基于卷积神经网络的单图像去雨
Posted zhang716921
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于卷积神经网络的单图像去雨相关的知识,希望对你有一定的参考价值。
图像去雨是图像处理和计算机视觉领域共同关心的重要问题,传统的关于图像去雨的图像恢复方法在某些特定的情况下会失效,鉴于深度卷积神经网络(CNN)在计算机视觉领域的迅猛发展及其良好的学习性能,越来越多的研究者将CNN应用到图像恢复领域。本文主要从图像处理和物理模型的研究角度,并结合卷积神经网络技术,对图像去雨技术进行综述。并主要介绍近几年提出的典型的去雨CNN网络的基本原理和研究进展,并对这些方法给出其视觉上的效果和客观的评估数据。
近年来,随着计算机软件和硬件技术的不断发展,计算能力不断增强,对雨天图像进行去雨处理已经成为可能,这反过来又对去雨图像的清晰度和真实感提出了新的要求。在雨天情况下,由于场景的能见度低和背景场景被遮挡,图像中目标的对比度和颜色等特征都会出现不同程度的衰减,导致背景信息(即目标图像)表达不明确,这使得一些视频或图像系统不能正常工作,因此需要消除雨天对图像场景的影响。事实上,图像去雨一直是图像恢复和计算机视觉领域研究的重要内容,其主要应用于视频监控和自动驾驶等领域,因此自动性和实时性就成为了研究关注的重点。本文分析和借鉴了最近的研究热点,从图像处理和物理模型的研究角度,并结合卷积神经网络技术,对图像去雨技术进行综述。
1 基于单图深度联合雨水检测和去除
恢复下雨图像在计算机视觉系统的应用中是很重要的,雨水会遮挡背景场景,造成图像形变或者模糊,而且雨水也会产生类似于雾气的大气遮挡效果,明显降低了图像背景的能见度。无论是雨滴密集的暴雨场景还是雨痕带积聚的场景,该团队论文提出的方法都可以良好的从单图像中解决去雨问题。其主要思想在于新的图像雨水模型(Rain model)和基于此雨水模型的深度网络架构。
1.1 雨水图像模型
广泛使用的雨水模型,表达式如下所示:![]() ,其中B代表背景层,即要获取的目标图像;S代表雨痕层;O代表有雨痕的输入图像(雨痕降质图像)。基于这个模型,图像去雨被认为是“双信号分离问题”,也就是说基于给定的降质图像O,由于背景层和雨痕层的具有各自不同的特点可以实现将两层分离,从而得到目标结果。但是这个模型有两个缺陷:首先,层密度不均匀,因为该层只有部分区域有雨痕,使用统一的稀疏编码建模的效果是不理想的;其次,解决信号分离问题,没有区分有雨区域和无雨区域,这会导致处理后的背景过度平滑,导致形变或者模糊。
,其中B代表背景层,即要获取的目标图像;S代表雨痕层;O代表有雨痕的输入图像(雨痕降质图像)。基于这个模型,图像去雨被认为是“双信号分离问题”,也就是说基于给定的降质图像O,由于背景层和雨痕层的具有各自不同的特点可以实现将两层分离,从而得到目标结果。但是这个模型有两个缺陷:首先,层密度不均匀,因为该层只有部分区域有雨痕,使用统一的稀疏编码建模的效果是不理想的;其次,解决信号分离问题,没有区分有雨区域和无雨区域,这会导致处理后的背景过度平滑,导致形变或者模糊。
基于以上的缺陷,对上述模型进行改进。使得层既包含雨痕的位置信息也要包含特定像素点位置的雨痕对像素值的贡献构成。由此得出一个广义的雨水模型,如下所示:![]() ,这里包含了一个基于区域的变量R,指明了单独可见的雨痕位置,该变量其实是一个二值图,值为“1”表示对应像素位置有雨痕,值为“0”表示对应像素位置没有雨痕。之所以将S、R分别描述并分别用于网络预测,是为了避免只回归S影响了图中不含雨滴的部分。对R独立建模有以下两点好处:首先,为网络提供更多的信息学习雨痕区域;其次,可以检测到雨水区域和非雨水区域,对两者做不同的处理,可以最大化得到背景层的信息。
,这里包含了一个基于区域的变量R,指明了单独可见的雨痕位置,该变量其实是一个二值图,值为“1”表示对应像素位置有雨痕,值为“0”表示对应像素位置没有雨痕。之所以将S、R分别描述并分别用于网络预测,是为了避免只回归S影响了图中不含雨滴的部分。对R独立建模有以下两点好处:首先,为网络提供更多的信息学习雨痕区域;其次,可以检测到雨水区域和非雨水区域,对两者做不同的处理,可以最大化得到背景层的信息。
在现实场景中,基于雨痕带具有不同的形状和不同的方向且雨痕之间会相互重叠,以及暴雨情况下的雨水积聚产生的雾气效果导致远处场景的能见度降低这两个主要的问题,该方法提出了一个更细致的雨水模型,该模型包含多个雨痕层(每个雨痕层中的雨痕方向是一致的),也包含了全局大气光的作用效果(用来模拟雨水产生的雾气效果),模型公式表示如下:![]() ,这里S表示一个雨痕层,该层中的雨痕方向都是一致的;t是雨痕层的索引;A是全局大气光,其实质是对雨水产生的雾气效果进行建模;是全局大气光传输系数。这个模型,同时实现了雨水效果和雾气效果的一种综合状态,更逼近真实的降雨效果,基于这个模型得到的目标图像更接近自然图像。
,这里S表示一个雨痕层,该层中的雨痕方向都是一致的;t是雨痕层的索引;A是全局大气光,其实质是对雨水产生的雾气效果进行建模;是全局大气光传输系数。这个模型,同时实现了雨水效果和雾气效果的一种综合状态,更逼近真实的降雨效果,基于这个模型得到的目标图像更接近自然图像。
1.2 联合雨水检测和去除的深度卷积神经网络
基于以上模型,提出了一个循环雨水检测和去除的深度网络架构,具体结构如图1所示。
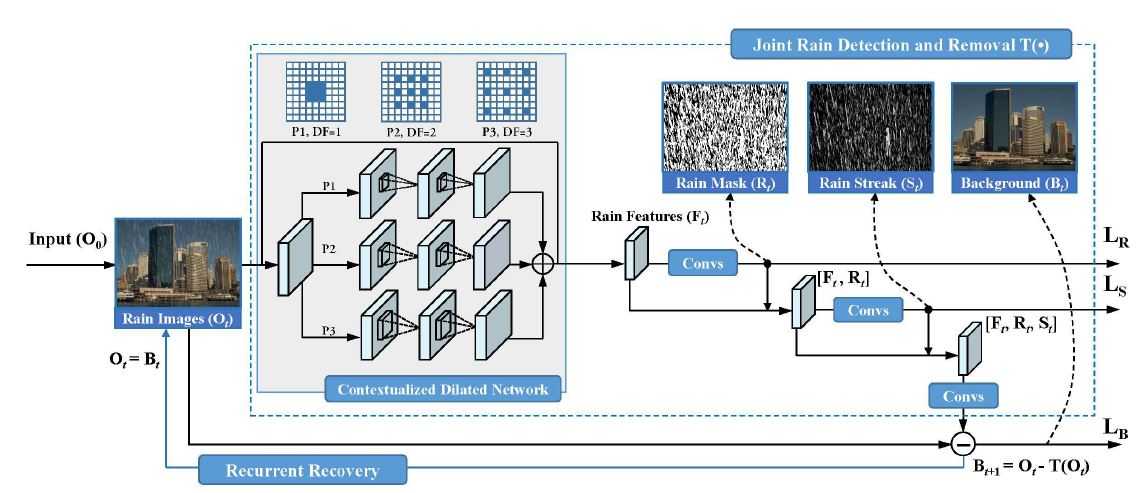
图1 循环雨水检测和去除网络架构。每次循环使用一个多任务网络进行雨水检测和去除(蓝色的点框)
情境化的上下文扩张网络:该深度架构包含一个新颖的网络结构,即基于情境信息的上下文扩张网络(Contextualized dilated network),此结构用于提取雨水图像的可识别特征,为后续的检测和去除做基础。
扩张卷积技术(Dilated Convolutions):上下文信息对于图像雨痕区域的检测和识别是非常有用的,使用情境化的上下文扩张网络可以聚合多尺度的上下文信息来学习雨水图像的特征信息。扩张卷积与普通的卷积相比,除了卷积核的大小以外,还有一个扩张因子(Dilated factors)参数,主要用来表示扩张的大小。扩张卷积与普通卷积的相同点在于,卷积核的大小是一样的,在神经网络中即参数数量不变,区别在于扩张卷积具有更大的感受野(Receptive field)。在图1中可以看到该网络包含三条卷积路径,每条卷积路径均使用3*3的卷积核,第一个卷积路径使用普通的卷积核,其余两条路径则使用扩张卷积技术,所以具有不同的扩张因子[DF = 1, 2, 3],使得提取到特征具有不同的接受视野[5*5, 9*9, 13*13]。基于这种思想,可以提取更丰富的图像上下文信息,使得特征具有更强的鲁棒性。
循环子网络:图1中的蓝色的点框是该子网络的结构,每次循环的结果会相应的生成一个残差图像T(*),该结果会作为下一次循环子网络的输入,每次的预测残差值随着网络的循环而累积。并且每次循环所需要的雨水掩模层和雨痕层,并不相同,而是通过损失和每次进行正则化后的结果。
1.3 实验结果
定性评估:以下给出本方法和其他方法,基于相同的真实雨水图像的测试数据集下的采样结果,其中主要了比较了DSC(鉴别稀疏编码)和LP(层先验),对比结果如下图2所示:
图2 基于真实图像,不同方法的测试结果。从左到右依次对应:输入测试图像,DSC,LP和本文方法
定量评估:主要使用峰值信噪比(PSNR)和结构相似性(SSIM)两个度量来对不同的去雨方法进行数据比较,并且对应度量的数值越大表明效果越好。表1是基于数据集Rain12和Rain100L得出的对比结果。
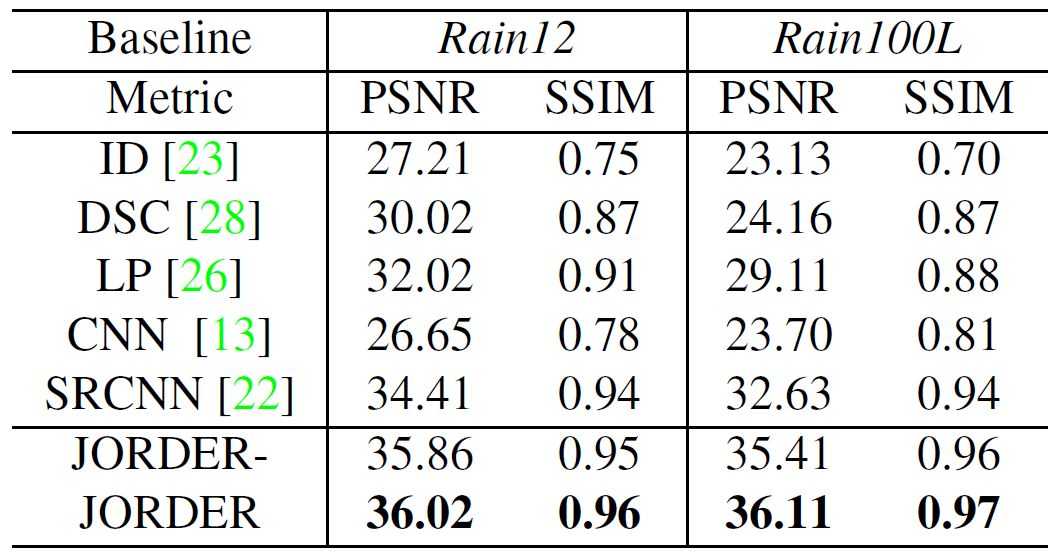
表1 基于数据集Rain12和Rain100L,不同去雨方法在PSNR和SSIM度量得出的结果
2 使用Attentive GAN对单图像去雨
本方法解决了一个更具挑战性的问题,去除落在玻璃或者镜头上的雨滴。首先,被雨水遮挡的原图像信息是不可知的;其次,被遮挡的背景信息不可避免会丢失很多;如果输入图像的雨滴较大并且分布密集时,情况会变得更加棘手。这给问题的解决带来了极大的难度。
为了解决这个问题,该团队论文提出了使用注意力生成对抗网络(Attentive GAN)。主要思想是模拟人的视觉注意力(Visual attention),将注意力进行量化,然后同时应用于生成网络(Generative network)和判别网络(Discriminative network)进行训练。在训练过程中,量化的视觉注意力可以学习到更多的雨水区域及其周围的信息。因此,将视觉注意力应用于生成网络和判别网络,可以使得生成网络能更好的聚焦于雨水区域及其周围的结构信息,也可以使得判别网络获得图像恢复区域的局部一致性信息。
2.1 雨水图像模型
本方法将被雨滴降质的图像视为是图像背景信息和雨滴效果共同作用产生的结果,并为降质图像进行构建了物理模型,表达式如下所示:![]() ,
,
这里的I表示输入图像;M是基于整张图像的每个像素二进制掩模(Binary-Mask,对于像素x,如果被雨滴覆盖,则M(x) = 1,否为M(x) = 0);B是图像的背景(即想要得到的目标图像);R是雨滴带来的影响综合效应(图像背景信息、环境反射光和附着在挡风玻璃或者镜头的雨滴的折射光的一种复杂混合,因为雨水是透明的,由于雨滴形状和折射率的问题,图像雨水区域内的一个像素会受到周边像素的影响,是一个综合的效应表现);操作符表示逐像素乘法。
基于这个模型,目标是从输入降质图像I获取目标图像B。使用M作引导生成注意力映射图(Attention map),并应用到GAN来实现目标图像的生成。
2.2 Attentive GAN网络结构
图3显示了本方法的整个网络的架构,可知网络主要包括两个部分:生成网络和判别网络。给定一张被雨水降质的图像,生成网络尝试生成尽可能真实的无雨图像,判别网络则用来验证生成的图像是否足够真实。
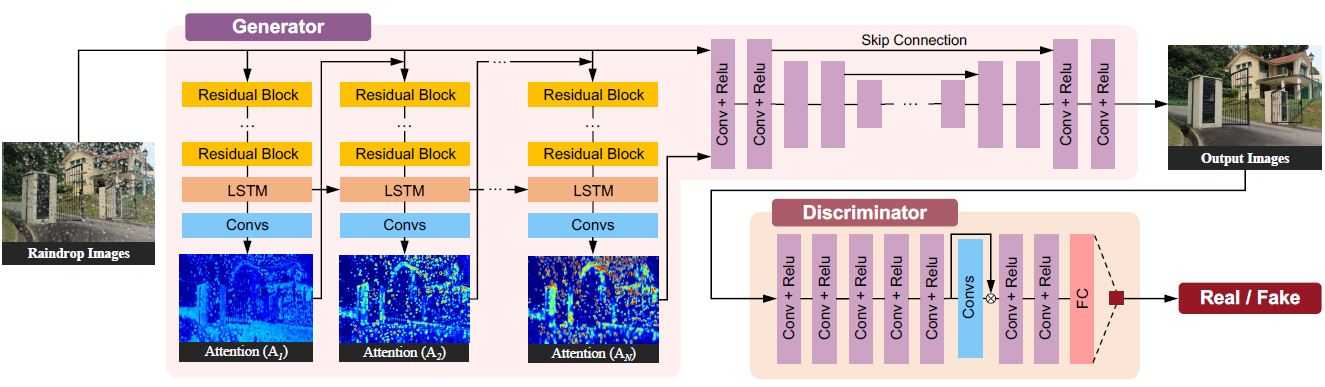
图3 Attentive GAN架构图示
生成网络:如图3所示的结构,该生成网络包含两个子网络:注意力循环子网络(Attentive-Recurrent Network)和上下文自编码器子网络(Contextual Autoencoder)。注意力循环子网络的目的是找到输入图像需要被注意的区域,主要是需要上下文自编码器子网络需要聚焦的雨水及其周围的区域。这样可以生成更好的局部恢复图像,以便判别网络更好的聚焦和评估。
注意力循环子网络:视觉注意力模型应可以帮助定位一张图像的目标区域,并获取该区域的特征。该模型对于生成无雨图像也同样重要,因为它可以让网络聚焦于图像修复区域。图3中显示,该方法使用循环网络生成量化后的图像的视觉注意力,对于每个时间步,其输入是原始输入图像和上一时间步的注意力映射图,它包含五个ResNet残差块层用于提取特征,和一个卷积LSTM单元以及一个卷积层用于生成一张2D的注意力图。
从每个时间步学习得到的注意力映射图,是一个二维的矩阵,每个元素的取值范围为0 ~ 1,且元素的值越大,表示该元素对应图像区域获到了更大的关注值。因此从整体来看,随着时间步的推移,每个步骤获取的注意力图的元素值是逐渐增加的。注意:第一个时间步的输入是原始图像和一个初始化的注意力映射图。
增加注意力机制是有意义的,注意力增加可以扩大关注的区域,使得雨水区域的周围信息也得到关注;不同的雨滴具有不同的透明度,背景信息不能完全被遮挡,扩大注意力可以透过雨滴捕捉到一些背景信息。
上下文自编码器子网络:该子网络的将原始输入图像和注意力循环子网络最后一个时间步生成的注意力映射图作为输入,以获取一张无雨图像为目标的。该深度自编码器包含16个conv-relu块和跳跃连接(Skip Connection)来防止目标图像模糊。具体结构如图4所示。
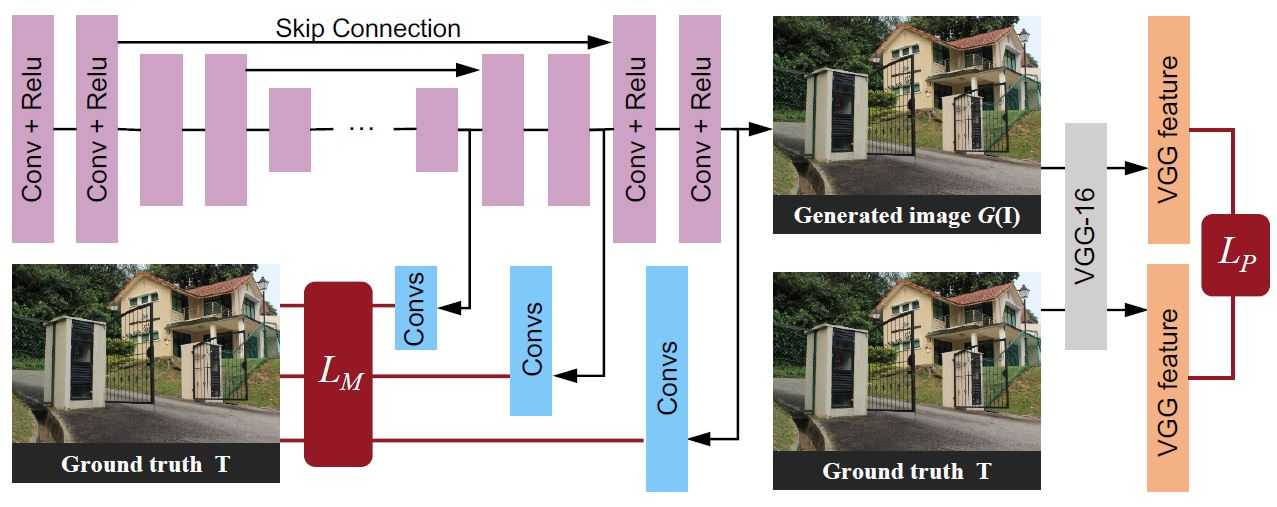
图4 上下文自编码器的结构。多尺度损失和感知损失被用于训练该子网络
由图4可以看出,该子网络使用了多尺度损失(Multi-scale loss)和感知损失(Perceptual loss)。基于像素操作的多尺度损失,从不同的解码层(Decoder layers)提取特征来形成不同尺寸的输出,这可以获取更多的上下文信息。感知损失,用来衡量由自编码网络输出图像的特征和原视输入图像特征的整体差异,而这里提到的特征提取,是基于训练好的CNN(基于ImageNet预训练好的VGG16)。
判别网络:为了区分生成图像的真实性,一些一些基于GAN的方法,在判别网络部分常采用图像内容全局和局部一致性为标准。全局判别器用来检测整体图片的不一致性,局部判别器检测一块很小的特定区域。
该判别网络的特点是使用一个注意力判别器(Attentive discriminator),即注意力循环网络生成的注意力映射图应用到判别网络。使用注意力映射图来引导判别器聚焦相应的区域,更好的来判断图像的真实性。
2.3 实验结果
定性评估:图5给出了本方法与其他论文提出的一些方法(主要是Eigen和Pix2Pix)的结果对比;图6给出了整个网络(AA+AD)与该网络体系其他可能的配置的结构(A,A+D,A+AD)的结果对比。A(无注意力映射图的自编码器),A + D(无注意力映射图自编码器加无注意力映射图判别器),A + AD(无注意力映射图自编码器加上有注意力映射图鉴别器),AA + AD(有注意力映射图自编码器和有注意力映射图判别器)表示本方法的网络整体架构。
无论雨滴颜色、形状和透明度具有多样性,本文方法都几乎都可以完全去除。

图5 不同方法的结果比较。从左到右:原始输入图像,Eigen,Pix2Pix,本文方法

图6 网络体系及其可能的配置结构之间的结果对比
定量评估:表2给出了本文方法和已有方法在峰值信噪比(PSNR)和结构相似性(SSIM)两个度量上比较的结果,对应度量的数值越大表明效果越好。
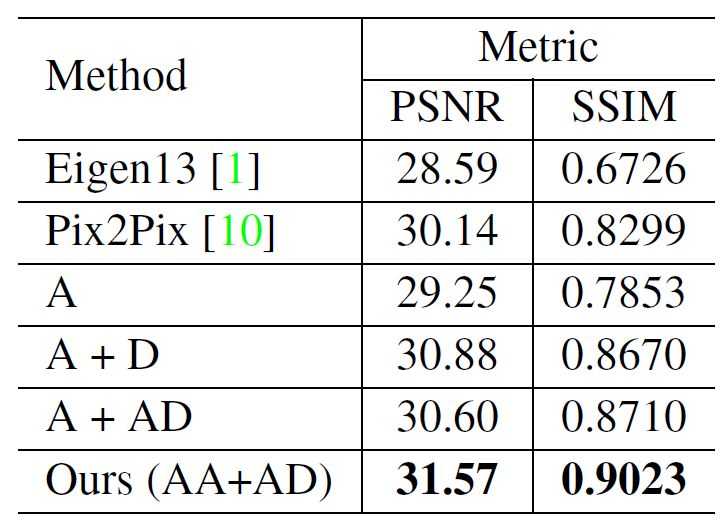
表2 定量评估结果
3 总结与展望
方法一团队提出了一种区域相关的雨水图像模型,用于进一步检测雨水,并进一步更好的模拟雨水积聚和暴雨的情况,并基于此模型提出一种联合雨水检测和去除的网络结构,对于去除雨痕积聚的情况很有效果;方法二团队提出了一种基于单幅图像的雨滴去除方法,该方法利用生成对抗网络,其中生成网络通过特殊的循环机制产生注意力映射图,并将该图与输入图像一起通过上下文自动编码器生成无雨滴图像,对于去除明显可见且密集的雨滴效果明显。
为了更好的泛化,获得更普适的去雨机制,可以尝试探索将两种方法结合起来的一种方法,此方法的展望需要进一步的实验探究和验证。经过不断的研究,图像去雨已经取得了较大的成就,但将卷积神经网络技术应用于图像去雨仍然需要继续探索。
4. 参 考 文 献
[1] Qian R, Tan R T, Yang W, et al. "Attentive Generative Adversarial Network for Raindrop Removal from a Single Image. " The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018
[2] Yang, Wenhan, et al. "Deep joint rain detection and removal from a single image." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
[3] Fu, Xueyang, et al. "Removing rain from single images via a deep detail network." The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017.
[4] Cai, Bolun, et al. "Dehazenet: An end-to-end system for single image haze removal."IEEE Transactions on Image Processing25.11 (2016): 5187-5198.
[5] Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions[J]. arXiv preprint arXiv:1511.07122, 2015.
[6] 徐波, 朱青松, 熊艳海. "视频图像去雨技术研究前沿." 中国科技论文 10.8 (2015): 916-927.
[7] 郭潘, et al. "图像去雾技术研究综述与展望." 计算机应用 30.9 (2010).
以上是关于基于卷积神经网络的单图像去雨的主要内容,如果未能解决你的问题,请参考以下文章
深度学习:图像去雨网络实现Pytorch 一个简单实用的基准模型(PreNet)实现