卷积神经网络学习
Posted chians-dw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了卷积神经网络学习相关的知识,希望对你有一定的参考价值。
一、基础知识(一)
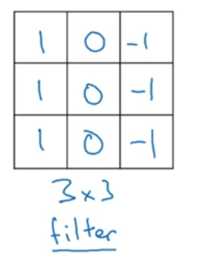
filter:
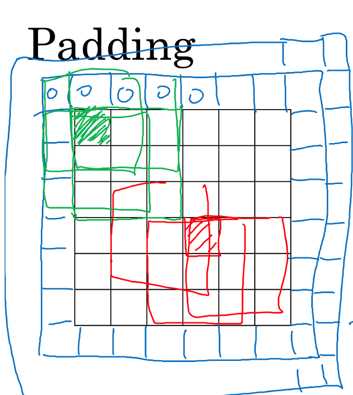
padding:在图像卷积操作之前,沿着图像边缘用0进行图像填充。padding会影响输出图像大小。
stride(卷积步长):卷积步长是指过滤器在图像上滑动的距离
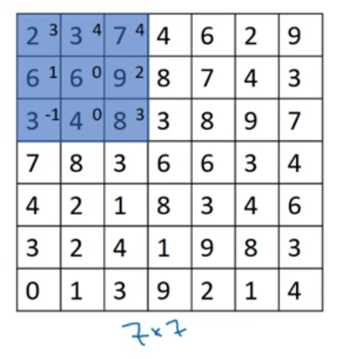
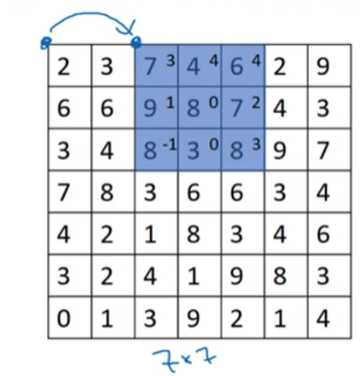
input: n*n, filter: f*f, stride: s, padding: p
output:![]() , ? ?表示向下取整
, ? ?表示向下取整
单层卷积网络:
ReLU(整流线性单位)——与Sigmoid函数不同的是,最近的网络更喜欢使用ReLu激活函数来处理隐藏层。该函数定义为:
当X>0时,函数的输出值为X;当X<=0时,输出值为0。函数图如下图所示:
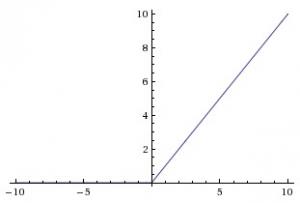
使用ReLU函数的最主要的好处是对于大于0的所有输入来说,它都有一个不变的导数值。常数导数值有助于网络训练进行得更快。
在矩阵上加入偏差b1,然后对加入偏差的矩阵做非线性的Relu变换,得到一个新的4*4矩阵,这就是单层卷积网络的完整计算过程。用公式表示:
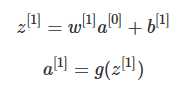
其中输入图像为a[0],过滤器用w[1]表示,对图像进行线性变化并加入偏差得到矩阵z[1],a[1]是应用Relu激活后的结果。
描述卷积神经网络的一些符号标识:
 输出图像的通道数就是过滤器的个数。
输出图像的通道数就是过滤器的个数。
卷积神经网络层的类型:
- 卷积层(convolution,conv)
- 池化层(pooling,pool)
- 全连接层(Fully connected,FC)
1.池化层
最大池化(Max pooling)
最大池化思想很简单,以下图为例,把4*4的图像分割成4个不同的区域,然后输出每个区域的最大值,这就是最大池化所做的事情。其实这里我们选择了2*2的过滤器,步长为2。在一幅真正的图像中提取最大值可能意味着提取了某些特定特征,比如垂直边缘、一只眼睛等等。
平均池化和最大池化唯一的不同是,它计算的是区域内的平均值而最大池化计算的是最大值。在日常应用使用最多的还是最大池化。平均池化和最大池化唯一的不同是,它计算的是区域内的平均值而最大池化计算的是最大值。在日常应用使用最多的还是最大池化。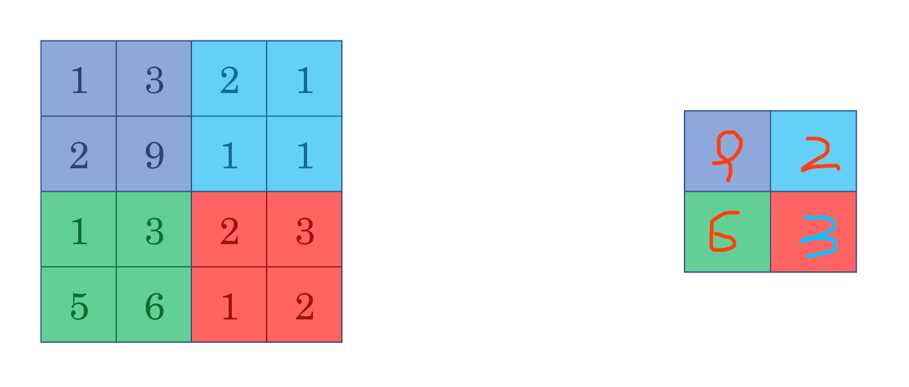
平均池化和最大池化唯一的不同是,它计算的是区域内的平均值而最大池化计算的是最大值。在日常应用使用最多的还是最大池化。
池化的超参数:步长、过滤器大小、池化类型最大池化or平均池化
以上是关于卷积神经网络学习的主要内容,如果未能解决你的问题,请参考以下文章