time 用于调整的时间
- cpu.share cgroup中cpu的分配,如果a group是100,b group是300,那么a就会获得(frac{1}{4}),b就会获得(frac{3}{4})的CPU。
CFS 调度器
接下来看一下对于 CPU 的限制是如何做到的,这要补充一下 CFS(完全公平调度器) 的相关的内容。
CFS 保证进程之间完全公平获得 CPU 的份额,和我们传统的操作系统的时间片的理念不同,CFS 计算进程的 vruntime (其实就是总时间中的比例,并且带上进程优先级作为权重),来选择需要调度的下一个进程。用户态暴露的权重就是nice值,这个值越高权重就会低,反之亦然。(坊间的解释是 nice 的意思就是我对别的进程很 nice ,所以让别的进程多运行一会儿,自己少运行一会儿)。
CFS主要有几点,时间计算,进程选择,调度入口。
时间计算
先看下面这句话
Linux is a multi-user operating system. Consider a scenario where user A spawns ten tasks and user B spawns five. Using the above approach, every task would get ~7% of the available CPU time within a scheduling period. So user A gets 67% and user B gets 33% of the CPU time during their runs. Clearly, if user A continues to spawn more tasks, he can starve user B of even more CPU time. To address this problem, the concept of “group scheduling” was introduced in the scheduler, where, instead of dividing the CPU time among tasks, it is divided among groups of tasks.
总结来说 CPU 的时间并不是分给独立的 task 的,而是分给 task_group 的,这样防止用户 A 的进程数远远大于 B 而导致 B 饥饿的情况。这一组task通过 sched_entity 来表示。能够导致进程分组的方式一种是把进程划入一个cgroup,一种是通过set_sid()系统调用的新session中创建的进程会自动分组,这需要CONFIG_SCHED_AUTOGROUP编译选项开启。
调度的粒度是以sched_entity为粒度的,
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
#if defined(CONFIG_SMP) && defined(CONFIG_FAIR_GROUP_SCHED)
/* Per-entity load-tracking */
struct sched_avg avg;
#endif
#ifdef CONFIG_SCHEDSTATS
struct sched_statistics statistics;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;
#endif
};
|
每个调度实体都有两个cfs_rq结构
|
1
2
3
4
5
6
7
|
struct cfs_rq {
struct load_weight load;
unsigned long runnable_load_avg;
unsigned long blocked_load_avg;
unsigned long tg_load_contrib;
/* ... */
};
|
Each scheduling entity may, in turn, be queued on a parent scheduling entity’s run queue. At the lowest level of this hierarchy, the scheduling entity is a task; the scheduler traverses this hierarchy until the end when it has to pick a task to run on the CPU.
最底层的调度实体就是进程,而每个调度实体还会有两个cfs_rq,一个是cfs_rq另一个是my_q,前者是当前调度实体从属的rq,后者他自己的rq,所有的子调度实体都在这个rq上,从而构成了树形结构。可以通过cfs_rq遍历调度实体,而把自己的时间平分给my_q的调度实体.
|
1
2
3
4
5
6
7
|
struct task_group {
struct sched_entity **se;
struct cfs_rq **cfs_rq;
unsigned long shares;
atomic_long_t load_avg;
/* ... */
};
|
Tasks belonging to a group can be scheduled on any CPU. Therefore it is not sufficient for a group to have a single scheduling entity; instead, every group must have one scheduling entity for each CPU. Tasks belonging to a group must move between the run queues in these per-CPU scheduling entities only, so that the footprint of the task is associated with the group even during task migrations.
单独的sched_entity为了适应SMP结构,又引入了task_group结构,包含了数组,分别属于某个CPU,对于一个进程想要从CPU1迁移到CPU2,只要把进程从tg->cfs_rq[0]转移到tg->cfs_rq[1]即可,一种 percpu 的结构。
优先级有一个映射表,表示调度占的权重,一般nice值为0的时候,大家都是1024,但是nice值为1的时候,权重就会降低到820,对于所有1024权重的进程,就会享有更少的时间,这个映射体现的是每提升一个等级,相差值大约为10%。
下面是 nice 值到权重的映射,这是内核普通进程的优先级范围(100-139),内核拥有140个优先级。
|
1
2
3
4
5
6
7
8
9
10
|
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
|
调度实体中包含了一个结构就是表示这个权重的值,表示进程占的权重。
|
1
2
3
|
struct load_weight {
unsigned long weight;
};
|
最后 time_slice = (sched_period() * se.load.weight) / cfs_rq.load.weight; 就是 se 运行时应该分配到的 CPU 时间的份额(sched_period是cfs.nr_running调度最小粒度时间,理想要每个进程都能运行一次)。
另外,用于衡量CPU负载的方式是通过sched_entity中的sched_avg结构,这个结构用于记录负载情况:
|
1
2
3
4
|
struct sched_avg {
u32 runnable_sum, runnable_avg_period;
unsigned long load_avg_contrib;
};
|
当sched_entity是一个进程的时候,计算公式是sa.load_avg_contrib = (sa.runnable_sum * se.load.weight) / sa.runnable_period;(se是sched_entity,sa是sched_avg),runnbale_sum 是处于 RUNNING 状态的时间,runnable_period 表示可以变成运行状态的时间段。runnable_load_avg 是cfs_rq中用于统计所有se的load的合,以此来表示CPU负载。blocked_load_avg 是相应的进程处于阻塞状态的负载。
当sched_entity是一组进程的时候,计算方式是,
首先提取task group
|
1
|
tg = cfs_rq->tg;
|
之前已经统计了队列中的所有se的总和runnable_load_avg,然后全部累加到tg中。
|
1
2
|
cfs_rq->tg_load_contrib = cfs_rq->runnable_load_avg + cfs_rq->blocked_load_avg;
tg->load_avg += cfs_rq->tg_load_contrib;
|
最后se的值是通过在tg中的比重得到的,这里的tg->shares是最大允许的负载。
|
1
2
|
se->avg.load_avg_contrib =
(cfs_rq->tg_load_contrib * tg->shares / tg->load_avg);
|
进程选择
完全公平调度器的进程选择其实很简单,通过调用pick_next_entity()每次选择 vruntime 最小的进程进行运行。装载进程的结构选择的是红黑树,并且最左下角的结点是个特殊的节点,被保存起来,这样防止每次都从 root 一直搜索到最左下角,每次选择进程的时候直接选择该节点即可。
每次 vruntime 会在时钟中断和任何进程运行状态发生改变的时候进行计算,方式是通过权重调整得到一个 delta 值然后加到 vruntime 上面。
公式是vruntime += delta_exec * (NICE_0_LOAD/curr->load.weight);。这里的 weight 取决于 shares 值和负载等等因素的综合结果。
通过enqueue_entity()可以把进程加入到红黑树当中,当进程被唤醒的时候,或者第一次调用fork的时候就会被调用这个函数。具体就是更新了统计数据,并且把调度节点插入到红黑树当中。如果正好插入到了最右下角,那么就能马上被运行了。
通过dequeue_entity()可以把调度结点从红黑树中删除,这是进程在阻塞或者终止的时候会被调用的函数,具体就是把调度节点移除红黑树并且调整红黑树。
调度入口
内核的调度入口就是schedule(),遍历所有的调度类(因为内核中调度器的实现不只一种),选择权重最高的调度类并且进行进程选择,然后执行该进程。
这里列举一下所有抢占可能发生的时机
- 用户态进程:
- 从系统调用返回
- 从中断返回
- 内核态进程:
- 从中断返回内核态
- 进程主动调用
schedule() - 进程变为可抢占状态(没有持有锁,其实还是中断驱动的)
- 进程阻塞(最后还是调用schedule)
具体看 cgroup 的 cpu 子系统
补充完调度器的知识,再回来看 cgroup 是如何对进程做运行时间限制的。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
static struct cftype cpu_files[] = {
#ifdef CONFIG_FAIR_GROUP_SCHED
{
.name = "shares",
.read_u64 = cpu_shares_read_u64,
.write_u64 = cpu_shares_write_u64,
},
#endif
#ifdef CONFIG_CFS_BANDWIDTH
{
.name = "cfs_quota_us",
.read_s64 = cpu_cfs_quota_read_s64,
.write_s64 = cpu_cfs_quota_write_s64,
},
{
.name = "cfs_period_us",
.read_u64 = cpu_cfs_period_read_u64,
.write_u64 = cpu_cfs_period_write_u64,
},
{
.name = "stat",
.read_map = cpu_stats_show,
},
#endif
|
cpu 子系统也是用对文件进行读写的接口,其实就是获取了 cgroup 的 subsystem 的从属的 task_group,并且读取或者设置了 quota_us 和 period_write 以及 shares 属性。具体这些属性应用的地方在调度器内部。task_group是一个管理组调度的结构。
因为内嵌了一个cgroup_subsys_state,这样cgroup就能通过自己的css成员反找到这个task_group。
看一下cpu_shares_write_u64的实现
|
1
2
3
|
cpu_shares_write_u64 实际调用的是
-> sched_group_set_shares(cgroup_tg(cgrp), scale_load(shareval))
-> update_cfs_shares 获取 cgroup 的task group结构,调整权重
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
static void update_cfs_shares(struct cfs_rq *cfs_rq)
{
struct task_group *tg;
struct sched_entity *se;
long shares;
tg = cfs_rq->tg;
se = tg->se[cpu_of(rq_of(cfs_rq))];
if (!se || throttled_hierarchy(cfs_rq))
return;
if (likely(se->load.weight == tg->shares))
return;
/* 根据tg->shares 和 rq 的负载计算出新的权重 */
shares = calc_cfs_shares(cfs_rq, tg);
reweight_entity(cfs_rq_of(se), se, shares);
}
|
最后一步 reweight_entity 就是调整se->load.weight的权重,从这里来保证shares能够调整进程可以获得的运行时间。当然除了这里,任何发生调度的地方都会有这样的行为,只不过我们主动修改了shares的值。
下图表示了展示了shares在task group中的作用。
对于cpu.cfs_period_us和cpu.cfs_quota_us,是关于CPU bandwith的内容,论文CPU bandwidth control for CFS详细描述了其中的设计。论文中举例提到,shares 值只是使得CPU 的时间能够平均分配,但是实际运行时间可能会有变化,不能限制一个进程运行的上限。
在调度实体sched_entity中内嵌了一个结构体:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
struct cfs_bandwidth {
#ifdef CONFIG_CFS_BANDWIDTH
raw_spinlock_t lock;
ktime_t period;
/* quota 是被赋予的时间,runtime 是实际运行的时间 */
u64 quota, runtime;
s64 hierarchal_quota;
/* 到期时间 */
u64 runtime_expires;
int idle, timer_active;
struct hrtimer period_timer, slack_timer;
struct list_head throttled_cfs_rq;
/* statistics */
int nr_periods, nr_throttled;
u64 throttled_time;
#endif
};
|
在每次调度的时候(无论是时间中断还是其他调度时间导致 enqueue 或者 dequeue),都会调用account_cfs_rq_runtime(),runtime 相当于实际使用的 quota , 在论文里说的是account_cfs_rq_quota(),对占用时间更新,计算剩余可以运行的时间,如果不够,则进行限制,标记为不可调度。其中内含一个高精度定时器period_timer定时扫描进程,把限制的进程解除,并给予更多的bandwidth以继续运行,period就是计时器的周期,每次都会更新可运行的时间。注意这里用的时间是真实时间.
另外,cpu.stat 主要是控制过程中的统计信息,是只读属性,比如被限制了多少次等等,具体的代码分析就直接略过。
cpuacct 子系统
cpuacct 比较简单,因为主要是一些统计信息
- cpuacct.stat cgroup 及子消耗在用户态和内核态的CPU循环次数
- cpuacct.usage cgroup 消耗的CPU总时间
- cpuacct.usage_percpu cgroup在每个CPU上消耗的总时间
在kernel/sched/cpuacct.c下有具体实现。
|
1
2
3
4
5
6
7
|
/* track cpu usage of a group of tasks and its child groups */
struct cpuacct {
struct cgroup_subsys_state css;
/* cpuusage holds pointer to a u64-type object on every cpu */
u64 __percpu *cpuusage;
struct kernel_cpustat __percpu *cpustat;
};
|
其中定义了per-cpu结构,让每个CPU都独占了一个用于统计的值,算是CPU的私有变量。
接口如下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
static struct cftype files[] = {
{
.name = "usage",
.read_u64 = cpuusage_read,
.write_u64 = cpuusage_write,
},
{
.name = "usage_percpu",
.read_seq_string = cpuacct_percpu_seq_read,
},
{
.name = "stat",
.read_map = cpuacct_stats_show,
},
{ } /* terminate */
};
|
每次调度update_curr,都会调用cpuacct_charge更新cpuacct中的值,作为统计数据。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
/*
* charge this task‘s execution time to its accounting group.
*
* called with rq->lock held.
*/
void cpuacct_charge(struct task_struct *tsk, u64 cputime)
{
struct cpuacct *ca;
int cpu;
/* 获取当前task属于的cpu */
cpu = task_cpu(tsk);
rcu_read_lock();
/* task的cpuacct结构 */
ca = task_ca(tsk);
/* 所有父节点的值都应该相应变化
* 上溯父节点更新统计值
*/
while (true) {
u64 *cpuusage = per_cpu_ptr(ca->cpuusage, cpu);
*cpuusage += cputime;
ca = parent_ca(ca);
if (!ca)
break;
}
rcu_read_unlock();
}
|
在时钟中断的时候会最终调用cpuacct_account_field()来更新kcpustat。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
/*
* Add user/system time to cpuacct.
*
* Note: it‘s the caller that updates the account of the root cgroup.
*/
void cpuacct_account_field(struct task_struct *p, int index, u64 val)
{
struct kernel_cpustat *kcpustat;
struct cpuacct *ca;
rcu_read_lock();
ca = task_ca(p);
while (ca != &root_cpuacct) {
kcpustat = this_cpu_ptr(ca->cpustat);
kcpustat->cpustat[index] += val;
ca = __parent_ca(ca);
}
rcu_read_unlock();
}
|
cpuacct 算是一个简单的子系统,多是统计信息。
cpuset 子系统
cpuset 子系统用于分配独立的内存节点和CPU节点,这个主要应用与NUMA结构里面,多内存节点属于结构,先看一下cpuset的结构。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
struct cpuset {
struct cgroup_subsys_state css;
unsigned long flags; /* "unsigned long" so bitops work */
cpumask_var_t cpus_allowed; /* CPUs allowed to tasks in cpuset */
nodemask_t mems_allowed; /* Memory Nodes allowed to tasks */
struct fmeter fmeter; /* memory_pressure filter */
/*
* Tasks are being attached to this cpuset. Used to prevent
* zeroing cpus/mems_allowed between ->can_attach() and ->attach().
*/
int attach_in_progress;
/* partition number for rebuild_sched_domains() */
int pn;
/* for custom sched domain */
int relax_domain_level;
struct work_struct hotplug_work;
};
|
- cpuset.cpus cpu结点限制
- cpuset.mems 内存结点限制
- cpuset.memory_migrate 内存结点改变是否迁移
- cpuset.cpu_exclusive 指定的限制是否是独享的,除了父节点或者子节点,不会和其他cpuset有交集
- cpuset.mem_exclusive 指定的限制是否是独享的,除了父节点或者子节点,不会和其他cpuset有交集
- cpuset.memory_pressure 换页压力的比率统计
- cpuset.mem_hardwall 限制内核内存分配的结点,mems是限制用户态的分配
- cpuset.memory_spread_page 把page cache分散到分配的各个结点中,而不是当前运行的结点.
- cpuset.memory_spread_slab 把fs相关的slab的对象(inode和dentry)分散到结点中.
- cpuset.sched_load_balance 打开调度CPU的负载均衡,这里指的是cpuset拥有的sched_domain,默认全局的CPU调度是本来就有负载均衡的。
- cpuset.sched_relax_domain_level
- cpuset.memory_pressure_enabled 计算换页压力的开关,注意,这个属性在
top_group里面才有
cpus_allowed和mems_allowed就是允许分配的内存节点和CPU节点的掩码。
分配内存的时候调用栈是alloc_pages()->alloc_pages_current()->__alloc_pages_nodemask(),直到寻找可分配结点的时候会调用 zref_in_nodemask 来判断是否可以分配在该结点。
|
1
2
3
4
5
6
7
8
|
static inline int zref_in_nodemask(struct zoneref *zref, nodemask_t *nodes)
{
return node_isset(zonelist_node_idx(zref), *nodes);
return 1;
}
|
从这个函数也可以看到如果编译选项带了CONFIG_NUMA才会起作用,不然返回的永远都是真。
分散file cache和slab cache的方式是通过设置标志位来实现的。
Setting the flag ‘cpuset.memory_spread_page’ turns on a per-process flag
PFA_SPREAD_PAGE for each task that is in that cpuset or subsequently
joins that cpuset. The page allocation calls for the page cache
is modified to perform an inline check for this PFA_SPREAD_PAGE task
flag, and if set, a call to a new routine cpuset_mem_spread_node()
returns the node to prefer for the allocation.Similarly, setting ‘cpuset.memory_spread_slab’ turns on the flag
PFA_SPREAD_SLAB, and appropriately marked slab caches will allocate
pages from the node returned by cpuset_mem_spread_node().
内存分配向结点的传播,都是通过设置标志PFA_SPREAD_PAGE或者PFA_SPREAD_SLAB来标记的,这个时候对应的函数cpuset_mem_spread_node和cpuset_mem_spread_node会返回希望分配的结点,举个例子,cpuset_mem_spread_node会从允许的节点中随机返回一个值,以达到分配对象分散在结点当中。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
static int cpuset_spread_node(int *rotor)
{
int node;
node = next_node(*rotor, current->mems_allowed);
if (node == MAX_NUMNODES)
node = first_node(current->mems_allowed);
*rotor = node;
return node;
}
int cpuset_mem_spread_node(void)
{
if (current->cpuset_mem_spread_rotor == NUMA_NO_NODE)
current->cpuset_mem_spread_rotor =
node_random(¤t->mems_allowed);
return cpuset_spread_node(¤t->cpuset_mem_spread_rotor);
}
|
对于CPU结点的控制是通过修改cpus_allowed来控制的,在task被唤醒的时候选择运行的rq时就会对掩码做判断,这是调度类需要实现的接口select_task_rq,比如CFS的实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
/*
* The caller (fork, wakeup) owns p->pi_lock, ->cpus_allowed is stable.
*/
static inline
int select_task_rq(struct task_struct *p, int sd_flags, int wake_flags)
{
int cpu = p->sched_class->select_task_rq(p, sd_flags, wake_flags);
/*
* In order not to call set_task_cpu() on a blocking task we need
* to rely on ttwu() to place the task on a valid ->cpus_allowed
* cpu.
*
* Since this is common to all placement strategies, this lives here.
*
* [ this allows ->select_task() to simply return task_cpu(p) and
* not worry about this generic constraint ]
*/
if (unlikely(!cpumask_test_cpu(cpu, tsk_cpus_allowed(p)) ||
!cpu_online(cpu)))
cpu = select_fallback_rq(task_cpu(p), p);
return cpu;
}
|
load_balance 设置的是cpuset的CS_SCHED_LOAD_BALANCE标志,之后会调用update_cpumask,这个标志的更新会调用rebuild_sched_domains_locked(),会引起sched_domain的分配。当然这不是唯一的sched_domain重新划分的触发点,触发点有一下几点。
- 绑定了CPU并且该标记改变
- 这个标记为enable,绑定CPU发生改变
- 绑定了CPU,这个标记为enable,标记
cpuset.sched_relax_domain_level发生改变 - 绑定了CPU,并且该标记设置了,但是cpuset被删除了
- CPU 转变 offline/online 状态
简单说一下sched_domain的作用,其实就是划定了负载均衡的 CPU 范围,默认是有一个全局的sched_domain,对所有 CPU 做负载均衡的,现在再划分出一个sched_domain把 CPU 的某个子集作为负载均衡的单元。
每个 Scheduling Domain 其实就是具有相同属性的一组 CPU 的集合. 并且跟据 Hyper-threading, Multi-core, SMP, NUMA architectures 这样的系统结构划分成不同的级别,不同级之间通过指针链接在一起, 从而形成一种的树状的关系, 如下图所示。

调度器会调用partition_sched_domains()来更新自己的scehd_domains,调度域发生作用的地方是在时钟中断的时候会触发SCHED_SOFTIRQ对任务做迁移,或者p->sched_class->select_task_rq,会在选择运行 CPU 时进行抉择,看一下 CFS 的实现的select_task_rq的简化流程
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
// 向上遍历更高层次的domain,如果发现同属一个domain
// 就是affine目标
for_each_domain(cpu, tmp) {
/*
* If both cpu and prev_cpu are part of this domain,
* cpu is a valid SD_WAKE_AFFINE target.
*/
if (want_affine && (tmp->flags & SD_WAKE_AFFINE) &&
cpumask_test_cpu(prev_cpu, sched_domain_span(tmp))) {
affine_sd = tmp;
break;
}
if (tmp->flags & sd_flag)
sd = tmp;
}
// 如果上面的条件满足,从prev_cpu中选出一个idle的new_cpu来运行.
if (affine_sd) {
if (cpu != prev_cpu && wake_affine(affine_sd, p, sync))
prev_cpu = cpu;
// 在同一个级别的sched domain向下找到一个idle的CPU.
new_cpu = select_idle_sibling(p, prev_cpu);
// 快速路径,有idle的CPU就不用负载均衡了.
goto unlock;
}
// 遍历层级
while (sd) {
// 找到负载最小的CPU
group = find_idlest_group(sd, p, cpu, load_idx);
if (!group) {
sd = sd->child;
continue;
}
new_cpu = find_idlest_cpu(group, p, cpu);
/* 如果最闲置的CPU没有变的话,或者没有找到的话,就向下遍历.
if (new_cpu == -1 || new_cpu == cpu) {
/* Now try balancing at a lower domain level of cpu */
sd = sd->child;
continue;
}
/* Now try balancing at a lower domain level of new_cpu */
cpu = new_cpu;
weight = sd->span_weight;
sd = NULL;
// 如果选出的节点weight比其他节点都大的话.
// 再向下一个层级遍历.
for_each_domain(cpu, tmp) {
if (weight <= tmp->span_weight)
break;
if (tmp->flags & sd_flag)
sd = tmp;
}
/* while loop will break here if sd == NULL */
}
|
负载均衡的对象有个例外。
CPUs in “cpuset.isolcpus” were excluded from load balancing by the
isolcpus= kernel boot option, and will never be load balanced regardless
of the value of “cpuset.sched_load_balance” in any cpuset.
如果boot选项标记了该CPU,会无视sched_load_balance的设置。
cpuset.sched_relax_domain_level有几个等级,越大越优先,表示迁移时搜索CPU的范围,这个主要开启了负载均衡选项的时候才有用。
- -1 : no request. use system default or follow request of others. 用默认的或者按照其他组的优先级来.
- 0 : no search,不搜索.
- 1 : search siblings (hyperthreads in a core,搜索CPU当中的超线程).
- 2 : search cores in a package.(搜索CPU当中的核).
- 3 : search cpus in a node [= system wide on non-NUMA system]
- 4 : search nodes in a chunk of node [on NUMA system]
- 5 : search system wide [on NUMA system]
memory 子系统
看完 cpu 部分再开看一下内存子系统是如何做限制的
memory 子系统的参数比较多
- memory.usage_in_bytes # 当前内存中的 res_counter 使用量
- memory.memsw.usage_in_bytes # 当前内存和交换空间中的 res_counter 使用量
- memory.limit_in_bytes # 设置/读取 内存使用量
- memory.memsw.limit_in_bytes # 设置/读取 内存加交换空间使用量
- memory.failcnt # 读取内存使用量被限制的次数
- memory.memsw.failcnt # 读取内存和交换空间使用量被限制的次数
- memory.max_usage_in_bytes # 最大内存使用量
- memory.memsw.max_usage_in_bytes # 最大内存和交换空间使用量
- memory.soft_limit_in_bytes # 设置/读取内存的soft limit
- memory.stat # 统计信息
- memory.use_hierarchy # 设置/读取 层级统计的使能
- memory.force_empty # trigger forced move charge to parent?
- memory.pressure_level # 设置内存压力通知
- memory.swappiness # 设置/读取 vmscan swappiness 参数?
- memory.move_charge_at_immigrate # 设置/读取 controls of moving charges?
- memory.oom_control # 设置/读取 内存超限控制信息
- memory.numa_stat # 每个numa节点的内存使用数量
- memory.kmem.limit_in_bytes # 设置/读取 内核内存限制的hard limit
- memory.kmem.usage_in_bytes # 读取当前内核内存的分配
- memory.kmem.failcnt # 读取当前内核内存分配受限的次数
- memory.kmem.max_usage_in_bytes # 读取最大内核内存使用量
- memory.kmem.tcp.limit_in_bytes # 设置tcp 缓存内存的hard limit
- memory.kmem.tcp.usage_in_bytes # 读取tcp 缓存内存的使用量
- memory.kmem.tcp.failcnt # tcp 缓存内存分配的受限次数
- memory.kmem.tcp.max_usage_in_bytes # tcp 缓存内存的最大使用量
对于大部分的数据是通过res_counter来保存的
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
/*
* The core object. the cgroup that wishes to account for some
* resource may include this counter into its structures and use
* the helpers described beyond
*/
struct res_counter {
/*
* the current resource consumption level
*/
unsigned long long usage;
/*
* the maximal value of the usage from the counter creation
*/
unsigned long long max_usage;
/*
* the limit that usage cannot exceed
*/
unsigned long long limit;
/*
* the limit that usage can be exceed
*/
unsigned long long soft_limit;
/*
* the number of unsuccessful attempts to consume the resource
*/
unsigned long long failcnt;
/*
* the lock to protect all of the above.
* the routines below consider this to be IRQ-safe
*/
spinlock_t lock;
/*
* Parent counter, used for hierarchial resource accounting
*/
struct res_counter *parent;
};
|
获取方式是通过该结构相关的封装接口提供的,比如mem_cgroup_usage就是通过res_counter_red_u64来获取对应的res_counter的RES_USAGE对应的值的,也就是unsigned long long usage这个成员。(如果不是root,还会递归获取rss和page cache的合。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
static inline u64 mem_cgroup_usage(struct mem_cgroup *memcg, bool swap)
{
u64 val;
if (!mem_cgroup_is_root(memcg)) {
if (!swap)
return res_counter_read_u64(&memcg->res, RES_USAGE);
else
return res_counter_read_u64(&memcg->memsw, RES_USAGE);
}
/*
* Transparent hugepages are still accounted for in MEM_CGROUP_STAT_RSS
* as well as in MEM_CGROUP_STAT_RSS_HUGE.
*/
// 如果是root就把所有的内存使用量都算进来.
val = mem_cgroup_recursive_stat(memcg, MEM_CGROUP_STAT_CACHE);
val += mem_cgroup_recursive_stat(memcg, MEM_CGROUP_STAT_RSS);
if (swap)
val += mem_cgroup_recursive_stat(memcg, MEM_CGROUP_STAT_SWAP);
return val << PAGE_SHIFT;
}
|
struct mem_cgroup 是负责内存 cgroup 的结构,简化的表示是
|
1
2
3
4
5
6
7
|
struct mem_cgroup {
struct cgroup_subsys_state css; // 通过css关联cgroup.
struct res_counter res; // mem统计变量
res_counter memsw; // mem+sw的和
struct res_counter kmem; // 内核内存统计量
...
}
|
这些参数的入口都在mm/memcontrol.c下,比如说memory.usage_in_bytes的读取调用的是mem_cgroup_read函数,
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
static ssize_t mem_cgroup_read(struct cgroup *cont, struct cftype *cft,
struct file *file, char __user *buf,
size_t nbytes, loff_t *ppos)
{
// 获取cgroup对应的mem_cgroup.
struct mem_cgroup *memcg = mem_cgroup_from_cont(cont);
char str[64];
u64 val;
int name, len;
enum res_type type;
// 获取读取的类型,memory.usage_in_bytes就是_MEM
type = MEMFILE_TYPE(cft->private);
// 名称
name = MEMFILE_ATTR(cft->private);
switch (type) {
case _MEM:
if (name == RES_USAGE)
val = mem_cgroup_usage(memcg, false);
else
val = res_counter_read_u64(&memcg->res, name);
break;
case _MEMSWAP:
if (name == RES_USAGE)
val = mem_cgroup_usage(memcg, true);
else
val = res_counter_read_u64(&memcg->memsw, name);
break;
case _KMEM:
val = res_counter_read_u64(&memcg->kmem, name);
break;
default:
BUG();
}
len = scnprintf(str, sizeof(str), "%llu
", (unsigned long long)val);
return simple_read_from_buffer(buf, nbytes, ppos, str, len);
}
|
接下来再看一下这些值是在什么时候统计的,统计的入口是mem_cgroup_charge_common(),如果统计值超过限制就会在cgroup内进行回收。调用者分别是缺页时调用的mem_cgroup_newpage_charge 和 page cache 相关的mem_cgroup_cache_charge。
简单复习一下内存分配的过程,来自维基百科
创建进程fork(), 程序载入execve(), 映射文件mmap(), 动态内存分配 malloc()/brk() 等进程相关操作都需要分配内存给进程。不过这时进程申请和获得的还不是实际内存,而是虚拟内存,准确的说是“内存区域”。进程对内存区域的分配最终都会归结到 do_mmap() 函数上来(brk调用被单独以系统调用实现,不用do_mmap()),内核使用 do_mmap() 函数创建一个新的线性地址区间。但是说该函数创建了一个新 VMA 并不非常准确,因为如果创建的地址区间和一个已经存在的地址区间相邻,并且它们具有相同的访问权限的话,那么两个区间将合并为一个。如果不能合并,那么就确实需要创建一个新的 VMA 了。但无论哪种情况,do_mmap() 函数都会将一个地址区间加入到进程的地址空间中–无论是扩展已存在的内存区域还是创建一个新的区域。同样,释放一个内存区域应使用函数 do_ummap(),它会销毁对应的内存区域。当进程需要内存时,从内核获得的仅仅是虚拟的内存区域,而不是实际的物理地址,进程并没有获得物理内存,获得的仅仅是对一个新的线性地址区间的使用权。实际的物理内存只有当进程真的去访问新获取的虚拟地址时,才会由”请求页机制”产生”缺页”异常,从而进入分配实际页面的例程
。
和下面来自内核文档
与用户进程相似,内核也有一个名为 init_mm 的 mm_strcut 结构来描述内核地址空间,其中页表项 pdg=swapper_pg_dir包含了系统内核空间(3G-4G)的映射关系。因此 vmalloc 分配内核虚拟地址必须更新内核页表,而kmalloc或get_free_page由于分配的连续内存,所以不需要更新内核页表。[13]
内存页的分配是基于伙伴分配系统,也就是基于2的阶乘通过拆分大阶乘的连续页和合并小阶乘的连续页来管理物理内存的方式,这在任何一本操作系统的书里都会讲到,我之前的博客也详细分析了。
当进程进入缺页异常的时候就会分配具体的物理内存,当物理内存使用超过高水平线以后,换页daemon(kswapd)就会被唤醒用于把内存交换到交换空间以腾出内存,当内存恢复至高水平线以后换页daemon进入睡眠。
缺页异常的入口是
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
static int __do_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pmd_t *pmd,
pgoff_t pgoff, unsigned int flags, pte_t orig_pte)
{
pte_t *page_table;
spinlock_t *ptl;
struct page *page;
struct page *cow_page;
pte_t entry;
int anon = 0;
struct page *dirty_page = NULL;
struct vm_fault vmf;
int ret;
int page_mkwrite = 0;
/*
* If we do COW later, allocate page befor taking lock_page()
* on the file cache page. This will reduce lock holding time.
*/
if ((flags & FAULT_FLAG_WRITE) && !(vma->vm_flags & VM_SHARED)) {
if (unlikely(anon_vma_prepare(vma)))
return VM_FAULT_OOM;
/* 分配内存并且映射到内存区间 */
cow_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address);
if (!cow_page)
return VM_FAULT_OOM;
/* 进行统计 */
if (mem_cgroup_newpage_charge(cow_page, mm, GFP_KERNEL)) {
page_cache_release(cow_page);
return VM_FAULT_OOM;
}
} else
cow_page = NULL;
|
mem_cgroup_newpage_charge则调用mem_cgroup_charge_common
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
int mem_cgroup_newpage_charge(struct page *page,
struct mm_struct *mm, gfp_t gfp_mask)
{
if (mem_cgroup_disabled())
return 0;
// 不应该关联到页表
VM_BUG_ON(page_mapped(page));
// 对应用户态地址,但是不是匿名页
VM_BUG_ON(page->mapping && !PageAnon(page));
// mm 为空
VM_BUG_ON(!mm);
return mem_cgroup_charge_common(page, mm, gfp_mask,
MEM_CGROUP_CHARGE_TYPE_ANON);
}
|
mem_cgroup_charge_common内容是,返回ret < 0则是OOM。第一步是调用__mem_cgroup_try_charge查看当前使用量是否超过内存限制,如果超过就进行内存回收。第二步如果成功就调用__mem_cgroup_commit_charge添加统计值 ,不然就返回无法分配内存的错误。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
static int mem_cgroup_charge_common(struct page *page, struct mm_struct *mm,
gfp_t gfp_mask, enum charge_type ctype)
{
struct mem_cgroup *memcg = NULL;
unsigned int nr_pages = 1;
bool oom = true;
int ret;
if (PageTransHuge(page)) {
nr_pages <<= compound_order(page);
VM_BUG_ON(!PageTransHuge(page));
/*
* Never OOM-kill a process for a huge page. The
* fault handler will fall back to regular pages.
*/
oom = false;
}
ret = __mem_cgroup_try_charge(mm, gfp_mask, nr_pages, &memcg, oom);
if (ret == -ENOMEM)
return ret;
__mem_cgroup_commit_charge(memcg, page, nr_pages, ctype, false);
return 0;
}
|
__mem_cgroup_try_charge最终会调用mem_cgroup_do_charge,省略代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
static int mem_cgroup_do_charge(struct mem_cgroup *memcg, gfp_t gfp_mask,
unsigned int nr_pages, unsigned int min_pages,
bool invoke_oom)
{
unsigned long csize = nr_pages * PAGE_SIZE;
struct mem_cgroup *mem_over_limit;
struct res_counter *fail_res;
unsigned long flags = 0;
int ret;
// 更新res计数器
ret = res_counter_charge(&memcg->res, csize, &fail_res);
if (likely(!ret)) {
if (!do_swap_account)
return CHARGE_OK;
// 计数成功,如果开启swap计数,记录memsw.
ret = res_counter_charge(&memcg->memsw, csize, &fail_res);
if (likely(!ret))
return CHARGE_OK;
// swap计数失败,退回res的计数
res_counter_uncharge(&memcg->res, csize);
// 获取fail_res对应的memcg,也就是计数失败的memcg.
mem_over_limit = mem_cgroup_from_res_counter(fail_res, memsw);
flags |= MEM_CGROUP_RECLAIM_NOSWAP;
} else
mem_over_limit = mem_cgroup_from_res_counter(fail_res, res);
// 回收内存
ret = mem_cgroup_reclaim(mem_over_limit, gfp_mask, flags);
// 告诉上层重试一次,可能回收了一些内存
if (nr_pages <= (1 << PAGE_ALLOC_COSTLY_ORDER) && ret)
return CHARGE_RETRY;
if (invoke_oom)
// 进入oom的处理
mem_cgroup_oom(mem_over_limit, gfp_mask, get_order(csize));
|
mem_cgroup_reclaim的代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
static unsigned long mem_cgroup_reclaim(struct mem_cgroup *memcg,
gfp_t gfp_mask,
unsigned long flags)
{
unsigned long total = 0;
bool noswap = false;
int loop;
if (flags & MEM_CGROUP_RECLAIM_NOSWAP)
noswap = true;
if (!(flags & MEM_CGROUP_RECLAIM_SHRINK) && memcg->memsw_is_minimum)
noswap = true;
for (loop = 0; loop < MEM_CGROUP_MAX_RECLAIM_LOOPS; loop++) {
if (loop)
drain_all_stock_async(memcg);
total += try_to_free_mem_cgroup_pages(memcg, gfp_mask, noswap);
/*
* Allow limit shrinkers, which are triggered directly
* by userspace, to catch signals and stop reclaim
* after minimal progress, regardless of the margin.
*/
if (total && (flags & MEM_CGROUP_RECLAIM_SHRINK))
break;
if (mem_cgroup_margin(memcg))
break;
/*
* If nothing was reclaimed after two attempts, there
* may be no reclaimable pages in this hierarchy.
*/
if (loop && !total)
break;
}
return total;
}
|
RSS在page_fault的时候记录,page cache是插入到inode的radix-tree中才记录的。RSS在完全unmap的时候减少计数,page cache的page在离开inode的radix-tree才减少计数。
即使RSS完全unmap,也就是被kswapd给换出,可能作为SwapCache存留在系统中,除非不作为SwapCache,不然还是会被计数。
一个换入的page不会马上计数,只有被map的时候才会,当进行换页的时候,会预读一些不属于当前进程的page,而不是通过page fault,所以不在换入的时候计数。
补充:
- why ‘memory+swap’ rather than swap.
The global LRU(kswapd) can swap out arbitrary pages. Swap-out means
to move account from memory to swap…there is no change in usage of
memory+swap. In other words, when we want to limit the usage of swap without
affecting global LRU, memory+swap limit is better than just limiting swap from
an OS point of view.[12]
使用memoery+swap来统计而不是光统计swap,是因为kswapd换出的page只是从内存到了交换空间而已 ,在不影响kswpad的单页内存池LRU的情况下,这样的统计更有意义。
内核内存是不会被换出的。只有在被限制的时候才会开始计数。并且限制不能在已经有进程或者有子cgroup的情况下设置。
计数部分
When use_hierarchy == 1 and a group is accounted, its children will
automatically be accounted regardless of their limit value.
总结
目前总结了调度相关和内存相关的 cgroup 代码,可以看出 cgroup 本身其实主要是在一些 hook 的地方做检查,真正的控制的执行者还是调度器和内存分配器本身,cgroup 只是统计数据并且在必要的时候触发调度和内存回收等等。接下来我会就网络的部分进行一些分析,希望能够把完整的各个 cgroup 的子系统都能够解析一下。
参考: