如何在win7下的eclipse中调试Hadoop2.2.0的程序
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在win7下的eclipse中调试Hadoop2.2.0的程序相关的知识,希望对你有一定的参考价值。
在上一篇博文中,散仙已经讲了Hadoop的单机伪分布的部署,本篇,散仙就说下,如何eclipse中调试hadoop2.2.0,如果你使用的还是hadoop1.x的版本,那么,也没事,散仙在以前的博客里,也写过eclipse调试1.x的hadoop程序,两者最大的不同之处在于使用的eclipse插件不同,hadoop2.x与hadoop1.x的API,不太一致,所以插件也不一样,我们只需要使用分别对应的插件即可.
下面开始进入正题:
序号 名称 描述
1 eclipse Juno Service Release 4.2的本
2 操作系统 Windows7
3 hadoop的eclipse插件 hadoop-eclipse-plugin-2.2.0.jar
4 hadoop的集群环境 虚拟机Linux的Centos6.5单机伪分布式
5 调试程序 Hellow World
遇到的几个问题如下:
Java代码 
java.io.IOException: Could not locate executable null\\bin\\winutils.exe in the Hadoop binaries.
解决办法:
在org.apache.hadoop.util.Shell类的checkHadoopHome()方法的返回值里写固定的
本机hadoop的路径,散仙在这里更改如下:
Java代码 
private static String checkHadoopHome()
// first check the Dflag hadoop.home.dir with JVM scope
//System.setProperty("hadoop.home.dir", "...");
String home = System.getProperty("hadoop.home.dir");
// fall back to the system/user-global env variable
if (home == null)
home = System.getenv("HADOOP_HOME");
try
// couldn't find either setting for hadoop's home directory
if (home == null)
throw new IOException("HADOOP_HOME or hadoop.home.dir are not set.");
if (home.startsWith("\\"") && home.endsWith("\\""))
home = home.substring(1, home.length()-1);
// check that the home setting is actually a directory that exists
File homedir = new File(home);
if (!homedir.isAbsolute() || !homedir.exists() || !homedir.isDirectory())
throw new IOException("Hadoop home directory " + homedir
+ " does not exist, is not a directory, or is not an absolute path.");
home = homedir.getCanonicalPath();
catch (IOException ioe)
if (LOG.isDebugEnabled())
LOG.debug("Failed to detect a valid hadoop home directory", ioe);
home = null;
//固定本机的hadoop地址
home="D:\\\\hadoop-2.2.0";
return home;
第二个异常,Could not locate executable D:\\Hadoop\\tar\\hadoop-2.2.0\\hadoop-2.2.0\\bin\\winutils.exe in the Hadoop binaries. 找不到win上的执行程序,可以去下载bin包,覆盖本机的hadoop跟目录下的bin包即可
第三个异常:
Java代码 
Exception in thread "main" java.lang.IllegalArgumentException: Wrong FS: hdfs://192.168.130.54:19000/user/hmail/output/part-00000, expected: file:///
at org.apache.hadoop.fs.FileSystem.checkPath(FileSystem.java:310)
at org.apache.hadoop.fs.RawLocalFileSystem.pathToFile(RawLocalFileSystem.java:47)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:357)
at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:245)
at org.apache.hadoop.fs.ChecksumFileSystem$ChecksumFSInputChecker.<init>(ChecksumFileSystem.java:125)
at org.apache.hadoop.fs.ChecksumFileSystem.open(ChecksumFileSystem.java:283)
at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:356)
at com.netease.hadoop.HDFSCatWithAPI.main(HDFSCatWithAPI.java:23)
出现这个异常,一般是HDFS的路径写的有问题,解决办法,拷贝集群上的core-site.xml和hdfs-site.xml文件,放在eclipse的src根目录下即可。
第四个异常:
Java代码 
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
出现这个异常,一般是由于HADOOP_HOME的环境变量配置的有问题,在这里散仙特别说明一下,如果想在Win上的eclipse中成功调试Hadoop2.2,就需要在本机的环境变量上,添加如下的环境变量:
(1)在系统变量中,新建HADOOP_HOME变量,属性值为D:\\hadoop-2.2.0.也就是本机对应的hadoop目录
(2)在系统变量的Path里,追加%HADOOP_HOME%/bin即可
以上的问题,是散仙在测试遇到的,经过对症下药,我们的eclipse终于可以成功的调试MR程序了,散仙这里的Hellow World源码如下:
Java代码 
package com.qin.wordcount;
import java.io.IOException;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/***
*
* Hadoop2.2.0测试
* 放WordCount的例子
*
* @author qindongliang
*
* hadoop技术交流群: 376932160
*
*
* */
public class MyWordCount
/**
* Mapper
*
* **/
private static class WMapper extends Mapper<LongWritable, Text, Text, IntWritable>
private IntWritable count=new IntWritable(1);
private Text text=new Text();
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException
String values[]=value.toString().split("#");
//System.out.println(values[0]+"========"+values[1]);
count.set(Integer.parseInt(values[1]));
text.set(values[0]);
context.write(text,count);
/**
* Reducer
*
* **/
private static class WReducer extends Reducer<Text, IntWritable, Text, Text>
private Text t=new Text();
@Override
protected void reduce(Text key, Iterable<IntWritable> value,Context context)
throws IOException, InterruptedException
int count=0;
for(IntWritable i:value)
count+=i.get();
t.set(count+"");
context.write(key,t);
/**
* 改动一
* (1)shell源码里添加checkHadoopHome的路径
* (2)974行,FileUtils里面
* **/
public static void main(String[] args) throws Exception
// String path1=System.getenv("HADOOP_HOME");
// System.out.println(path1);
// System.exit(0);
JobConf conf=new JobConf(MyWordCount.class);
//Configuration conf=new Configuration();
//conf.set("mapred.job.tracker","192.168.75.130:9001");
//读取person中的数据字段
// conf.setJar("tt.jar");
//注意这行代码放在最前面,进行初始化,否则会报
/**Job任务**/
Job job=new Job(conf, "testwordcount");
job.setJarByClass(MyWordCount.class);
System.out.println("模式: "+conf.get("mapred.job.tracker"));;
// job.setCombinerClass(PCombine.class);
// job.setNumReduceTasks(3);//设置为3
job.setMapperClass(WMapper.class);
job.setReducerClass(WReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
String path="hdfs://192.168.46.28:9000/qin/output";
FileSystem fs=FileSystem.get(conf);
Path p=new Path(path);
if(fs.exists(p))
fs.delete(p, true);
System.out.println("输出路径存在,已删除!");
FileInputFormat.setInputPaths(job, "hdfs://192.168.46.28:9000/qin/input");
FileOutputFormat.setOutputPath(job,p );
System.exit(job.waitForCompletion(true) ? 0 : 1);
控制台,打印日志如下:
Java代码 
INFO - Configuration.warnOnceIfDeprecated(840) | mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
模式: local
输出路径存在,已删除!
INFO - Configuration.warnOnceIfDeprecated(840) | session.id is deprecated. Instead, use dfs.metrics.session-id
INFO - JvmMetrics.init(76) | Initializing JVM Metrics with processName=JobTracker, sessionId=
WARN - JobSubmitter.copyAndConfigureFiles(149) | Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
WARN - JobSubmitter.copyAndConfigureFiles(258) | No job jar file set. User classes may not be found. See Job or Job#setJar(String).
INFO - FileInputFormat.listStatus(287) | Total input paths to process : 1
INFO - JobSubmitter.submitJobInternal(394) | number of splits:1
INFO - Configuration.warnOnceIfDeprecated(840) | user.name is deprecated. Instead, use mapreduce.job.user.name
INFO - Configuration.warnOnceIfDeprecated(840) | mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
INFO - Configuration.warnOnceIfDeprecated(840) | mapred.mapoutput.value.class is deprecated. Instead, use mapreduce.map.output.value.class
INFO - Configuration.warnOnceIfDeprecated(840) | mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class
INFO - C
在win7下配置eclipse的hadoop环境:
1、配置插件
打开Windows->Open Perspective中的Map/Reduce,在此perspective下进行hadoop程序开发。

2、打开Windows->Show View中的Map/Reduce Locations,如下图右键选择New Hadoop location…新建hadoop连接。

3、确认完成以后如下,eclipse会连接hadoop集群。

4、如果连接成功,在project explorer的DFS Locations下会展现hdfs集群中的文件。
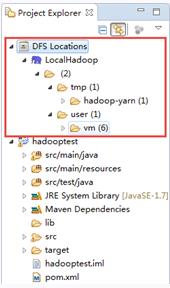
5、导入hadoop程序。
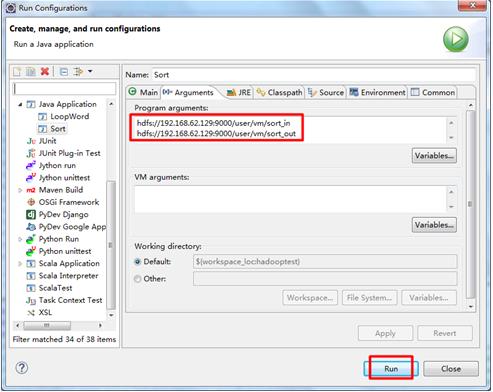
6、程序执行
右键选择Run As -> Run Configurations…,在参数中填好输入输出目录,执行Run即可。
更新 hadoop eclipse 插件
卸载hadoop 1.1.2插件。并安装新版hadoop 2.2.0插件。
假设直接删除eclipse plugin文件夹下的hadoop 1.1.2插件,会导致hadoop 1.1.2插件残留在eclipse中,在eclipse perspective视图中有Map/Reduce视图,可是没有图标,新建项目也不会出现Map/Reduce项目。
须要运行例如以下步骤:
1. 删除plugins文件夹下的hadoop 1.1.2插件,并放入hadoop 2.2.0插件。
2. 删除configuration\org.eclipse.update\文件夹下的全部文件。
3. 进入eclipse根文件夹下。执行eclipse.exe -clean启动eclipse
4. 启动完毕后。hadoop插件即更新完毕。配置hadoop跟文件夹就可以。
以上是关于如何在win7下的eclipse中调试Hadoop2.2.0的程序的主要内容,如果未能解决你的问题,请参考以下文章