oracle树状索引详解(图摘取《收获不止oracle》)
Posted wangchuanjie
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了oracle树状索引详解(图摘取《收获不止oracle》)相关的知识,希望对你有一定的参考价值。
一.树状索引特点
1.高度较低
2.存储列值
3.结构有序
我们先看一下索引的结构,如图:
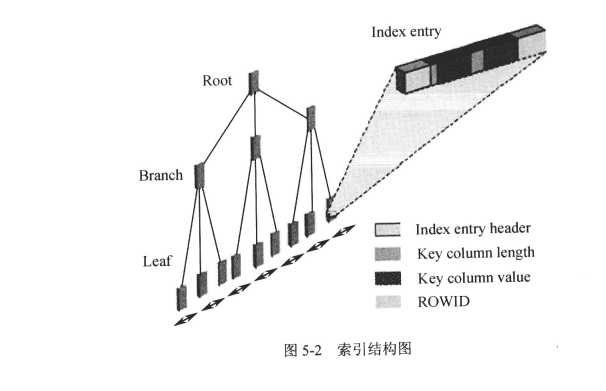
以上结构图说明索引是由 ROOT(根块),Branch(茎块)和Leaf(叶子块)三部分组成的,其中最底层的叶子块 主要存储了 key column value(索引列具体值),以及能具体定位到数据所在位置的rowid(此处rowid和查询时候用的rownum不是同一个概念,有兴趣可以百度rownum和rowid的区别)
注意点:索引块和数据块 需要区分,索引块也是占磁盘空间的
二.oracle索引查询
索引是如何快速检索到数据的呢?
举个书上的例子:select * from test where id = 12;
假如该test表共有10050条数据,而id=12仅返回一条数据,test表id字段建了一个索引,检索数据如下图:
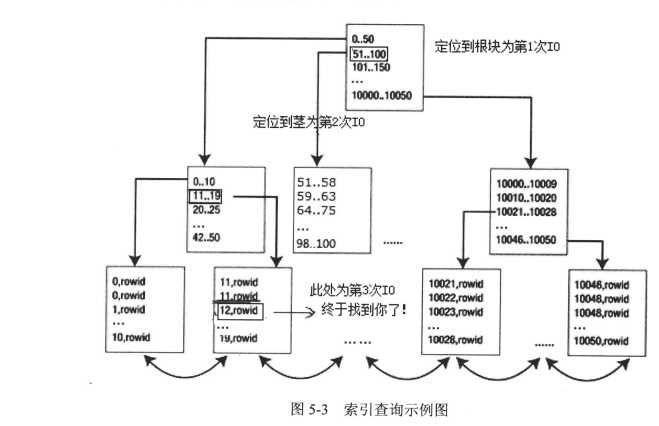
通过图片理解,该sql语句大致只要3个IO,此处是个例子,实际情况1w多数据量,索引高度应该只有2层,即2个IO左右。
首先查询定位到索引根部,接下来根据根块数据分布,定位到茎部数据,然后定位到叶子块。
有了索引,oracle只会去扫描部分索引块,而非全部,所以会提高性能。由于是select * 语句,不止只要id这个字段,所以不止要扫描索引块,还要根据 这个id=12的索引中的rowid,去回表扫描其他字段,所以要加上一次IO。
数据库IO:连续读,随机读,随机写和连续写
三.索引高度和结构的理解
索引并不是真的就是根茎叶3层,索引高度是根据数据量来体现的。
1.索引建立的步骤
还是test表,有id等列,现在在id上建立索引,
1)先从test表的id列的值顺序取出来放在内存中,每个值对应的rowid也被一并取出。
2)依次将内存中顺序存放的列的值和对应的rowid存进oracle空闲的BLOCK中,形成了索引块,步骤如下图:
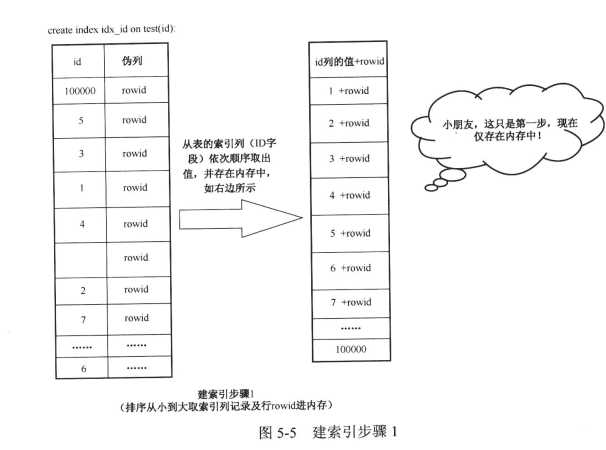
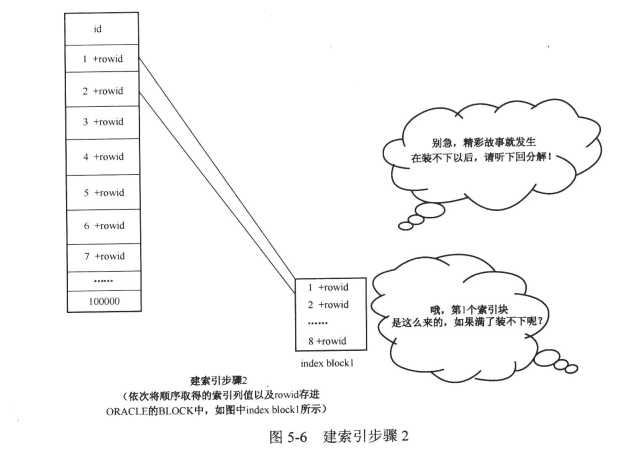
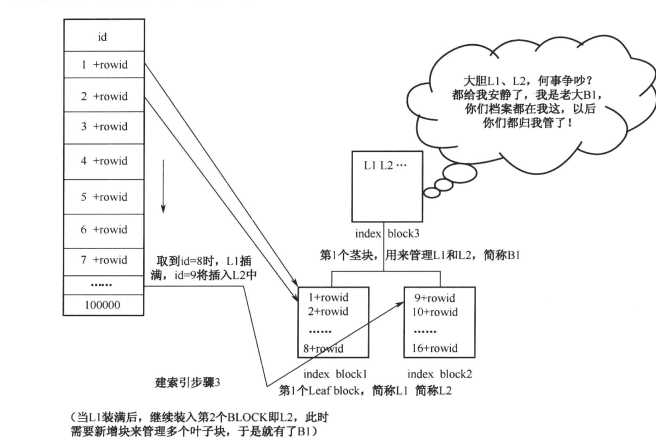
步骤总结:
1.要建索引先排序 ,所以索引其实是有序的
2.列值入块成索引,索引块就是这么来的
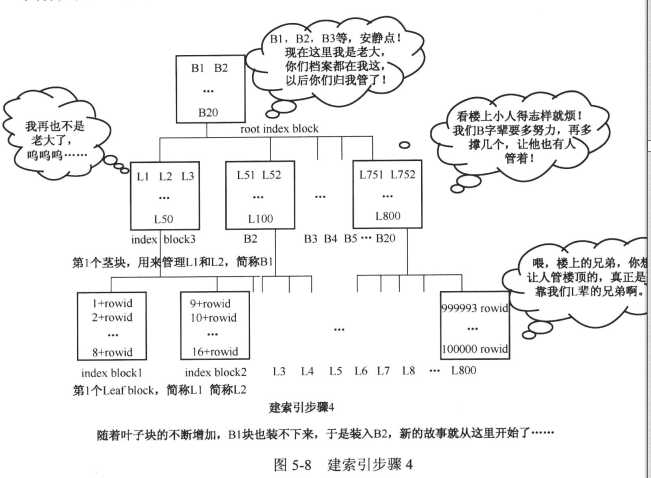
3.填满一块接一块,数据量增大在索引的体现,就是叶子块横向扩展
4.同级两块需人管,叶子块有2个或以上时候,就需要有一个老大来管理多个叶子块,这个老大块里放的是没个叶子块的指针,所以索引的高度不容易变得特别大也是这个道理
由此,也可以得到索引的三大特点:

验证以上理论,可以根据书上例子自己本地试验一下,



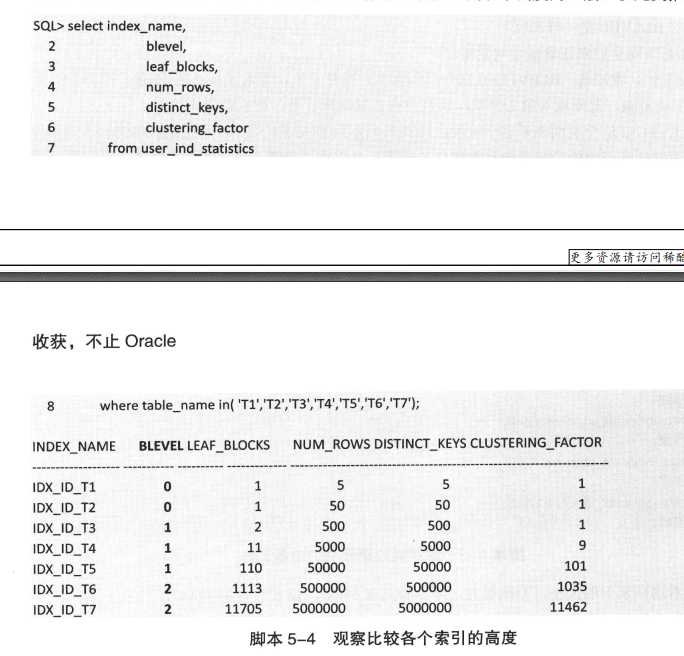
可以通过执行计划看一下索引高度相同的表的查询语句,是不是耗费成本一样,因为产生IO次数一样;而索引高度再高,根据索引去查询数据,也就多了几次IO,速度也是很快(在例子中,查询只返回一条的情况下)
为什么索引建立的时候,要选择选择率高的字段,比如一个表只有几个状态,不应该建索引?
根据以上理论,可以知道,如果10w数据根据索引查询出有5w,IO次数相当于5w*3次IO,
而全表扫描是远远没有那么多的,就算一条一条扫描也最多10w,更不用说全表扫描,一次可以扫多个数据块了。
以上是关于oracle树状索引详解(图摘取《收获不止oracle》)的主要内容,如果未能解决你的问题,请参考以下文章