Dream team: Stacking for combining classifiers梦之队:组合分类器
Posted webrobot
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Dream team: Stacking for combining classifiers梦之队:组合分类器相关的知识,希望对你有一定的参考价值。
sklearn实战-乳腺癌细胞数据挖掘
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share
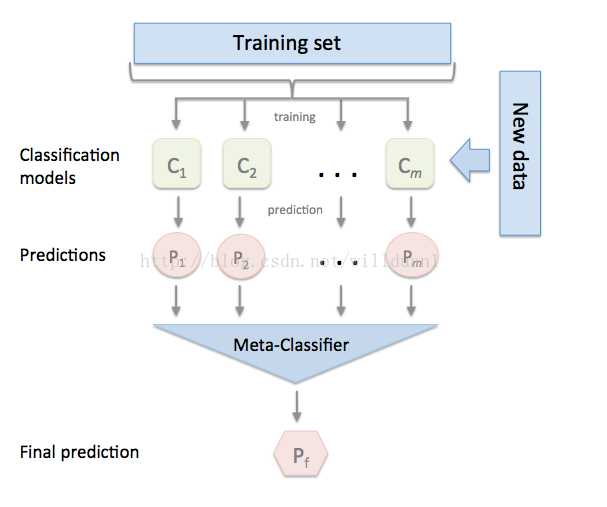
将训练好的所有基模型对整个训练集进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测:
下面我们介绍一款功能强大的stacking利器,mlxtend库,它可以很快地完成对sklearn模型地stacking。
主要有以下几种使用方法吧:
I. 最基本的使用方法,即使用前面分类器产生的特征输出作为最后总的meta-classifier的输入数据
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
import numpy as np
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr)
print(‘3-fold cross validation:
‘)
for clf, label in zip([clf1, clf2, clf3, sclf],
[‘KNN‘,
‘Random Forest‘,
‘Naive Bayes‘,
‘StackingClassifier‘]):
scores = model_selection.cross_val_score(clf, X, y,
cv=3, scoring=‘accuracy‘)
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
II. 另一种使用第一层基本分类器产生的类别概率值作为meta-classfier的输入,这种情况下需要将StackingClassifier的参数设置为 use_probas=True。如果将参数设置为 average_probas=True,那么这些基分类器对每一个类别产生的概率值会被平均,否则会拼接。
例如有两个基分类器产生的概率输出为:
classifier 1: [0.2, 0.5, 0.3]
classifier 2: [0.3, 0.4, 0.4]
1) average = True :
产生的meta-feature 为:[0.25, 0.45, 0.35]
2) average = False:
产生的meta-feature为:[0.2, 0.5, 0.3, 0.3, 0.4, 0.4]
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
import numpy as np
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
use_probas=True,
average_probas=False,
meta_classifier=lr)
print(‘3-fold cross validation:
‘)
for clf, label in zip([clf1, clf2, clf3, sclf],
[‘KNN‘,
‘Random Forest‘,
‘Naive Bayes‘,
‘StackingClassifier‘]):
scores = model_selection.cross_val_score(clf, X, y,
cv=3, scoring=‘accuracy‘)
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
III. 另外一种方法是对训练基中的特征维度进行操作的,这次不是给每一个基分类器全部的特征,而是给不同的基分类器分不同的特征,即比如基分类器1训练前半部分特征,基分类器2训练后半部分特征(可以通过sklearn 的pipelines 实现)。最终通过StackingClassifier组合起来。
from sklearn.datasets import load_iris
from mlxtend.classifier import StackingClassifier
from mlxtend.feature_selection import ColumnSelector
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
iris = load_iris()
X = iris.data
y = iris.target
pipe1 = make_pipeline(ColumnSelector(cols=(0, 2)),
LogisticRegression())
pipe2 = make_pipeline(ColumnSelector(cols=(1, 2, 3)),
LogisticRegression())
sclf = StackingClassifier(classifiers=[pipe1, pipe2],
meta_classifier=LogisticRegression())
sclf.fit(X, y)
StackingClassifier 使用API及参数解析:
StackingClassifier(classifiers, meta_classifier, use_probas=False, average_probas=False, verbose=0, use_features_in_secondary=False)
参数:
classifiers : 基分类器,数组形式,[cl1, cl2, cl3]. 每个基分类器的属性被存储在类属性 self.clfs_.
meta_classifier : 目标分类器,即将前面分类器合起来的分类器
use_probas : bool (default: False) ,如果设置为True, 那么目标分类器的输入就是前面分类输出的类别概率值而不是类别标签
average_probas : bool (default: False),用来设置上一个参数当使用概率值输出的时候是否使用平均值。
verbose : int, optional (default=0)。用来控制使用过程中的日志输出,当 verbose = 0时,什么也不输出, verbose = 1,输出回归器的序号和名字。verbose = 2,输出详细的参数信息。verbose > 2, 自动将verbose设置为小于2的,verbose -2.
use_features_in_secondary : bool (default: False). 如果设置为True,那么最终的目标分类器就被基分类器产生的数据和最初的数据集同时训练。如果设置为False,最终的分类器只会使用基分类器产生的数据训练。
属性:
clfs_ : 每个基分类器的属性,list, shape 为 [n_classifiers]。
meta_clf_ : 最终目标分类器的属性
方法:
fit(X, y)
fit_transform(X, y=None, fit_params)
get_params(deep=True),如果是使用sklearn的GridSearch方法,那么返回分类器的各项参数。
predict(X)
predict_proba(X)
score(X, y, sample_weight=None), 对于给定数据集和给定label,返回评价accuracy
set_params(params),设置分类器的参数,params的设置方法和sklearn的格式一样
一套弱系统能变成一个强系统吗?
当你处在一个复杂的分类问题面前时,金融市场通常会出现这种情况,在搜索解决方案时可能会出现不同的方法。 虽然这些方法可以估计分类,但有时候它们都不比其他分类好。 在这种情况下,合理的选择是将它们全部保留下来,然后通过整合这些部分来创建最终系统。 这种多样化的方法是最方便的做法之一:在几个系统之间划分决定,以避免把所有的鸡蛋放在一个篮子里。
一旦我对这种情况有了大量的估计,我怎样才能将N个子系统的决策结合起来? 作为一个快速的答案,我可以做出平均决定并使用它。 但是,是否有不同的方式充分利用我的子系统? 当然有!
Can a set of weak systems turn into a single strong system?
When you’re in front of a complex classification problem, as is often the case with financial markets, different approaches may appear while searching for a solution. Although these approaches can estimate the classification, sometimes none of them are better than the rest. In this case, a reasonable choice is to keep them all, and then create a final system by integrating the pieces. This method of diversification is one of the most convenient practices: divide the decision among several systems in order to avoid putting all your eggs in one basket.
Once I have a number of estimates for the one case, how can I combine the decisions of the N sub-systems? As a quick answer, I can take the decision average and use this. But are there different ways of making the most out of my sub-systems? Of course there are!
Think outside the box!
Several classifiers with a common objective are called multiclassifiers. In Machine Learning, multiclassifiers are sets of different classifiers which make estimates and are fused together, obtaining a result that is a combination of them. Lots of terms are used to refer to multiclassifiers: multi-models, multiple classifier systems, combining classifiers, decision committee, etc. They can be divided into two main groups:
- Ensemble methods: Refers to sets of systems that combine to create a new system using the same learning technique. Bagging and Boosting are the most extended ones.
- Hybrid methods: Takes a set of different learners and combines them using new learning techniques. Stacking (or Stacked Generalization) is one of the main hybrid multiclassifiers.
创造性思考!
几个具有共同目标的分类器称为多分类器。 在机器学习中,多分类器是一组不同的分类器,它们进行估算并融合在一起,得到一个结合它们的结果。 许多术语用于指多分类器:多模型,多分类器系统,组合分类器,决策委员会等。它们可以分为两大类:
集成方法:指使用相同的学习技术组合成一组系统来创建新系统。 套袋和提升是最延伸的。
混合方法:采用一组不同的学习者并使用新的学习技术进行组合。 堆叠(或堆叠泛化)是主要的混合多分类器之一。
How to build a multiclassifier motivated by Stacking.
Imagine that I would like to estimate the EURUSD’s trends(欧元兑美元趋势). First of all, I turn my issue into a classification problem, so I split the price data into two types (or classes): up and down movements. Guessing every daily movement is not my intention. I only want to detect the main trends: up for trading Long (class = 1) and down for trading Short (class = 0).
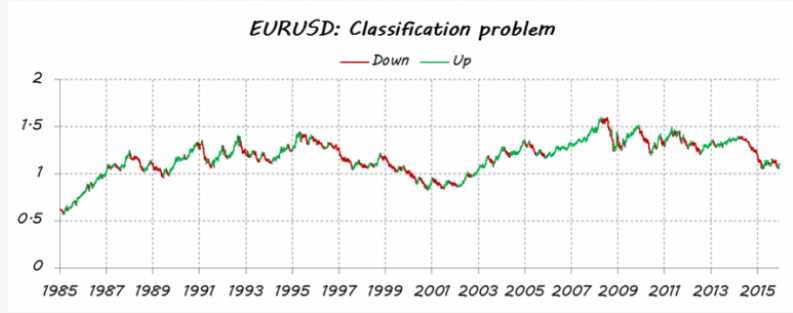
I have done this split a posteriori; by which I mean that all historical data have been used to decide the classes, so it takes into account some future information. Therefore, I’m not able to assure iup or down movement at the current moment. For this reason an estimate for the today’s class is required.
For the purpose of this example I have designed three independent systems. They are three different learners using separate sets of attributes. It does not matter if you use the same learner algorithm or if they share some/all attributes; the key is that they must be different enough in order to guarantee diversification.
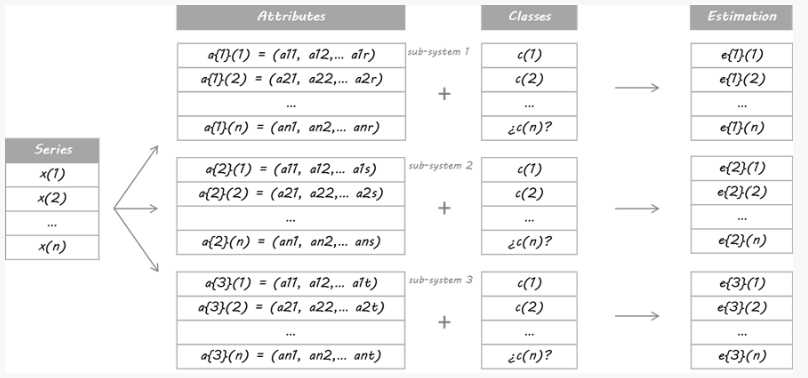
Then, they trade based on those probabilities: If E is above 50%, it means Long entry, more the bigger E is. If E is under 50%, it is Short entry, more the smaller E is.
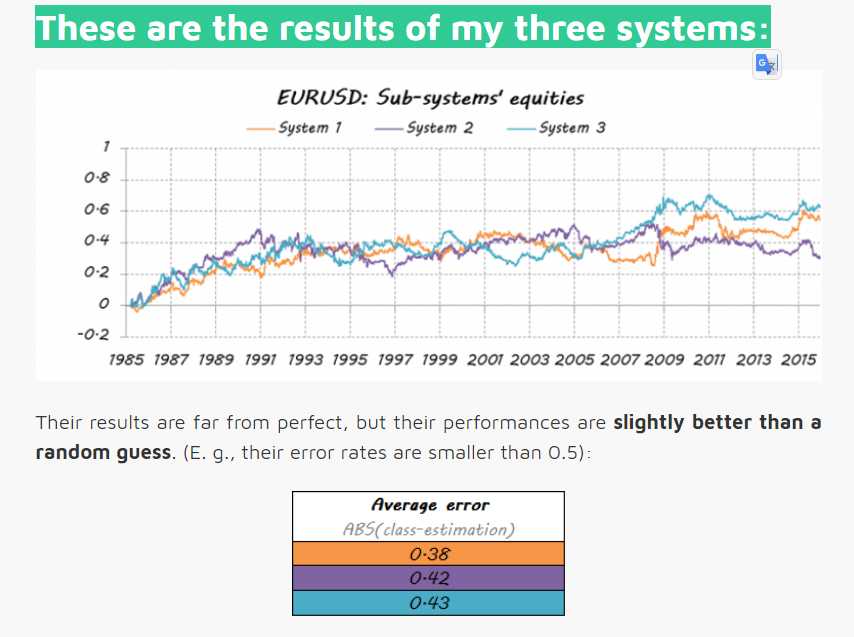
These are the results of my three systems:
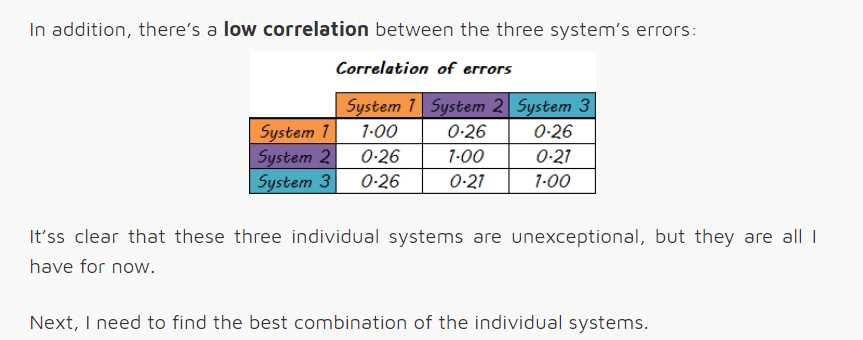
一组穷人可以组成梦之队吗?
构建多分类器的目的是获得比任何单个分类器都能获得的更好的预测性能。让我们看看是否是这种情况。
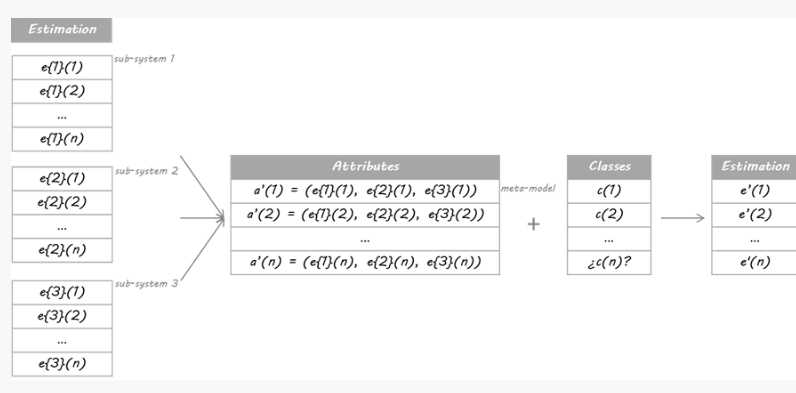
我将在本例中使用的方法基于Stacking算法。 Stacking的思想是,称为级别0模型的主分类器的输出将被用作称为元模型的另一分类器的属性以近似相同的分类问题。元模型留下来找出合并机制。它将负责连接0级模型的回复和真实分类。
严格的过程包括将训练集分成不相交的集合。然后训练每个级别0的学习者关于整个数据,排除一组,并将其应用于排除组。通过对每组重复,为每个学习者获得每个数据的估计。这些估计值将成为训练元模型或1级模型的属性。由于我的数据是一个时间序列,因此我决定使用第1天到第d-1天的集合来构建第d天的估计。
Can a set of poor players make up a dream team?
The purpose of building a multiclassifier is to obtain better predictive performance than what could be obtained from any single classifier. Let’s see if this is the case.
The method I am going to use in this example is based on the Stacking algorithm. The idea of Stacking is that the output of primary classifiers, called level 0 models, will be used as attributes for another classifier, called meta-model, to approximate the same classification problem. The meta-model is left to figure out the combining mechanism. It will be in charge of connecting the level 0 models’ replies and the real classification.
The rigorous process consists in splitting the training set into disjoint sets. Then train each level 0 learner on the whole data, excluding one set, and apply it over the excluded set. By repeating for each set, an estimate for each data is obtained for each learner. These estimates will be the attributes for training the meta-model or level 1 model. As my data was a time series, I decided to build the estimation for day d just using the set from day 1 to day d-1.
这与哪种模式配合使用?
元模型可以是分类树,随机森林,支持向量机......任何分类学习者都是有效的。 对于这个例子,我选择了使用最近邻居算法。 这意味着元模型将估计新数据的类别,以发现过去数据中0级分类的类似配置,然后将分配这些类似情况的类别。
让我们看看我的梦之队的成绩是多么的好......
Which model does this work with?
The meta-model can be a classification tree, a random forest, a support vector machine… Any classification learner is valid. For this example I chose to use a nearest neighbours algorithm. It means that the meta-model will estimate the class of the new data finding similar configurations of the level 0 classifications in past data, and then will assign the class of these similar situations.
Let’s see how good my dream team result is…
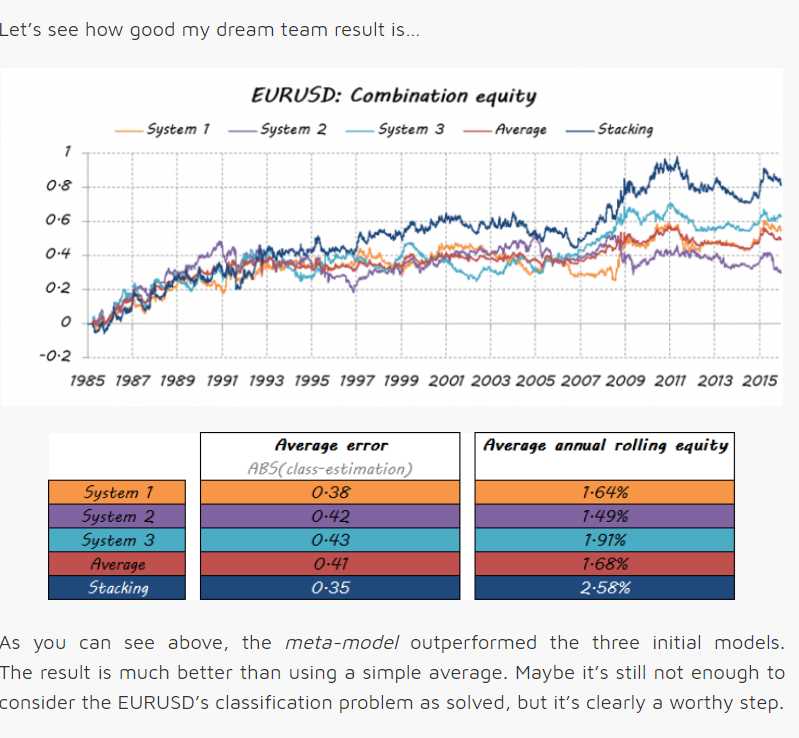
Conclusion
This is just one example of the huge amount of available multiclassifiers. They can help you not only to join your partial solutions into a unique answer by means of a modern and original technique, but to create a real dream team. There’s also an important margin for improvement in the way that the individual pieces are integrated into a single system.
So, next time you need to combine, spend more than a moment working on the possibilities. Avoid the traditional average by force of habit and explore more complex methods. They may surprise you with extra performance.
结论
这只是大量可用多分类器的一个例子。 他们不仅可以帮助您通过现代和独创的技术将您的部分解决方案融入到独特的答案中,而且可以创建一个真正的梦幻团队。 单个组件被集成到一个系统中的方式也有一个重要的改进余地。
所以,下次你需要结合时,花更多的时间来研究可能性。 通过习惯的力量避免传统的平均水平,并探索更复杂的方法。 他们可能会为你带来额外的表现
python风控评分卡建模和风控常识
以上是关于Dream team: Stacking for combining classifiers梦之队:组合分类器的主要内容,如果未能解决你的问题,请参考以下文章