sql 提取第一个字符
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql 提取第一个字符相关的知识,希望对你有一定的参考价值。
怎样写语句把分类号如tp12,f13,A123等这样的字符中的第一位提取出来作为新的一列,前两位提取出来作为另一列。
sql怎样提取第一个字符的方法用到的是substring() 方法用于提取字符串中介于两个指定下标之间的字符。

返回值
一个新的字符串,该字符串值包含 stringObject 的一个子字符串,其内容是从 start 处到 stop-1 处的所有字符,其长度为 stop 减 start。
2.说明
substring() 方法返回的子串包括 start 处的字符,但不包括 stop 处的字符。
如果参数 start 与 stop 相等,那么该方法返回的就是一个空串(即长度为 0 的字符串)。如果 start 比 stop 大,那么该方法在提取子串之前会先交换这两个参数。
举例说明:
select id, substring(str,charindex(',',str)+1,len(str)-charindex(',',str)) from test;
参考技术A
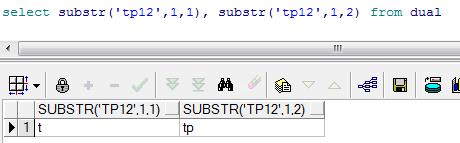
select substr('tp12',1,1), substr('tp12',1,2) from dual
函数格式:
string substr ( string string, int start [, int length])
参数1:处理字符串
参数2:截取的起始位置(第一个字符是从0开始)
参数3:截取的字符数量本回答被提问者采纳 参考技术C 看你的意思,是以什么条件来判断哪个是取第一个字符,哪个是取前两个字符呢?
你说的越清楚,我们才能更好的回答
通过第一个冒号提取字符串
【中文标题】通过第一个冒号提取字符串【英文标题】:extract string through first colon 【发布时间】:2013-03-05 11:49:28 【问题描述】:我有一个字符串数据集,想要提取一个子字符串,直到并包括第一个冒号。早些时候我在这里发帖询问如何仅提取第一个冒号之后的部分:Split strings at the first colon 下面我列出了我解决当前问题的一些尝试。
我知道^[^:]+: 匹配我想要保留的部分,但我不知道如何提取该部分。
这是一个示例数据集和所需的结果。
my.data <- "here is: some text
here is some more.
even: more text
still more text
this text keeps: going."
my.data2 <- readLines(textConnection(my.data))
desired.result <- "here is:
0
even:
0
this text keeps:"
desired.result2 <- readLines(textConnection(desired.result))
# Here are some of my attempts
# discards line 2 and 4 but does not extract portion from lines 1,3, and 5.
ifelse( my.data2 == gsub("^[^:]+:", "", my.data2), '', my.data2)
# returns the portion I do not want rather than the portion I do want
sub("^[^:]+:", "\\1", my.data2, perl=TRUE)
# returns an entire line if it contains a colon
grep("^[^:]+:", my.data2, value=TRUE)
# identifies which rows contain a match
regexpr("^[^:]+:", my.data2)
# my attempt at anchoring the right end instead of the left end
regexpr("[^:]+:$", my.data2)
这个较早的问题涉及返回匹配的反面。如果我从上面链接的早期问题的解决方案开始,我还没有想出如何在 R 中实现这个解决方案:Regular Expression Opposite
我最近获得了 RegexBuddy 来学习正则表达式。这就是我知道^[^:]+: 与我想要的匹配的方式。我只是无法使用该信息来提取匹配项。
我知道stringr 包。也许它可以提供帮助,但我更喜欢 base R 中的解决方案。
感谢您的任何建议。
【问题讨论】:
我认为您只是缺少捕获括号,( 和 ) - 您的表达式包括它们将是 ^([^:]+:)
我认为您正在寻找的是正则表达式组。也许这对***.com/questions/952275/regex-group-capture-in-r 有帮助?
【参考方案1】:
strsplit 的另一种不太优雅的方法:
x <- strsplit(my.data2, ":")
lens <- sapply(x, length)
y <- sapply(x, "[", 1)
y[lens==1] <- "0"
【讨论】:
尽可能避免使用正则表达式并不是不优雅的。【参考方案2】:这似乎产生了您正在寻找的东西(尽管它只返回带有冒号的行):
grep(":",gsub("(^[^:]+:).*$","\\1",my.data2 ),value=TRUE)
[1] "here is:" "even:" "this text keeps:"
当我输入此内容时,我看到了@DWin 的答案,该答案也建议使用括号,并且有ifelse,它也确实为您提供了“0”。
【讨论】:
【参考方案3】:“我知道 ^[^:]+: 匹配我要保留的部分,但我不知道如何提取该部分。”
所以只需将括号包裹起来并在末尾添加“.+$”并使用带有引用的子
sub("(^[^:]+:).+$", "\\1", vec)
step1 <- sub("^([^:]+:).+$", "\\1", my.data2)
step2 <- ifelse(grepl(":", step1), step1, 0)
step2
#[1] "here is:" "0" "even:" "0"
#[5] "this text keeps:"
不清楚您是否希望将它们作为单独的矢量元素与换行符一起粘贴:
> step3 <- paste0(step2, collapse="\n")
> step3
[1] "here is:\n0\neven:\n0\nthis text keeps:"
> cat(step3)
here is:
0
even:
0
this text keeps:
【讨论】:
以上是关于sql 提取第一个字符的主要内容,如果未能解决你的问题,请参考以下文章