ELK日志收集与监控
Posted seagull-321
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ELK日志收集与监控相关的知识,希望对你有一定的参考价值。
一、ELK介绍
分析数据,日志,统计,聚合分析,了解用户使用使用虚拟机情况。
openstack使用elk的原因:组件多日志多。排查定位问题方便,统一收集错误。创建虚拟机时会生成日志,若出错会产生日志,及时建立模型,可以分析问题。在大量虚拟机环境下,可以对日志进行聚合分析,进行业务分析。估算vm创建的最大值,预知用户在什么时候创建vm,创建vm失败情况。
筛选有价值的日志塞到elasticsearck中,如果 没有日志可以自己创造日志,通过脚本的方式。
下一代智能运维:智能报警,预测报警,在问题出现之前进行报警,当呈现某种趋势时进行报警。
elasticsearch:elasticsearch来存储日志信息.Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。做搜索和数据分析,实时的,只支持json格式。做数据分析价值更大。底层是lunce,是java编写的。
版本要求:jdk1.8以上,目前版本5.2.2(6.0.0)
ELK二次开发价值比较大。
logstash;数据接口,为elasticsearch对接外面过来的log数据,它对接的渠道,有kafka,有log文件,有redis等等.Logstash是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用
kibana:主要用来做数据展现
预测报警+建模
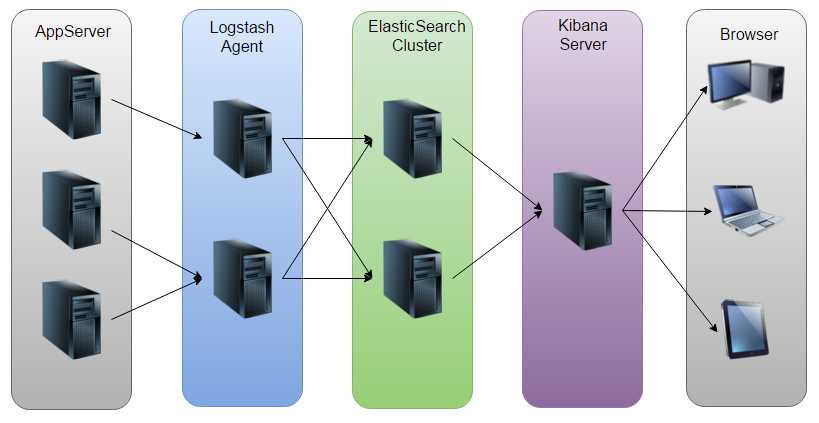
二、如何安装部署ELK
环境准备:
一共 七个vm,每个vm4C8G
前五个运行Elasticsearch,一个装logstash,一个安装k。插件bigdesk和head插件。
不能直接用root用户
screen介绍:http://man.linuxde.net/screen
管理elasticsh集群的两个插件:bigdesk和head
部署步骤:
确保java安装好:
下载java包,解压缩,配置路径,source /etc/profile
tar zxf jdk-8u161-linux-x64.tar.gz
[[email protected] tools]# cat /etc/profile
export JAVA_HOME=/home/seagull/tools/jdk1.8.0_161
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
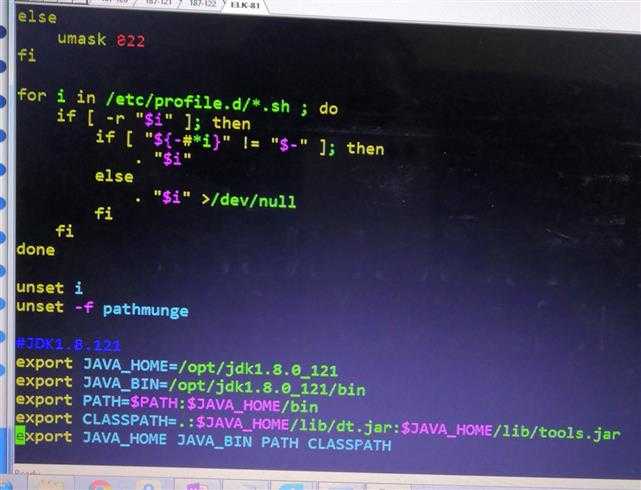
[[email protected] tools]# source /etc/profile
下载几个包,并解压缩
drwxr-xr-x. 8 root root 4096 Mar 13 18:08 elasticsearch-6.2.3
-rw-r--r--. 1 root root 921421 Apr 3 19:11 elasticsearch-head-master.zip
drwxr-xr-x. 8 10 143 4096 Apr 3 19:06 jdk1.8.0_161
drwxrwxr-x. 12 1000 1000 4096 Mar 13 18:25 kibana-6.2.3-linux-x86_64
drwxr-xr-x. 11 root root 4096 Apr 3 19:15 logstash-6.2.3
elasticsearch目录结构层次:
elasticsearch-6.2.3/bin/elastcisearch 启动文件,./elasticsearch -d可以直接启动(需要配置好之后才能启动)
elasticsearch-6.2.3/configure 配置文件
elasticsearch-6.2.3/lib jar包
elasticsearch-6.2.3/plugins 插件
打开最大文件打开数:
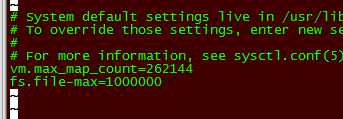
vim /etc/sysctl.conf
vm.max_map_count=262144
fs.file-max=1000000
sysctl -p
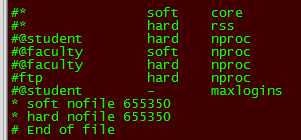
vim /etc/security/limits.conf
* soft nofile 655350
* hard nofile 655350
[[email protected] tools]# ulimit -Hn
655350
修改之后如果没有改变,可以考虑重新启动。
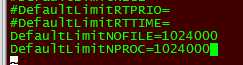
vim /etc/systemd/system.conf
DefaultLimitNOFILE=1024000
DefaultLimitNPROC=1024000
新建用户
[[email protected] tools]# adduser elastic
[[email protected] tools]# mkdir -p /var/log/elasticsearch #创建目录
[[email protected] tools]# mkdir -p /var/lib/elasticsearch/data #存储elasticsearch数据
更改权限
[[email protected] tools]# chown -R elastic:elastic /home/seagull/tools/elasticsearch-6.2.3
[[email protected] tools]# chown -R elastic:elastic /var/log/elasticsearch
[[email protected] tools]# chown -R elastic:elastic /var/lib/elasticsearch/data
[[email protected] tools]# passwd elastic
cd /home/seagull/tools/elasticsearch-6.2.3/config
[[email protected] config]# vim jvm.options
根据实际情况修改下列参数
-Xms4g
-Xmx4g
[[email protected] config]$ vim elasticsearch.yml
配置文件,内容如下:
cluster.name: openstack_newton
node.name: master-node1 #如果不设置,会随机生成一个名字
node.master:true #根据节点的情况设置
node.data:false
action.auto_create_index:true
path.data: /var/lib/elasticsearch/data
path.logs: /var/log/elasticsearch
network.host: 9.110.187.122
http.port: 9200
transport.host:9.110.187.122
transport.tcp.port:9300
discovery.zen.ping.unicast.hosts: ["9.110.187.123"] #绑定除自己之外的所有节点
discovery.zen.minimum_master_nodes: 1
http.cors.enabled:true
http.cors.allow-origin:"*"
注意:权限为elastic:elastic
启动服务:
注意:不能在root下启动,需要切换到elastic用户下进行启动。
[[email protected] config]$ /home/seagull/tools/elasticsearch-6.2.3/bin/elasticsearch -d
检查是否成功:

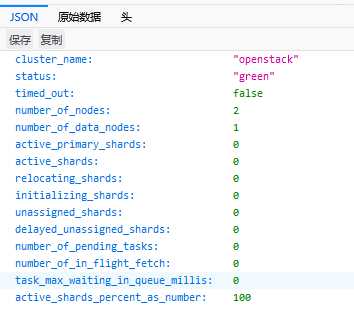
启动时出现内存报错,增加内存解决问题。
elasticsearch目录下面有四个log后缀的文件
vim openstack_newton.log
tail -f openstack_newton.log
在浏览器输入:ip:9200后有代码出现
查询节点状态:
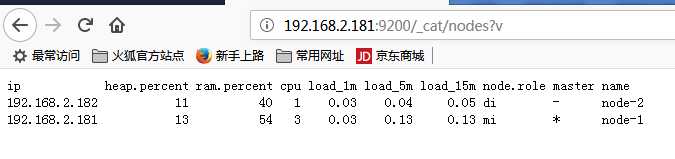
安装head插件:
将插件放到master上面。
elasticsearch-head-master
yum install -y httpd #安装httpd服务
systemctl restart httpd
mv elasticsearch-head-master head
cp -r head/ /var/www/html
在浏览器中输入:ip/head/ #如果不改名,则输入ip/elasticsearch-head-master
bigdesk的安装相同。
安装kibana(也可以yum安装)
cd kibana-5.2.2
cd config
vi kinana.yml
server.port:80 #修改之前的端口,确保80没有被占用
server.host:"0.0.0.0" #ip地址不是本地地址,如果此处选择自己本地ip,则上面可以填5601
elasticsearch.url:"http://9.115.75.81:9200"
kibana.index:".kibana"
启动:
cd bin
./kibana
screen的安装和使用
先按ctrl+A,松开后再按D
安装好kibana之后,进入web界面之后,点击discover报错,解决方式:需要映射,映射ES中的字段hypervisors_status-*
带下划线的是默认的字段,不需要管。
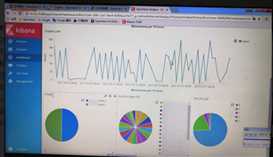
拿到数据分析的是业务层面的,做成折现图,可以看到趋势。
Dev Tools中是一些API的编写与调用。
三、Logstach介绍
是一个由JRuby语言编写的运行在java虚拟机上的具有收集,分析和转发数据流功能的工具。
采集的日志类型:Apache Logs,nginx logs,Cloud logs,Event data。
安装步骤:
1、安装好JDK
2、源码包方式安装
直接下载logstash-1.5.5.tar.gz解压运行
3、yum方式安装
rpm --import http://
yum install all
yum install logstash
此处采用的是源码包安装方式
cd logstash-5.2.2/bin
./logstash -f
查看配置文件
在logstash-5.2.2目录下新建conf目录
使用工具分析日志:
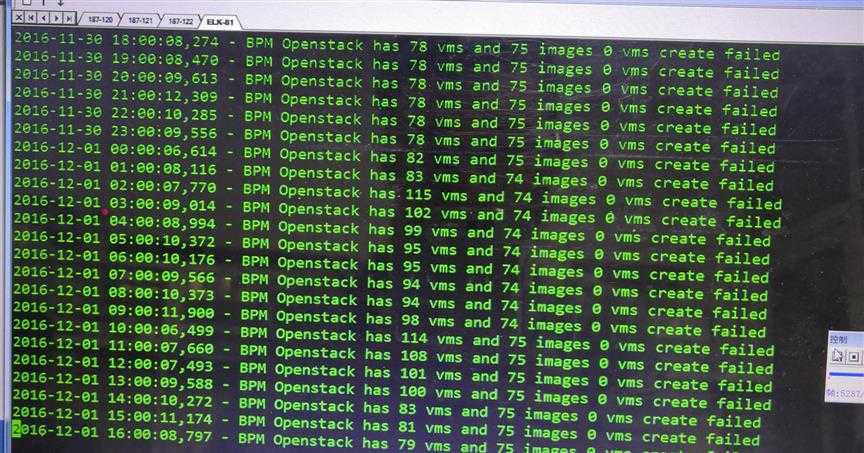
下图是通过脚本生成的一些创建虚拟机的信息
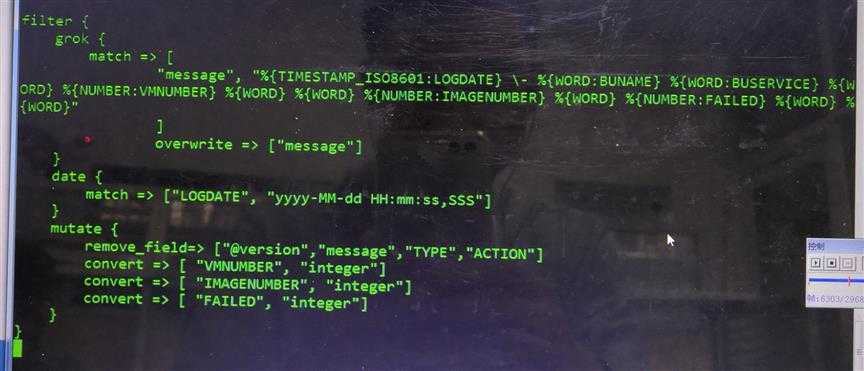
配置文件分为如下结构:input表示日志从哪里来,filter表示过滤,可以使用一些过滤规则。此处采用的是本地方式导入日志。

对于多种日志格式,可以在下面多写几种规则
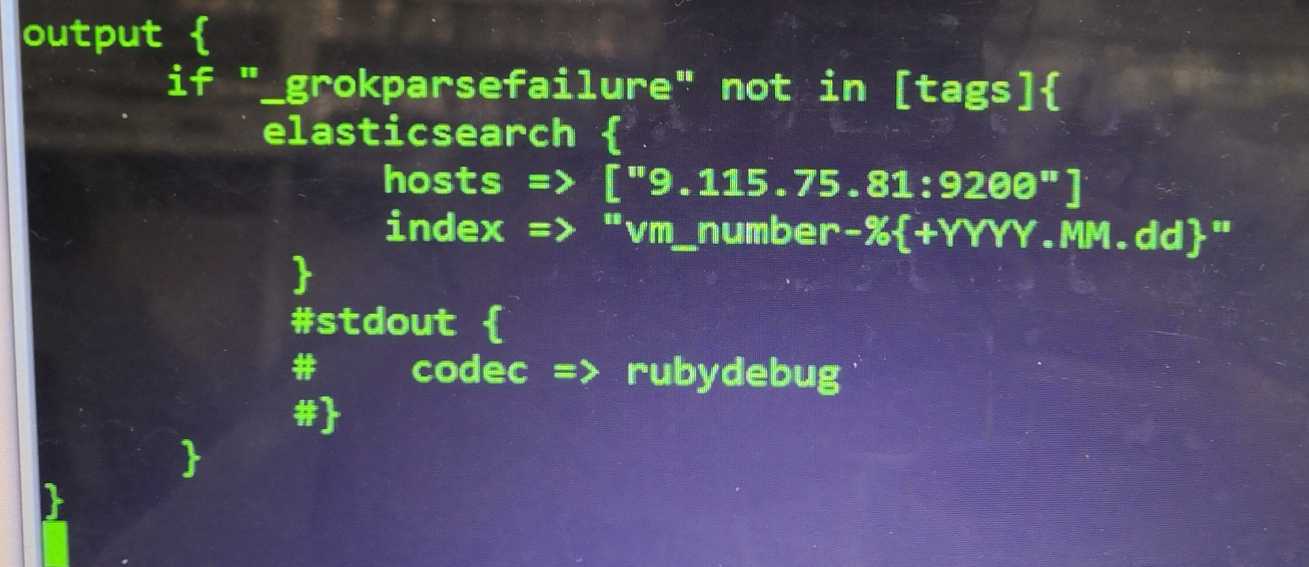
安装logstach
[[email protected] ~]# cd /home/seagull/tools/logstash-6.2.3/bin
[[email protected] bin]# ./logstash -f
常见pattern:
以上是关于ELK日志收集与监控的主要内容,如果未能解决你的问题,请参考以下文章
ELK 学习总结—— 从零搭建一个基于 ELK 的日志指标收集与监控系统