如何用Python实现支持向量机
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用Python实现支持向量机相关的知识,希望对你有一定的参考价值。
参考技术A #SVM.pyfrom numpy import *
import time
import matplotlib.pyplot as plt
# calulate kernel value
def calcKernelValue(matrix_x, sample_x, kernelOption):
kernelType = kernelOption[0]
numSamples = matrix_x.shape[0]
kernelValue = mat(zeros((numSamples, 1)))
if kernelType == 'linear':
kernelValue = matrix_x * sample_x.T
elif kernelType == 'rbf':
sigma = kernelOption[1]
if sigma == 0:
sigma = 1.0
for i in xrange(numSamples):
diff = matrix_x[i, :] - sample_x
kernelValue[i] = exp(diff * diff.T / (-2.0 * sigma**2))
else:
raise NameError('Not support kernel type! You can use linear or rbf!')
return kernelValue
# calculate kernel matrix given train set and kernel type
def calcKernelMatrix(train_x, kernelOption):
numSamples = train_x.shape[0]
kernelMatrix = mat(zeros((numSamples, numSamples)))
for i in xrange(numSamples):
kernelMatrix[:, i] = calcKernelValue(train_x, train_x[i, :], kernelOption)
return kernelMatrix
# define a struct just for storing variables and data
class SVMStruct:
def __init__(self, dataSet, labels, C, toler, kernelOption):
self.train_x = dataSet # each row stands for a sample
self.train_y = labels # corresponding label
self.C = C # slack variable
self.toler = toler # termination condition for iteration
self.numSamples = dataSet.shape[0] # number of samples
self.alphas = mat(zeros((self.numSamples, 1))) # Lagrange factors for all samples
self.b = 0
self.errorCache = mat(zeros((self.numSamples, 2)))
self.kernelOpt = kernelOption
self.kernelMat = calcKernelMatrix(self.train_x, self.kernelOpt)
# calculate the error for alpha k
def calcError(svm, alpha_k):
output_k = float(multiply(svm.alphas, svm.train_y).T * svm.kernelMat[:, alpha_k] + svm.b)
error_k = output_k - float(svm.train_y[alpha_k])
return error_k
# update the error cache for alpha k after optimize alpha k
def updateError(svm, alpha_k):
error = calcError(svm, alpha_k)
svm.errorCache[alpha_k] = [1, error]
# select alpha j which has the biggest step
def selectAlpha_j(svm, alpha_i, error_i):
svm.errorCache[alpha_i] = [1, error_i] # mark as valid(has been optimized)
candidateAlphaList = nonzero(svm.errorCache[:, 0].A)[0] # mat.A return array
maxStep = 0; alpha_j = 0; error_j = 0
# find the alpha with max iterative step
if len(candidateAlphaList) > 1:
for alpha_k in candidateAlphaList:
if alpha_k == alpha_i:
continue
error_k = calcError(svm, alpha_k)
if abs(error_k - error_i) > maxStep:
maxStep = abs(error_k - error_i)
alpha_j = alpha_k
error_j = error_k
# if came in this loop first time, we select alpha j randomly
else:
alpha_j = alpha_i
while alpha_j == alpha_i:
alpha_j = int(random.uniform(0, svm.numSamples))
error_j = calcError(svm, alpha_j)
return alpha_j, error_j
# the inner loop for optimizing alpha i and alpha j
def innerLoop(svm, alpha_i):
error_i = calcError(svm, alpha_i)
### check and pick up the alpha who violates the KKT condition
## satisfy KKT condition
# 1) yi*f(i) >= 1 and alpha == 0 (outside the boundary)
# 2) yi*f(i) == 1 and 0<alpha< C (on the boundary)
# 3) yi*f(i) <= 1 and alpha == C (between the boundary)
## violate KKT condition
# because y[i]*E_i = y[i]*f(i) - y[i]^2 = y[i]*f(i) - 1, so
# 1) if y[i]*E_i < 0, so yi*f(i) < 1, if alpha < C, violate!(alpha = C will be correct)
# 2) if y[i]*E_i > 0, so yi*f(i) > 1, if alpha > 0, violate!(alpha = 0 will be correct)
# 3) if y[i]*E_i = 0, so yi*f(i) = 1, it is on the boundary, needless optimized
if (svm.train_y[alpha_i] * error_i < -svm.toler) and (svm.alphas[alpha_i] < svm.C) or\\
(svm.train_y[alpha_i] * error_i > svm.toler) and (svm.alphas[alpha_i] > 0):
# step 1: select alpha j
alpha_j, error_j = selectAlpha_j(svm, alpha_i, error_i)
alpha_i_old = svm.alphas[alpha_i].copy()
alpha_j_old = svm.alphas[alpha_j].copy()
# step 2: calculate the boundary L and H for alpha j
if svm.train_y[alpha_i] != svm.train_y[alpha_j]:
L = max(0, svm.alphas[alpha_j] - svm.alphas[alpha_i])
H = min(svm.C, svm.C + svm.alphas[alpha_j] - svm.alphas[alpha_i])
else:
L = max(0, svm.alphas[alpha_j] + svm.alphas[alpha_i] - svm.C)
H = min(svm.C, svm.alphas[alpha_j] + svm.alphas[alpha_i])
if L == H:
return 0
# step 3: calculate eta (the similarity of sample i and j)
eta = 2.0 * svm.kernelMat[alpha_i, alpha_j] - svm.kernelMat[alpha_i, alpha_i] \\
- svm.kernelMat[alpha_j, alpha_j]
if eta >= 0:
return 0
# step 4: update alpha j
svm.alphas[alpha_j] -= svm.train_y[alpha_j] * (error_i - error_j) / eta
# step 5: clip alpha j
if svm.alphas[alpha_j] > H:
svm.alphas[alpha_j] = H
if svm.alphas[alpha_j] < L:
svm.alphas[alpha_j] = L
# step 6: if alpha j not moving enough, just return
if abs(alpha_j_old - svm.alphas[alpha_j]) < 0.00001:
updateError(svm, alpha_j)
return 0
# step 7: update alpha i after optimizing aipha j
svm.alphas[alpha_i] += svm.train_y[alpha_i] * svm.train_y[alpha_j] \\
* (alpha_j_old - svm.alphas[alpha_j])
# step 8: update threshold b
b1 = svm.b - error_i - svm.train_y[alpha_i] * (svm.alphas[alpha_i] - alpha_i_old) \\
* svm.kernelMat[alpha_i, alpha_i] \\
- svm.train_y[alpha_j] * (svm.alphas[alpha_j] - alpha_j_old) \\
* svm.kernelMat[alpha_i, alpha_j]
b2 = svm.b - error_j - svm.train_y[alpha_i] * (svm.alphas[alpha_i] - alpha_i_old) \\
* svm.kernelMat[alpha_i, alpha_j] \\
- svm.train_y[alpha_j] * (svm.alphas[alpha_j] - alpha_j_old) \\
* svm.kernelMat[alpha_j, alpha_j]
if (0 < svm.alphas[alpha_i]) and (svm.alphas[alpha_i] < svm.C):
svm.b = b1
elif (0 < svm.alphas[alpha_j]) and (svm.alphas[alpha_j] < svm.C):
svm.b = b2
else:
svm.b = (b1 + b2) / 2.0
# step 9: update error cache for alpha i, j after optimize alpha i, j and b
updateError(svm, alpha_j)
updateError(svm, alpha_i)
return 1
else:
return 0
# the main training procedure
def trainSVM(train_x, train_y, C, toler, maxIter, kernelOption = ('rbf', 1.0)):
# calculate training time
startTime = time.time()
# init data struct for svm
svm = SVMStruct(mat(train_x), mat(train_y), C, toler, kernelOption)
# start training
entireSet = True
alphaPairsChanged = 0
iterCount = 0
# Iteration termination condition:
# Condition 1: reach max iteration
# Condition 2: no alpha changed after going through all samples,
# in other words, all alpha (samples) fit KKT condition
while (iterCount < maxIter) and ((alphaPairsChanged > 0) or entireSet):
alphaPairsChanged = 0
# update alphas over all training examples
if entireSet:
for i in xrange(svm.numSamples):
alphaPairsChanged += innerLoop(svm, i)
print '---iter:%d entire set, alpha pairs changed:%d' % (iterCount, alphaPairsChanged)
iterCount += 1
# update alphas over examples where alpha is not 0 & not C (not on boundary)
else:
nonBoundAlphasList = nonzero((svm.alphas.A > 0) * (svm.alphas.A < svm.C))[0]
for i in nonBoundAlphasList:
alphaPairsChanged += innerLoop(svm, i)
print '---iter:%d non boundary, alpha pairs changed:%d' % (iterCount, alphaPairsChanged)
iterCount += 1
# alternate loop over all examples and non-boundary examples
if entireSet:
entireSet = False
elif alphaPairsChanged == 0:
entireSet = True
print 'Congratulations, training complete! Took %fs!' % (time.time() - startTime)
return svm
# testing your trained svm model given test set
def testSVM(svm, test_x, test_y):
test_x = mat(test_x)
test_y = mat(test_y)
numTestSamples = test_x.shape[0]
supportVectorsIndex = nonzero(svm.alphas.A > 0)[0]
supportVectors = svm.train_x[supportVectorsIndex]
supportVectorLabels = svm.train_y[supportVectorsIndex]
supportVectorAlphas = svm.alphas[supportVectorsIndex]
matchCount = 0
for i in xrange(numTestSamples):
kernelValue = calcKernelValue(supportVectors, test_x[i, :], svm.kernelOpt)
predict = kernelValue.T * multiply(supportVectorLabels, supportVectorAlphas) + svm.b
if sign(predict) == sign(test_y[i]):
matchCount += 1
accuracy = float(matchCount) / numTestSamples
return accuracy
# show your trained svm model only available with 2-D data
def showSVM(svm):
if svm.train_x.shape[1] != 2:
print "Sorry! I can not draw because the dimension of your data is not 2!"
return 1
# draw all samples
for i in xrange(svm.numSamples):
if svm.train_y[i] == -1:
plt.plot(svm.train_x[i, 0], svm.train_x[i, 1], 'or')
elif svm.train_y[i] == 1:
plt.plot(svm.train_x[i, 0], svm.train_x[i, 1], 'ob')
# mark support vectors
supportVectorsIndex = nonzero(svm.alphas.A > 0)[0]
for i in supportVectorsIndex:
plt.plot(svm.train_x[i, 0], svm.train_x[i, 1], 'oy')
# draw the classify line
w = zeros((2, 1))
for i in supportVectorsIndex:
w += multiply(svm.alphas[i] * svm.train_y[i], svm.train_x[i, :].T)
min_x = min(svm.train_x[:, 0])[0, 0]
max_x = max(svm.train_x[:, 0])[0, 0]
y_min_x = float(-svm.b - w[0] * min_x) / w[1]
y_max_x = float(-svm.b - w[0] * max_x) / w[1]
plt.plot([min_x, max_x], [y_min_x, y_max_x], '-g')
plt.show()
from numpy import *
import SVM
## step 1: load data
print "step 1: load data..."
dataSet = []
labels = []
fileIn = open('E:/Python/Machine Learning in Action/testSet.txt')
for line in fileIn.readlines():
lineArr = line.strip().split('\\t')
dataSet.append([float(lineArr[0]), float(lineArr[1])])
labels.append(float(lineArr[2]))
dataSet = mat(dataSet)
labels = mat(labels).T
train_x = dataSet[0:81, :]
train_y = labels[0:81, :]
test_x = dataSet[80:101, :]
test_y = labels[80:101, :]
## step 2: training...
print "step 2: training..."
C = 0.6
toler = 0.001
maxIter = 50
svmClassifier = SVM.trainSVM(train_x, train_y, C, toler, maxIter, kernelOption = ('linear', 0))
## step 3: testing
print "step 3: testing..."
accuracy = SVM.testSVM(svmClassifier, test_x, test_y)
## step 4: show the result
print "step 4: show the result..."
print 'The classify accuracy is: %.3f%%' % (accuracy * 100)
SVM.showSVM(svmClassifier)
可以去下面的网址,有详细讲解。
参考资料:http://blog.csdn.net/zouxy09/article/details/17292011
支持向量机Python实现(附源码与数据)
之前的文章已经将支持向量机的原理讲解的比较清楚了,今天这篇文章主要是基于Python实现支持向量机,具体的数据集和源代码如下所示(文末附有本文使用的数据集和源代码的下载链接)。

运行环境
Pyhton3 --------------------------------------------------------
numpy --------------------------------------------------------
matplotlib--------------------------------------------------------
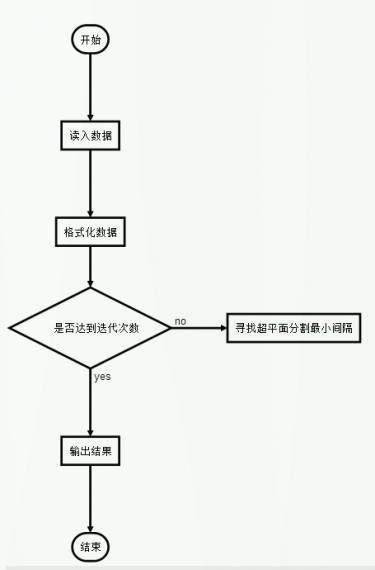
程序的流程图
样本数据集
实现代码
源代码:http://pan.baidu.com/s/1geU9fRP
以上是关于如何用Python实现支持向量机的主要内容,如果未能解决你的问题,请参考以下文章