网络爬虫
Posted zhoulixiansen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络爬虫相关的知识,希望对你有一定的参考价值。
上一节保存心急了,附上Linux的安装;
docker官方版安装:curl -sSL http://get.docker.com/ | sh
阿里云版安装:curl -sSL http://acs-public-mirror.oss-cn-hangzhou.aliyuncs.com/docker-engine/internet | sh -
DaoCloud的安装脚本:curl -sSL http://get.daocloud.io/docker.com/ | sh
三选一
了解爬虫基础:HTTP和HTTPS
HTTP是叫超文本传输协议,目前使用http1.1版本。HTTPS是以安全为目标的HTTP通道,简单来讲就是HTTP的安全版本。就是在HTTP下假如ssl层,简称HTTPS。
HTTPS的安全基础是SSL,因此通过传输的内容都是SSL加密的,作用有如下两种。
1,建立一个安全的信息通道保证数据的安全
2,确认网站的真实性,凡是使用了HTTPS的网站,都有网站认证。
但是有一点的情况下:有些HTTPS没有被CA机构信任,是自行签发的。爬取这样的站点,就需要忽略证书的选项,否则会提示SSL链接错误。
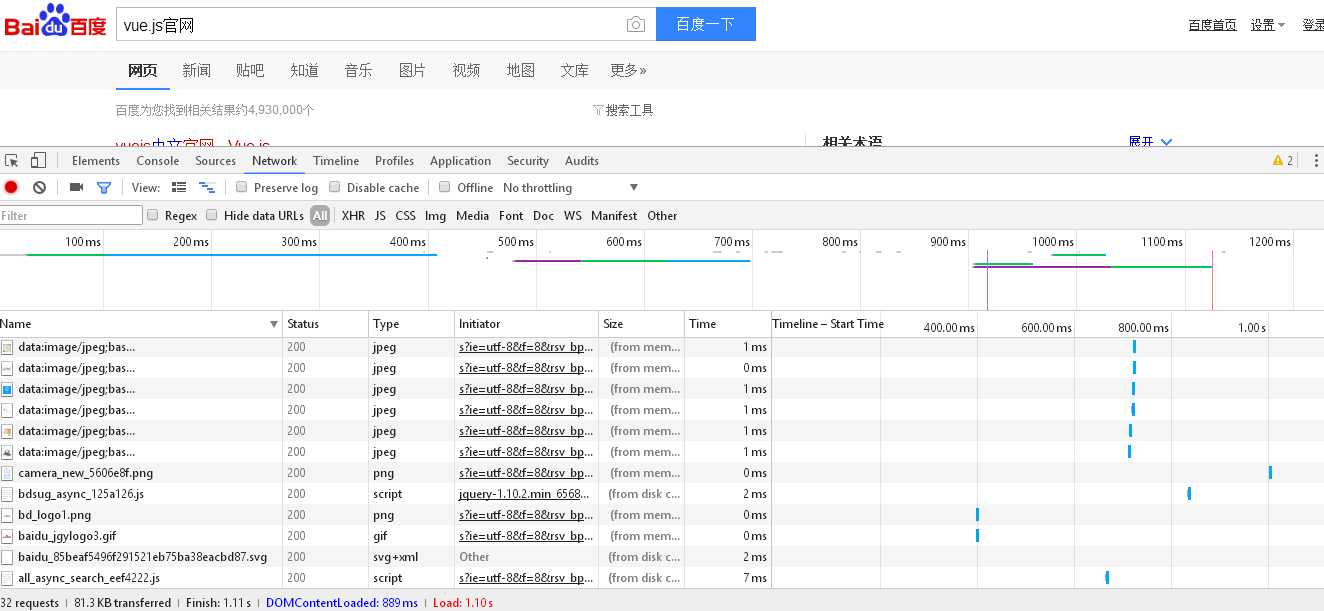
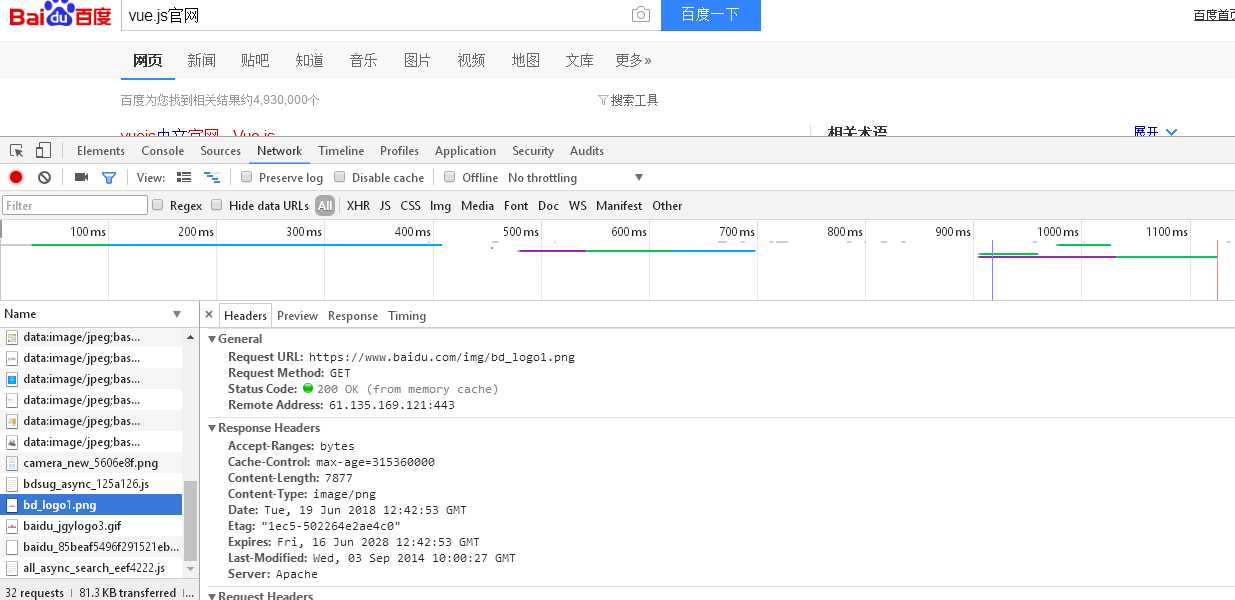
上面的两张图就是浏览器在搜索时开发者F12你能看到的种种信息。
当然在做爬虫的过程之中,经常会遇到这种情况,最初爬虫能够正常运行,正常抓取数据,但是一会就会提示403错误,其实打开网页一看,“您的IP频率太高”。
这种情况是因为网站做出来反爬虫措施。服务器会检测某个IP在单位时间的请求次数,如果超过了这个阈值,就会直接拒绝服务。返回一些错误信息,这种情况称之为封IP。
那就接下来使用代理:
使用网上的免费代理
使用付费代理
亦或者使用ADSL拨号:拨一次号换一个IP,稳定性还高。
下面正式介绍爬虫的使用:
基本库的使用:urllib
网上很多介绍urllib使用的方法已经不管用了。因为python3中已经不存在urllib2这个库了,统一为urllib了,引用的时候切记要注意 了。
urllib模块呢分为4个内容:①request,他是最基本的HTTP的请求模块,可以用来模拟发送请求。就像在浏览器中输入网址并且回车一样,现在只需要给库传网址和必要的参数就可以模拟实现这个过程。
②error:这个是一个异常处理的模块,如果出现请求错误,我们便可以捕获异常。然后进行其他操作。
③parse:一个工具模块,提供了多种url的处理方法,比如说拆分解析合并等。
④robotparser:主要是用来识别网站的robots.txt文件,判断哪些网站可以爬,哪些网站不可爬取,用的相当少
import urllib.request response = urllib.request.urlopen("http://www.baidu.com") html = response.read() print(html)
情调一点:
import urllib.request这个是python3的引入。
下面的具体的用法:
1,URLopen()
urllib.request 模块提供最基本的狗仔HTTP请求方法,利用他可以模拟浏览器的一个请求的发起过程,同时他还有处理授权验证(authenticaton)、重定向(redirection)、浏览器Cookies以及其他的内容
下面举个栗子看下强大之处:
虽然以上上图中仅仅三行代码:就完成python的官网抓取,输出了网页的源代码。得到源代码之后呢,我们需要的链接、图片地址、文本信息不就可以提取出来了吗?


1 import urllib.request 2 response = urllib.request.urlopen("http://www.python.org") 3 print(type(response)) 4 5 6 >>><class ‘http.client.HTTPResponse‘>
可以发现,他是一个HTTPResponse类型的对象,主要包含read()、readinto()、getheader(name)、……等属性。
得到这个对象之后,我们把它赋值为response变量,然后就可以调用这些方法和属性,得到返回结果的一系列信息了。
例如:调用send()方法可以得到网页的内容,调用status属性可以得到返回结果的状态码,如果是200代表成功,404代表网页未找到
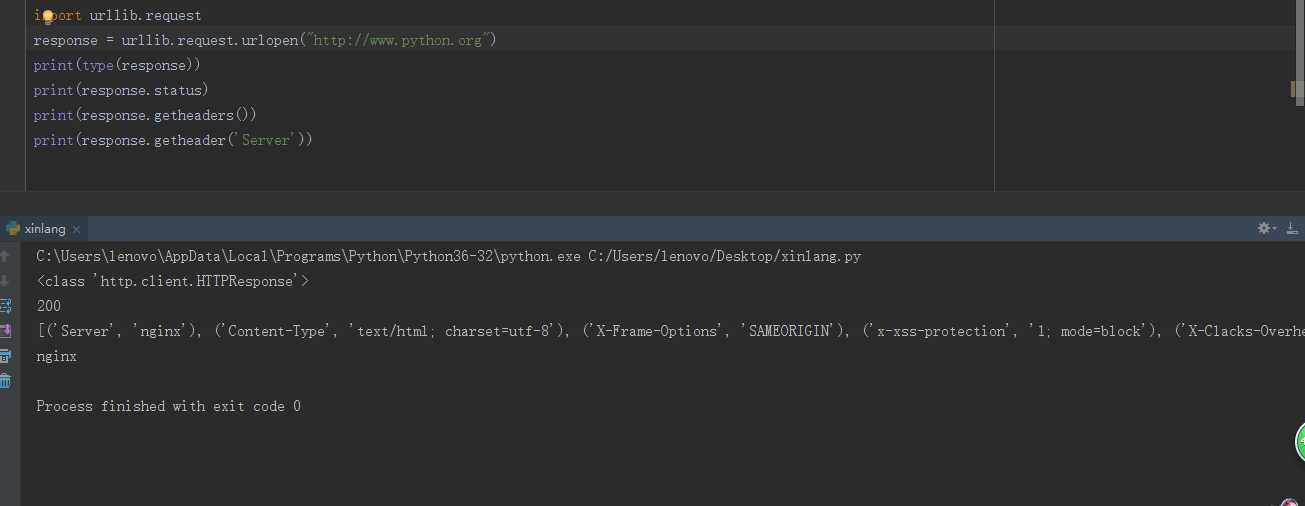
可见,前连个输出分别输出了响应的状态码和响应的头信息,最后一个输出通过调用getheader()方法并且传递一个参数Server获取了响应头中的Server值,结果是nginx,意思是服务器是采用nginx搭建的
利用最为基本的urlopen()就可以完成最简单GET的抓取。
假如我要传入一些参数呢?
我们来看一下源码:
def urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT, *, cafile=None, capath=None, cadefault=False, context=None):
除了第一个参数是url之外,比如说data(附加数据),timeout(超时时间)等。
data参数是可选的,如果需要添加参数,并且他是字节流编码格式的内容,也就是bytes()类型,需要通过bytes()方法转化,另外传递了这个参数,那么他的请求方法就不在是GET方式,而是POST方式,
下面是实例:
import urllib.request import urllib.parse data = bytes(urllib.parse.urlencode({‘word‘: ‘hello‘}), encoding=‘utf-8‘) # parse是用来处理URL,比如拆分和解析、合并等 response = urllib.request.urlopen("http://httpbin.org/post", data=data) print(type(response)) print(response.read())
得到结果是:
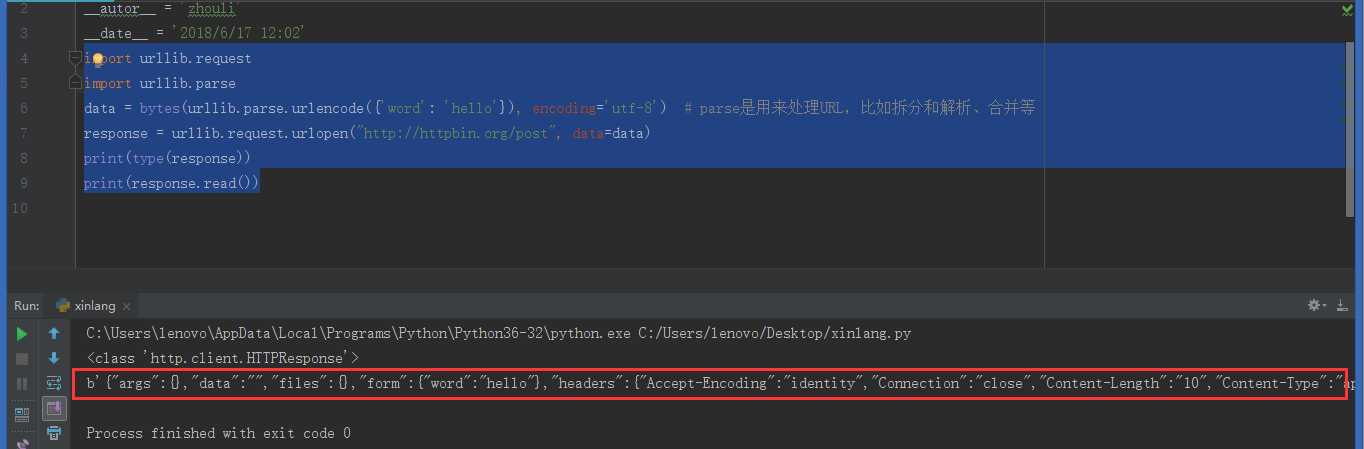
我们传递的参数出现在form字段中,说明了模拟了表单的提交方式,并且以POST方式传递数据。
timeout参数
假如我想现在给上面的代码加一个timeout的参数:
import urllib.request response = urllib.request.urlopen("http://httpbin.org/post", timeout=1) print(type(response)) print(response.read())
得到的结果是什么?
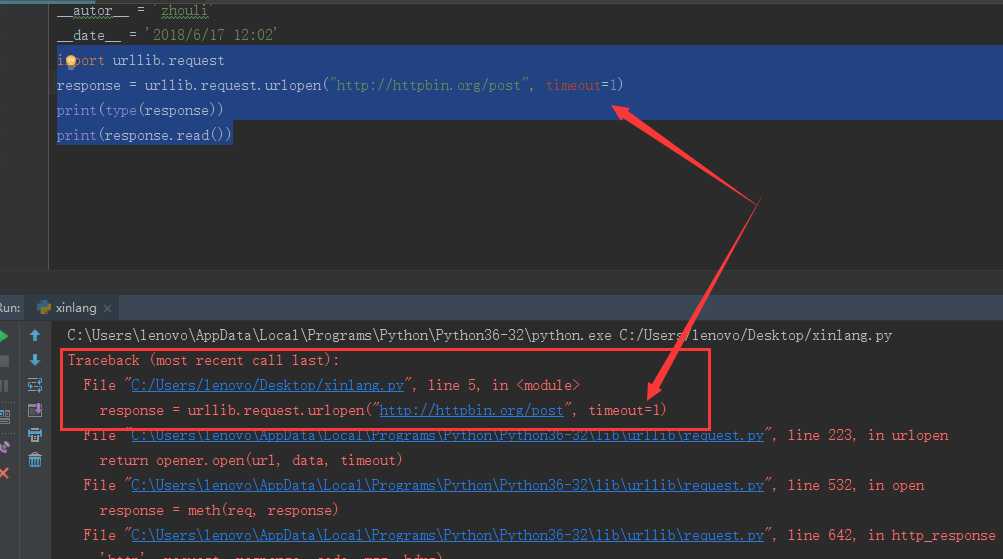 因为现在
因为现在
我们设置的超时时间1s,当程序运行1s之后服务器依旧没有响应,于是抛出异常,该异常属于urllib.error模块,错误原因就是超时。
因此可以设置一个超时时间来控制一个网页如果长时间没有响应,就直接跳过他的抓取,这个可以使用try……except来进行捕获异常,代码如下:
import urllib.request import urllib.error import socket try: response = urllib.request.urlopen("http://httpbin.org/get", timeout=0.1) except urllib.error.URLError as e: if isinstance(e.reason, socket.timeout): print("你已超时")
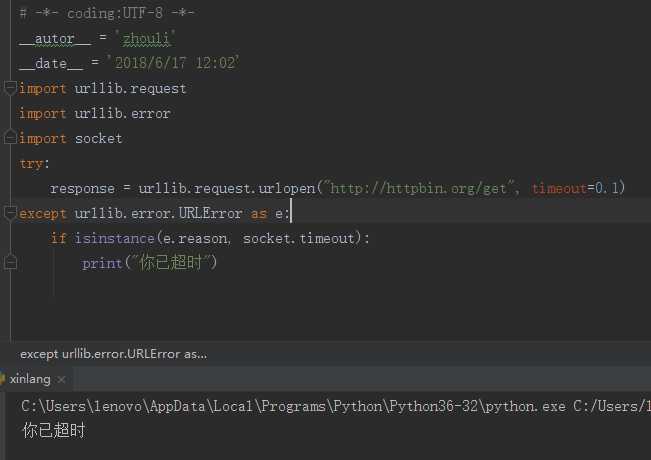
这里是请求了 http://httpvin.org/get测试连接,设置超时时间为0.1s,然后捕获了URLerror异常,接着判断异常是否属于,socke.timeout类型,打印结果。
其他参数:
除了data参数和timeout参数之外还有context参数,他必须是ssl.SSLContext类型,用来指定SSL设置。
此外cafile和capath两个参数分别制定CA证书以及他的路径,这个在请求HTTPS连接的时候有用的,cadefault参数目前已经废弃了,,默认值为false。
前面讲到了URLopen()的方法以及一些参数的使用,,其他的事情就交给官方文档吧。
以上是关于网络爬虫的主要内容,如果未能解决你的问题,请参考以下文章