程序员必备知识(操作系统5-文件系统)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了程序员必备知识(操作系统5-文件系统)相关的知识,希望对你有一定的参考价值。
参考技术A 本篇与之前的第三篇的内存管理知识点有相似的地方对于运行的进程来说,内存就像一个纸箱子, 仅仅是一个暂存数据的地方, 而且空间有限。如果我们想要进程结束之后,数据依然能够保存下来,就不能只保存在内存里,而是应该保存在 外部存储 中。就像图书馆这种地方,不仅空间大,而且能够永久保存。
我们最常用的外部存储就是 硬盘 ,数据是以文件的形式保存在硬盘上的。为了管理这些文件,我们在规划文件系统的时候,需要考虑到以下几点。
第一点,文件系统要有严格的组织形式,使得文件能够 以块为单位进行存储 。这就像图书馆里,我们会给设置一排排书架,然后再把书架分成一个个小格子,有的项目存放的资料非常多,一个格子放不下,就需要多个格子来进行存放。我们把这个区域称为存放原始资料的 仓库区 。
第二点,文件系统中也要有 索引区 ,用来方便查找一个文件分成的多个块都存放在了什么位置。这就好比,图书馆的书太多了,为了方便查找,我们需要专门设置一排书架,这里面会写清楚整个档案库有哪些资料,资料在哪个架子的哪个格子上。这样找资料的时候就不用跑遍整个档案库,在这个书架上找到后,直奔目标书架就可以了。
第三点,如果文件系统中有的文件是热点文件,近期经常被读取和写入,文件系统应该有 缓存层 。这就相当于图书馆里面的热门图书区,这里面的书都是畅销书或者是常常被借还的图书。因为借还的次数比较多,那就没必要每次有人还了之后,还放回遥远的货架,我们可以专门开辟一个区域, 放置这些借还频次高的图书。这样借还的效率就会提高。
第四点,文件应该用 文件夹 的形式组织起来,方便管理和查询。这就像在图书馆里面,你可以给这些资料分门别类,比如分成计算机类.文学类.历史类等等。这样你也容易管理,项目组借阅的时候只要在某个类别中去找就可以了。
在文件系统中,每个文件都有一个名字,这样我们访问一个文件,希望通过它的名字就可以找到。文件名就是一个普通的文本。 当然文件名会经常冲突,不同用户取相同的名字的情况还是会经常出现的。
要想把很多的文件有序地组织起来,我们就需要把它们成为 目录 或者文件夹。这样,一个文件夹里可以包含文件夹,也可以包含文件,这样就形成了一种 树形结构 。而我们可以将不同的用户放在不同的用户目录下,就可以一定程度上避免了命名的冲突问题。
第五点,Linux 内核要在自己的内存里面维护一套数据结构,来保存哪些文件被哪些进程打开和使用 。这就好比,图书馆里会有个图书管理系统,记录哪些书被借阅了,被谁借阅了,借阅了多久,什么时候归还。
文件系统是操作系统中负责管理持久数据的子系统,说简单点,就是负责把用户的文件存到磁盘硬件中,因为即使计算机断电了,磁盘里的数据并不会丢失,所以可以持久化的保存文件。
文件系统的基本数据单位是 文件 ,它的目的是对磁盘上的文件进行组织管理,那组织的方式不同,就会形成不同的文件系统。
Linux最经典的一句话是:“一切皆文件”,不仅普通的文件和目录,就连块设备、管道、socket 等,也都是统一交给文件系统管理的。
Linux文件系统会为每个文件分配两个数据结构: 索引节点(index node) 和 目录项(directory entry) ,它们主要用来记录文件的元信息和目录层次结构。
●索引节点,也就是inode, 用来记录文件的元信息,比如inode编号、文件大小访问权限、创建时间、修改时间、 数据在磁盘的位置 等等。 索引节点是文件的唯一标识 ,它们之间一一对应, 也同样都会被 存储在硬盘 中,所以索引节点同样占用磁盘空间。
●目录项,也就是dentry, 用来记录文件的名字、索引节点指针以及与其他目录项的层级关联关系。多个目录项关联起来,就会形成 目录结构 ,但它与索引节点不同的是,目录项是由内核维护的一个数据结构,不存放于磁盘,而是 缓存在内存 。
由于索引节点唯一标识一个文件,而目录项记录着文件的名,所以目录项和索引节点的关系是多对一,也就是说,一个文件可以有多个别字。比如,硬链接的实现就是多个目录项中的索引节点指向同一个文件。
注意,目录也是文件,也是用索引节点唯一标识,和普通文件不同的是,普通文件在磁盘里面保存的是文件数据,而目录文件在磁盘里面保存子目录或文件。
(PS:目录项和目录不是一个东西!你也不是一个东西(^_=), 虽然名字很相近,但目录是个文件。持久化存储在磁盘,而目录项是内核一个数据结构,缓存在内存。
如果查询目录频繁从磁盘读,效率会很低,所以内核会把已经读过的目录用目录项这个数据结构缓存在内存,下次再次读到相同的目录时,只需从内存读就可以,大大提高了 文件系统的效率。
目录项这个数据结构不只是表示目录,也是可以表示文件的。)
磁盘读写的最小单位是 扇区 ,扇区的大小只有512B大小,很明显,如果每次读写都以这么小为单位,那这读写的效率会非常低。
所以,文件系统把多个扇区组成了一个 逻辑块 ,每次读写的最小单位就是逻辑块(数据块) , Linux中的逻辑块大小为4KB,也就是一次性读写 8个扇区,这将大大提高了磁盘的读写的效率。
以上就是索引节点、目录项以及文件数据的关系,下面这个图就很好的展示了它们之间的关系:
索引节点是存储在硬盘上的数据,那么为了加速文件的访问,通常会把索引节点加载到内存中。
另外,磁盘进行格式化的时候,会被分成三个存储区域,分别是超级块、索引节点区和数据块区。
●超级块,用来存储文件系统的详细信息,比如块个数、块大小、空闲块等等。
●索引节点区,用来存储索引节点;
●数据块区,用来存储文件或目录数据;
我们不可能把超级块和索引节点区全部加载到内存,这样内存肯定撑不住,所以只有当需要使用的时候,才将其加载进内存,它们加载进内存的时机是不同的.
●超级块:当文件系统挂载时进入内存;
●索引节点区:当文件被访问时进入内存;
文件系统的种类众多,而操作系统希望 对用户提供一个统一的接口 ,于是在用户层与文件系统层引入了中间层,这个中间层就称为 虚拟文件系统(Virtual File System, VFS) 。
VFS定义了一组所有文件系统都支持的数据结构和标准接口,这样程序员不需要了解文件系统的工作原理,只需要了解VFS提供的统一接口即可。
在Linux文件系统中,用户空间、系统调用、虚拟机文件系统、缓存、文件系统以及存储之间的关系如下图:
Linux支持的文件系统也不少,根据存储位置的不同,可以把文件系统分为三类:
●磁盘的文件系统,它是直接把数据存储在磁盘中,比如Ext 2/3/4. XFS 等都是这类文件系统。
●内存的文件系统,这类文件系统的数据不是存储在硬盘的,而是占用内存空间,我们经常用到的/proc 和/sys文件系统都属于这一类,读写这类文件,实际上是读写内核中相关的数据。
●网络的文件系统,用来访问其他计算机主机数据的文件系统,比如NFS. SMB等等。
文件系统首先要先挂载到某个目录才可以正常使用,比如Linux系统在启动时,会把文件系统挂载到根目录。
在操作系统的辅助之下,磁盘中的数据在计算机中都会呈现为易读的形式,并且我们不需要关心数据到底是如何存放在磁盘中,存放在磁盘的哪个地方等等问题,这些全部都是由操作系统完成的。
那么,文件数据在磁盘中究竟是怎么样的呢?我们来一探究竟!
磁盘中的存储单元会被划分为一个个的“ 块 ”,也被称为 扇区 ,扇区的大小一般都为512byte.这说明即使一块数据不足512byte,那么它也要占用512byte的磁盘空间。
而几乎所有的文件系统都会把文件分割成固定大小的块来存储,通常一个块的大小为4K。如果磁盘中的扇区为512byte,而文件系统的块大小为4K,那么文件系统的存储单元就为8个扇区。这也是前面提到的一个问题,文件大小和占用空间之间有什么区别?文件大小是文件实际的大小,而占用空间则是因为即使它的实际大小没有达到那么大,但是这部分空间实际也被占用,其他文件数据无法使用这部分的空间。所以我们 写入1byte的数据到文本中,但是它占用的空间也会是4K。
这里要注意在Windows下的NTFS文件系统中,如果一开始文件数据小于 1K,那么则不会分配磁盘块来存储,而是存在一个文件表中。但是一旦文件数据大于1K,那么不管以后文件的大小,都会分配以4K为单位的磁盘空间来存储。
与内存管理一样,为了方便对磁盘的管理,文件的逻辑地址也被分为一个个的文件块。于是文件的逻辑地址就是(逻辑块号,块内地址)。用户通过逻辑地址来操作文件,操作系统负责完成逻辑地址与物理地址的映射。
不同的文件系统为文件分配磁盘空间会有不同的方式,这些方式各自都有优缺点。
连续分配要求每个文件在磁盘上有一组连续的块,该分配方式较为简单。
通过上图可以看到,文件的逻辑块号的顺序是与物理块号相同的,这样就可以实现随机存取了,只要知道了第一个逻辑块的物理地址, 那么就可以快速访问到其他逻辑块的物理地址。那么操作系统如何完成逻辑块与物理块之间的映射呢?实际上,文件都是存放在目录下的,而目录是一种有结构文件, 所以在文件目录的记录中会存放目录下所有文件的信息,每一个文件或者目录都是一个记录。 而这些信息就包括文件的起始块号和占有块号的数量。
那么操作系统如何完成逻辑块与物理块之间的映射呢? (逻辑块号, 块内地址) -> (物理块号, 块内地址),只需要知道逻辑块号对应的物理块号即可,块内地址不变。
用户访问一个文件的内容,操作系统通过文件的标识符找到目录项FCB, 物理块号=起始块号+逻辑块号。 当然,还需要检查逻辑块号是否合法,是否超过长度等。因为可以根据逻辑块号直接算出物理块号,所以连续分配支持 顺序访问和随机访问 。
因为读/写文件是需要移动磁头的,如果访问两个相隔很远的磁盘块,移动磁头的时间就会变长。使用连续分配来作为文件的分配方式,会使文件的磁盘块相邻,所以文件的读/写速度最快。
连续空间存放的方式虽然读写效率高,但是有 磁盘空间碎片 和 文件长度不易扩展 的缺陷。
如下图,如果文件B被删除,磁盘上就留下一块空缺,这时,如果新来的文件小于其中的一个空缺,我们就可以将其放在相应空缺里。但如果该文件的大小大于所
有的空缺,但却小于空缺大小之和,则虽然磁盘上有足够的空缺,但该文件还是不能存放。当然了,我们可以通过将现有文件进行挪动来腾出空间以容纳新的文件,但是这个在磁盘挪动文件是非常耗时,所以这种方式不太现实。
另外一个缺陷是文件长度扩展不方便,例如上图中的文件A要想扩大一下,需要更多的磁盘空间,唯一的办法就只能是挪动的方式,前面也说了,这种方式效率是非常低的。
那么有没有更好的方式来解决上面的问题呢?答案当然有,既然连续空间存放的方式不太行,那么我们就改变存放的方式,使用非连续空间存放方式来解决这些缺陷。
非连续空间存放方式分为 链表方式 和 索引方式 。
链式分配采取离散分配的方式,可以为文件分配离散的磁盘块。它有两种分配方式:显示链接和隐式链接。
隐式链接是只目录项中只会记录文件所占磁盘块中的第一块的地址和最后一块磁盘块的地址, 然后通过在每一个磁盘块中存放一个指向下一 磁盘块的指针, 从而可以根据指针找到下一块磁盘块。如果需要分配新的磁盘块,则使用最后一块磁盘块中的指针指向新的磁盘块,然后修改新的磁盘块为最后的磁盘块。
我们来思考一个问题, 采用隐式链接如何将实现逻辑块号转换为物理块号呢?
用户给出需要访问的逻辑块号i,操作系统需要找到所需访问文件的目录项FCB.从目录项中可以知道文件的起始块号,然后将逻辑块号0的数据读入内存,由此知道1号逻辑块的物理块号,然后再读入1号逻辑块的数据进内存,此次类推,最终可以找到用户所需访问的逻辑块号i。访问逻辑块号i,总共需要i+ 1次磁盘1/0操作。
得出结论: 隐式链接分配只能顺序访问,不支持随机访问,查找效率低 。
我们来思考另外一个问题,采用隐式链接是否方便文件拓展?
我们知道目录项中存有结束块号的物理地址,所以我们如果要拓展文件,只需要将新分配的磁盘块挂载到结束块号的后面即可,修改结束块号的指针指向新分配的磁盘块,然后修改目录项。
得出结论: 隐式链接分配很方便文件拓展。所有空闲磁盘块都可以被利用到,无碎片问题,存储利用率高。
显示链接是把用于链接各个物理块的指针显式地存放在一张表中,该表称为文件分配表(FAT, File Allocation Table)。
由于查找记录的过程是在内存中进行的,因而不仅显著地 提高了检索速度 ,而且 大大减少了访问磁盘的次数 。但也正是整个表都存放在内存中的关系,它的主要的缺点是 不适 用于大磁盘 。
比如,对于200GB的磁盘和1KB大小的块,这张表需要有2亿项,每一项对应于这2亿个磁盘块中的一个块,每项如果需要4个字节,那这张表要占用800MB内存,很显然FAT方案对于大磁盘而言不太合适。
一直都在,加油!(*゜Д゜)σ凸←自爆按钮
链表的方式解决了连续分配的磁盘碎片和文件动态打展的问题,但是不能有效支持直接访问(FAT除外) ,索引的方式可以解决这个问题。
索引的实现是为每个文件创建一个 索引数据块 ,里面存放的 是指向文件数据块的指针列表 ,说白了就像书的目录一样,要找哪个章节的内容,看目录查就可以。
另外, 文件头需要包含指向索引数据块的指针 ,这样就可以通过文件头知道索引数据块的位置,再通过索弓|数据块里的索引信息找到对应的数据块。
创建文件时,索引块的所有指针都设为空。当首次写入第i块时,先从空闲空间中取得一个块, 再将其地址写到索引块的第i个条目。
索引的方式优点在于:
●文件的创建、增大、缩小很方便;
●不会有碎片的问题;
●支持顺序读写和随机读写;
由于索引数据也是存放在磁盘块的,如果文件很小,明明只需一块就可以存放的下,但还是需要额外分配一块来存放索引数据,所以缺陷之一就是存储索引带来的开销。
如果文件很大,大到一个索引数据块放不下索引信息,这时又要如何处理大文件的存放呢?我们可以通过组合的方式,来处理大文件的存储。
先来看看 链表+索引 的组合,这种组合称为 链式索引块 ,它的实现方式是在 索引数据块留出一个存放下一个索引数据块的指针 ,于是当一个索引数据块的索引信息用完了,就可以通过指针的方式,找到下一个索引数据块的信息。那这种方式也会出现前面提到的链表方式的问题,万一某个指针损坏了,后面的数据也就会无法读取了。
还有另外一种组合方式是 索引+索引 的方式,这种组合称为多级索引块,实现方式是通过一个索引块来存放多个索引数据块,一层套一层索引, 像极了俄罗斯套娃是吧๑乛◡乛๑
前面说到的文件的存储是针对已经被占用的数据块组织和管理,接下来的问题是,如果我要保存一个数据块, 我应该放在硬盘上的哪个位置呢?难道需要将所有的块扫描一遍,找个空的地方随便放吗?
那这种方式效率就太低了,所以针对磁盘的空闲空间也是要引入管理的机制,接下来介绍几种常见的方法:
●空闲表法
●空闲链表法
●位图法
空闲表法
空闲表法就是为所有空闲空间建立一张表,表内容包括空闲区的第一个块号和该空闲区的块个数,注意,这个方式是连续分配的。如下图:
当请求分配磁盘空间时,系统依次扫描空闲表里的内容,直到找到一个合适的空闲区域为止。当用户撤销一个文件时,系统回收文件空间。这时,也需顺序扫描空闲表,寻找一个空闲表条目并将释放空间的第一个物理块号及它占用的块数填到这个条目中。
这种方法仅当有少量的空闲区时才有较好的效果。因为,如果存储空间中有着大量的小的空闲区,则空闲表变得很大,这样查询效率会很低。另外,这种分配技术适用于建立连续文件。
空闲链表法
我们也可以使用链表的方式来管理空闲空间,每一个空闲块里有一个指针指向下一个空闲块,这样也能很方便的找到空闲块并管理起来。如下图:
当创建文件需要一块或几块时,就从链头上依次取下一块或几块。反之,当回收空间时,把这些空闲块依次接到链头上。
这种技术只要在主存中保存一个指针, 令它指向第一个空闲块。其特点是简单,但不能随机访问,工作效率低,因为每当在链上增加或移动空闲块时需要做很多1/0操作,同时数据块的指针消耗了一定的存储空间。
空闲表法和空闲链表法都不适合用于大型文件系统,因为这会使空闲表或空闲链表太大。
位图法
位图是利用二进制的一位来表示磁盘中一个盘块的使用情况,磁盘上所有的盘块都有一个二进制位与之对应。
当值为0时,表示对应的盘块空闲,值为1时,表示对应的盘块已分配。它形式如下:
在Linux文件系统就采用了位图的方式来管理空闲空间,不仅用于数据空闲块的管理,还用于inode空闲块的管理,因为inode也是存储在磁盘的,自然也要有对其管理。
前面提到Linux是用位图的方式管理空闲空间,用户在创建一个新文件时, Linux 内核会通过inode的位图找到空闲可用的inode,并进行分配。要存储数据时,会通过块的位图找到空闲的块,并分配,但仔细计算一下还是有问题的。
数据块的位图是放在磁盘块里的,假设是放在一个块里,一个块4K,每位表示一个数据块,共可以表示4 * 1024 * 8 = 2^15个空闲块,由于1个数据块是4K大小,那么最大可以表示的空间为2^15 * 4 * 1024 = 2^27个byte,也就是128M。
也就是说按照上面的结构,如果采用(一个块的位图+ 一系列的块),外加一(个块的inode的位图+一系列的inode)的结构能表示的最大空间也就128M,
这太少了,现在很多文件都比这个大。
在Linux文件系统,把这个结构称为一个 块组 ,那么有N多的块组,就能够表示N大的文件。
最终,整个文件系统格式就是下面这个样子。
最前面的第一个块是引导块,在系统启动时用于启用引导,接着后面就是一个一个连续的块组了,块组的内容如下:
● 超级块 ,包含的是文件系统的重要信息,比如inode总个数、块总个数、每个块组的inode个数、每个块组的块个数等等。
● 块组描述符 ,包含文件系统中各个块组的状态,比如块组中空闲块和inode的数目等,每个块组都包含了文件系统中「所有块组的组描述符信息」。
● 数据位图和inode位图 ,用于表示对应的数据块或inode是空闲的,还是被使用中。
● inode 列表 ,包含了块组中所有的inode, inode 用于保存文件系统中与各个文件和目录相关的所有元数据。
● 数据块 ,包含文件的有用数据。
你可以会发现每个块组里有很多重复的信息,比如 超级块和块组描述符表,这两个都是全局信息,而且非常的重要 ,这么做是有两个原因:
●如果系统崩溃破坏了超级块或块组描述符,有关文件系统结构和内容的所有信息都会丢失。如果有冗余的副本,该信息是可能恢复的。
●通过使文件和管理数据尽可能接近,减少了磁头寻道和旋转,这可以提高文件系统的性能。
不过,Ext2 的后续版本采用了稀疏技术。该做法是,超级块和块组描述符表不再存储到文件系统的每个块组中,而是只写入到块组0、块组1和其他ID可以表示为3、5、7的幂的块组中。
在前面,我们知道了一个普通文件是如何存储的,但还有一个特殊的文件,经常用到的目录,它是如何保存的呢?
基于Linux 一切切皆文件的设计思想,目录其实也是个文件,你甚至可以通过vim打开它,它也有inode, inode 里面也是指向一些块。
和普通文件不同的是, 普通文件的块里面保存的是文件数据,而目录文件的块里面保存的是目录里面一项一项的文件信息 。
在目录文件的块中,最简单的保存格式就是 列表 ,就是一项一项地将目录下的文件信息(如文件名、文件inode.文件类型等)列在表里。
列表中每一项就代表该目录下的文件的文件名和对应的inode,通过这个inode,就可以找到真正的文件。
通常,第一项是「则」,表示当前目录,第二项是.,表示上一级目录, 接下来就是一项一项的文件名和inode。
如果一个目录有超级多的文件,我们要想在这个目录下找文件,按照列表一项一项的找,效率就不高了。
于是,保存目录的格式改成 哈希表 ,对文件名进行哈希计算,把哈希值保存起来,如果我们要查找一个目录下面的文件名,可以通过名称取哈希。如果哈希能够匹配上,就说明这个文件的信息在相应的块里面。
Linux系统的ext文件系统就是采用了哈希表,来保存目录的内容,这种方法的优点是查找非常迅速,插入和删除也较简单,不过需要一些预备措施来避免哈希冲突。
目录查询是通过在磁盘上反复搜索完成,需要不断地进行/0操作,开销较大。所以,为了减少/0操作,把当前使用的文件目录缓存在内存,以后要使用该文件时只要在内存中操作,从而降低了磁盘操作次数,提高了文件系统的访问速度。
感谢您的阅读,希望您能摄取到知识!加油!冲冲冲!(发现光,追随光,成为光,散发光!)我是程序员耶耶!有缘再见。<-biubiu-⊂(`ω´∩)
后端程序员必备的Linux基础知识
历史文章推荐:
2)
学习Linux之前,我们先来简单的认识一下操作系统。
一 从认识操作系统开始
1.1 操作系统简介
我通过以下四点介绍什么操作系统:
操作系统(Operation System,简称OS)是管理计算机硬件与软件资源的程序,是计算机系统的内核与基石;
操作系统本质上是运行在计算机上的软件程序 ;
为用户提供一个与系统交互的操作界面 ;
操作系统分内核与外壳(我们可以把外壳理解成围绕着内核的应用程序,而内核就是能操作硬件的程序)。
1.2 操作系统简单分类
Windows: 目前最流行的个人桌面操作系统 ,不做多的介绍,大家都清楚。
Unix: 最早的多用户、多任务操作系统 .按照操作系统的分类,属于分时操作系统。Unix 大多被用在服务器、工作站,现在也有用在个人计算机上。它在创建互联网、计算机网络或客户端/服务器模型方面发挥着非常重要的作用。

Linux: Linux是一套免费使用和自由传播的类Unix操作系统.Linux存在着许多不同的Linux版本,但它们都使用了 Linux内核 。Linux可安装在各种计算机硬件设备中,比如手机、平板电脑、路由器、视频游戏控制台、台式计算机、大型机和超级计算机。严格来讲,Linux这个词本身只表示Linux内核,但实际上人们已经习惯了用Linux来形容整个基于Linux内核,并且使用GNU 工程各种工具和数据库的操作系统。
二 初探Linux
2.1 Linux简介
我们上面已经介绍到了Linux,我们这里只强调三点。
类Unix系统: Linux是一种自由、开放源码的类似Unix的操作系统
Linux内核: 严格来说,Linux这个词本身只表示Linux内核
Linux之父: 一个编程领域的传奇式人物。他是Linux内核的最早作者,随后发起了这个开源项目,担任Linux内核的首要架构师与项目协调者,是当今世界最著名的电脑程序员、黑客之一。他还发起了Git这个开源项目,并为主要的开发者。

2.2 Linux诞生简介
1991年,芬兰的业余计算机爱好者Linus Torvalds编写了一款类似Minix的系统(基于微内核架构的类Unix操作系统)被ftp管理员命名为Linux 加入到自由软件基金的GNU计划中;
Linux以一只可爱的企鹅作为标志,象征着敢作敢为、热爱生活。

2.3 Linux的分类
Linux根据原生程度,分为两种:
内核版本: Linux不是一个操作系统,严格来讲,Linux只是一个操作系统中的内核。内核是什么?内核建立了计算机软件与硬件之间通讯的平台,内核提供系统服务,比如文件管理、虚拟内存、设备I/O等;
发行版本: 一些组织或公司在内核版基础上进行二次开发而重新发行的版本。Linux发行版本有很多种(ubuntu和CentOS用的都很多,初学建议选择CentOS),如下图所示:

三 Linux文件系统概览
3.1 Linux文件系统简介
在Linux操作系统中,所有被操作系统管理的资源,例如网络接口卡、磁盘驱动器、打印机、输入输出设备、普通文件或是目录都被看作是一个文件。
也就是说在LINUX系统中有一个重要的概念:一切都是文件。其实这是UNIX哲学的一个体现,而Linux是重写UNIX而来,所以这个概念也就传承了下来。在UNIX系统中,把一切资源都看作是文件,包括硬件设备。UNIX系统把每个硬件都看成是一个文件,通常称为设备文件,这样用户就可以用读写文件的方式实现对硬件的访问。
3.2 文件类型与目录结构
Linux支持5种文件类型 :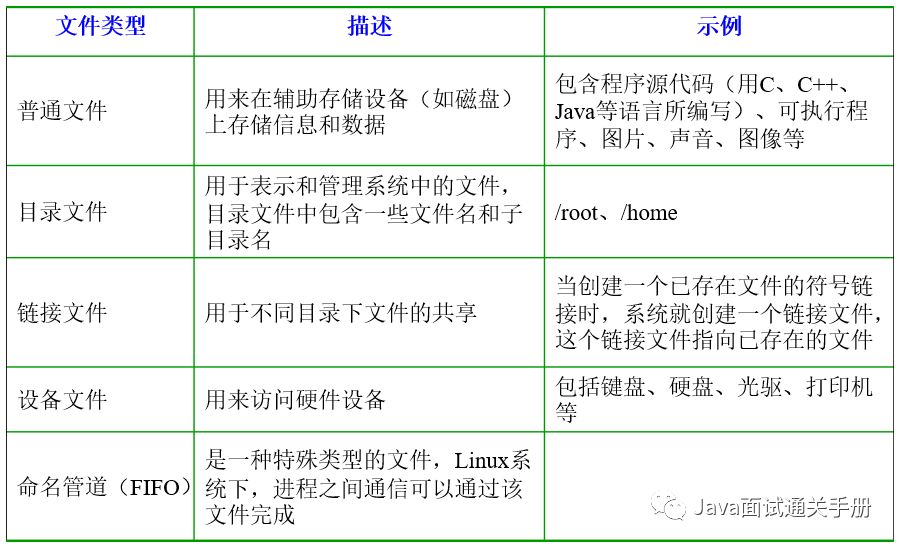
Linux的目录结构如下:
Linux文件系统的结构层次鲜明,就像一棵倒立的树,最顶层是其根目录: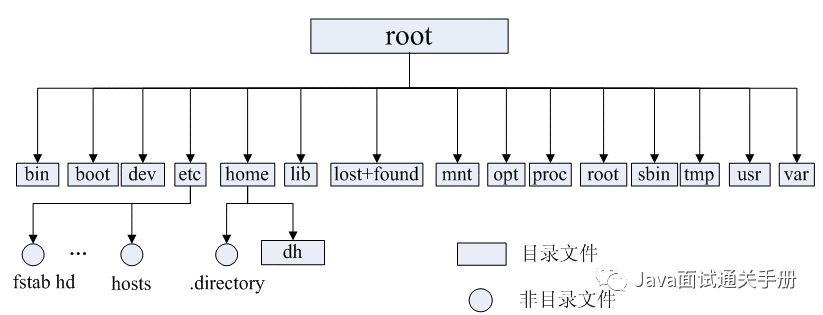
常见目录说明:
/bin: 存放二进制可执行文件(ls,cat,mkdir等),常用命令一般都在这里;
/etc: 存放系统管理和配置文件;
/home: 存放所有用户文件的根目录,是用户主目录的基点,比如用户user的主目录就是/home/user,可以用~user表示;
/usr : 用于存放系统应用程序;
/opt: 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把tomcat等都安装到这里;
/proc: 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
/root: 超级用户(系统管理员)的主目录(特权阶级^o^);
/sbin: 存放二进制可执行文件,只有root才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如ifconfig等;
/dev: 用于存放设备文件;
/mnt: 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
/boot: 存放用于系统引导时使用的各种文件;
/lib : 存放着和系统运行相关的库文件 ;
/tmp: 用于存放各种临时文件,是公用的临时文件存储点;
/var: 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
/lost+found: 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里。
四 Linux基本命令
下面只是给出了一些比较常用的命令。推荐一个Linux命令快查网站,非常不错,大家如果遗忘某些命令或者对某些命令不理解都可以在这里得到解决。
Linux命令大全:http://man.linuxde.net/ (复制该链接后浏览器打开即可访问)
4.1 目录切换命令
cd usr: 切换到该目录下usr目录cd..(或cd../): 切换到上一层目录cd/: 切换到系统根目录cd~: 切换到用户主目录cd-: 切换到上一个所在目录
4.2 目录的操作命令(增删改查)
mkdir目录名称: 增加目录ls或者ll(ll是ls -l的缩写,ll命令以看到该目录下的所有目录和文件的详细信息):查看目录信息
find目录参数: 寻找目录(查)示例(根据文件或者正则表达式进行匹配):
1)列出当前目录及子目录下所有文件和文件夹:
find.2)在
/home目录下查找以.txt结尾的文件名:find/home-name"*.txt"3)同上,但忽略大小写:
find/home-iname"*.txt"4)当前目录及子目录下查找所有以.txt和.pdf结尾的文件:
find.(-name"*.txt"-o-name"*.pdf")或find.-name"*.txt"-o-name"*.pdf"
mv目录名称新目录名称: 修改目录的名称(改)注意:mv的语法不仅可以对目录进行重命名而且也可以对各种文件,压缩 包等进行 重命名的操作。mv命令用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中。后面会介绍到mv命令的另一个用法。
mv目录名称目录的新位置: 移动目录的位置---剪切(改)注意:mv语法不仅可以对目录进行剪切操作,对文件和压缩包等都可执行剪切操作。另外mv与cp的结果不同,mv好像文件“搬家”,文件个数并未增加。而cp对文件进行复制,文件个数增加了。
cp-r目录名称目录拷贝的目标位置: 拷贝目录(改),-r代表递归拷贝注意:cp命令不仅可以拷贝目录还可以拷贝文件,压缩包等,拷贝文件和压缩包时不 用写-r递归
rm[-rf]目录: 删除目录(删)注意:rm不仅可以删除目录,也可以删除其他文件或压缩包,为了增强大家的记忆, 无论删除任何目录或文件,都直接使用
rm-rf目录/文件/压缩包
4.3 文件的操作命令(增删改查)
touch文件名称: 文件的创建(增)cat/more/less/tail文件名称文件的查看(查)cat: 只能显示最后一屏内容more: 可以显示百分比,回车可以向下一行, 空格可以向下一页,q可以退出查看less: 可以使用键盘上的PgUp和PgDn向上 和向下翻页,q结束查看tail-10: 查看文件的后10行,Ctrl+C结束注意:命令 tail -f 文件 可以对某个文件进行动态监控,例如tomcat的日志文件, 会随着程序的运行,日志会变化,可以使用tail -f catalina-2016-11-11.log 监控 文 件的变化
vim文件: 修改文件的内容(改)vim编辑器是Linux中的强大组件,是vi编辑器的加强版,vim编辑器的命令和快捷方式有很多,但此处不一一阐述,大家也无需研究的很透彻,使用vim编辑修改文件的方式基本会使用就可以了。
在实际开发中,使用vim编辑器主要作用就是修改配置文件,下面是一般步骤:
vim 文件------>进入文件----->命令模式------>按i进入编辑模式----->编辑文件 ------->按Esc进入底行模式----->输入:wq/q! (输入wq代表写入内容并退出,即保存;输入q!代表强制退出不保存。)
rm-rf文件: 删除文件(删)同目录删除:熟记
rm-rf文件 即可
4.4 压缩文件的操作命令
1)打包并压缩文件:
Linux中的打包文件一般是以.tar结尾的,压缩文件一般是以.gz结尾的。
而一般情况下打包和压缩是一起进行的,打包并压缩后的文件的后缀名一般.tar.gz。 命令: tar-zcvf打包压缩后的文件名要打包压缩的文件
其中:
z:调用gzip压缩命令进行压缩
c:打包文件
v:显示运行过程
f:指定文件名
比如:加入test目录下有三个文件分别是 :aaa.txt bbb.txt ccc.txt,如果我们要打包test目录并指定压缩后的压缩包名称为test.tar.gz可以使用命令: tar-zcvf test.tar.gz aaa.txt bbb.txt ccc.txt或: tar-zcvf test.tar.gz/test/
2)解压压缩包:
命令:tar [-xvf] 压缩文件
其中:x:代表解压
示例:
1 将/test下的test.tar.gz解压到当前目录下可以使用命令: tar-xvf test.tar.gz
2 将/test下的test.tar.gz解压到根目录/usr下: tar-xvf xxx.tar.gz-C/usr(- C代表指定解压的位置)
4.5 Linux的权限命令
操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在Linux中权限一般分为读(readable)、写(writable)和执行(excutable)三组。通过 ls-l 命令我们可以 查看某个目录下的文件或目录的权限。
示例:在随意某个目录下 ls-l
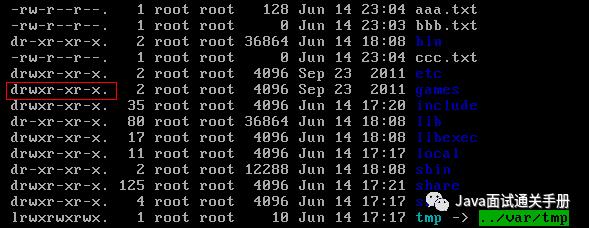
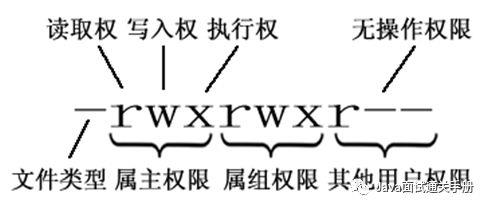
第一列的内容的信息解释如下:
下面将详细讲解文件的类型、Linux中权限以及文件有所有者、所在组、其它组具体是什么?
文件的类型:
d: 代表目录
-: 代表文件
l: 代表链接(可以认为是window中的快捷方式)
Linux中权限分为以下几种:
r:代表权限是可读,r也可以用数字4表示
w:代表权限是可写,w也可以用数字2表示
x:代表权限是可执行,x也可以用数字1表示
文件和目录权限的区别:
对文件和目录而言,读写执行表示不同的意义。
对于文件:
| 权限名称 | 可执行操作 |
|---|---|
| r | 可以使用cat查看文件的内容 |
| w | 可以修改文件的内容 |
| x | 可以将其运行为二进制文件 |
对于目录:
| 权限名称 | 可执行操作 |
|---|---|
| r | 可以查看目录下列表 |
| w | 可以创建和删除目录下文件 |
| x | 可以使用cd进入目录 |
在linux中的每个用户必须属于一个组,不能独立于组外。在linux中每个文件有所有者、所在组、其它组的概念。
所有者
一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用ls ‐ahl命令可以看到文件的所有者 也可以使用chown 用户名 文件名来修改文件的所有者 。
文件所在组
当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组 用ls ‐ahl命令可以看到文件的所有组 也可以使用chgrp 组名 文件名来修改文件所在的组。
其它组
除开文件的所有者和所在组的用户外,系统的其它用户都是文件的其它组
我们再来看看如何修改文件/目录的权限。
修改文件/目录的权限的命令: chmod
示例:修改/test下的aaa.txt的权限为属主有全部权限,属主所在的组有读写权限, 其他用户只有读的权限
chmod u=rwx,g=rw,o=r aaa.txt
上述示例还可以使用数字表示:
chmod 764 aaa.txt
补充一个比较常用的东西:
假如我们装了一个zookeeper,我们每次开机到要求其自动启动该怎么办?
新建一个自动运行zookeeper的脚本,名称为“zookeeper”
为新建的脚本zookeeper添加可执行权限,命令是:
chmod+x zookeeper把zookeeper这个脚本添加到开机启动项里面,命令是:
chkconfig--add zookeeper如果想看看是否添加成功,命令是:
chkconfig--list
4.6 Linux 用户管理命令
Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。
用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护。
Linux用户管理相关命令:
useradd选项用户名:添加用户账号userdel选项用户名:删除用户帐号usermod选项用户名:修改帐号passwd用户名:更改或创建用户的密码passwd-S用户名:显示用户账号密码信息passwd-d用户名: 清除用户密码
useradd命令用于Linux中创建的新的系统用户。useradd可用来建立用户帐号。帐号建好之后,再用passwd设定帐号的密码.而可用userdel删除帐号。使用useradd指令所建立的帐号,实际上是保存在/etc/passwd文本文件中。
passwd命令用于设置用户的认证信息,包括用户密码、密码过期时间等。系统管理者则能用它管理系统用户的密码。只有管理者可以指定用户名称,一般用户只能变更自己的密码。
4.7 Linux系统用户组的管理命令
每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同Linux 系统对用户组的规定有所不同,如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对/etc/group文件的更新。
Linux系统用户组的管理相关命令:
groupadd选项用户组:增加一个新的用户组groupdel用户组:删除一个已有的用户组groupmod选项用户组: 修改用户组的属性
4.8 其他常用命令
pwd: 显示当前所在位置grep要搜索的字符串要搜索的文件--color: 搜索命令,--color代表高亮显示ps-ef/ps aux: 这两个命令都是查看当前系统正在运行进程,两者的区别是展示格式不同。如果想要查看特定的进程可以使用这样的格式:ps aux|grep redis(查看包括redis字符串的进程)注意:如果直接用ps((Process Status))命令,会显示所有进程的状态,通常结合grep命令查看某进程的状态。
kill-9进程的pid: 杀死进程(-9 表示强制终止。)先用ps查找进程,然后用kill杀掉
网络通信命令:
1. 查看当前系统的网卡信息:ifconfig
2. 查看与某台机器的连接情况:ping
3. 查看当前系统的端口使用:netstat -an
shutdown:shutdown-h now: 指定现在立即关机;shutdown+5"System will shutdown after 5 minutes":指定5分钟后关机,同时送出警告信息给登入用户。
reboot:reboot: 重开机。reboot-w: 做个重开机的模拟(只有纪录并不会真的重开机)。
如果你觉得我的文章对你有帮助话,欢迎转发点赞,转发点赞就是对作者最大的鼓励。
以上是关于程序员必备知识(操作系统5-文件系统)的主要内容,如果未能解决你的问题,请参考以下文章
Android开发核心知识点梳理,25~40岁程序员进阶必备