Python获取指定内存地址中的对象
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python获取指定内存地址中的对象相关的知识,希望对你有一定的参考价值。
比如在一个python进程中创建了一个对象,在另一个python进程中(不是由multiprocessing创建的)如何获取同一个对象并能对其进行操作?
你找一找这个库,rpyc。这个东西是目前RPC方面最好用的一个东西了。比我以前接触学习的分布式对象系统更好用。 其实python这个东西,因为是脚本,所以做分布式对象特别容易。主要是做好系列化与反系列化就可以了。此外rpc-xml也是常用的一个方法。
如果你对需求理解深,通常不会选择分布式对象,而是自己定制数据结构,传输协议,序列化与反序列化。这样才能实现高效,可扩展性。
你在一个进程中创建一个对象,可以使用python自带的系列化模块pickle进行转换。然后传递到另一个进程中,再反序列化就可以实现。操作完成后,再传递回来。这就是原理。
如果使用指定内存地址也是可以的。可以设计一个共享内存,然后通过numpy这个模块进行内存与对象的转换。其它的就不多说了。 当然你也可以自己设计序列化与反序列化模块。
通常复杂的对象效率低。整型固定长度数组是最快的。追问
我还看到一个叫pyro的模块,这个和rpyc比怎么样?
追答这个模块我用过。小巧,学起来容易。现在还有人在用。不过有些局限性,与你想象的分布式计算有差距。最多是一个分布式组件。它与rpyc比起来怎么说呢,也许效率更高,不过可用性比rpyc差远了。
参考技术A 如果你不用multiprocessing和它的proxy,你还是得自己写一个类似proxy的C/C++模块,何苦呢? 参考技术B 通过管道通信行不? 参考技术C 百度一下,编程论坛,会更快,更专业。问题找到能更快解决的方法。编程要多交流,在论坛里你会学到更多。天啦噜!仅仅5张图,彻底搞懂Python中的深浅拷贝
Python中的深浅拷贝
在讲深浅拷贝之前,我们先重温一下 is 和==的区别。
在判断对象是否相等比较的时候我们可以用is 和 ==
- is:比较两个对象的引用是否相同,即 它们的id 是否一样
- == : 比较两个对象的值是否相同。
id() ,是Python的一个内置函数,返回对象的唯一标识,用于获取对象的内存地址。
如下
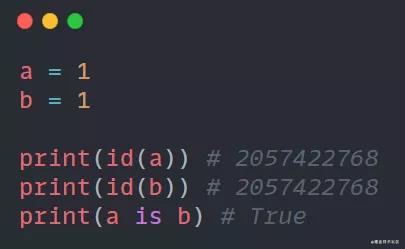
首先,会为整数1分配一个内存空间。 变量a 和 b 都指向了这个内存空间(内存地址相等),所以他们的id相等。
即 a is b 为 True
但是,真的所有整数数字都这样吗? 答案是:不是! 只有在 -25 ~ 256范围中的整数才不会重新分配内存空间。
如下所示:
因为257 超出了范围,所以id不相同,所以a is b返回的值为False。
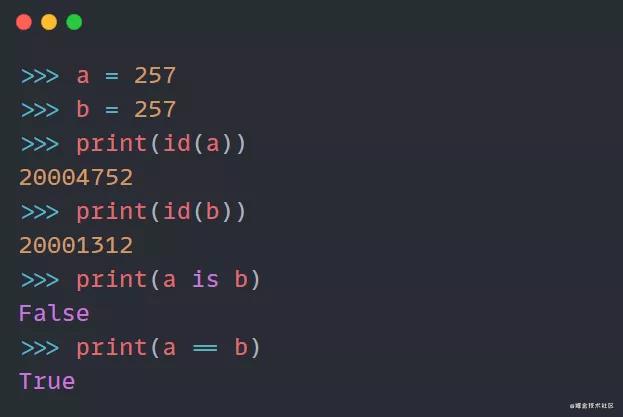
>>> a = 257
>>> b = 257
>>> print(id(a))
20004752
>>> print(id(b))
20001312
>>> print(a is b)
False
>>> print(a == b)
True这样做是考虑到性能,Python对-5 到 256 的整数维护了一个数组,相当于一个缓存, 当数值在这个范围内,直接就从数组中返回相对应的引用地址了。如果不在这个范围内,会重新开辟一个新的内存空间。
is 和 == 哪个效率高?
相比之下,is比较的效率更高,因为它只需要判断两个对象的id是否相同即可。
而== 则需要重载__eq__ 这个函数,遍历变量中的所有元素内容,逐次比较是否相同。因此效率较低
浅拷贝 深拷贝
给变量进行赋值,有两种方法 直接赋值,拷贝
直接赋值就 = 就可以了。而拷贝又分为浅拷贝和深拷贝
先说结论吧:
- 浅拷贝:拷贝的是对象的引用,如果原对象改变,相应的拷贝对象也会发生改变
- 深拷贝:拷贝对象中的每个元素,拷贝对象和原有对象不在有关系,两个是独立的对象
光看上面的概念,对新手来讲可能不太好理解。来看下面的例子吧
赋值
a = [1, 2, 3]
b = a
print(id(a)) # 52531048
print(id(b)) # 52531048定义变量a,同时将a赋值给b。打印之后发现他们的id是相同的。说明指向了同一个内存地址。

然后修改a的值,再查看他们的id
a = [1, 2, 3]
b = a
print(id(a)) # 46169960
a[1] = 0
print(a, b) # [1, 0, 3] [1, 0, 3]
print(id(a)) # 46169960
print(id(b)) # 46169960这时候发现修改后的a和b以及最开始的a的内存地址是一样的。也就是说a和b还是指向了那一块内存,只不过内存里面的[1, 2, 3] 变成了[1, 0, 3]
因为每次重新执行的时候内存地址都是发生改变的,此时的id(a) 的值46169960与52531048是一样的
所以我们就可以判断出,b和a的引用是相同的,当a发生改变的时候,b也会发生改变。
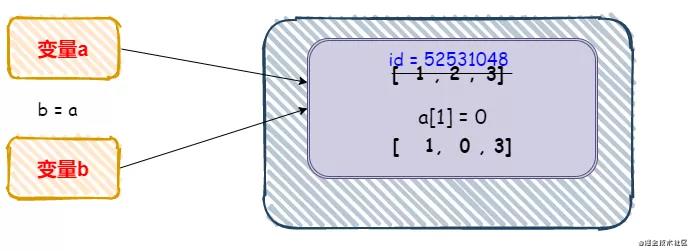
赋值就是:你a无论怎么变,你指向谁,我b就跟着你指向谁。
拷贝
提到拷贝就避免不了可变对象和不可变对象。

- 可变对象:当有需要改变对象内部的值的时候,这个对象的id不发生变化。
- 不可变对象:当有需要改变对象内部的值的时候,这个对象的id会发生变化。
a = [1, 2, 3]
print(id(a)) # 56082504
a.append(4)
# 修改列表a之后 id没发生改变,可变对象
print(id(a)) # 56082504
a = \'hello\'
print(id(a)) # 59817760
a = a + \' world\'
print(id(a)) # 57880072
# 修改字符串a之后,id发生了变化。不可变对象
print(a) # hello world浅拷贝
拷贝的是不可变对象,一定程度上来讲等同于赋值操作。但是对于多层嵌套结构,浅拷贝只拷贝父对象,不拷贝内部的子对象。
使用copy模块的 copy.copy 进行浅拷贝。
import copy
a = [1, 2, 3]
b = copy.copy(a)
print(id(a)) # 55755880
print(id(b)) # 55737992
a[1] = 0
print(a, b) # [1, 0, 3] [1, 2, 3]通俗的讲,我将现在的a 复制一份重新分配了一个内存空间。后面你a怎么改变,那跟我b是没有任何关系的。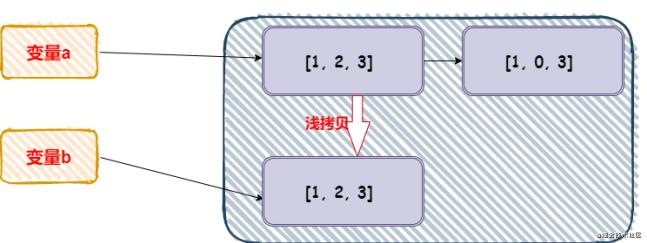
对于列表的浅拷贝还可以通过list(), list[:] 来实现
但是!我前面提到了对于多层嵌套的结构,需要注意
看下面的例子
import copy
a = [1, 2, [3, 4]]
b = copy.copy(a)
print(id(a)) # 23967528
print(id(b)) # 21738984
# 改变a中的子列表
a[-1].append(5)
print(a) # [1, 2, [3, 4, 5]]
print(b) # [1, 2, [3, 4, 5]] ?? 为什么不是[1, 2, [3, 4]]呢?b是由a浅拷贝得到的。我修改了a中嵌套的列表,发现b也跟着修改了?
如果还是不太理解,可以参考下图。LIST就是一个嵌套的子对象,指向了另外一个内存空间。所以浅拷贝只是拷贝了元素1, 2 和子对象的引用!

另外一种情况,如果嵌套的是一个元组呢?
import copy
a = [1, 2, (3, 4)]
b = copy.copy(a)
# 改变a中的元组
a[-1] += (5,)
print(a) # [1, 2, (3, 4, 5)]
print(b) # [1, 2, (3, 4)]我们发现浅拷贝得来的b并没有发生改变。因为元组是不可变对象。改变了元组就会生成新的对象。b中的元组引用还是指向了旧的元组。
深拷贝
所谓深拷贝呢,就是重新分配一个内存空间(新对象),将原对象中的所有元素通过递归的方式进行拷贝到新对象中。
在Python中 通过copy.deepcopy() 来实现深拷贝。

import copy
a = [1, 2, [3, 4]]
b = copy.deepcopy(a)
print(id(a)) # 66587176
print(id(b)) # 66587688
# 改变a中的可变对象
a[-1].append(5)
print(a) # [1, 2, [3, 4, 5]]
print(b) # [1, 2, [3, 4]] 深拷贝之后字列表不会受原来的影响
结语
1、深浅拷贝都会对源对象进行复制,占用不同的内存空间
2、如果源对象没有子目录,则浅拷贝只能拷贝父目录,改动子目录时会影响浅拷贝的对象
3、列表的切片本质就是浅拷贝
史上最全Python资料汇总(长期更新)。隔壁小孩都馋哭了 --- 点击领取

以上是关于Python获取指定内存地址中的对象的主要内容,如果未能解决你的问题,请参考以下文章