Selenium自动截图怎么总是上个页面
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Selenium自动截图怎么总是上个页面相关的知识,希望对你有一定的参考价值。
参考技术A 在自动化测试中,获取屏幕截图是必不可少的,在测试报告中有效的截图能更有说服力。截图方法,方法1:get_screenshot_as_file。方法2:save_screenshot。方法3:im.crop((left,top,right,bottom))#对浏览器截图进行裁剪
利用PIL和Selenium实现页面元素截图
预备
照张相片
selenium.webdriver可以实现对显示页面的截图:
from selenium import webdriver dr = webdriver.Firefox() dr.get(\'http://store.steampowered.com/\') dr.save_screenshot(\'D:\\\\page.png\')
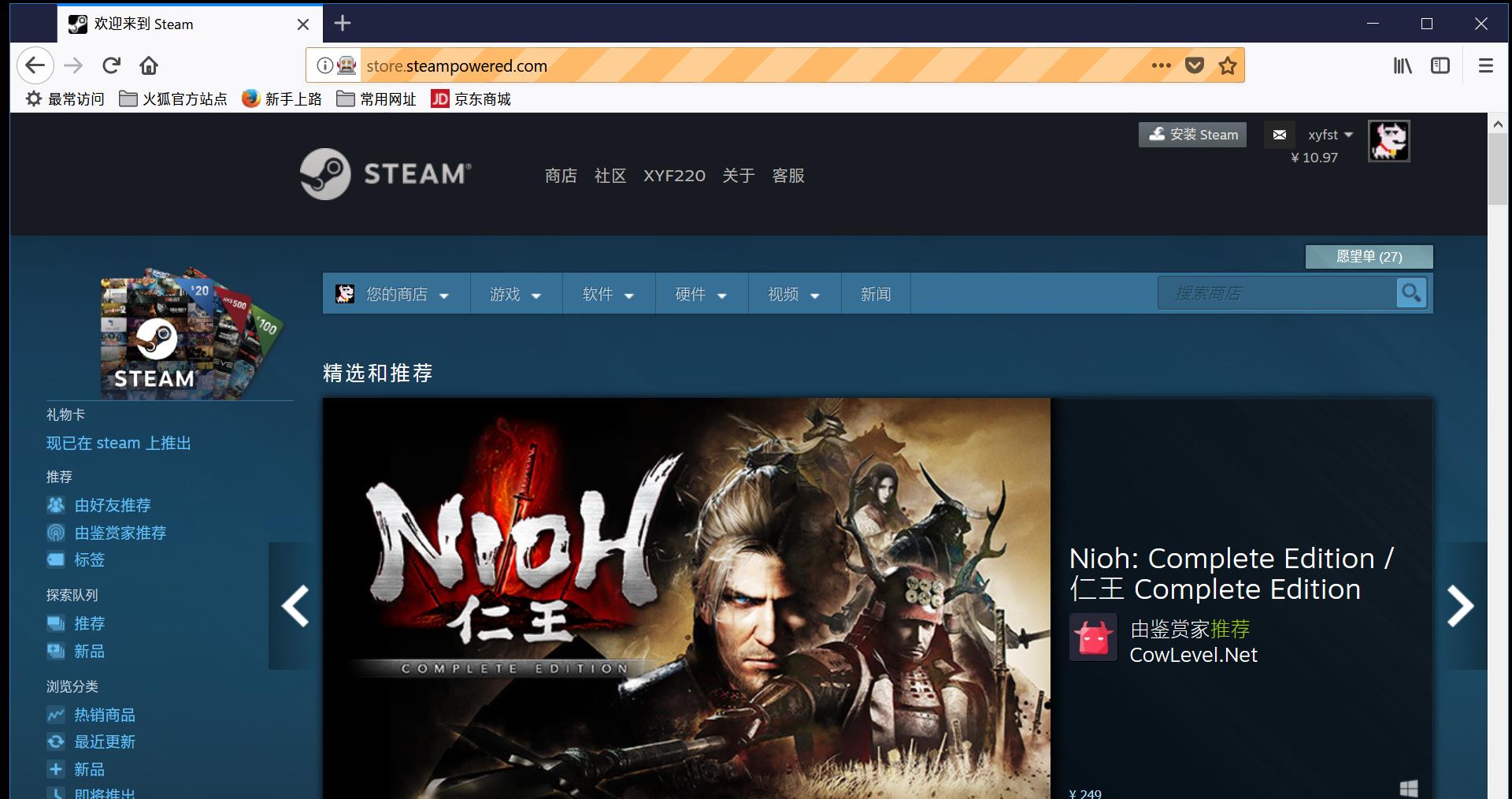
实际浏览器界面和截图结果
可以发现截图结果是浏览器内当前的显示内容。
让我想想...那只要让需要截图的元素出现在当前页面上,再从得到的截图里再把要的元素截取出来不就好啦?
那问题是怎么才能让当前元素先让我们看见呢?
让提线木偶动起来
在js中,页面可以滚动到特定元素:
item_obj = document.getElementsByClassName(\'store_capsule_frame\'); item = item_obj[0]; item.style.border = \'2px solid red\'; item.scrollIntoView();
在浏览器的控制台执行上述代码
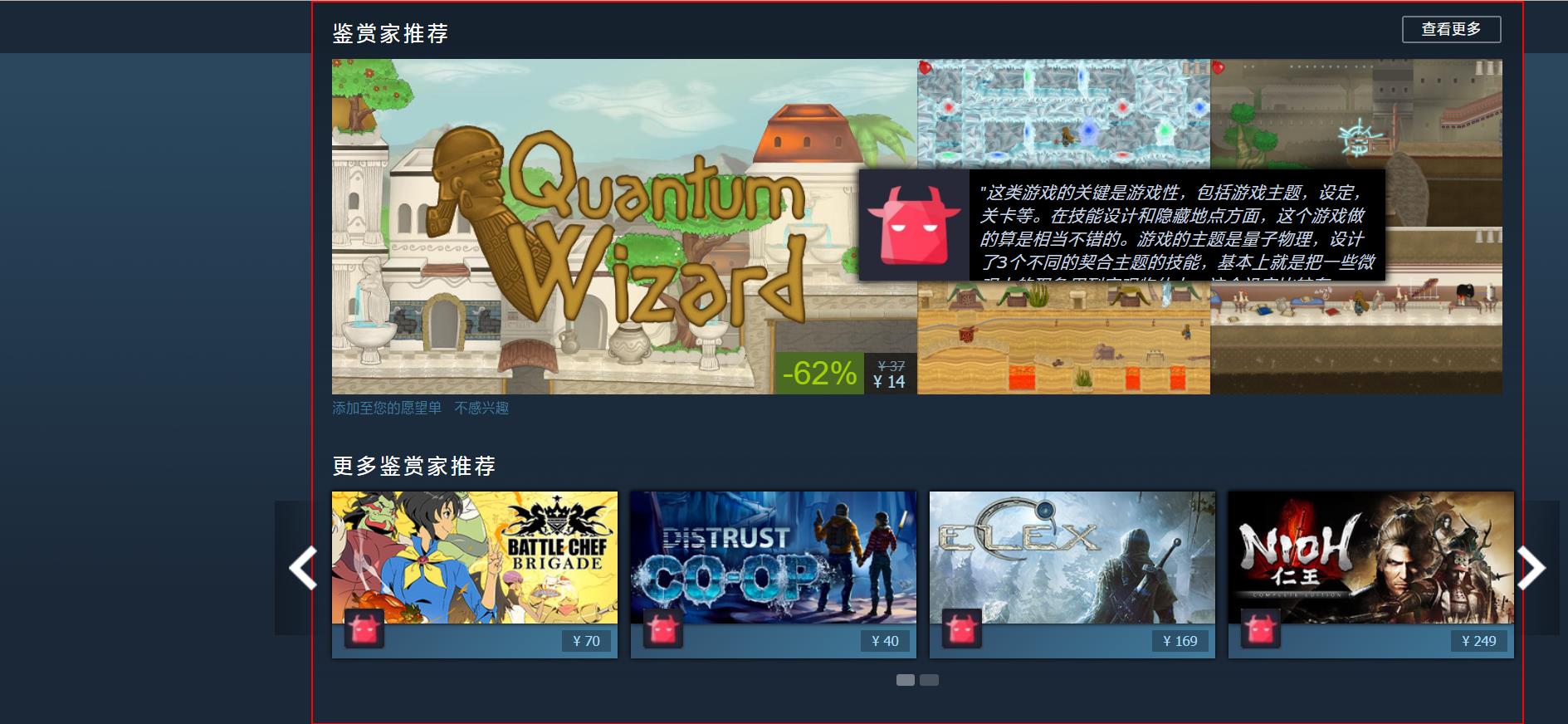
可以看到页面会滚动到鉴赏家推荐这一栏,并且我给该元素加了个红线条的边框。边框内的内容就是我们要截图保存的元素。
scrollIntoView方法的参数是一个布尔值,默认为True,指的是否与顶部对齐。true则页面从元素顶部开始,false则页面会与底部对齐。
在selenium中,webdriver有execute_script的方法
可以向webdriver中直接注入任何js代码,操作页面,并且可以传入参数。
我们可以把上面的js代码注入到webdriver中,实现同样的效果。(这里稍微改动一下,用webdriver来获取元素)
item = dr.find_element(\'class name\', \'store_capsule_frame\') dr.execute_script(\'arguments[0].scrollIntoView();\', item)
js代码中的arguments是execute_script方法后面的参数集合,这里我们将定位的元素传入,效果如上图。
现在可以让想要的元素显示出来啦,自然也可以截出一张对应的页面图片啦。
那么又该如何定位元素在图片中的位置并裁剪出来呢?
来切相片吧
先画好位置
webdriver获取的页面元素封装了对裁剪很有用的信息。这里会用到它的locaion属性。
item.location # {\'x\': 247, \'y\': 1959}
item.size # {\'width\': , \'height\': }
可以看到元素的location保存在一个字典中,分别是该元素相对整个html的x轴和y轴距离。size属性亦然。
因为截图时会以元素顶部为起始线,元素左上顶点在截图中的位置就是(item.location[\'x\'],0),右下顶点位置就是(item.locaion[\'x\'] + item.size[\'width\'], item.size[\'height\'])
学会剪裁
PIL是python中的图像处理库,pillow是其的一个分支,其核心仍然是PIL,但更易用。用pip即可安装。
来剪切刚刚保存的图片:
from PIL import Image img = Image.open("D:\\\\page.png") crop_size = (0,0,300,300) cropped = img.crop(crop_size) cropped.save(\'D:\\\\cropped.png\')
先将图片读入到内存,存储到一个Image对象中。
crop方法返回一个长方形的Image对象,需要传入要剪切的尺寸,类型为一个元组。四个值分别是裁剪出的图片距离原图片左边、上边、右边、下边的距离,说简单点,其实就是裁剪结果左上顶点的x,y坐标以及右下定点的x,y坐标(以原图的左上顶点为原点)。
上面的操作会从原图片的左上角裁剪出一个300*300的正方形。

初步代码
def get_element_screenshot(driver, by, value, path):
from selenium import webdriver from PIL import Image ele = driver.find_element(by, value) driver.execute_script(\'arguments[0].scrollIntoView();\', ele) if driver.save_screenshot(path): img = Image.open(path+\'_Page.png\') size = (ele.location[\'x\'],0,ele.location[\'x\']+ele.size[\'width\'],ele.size[\'height\']) cropped = img.crop(size) cropped.save(path+\'Cropped.png\') del img, cropped print(\'Image is cropped successfully.\') return True else: print(\'Image not saved.\') return False
跌落的坑
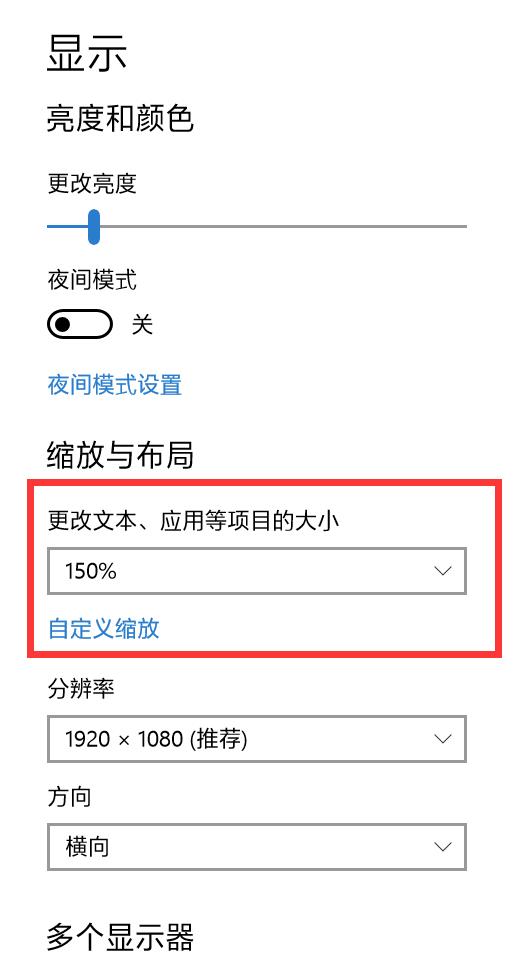
我在截图过程中,发现按照页面元素的实际大小去截取而得的图片总是要小很多。原先以为是截取时选择的高和宽不对,毕竟js中height值根据padding和boder是否包含分为了clientHeight、offsetHeight等值。但查找多时,仍是没有结果,无论怎样改变,都无法准确截取。去浏览器的控制台中选中元素查看,发现元素的高宽和实际的像素值差了一些,实际值是其1.5倍。突然想到是否和分辨率有关,就去看了一下,是1920 * 1080。在控制台中用window.screen.availHeight获得可用高度,刚好是1.5倍。我以为症结就是这个,就搜索了一下,准备用win32api模块中的GetSystemMetrics方法获得屏幕分辨率,在除以可用高/宽度,拿到一个比例。但是执行该方法查询后发现结果是1280和720。我觉得很奇怪,不是1920 * 1080吗?又去显示设置去瞧了一下,才忽然知道应该是这缩放设置惹的祸,我将缩放设置为了150%。调为100%后,再去截取图片,便没有任何问题了。
费时不少,虽然错误很小,但中间也复习了height的相关知识,也学习了些win32模块的一些小知识点,算是绕路式学习。
是以为记。
尚未解决的问题
scrollIntoView方法执行后,已经到页面底部,但是元素顶部并未与页面顶部对齐,这时的元素定位方法就要随之改变,但还未写,留待之后改进。
最终代码


def get_screenshot(driver, ele, path): """ :param driver: selenium webdriver object :param by: method to find element :param value: element value :param path: path to save picture :return: """ from PIL import Image # Decide whether a scroll bar exists js_ret = driver.execute_script(\'\'\' var bounding_top = arguments[0].getBoundingClientRect(); if(document.documentElement.scrollHeight > document.documentElement.clientHeight){ arguments[0].scrollIntoView(); var rect_obj = arguments[0].getBoundingClientRect(); if(rect_obj.top == 0){ return \'scroll-and-on-the-top\'; }else{ var size_array = new Array(4); size_array[0] = rect_obj.x; size_array[1] = rect_obj.y; size_array[2] = rect_obj.right; size_array[3] = rect_obj.bottom; return size_array; } }else{ return \'no-scroll\'; } \'\'\', ele) driver.execute_script(\'arguments[0].scrollIntoView();\', ele) if driver.save_screenshot(path): img = Image.open(path) _x = ele.location[\'x\'] _y = ele.location[\'y\'] _h = ele.size[\'height\'] _w = ele.size[\'width\'] if js_ret == \'scroll-and-on-the-top\': size = (_x, 0, _x + _w, _h) elif js_ret == \'no-scroll\': size = (_x, _y, _x + _w, _y + _h) else: print(js_ret) size = tuple(js_ret) cropped = img.crop(size) cropped.save(path) del img, cropped print(\'Image is cropped successfully and saved to %s.\' % path) return True else: print(\'Image not saved due to invalid file path. Screen shot failed.\') return False
参考
关于js中getBoundingClientRect()方法的说明,戳这里:
https://www.cnblogs.com/Songyc/p/4458570.html
以上是关于Selenium自动截图怎么总是上个页面的主要内容,如果未能解决你的问题,请参考以下文章
我们是否需要同时拥有Selenium服务器和Selenium WebDriver?
Selenium2+python自动化39-关于面试的题转载