AMD二代霄龙实测:双路128核心256线程无情碾压
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AMD二代霄龙实测:双路128核心256线程无情碾压相关的知识,希望对你有一定的参考价值。
参考技术A近日,AMD正式发布了第二代EPYC霄龙骁龙处理器,为数据中心市场奉上一道大餐,规格参数遥遥领先,生态建设也是欣欣向荣。那么实际性能到底如何呢?AnandTech有幸进行了一番实测,一起来瞻仰瞻仰。
二代霄龙的规格无疑是相当炫目的,也没有任何敌手:7nm全新工艺、Zen 2全新架构、Chiplet小芯片设计、最多64核心128线程、最大256MB三级缓存、首发支持PCIe 4.0并有128条通道、单路最大4TB DDR4-3200内存、18GT/s高速低延迟第二代Infinity Fabric互连总线、SME安全内存加密、SEV安全加密虚拟化……
AnandTech拿到的是 旗舰型号霄龙7742,64核心128线程,基准频率2.25GHz,最高加速3.40GHz,三级缓存256MB,热设计功耗225W,价格为6950美元。
Intel方面目前最顶级的是 至强铂金8280/8280M ,14nm工艺,28核心56线程,基准频率2.7GHz,最高加速4.0GHz,三级缓存38.5MB,热设计功耗205W,价格10009/13012美元。
其实,Intel也有56核心112线程的至强铂金9282,但采用了LGA封装,整合在主板上,热设计功耗高达400W,价格更是据说要五六万美元。
就在二代霄龙发布前,Intel刚刚宣布了56核心112线程的LGA独立封装新品,但尚未正式发布,具体规格也没有公布,而且即便如此核心数量上也仍处于劣势,价格怎么也得两三万美元。
二代霄龙双路产品线
二代霄龙VS二代可扩展至强
二代霄龙单路产品线
实际测试中用了两颗霄龙7742,组成双路共128核心256线程,搭配主板是一块参考设计板子,内存是美光的DDR4-3200 512GB(32GB×16),硬盘启动盘是三星MZ7LM240、数据盘是美光9300 3.84TB,电源1200W。
同时还有 初代霄龙旗舰7601 ,32核心64线程,最高频率2.2-3.2GHz,三级缓存64MB,热设计功耗180W,也搭配16条32GB内存。
Intel方面参战一个是刚才说的 至强铂金8280 ,另一个是初代可扩展 至强铂金8176 ,也是28核心56线程,频率2.1-3.8GHz,三级缓存38.5MB,热设计功耗165W,价格8725美元。
有时候还会加入 至强E5-2699 v4 ,Broadwell四代酷睿同架构,14nm工艺,22核心44线程,频率2.2-3.6GHz,三级缓存55MB,热设计功耗145W,价格4115美元。
由于服务器的测试项目都比较专业、复杂,我们这里不做过多展开,看看对比差异就好。
另外,霄龙的内存延迟问题由于比较复杂,后续将单独展开介绍。
SPEC CPU2006单线程测试中,霄龙7742、7601单个核心可以分别最高加速到规定的3.4GHz、3.2GHz,至强8176也能如约达到3.8GHz,但无法获得至强8280的数据,如果能达到4GHz则性能可比至强8176高出大约3-5%。
霄龙7742的单线程性能比前代霄龙7601几乎每个项目中都有明显提升,最多达到了36%,平均也有18%。如果排除一个不变、一个倒退1%,其他项目平均提升幅度达22%。
霄龙7742对比至强8176则是有高有低,最好的领先28%,最差的落后39%,平均落后7%,如果对比至强8280可能落后10%左右。
另外要注意,GCC编译器的版本非常重要,越新越好,GCC 8.3相比于GCC 7.4霄龙7742的性能略有提升,456.hmmer甚至翻了一番。
SPEC CPU2006多线程测试中,霄龙7742相比霄龙7601核心数翻番、频率更高,领先幅度最高达到了恐怖的153%,平均也有109%,翻了一番还多。
霄龙7742对比至强8176更是碾压一般的存在,最多领先188%,最少领先36%,平均高达121%!即便是对至强8280也能领先超过110%。
在部分测试中比如libquantum,霄龙7742可以所有核心线程都跑到3.2GHz,而在另一些测试比如h264ref则都是2.5GHz。
7-Zip压缩测试中,霄龙7742领先霄龙7601 78%,领先至强8176 54% ,解压测试中分别领先1.27倍、 1.51倍 。
Java Max-jOPS测试中,霄龙7742领先霄龙7601 60%,领先至强8280 38-48% 。
如果每个节点四个Java虚拟机,官方数据提供的霄龙7742性能可领先联想系统实测的至强8280 73%。
Java Critical-jOPS测试中,大页(huge pages)的话霄龙7742领先至强8176 33% ,小页(small pages)则是可怕的 2.57倍 。
按照两家官方数据,如果为虚拟机配置更大内存,霄龙7742可领先 66% 。
NAMD高性能计算测试,至强8280终于扳回一局,但即便是开启AVX-512指令集,也只能领先霄龙7742 2%,否则的话霄龙7742就能领先 43% ,而对比霄龙7601则提升了71%。
虽然因为时间关系,本次测试并不全面深入,尤其是缺乏最高负载的测试,但是 很明显可以看出二代霄龙的强大优势,相比对手性能超出50-100%,而价格低了40%,无论性能、性价比、能耗比都无情碾压。
更何况,二代霄龙还有更新的工艺、更多的核心、更多的内存通道和容量、更多的PCIe通道和首发的PCIe 4.0。
这也难怪众多软硬件企业巨头都纷纷力捧AMD,也难怪AMD提出了数据中心市场份额要达到两位数的目标(目前为3.4%)。
AnandTech也是对二代霄龙赞不绝口,认为AMD达成了精彩绝伦(stellar)的成就,值得热烈鼓掌。
AMD后续还有Zen 3、Zen 4架构按期推进,Intel则会在明年推出10nm Ice Lake新工艺新架构的新至强,号称IPC提升18%,也支持八通道内存,核心数几乎肯定要多于56个,但不知道是否也会采用chiplet小芯片设计,频率和功耗又会如何。
高性能编程:三级缓存(LLC)访问优化
AMD 服务器,多线程应用绑核,选取不同的 CPU 核,性能差距可达50%。
最近有幸因项目拿到一台 AMD EPYC 系列测试服务器,发现了一些奇怪的现象。
这台测试服务器拥有双路 AMD EPYC 7552 处理器,属于第二代 Rome(Zen2)架构,单路 48 个物理核,双路总计 192 个逻辑核(线程),有两个 NUMA 节点。
为了进行测试,预先编写了一个简单的多线程程序:
两个线程,分别为生产者、消费者,模拟 route-worker 模型;
三个线程,分别为生产者、转发者、消费者,模拟 pipeline 模型。
线程间采用无锁队列通信。生产者依次写入 1 ~100000000,消费者取出数字求和。线程每次写入或读取队列数据后执行一些无意义循环用于消耗时间,模拟业务逻辑。
所有线程分别绑核,避免线程迁移导致 Cache 抖动,且绑定的核心属于同一个 CPU。所有队列均在这个 CPU 的本地内存上进行分配,避免跨 NUMA 的远程内存访问。
奇怪的现象
测试发现,线程绑到不同的核上,有显著的性能差异:
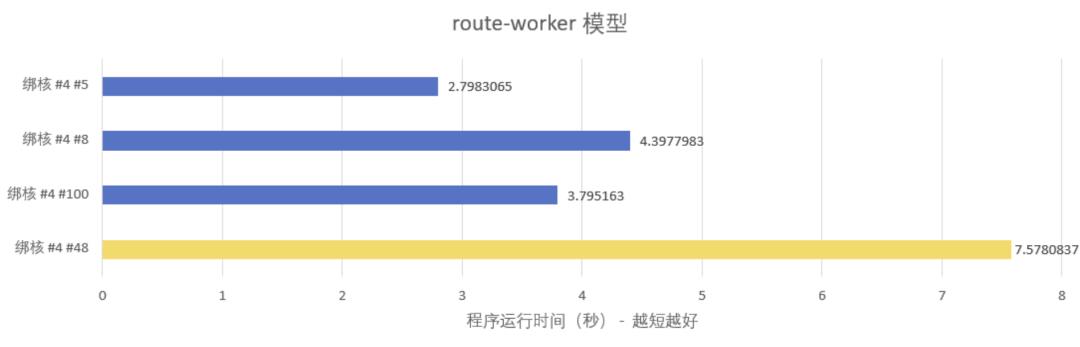
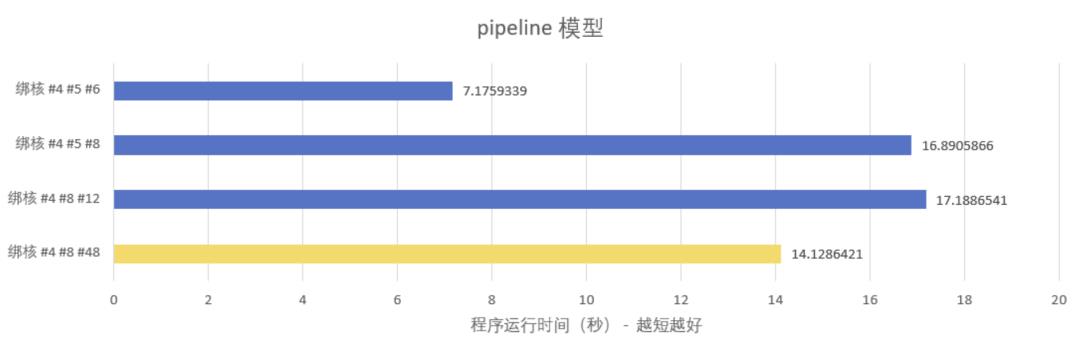
绑核说明:
核 #4 #5 #6 #8 #12 #100 均为同一个 CPU,不存在跨 NUMA 访问内存的情况;
核 #4 #100 是一对 SMT 核心,即同一个物理核虚拟出来的两个逻辑核;
黄条涉及的核 #48 属于另一个 CPU,存在跨 NUMA 访问内存的情况,仅供对比。
测试结果反映了一个很奇怪的现象:线程绑核,在同一个 NUMA 选取不同的核心,性能差距竟然达到 50%(route-worker 模型 #4#5 vs #4#8)甚至 140%(pipeline 模型 #4#5#6 vs #4#8#12)。
这究竟是为什么呢?
复杂的内存层次模型
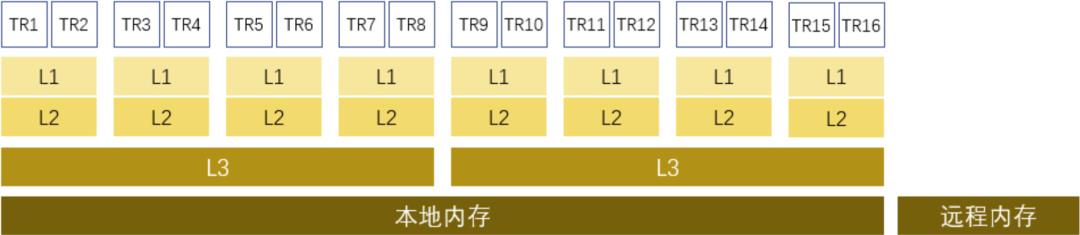
这要从内存层次说起。通常,根据延迟时间从小到大,内存层次可以划分为:(1)L1,一级缓存;(2)L2,二级缓存;(3)L3,又叫 LLC,三级缓存;(4)内存。
在具体实现上,传统的 Intel 至强系列模型比较简单:
每个物理核虚拟出两个逻辑核(TR1/TR2,TR3/TR4)
每个物理核独有 L1 和 L2
所有物理核共享 L3
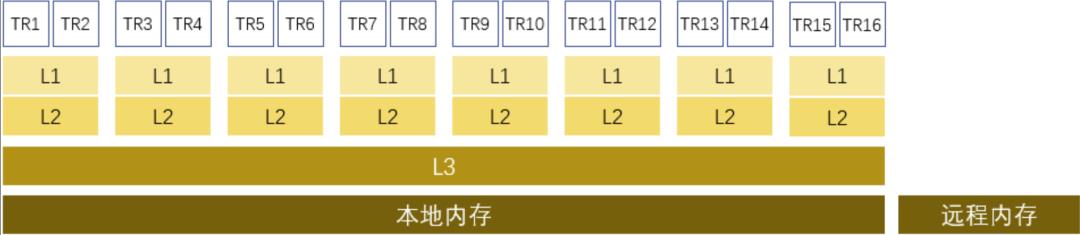
这就解释了一些高性能程序开发的优化策略:
避免跨 NUMA 的远程内存访问,除了降低访问延迟,对 L3 也更友好
将线程绑核,避免 Cache 抖动,具体是避免 L1 和 L2 的抖动
共享 L3 的存在是透明的,软件上不关心,也无法关心
这一切,在 AMD 的体系结构中发生了变化。
AMD 于 2017 年发布了 Zen 架构,其中一个重要的设计原则是:一块 CPU 由多个 CCX(CPU Complex)堆叠而成。那么,CCX 是什么呢?简单来说,CCX 实际上就是 4 个物理核(8 个逻辑核)+ L3。CCX 通过 IF 总线与 IO Die 连接(Rome),实现 CCX 间互通以及与内存、IO 的通信。
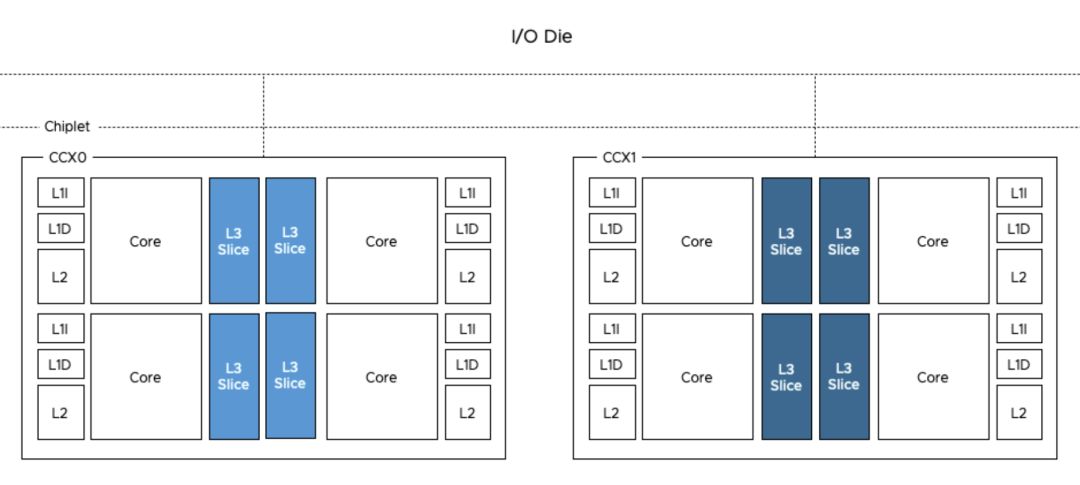
图片来源:
https://frankdenneman.nl/2019/10/14/amd-epyc-naples-vs-rome-and-vsphere-cpu-scheduler-updates/
所以,AMD EPYC 的内存模型就和传统模型有了很大区别:L3 并不由所有物理核共享,而是由同一个 CCX 内的 4 个物理核共享。与 NUMA 引入的“远程内存”概念类似,CCX 引入了“远程 L3”的概念。
在网上找到一个访问延迟表,供参考:
| 事件 | 延迟 |
|---|---|
| 一个 CPU 周期(2.3GHz 主频) | 0.4 ns |
| 访问 L1 | 1.6 ns |
| 访问 L2 | 4.8 ns |
| 访问 L3 | 15.2 ns |
| 访问远程 L3 | 63 ns |
| 访问本地内存 | 75 ns |
| 访问远程内存 | 130 ns |
结论与优化建议
结论是,在 AMD 服务器下,如果要获得更高的性能,要针对 L3 进行优化,方法为:把一组任务(线程、进程)绑定到同一个 CCX 下的核心。
那怎样才能知道哪些核心是同一个 CCX 呢?可以使用 hwloc-ls 命令:
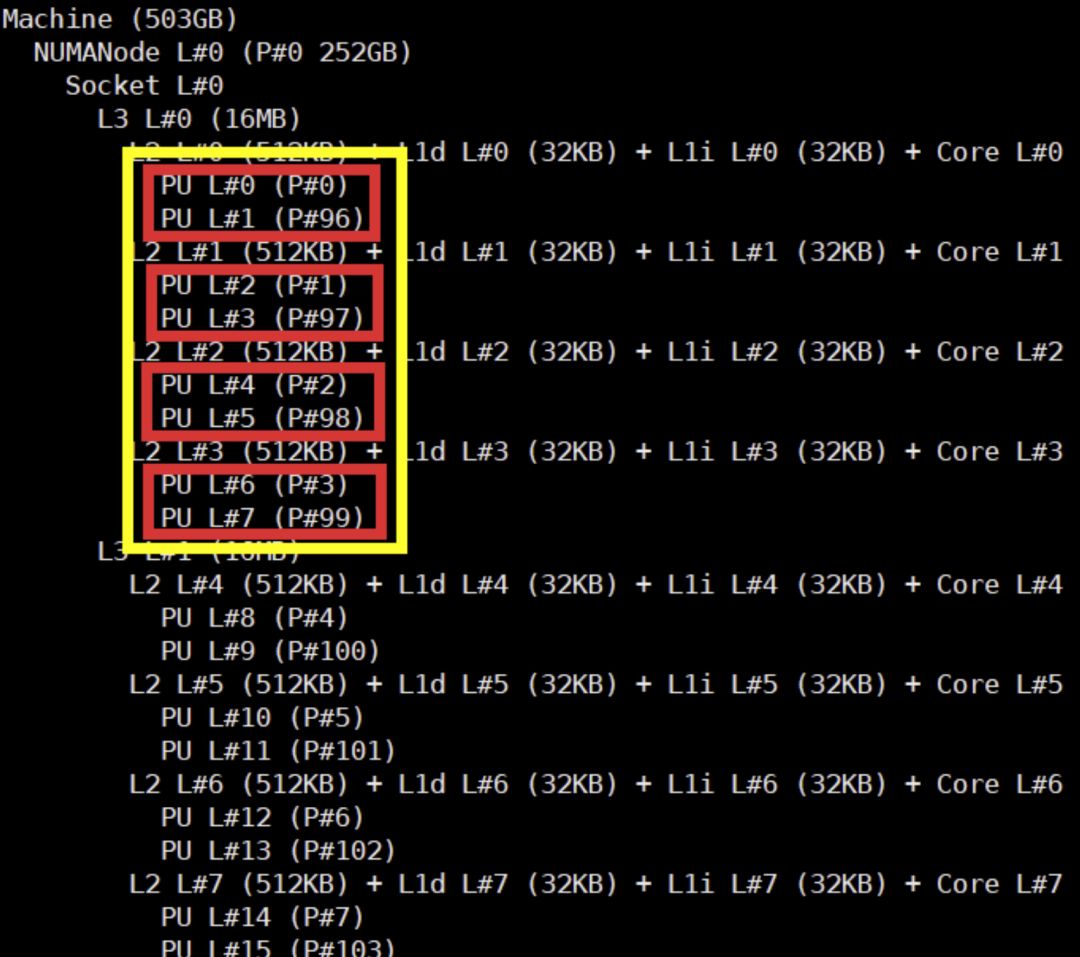
可以看出:#0 #96 #1 #97 #2 #98 #3 #99 是 4 个物理核 8 个逻辑核,它们共享了 16 MB 的 L3,所以这几个核属于同一个 CCX。
因此,绑核的时候,可以绑 #0 #1 #2 #3 #96 #97 #98 #99,又或者 #4 #5 #6 #7 #100 #101 #102 #103,以此类推。
文章开头的测试结果就很好解释了:#4 #5 #6 是同一个 CCX,因为它们共享 L3,每次读写队列其实都是读写 L3,所以性能高;#4 #8 #12 分属 3 个不同的 CCX,每次写队列,都会使得其它 CCX 的 L3 数据失效,导致读队列时必须要从内存中读取,所以性能差。
最后,可以通过:
perf stat -e r510143,r510243,r510843,r511043,r514043 ./xxx
查看 L3 的访问情况,PMC Code 来自 AMD的官方文档:

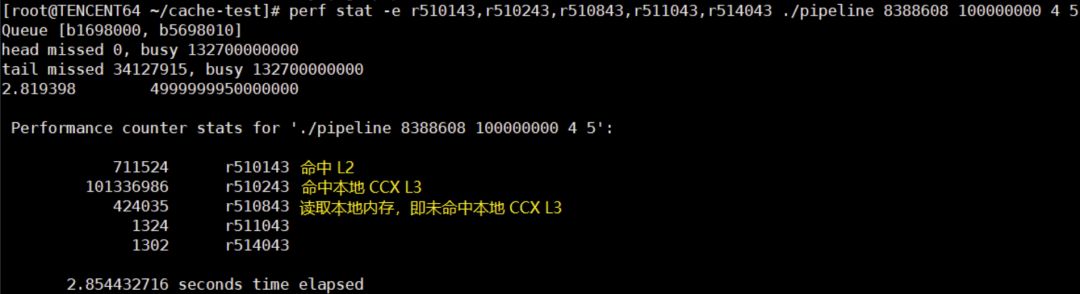
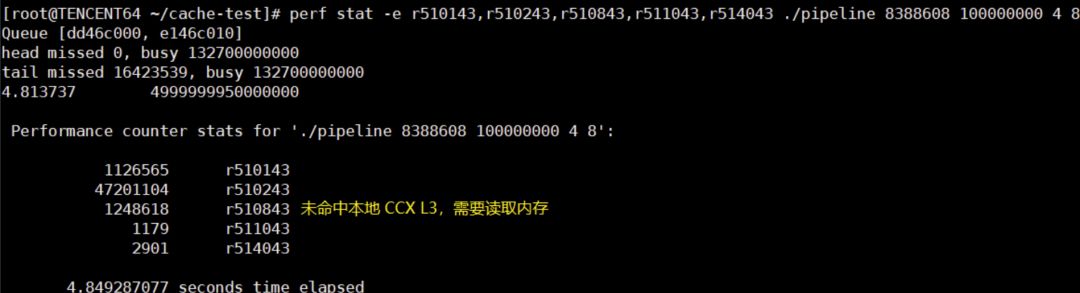
可以看到绑核 #4 #8 读取内存次数几乎是绑核 #4 #5 的 3 倍。
扫描/识别二维码关注"Linux阅码场"

如果您觉得不错,请转发转发转发!
或者随手点个“在看”吧~
以上是关于AMD二代霄龙实测:双路128核心256线程无情碾压的主要内容,如果未能解决你的问题,请参考以下文章
AMD展示64核EYPC处理器性能:比Intel至强8280快一倍以上