p-value&q-value&FDR
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了p-value&q-value&FDR相关的知识,希望对你有一定的参考价值。
参考技术A P-value 的计算方式1) P-value 是 (在H0 = true的情况下)得到和试验数据一样极端(或更极端)的统计量的概率. 它不是H1发生的概率. 假定吃苹果的一组和不吃苹果的一组的差异为D, P-value=0.2的意思是, pure randomly (即H0=true)的情况下, 观察到和D一样或比D更大的差异的概率是20%.
2) p-value 的本质是控制PFR (false positive rate), hypothesis test 的目的是make decision. 传统上把小概率事件的概率定义为0.05或0.01, 但不总是这样. 主要根据研究目的. 在一次试验中(注意:是一次试验, 即single test), 0.05 或0.01的cutoff足够严格了(想象一下, 一个口袋有100个球, 95个白的, 5个红的, 只让你摸一次, 你能摸到红的可能性是多大?). 我刚才强调的是single test, 在multiple test中, 通常不用p-value, 而采用更加严格的q-value. 与p-value 不同, q-value 控制的是FDR (false discovery rate).
3)举个例子.假如有一种诊断艾滋病(AIDS)的 试剂 , 试验验证其准确性为99%(每100次诊断就有一次false positive). 对于一个被检测的人(single test) 来说, 这种准确性够了. 但对于医院 (multiple test) 来说, 这种准确性远远不够, 因为每诊断10 000个个体, 就会有100个人被误诊为艾滋病(AIDS).
4)总之, 如果你很care false positive, p-value cutoff 就要很低. 如果你很care false negative (就是"宁可错杀一千, 也不能漏掉一个" 情况), p-value 可以适当放松到 0.1, 0.2 都是可以的.
两种矫正p-value的方法
Bonferroni校正
如果在同一数据集上同时检验n个独立的假设,那么用于每一假设的统计显著水平,应为仅检验一个 假设时的显著水平的1/n。举个例子:如要在同一数据集上检验两个独立的假设,显著水平设为常见的0.05。此时用于检验该两个假设应使用更严格的 0.025。即0.05* (1/2)。该方法是由Carlo Emilio Bonferroni发展的,因此称Bonferroni校正。
Benjamini于1995年提出一种方法,通过控制FDR(False Discovery Rate)来决定P值的域值. 假设你挑选了R个差异表达的基因,其中有S个是真正有差异表达的,另外有V个其实是没有差异表达的,是假阳性的.实践中希望错误比例Q=V/R平均而言不 能超过某个预先设定的值(比如0.05),在统计学上,这也就等价于控制FDR不能超过5%. 根据Benjamini在他的文章中所证明的定理,控制fdr的步骤实际上非常简单。 设总共有m个候选基因,每个基因对应的p值从小到大排列分别是 p(1),p(2),...,p(m),则若想控制fdr不能超过q,则只需找到最大的正整数i,使得 p(i)<= (i*q)/m.然后,挑选对应p(1),p(2),...,p(i)的基因做为差异表达基因,这样就能从统计学上保证fdr不超过q。
> p<-c(0.0003,0.0001,0.02)
> p
[1] 3e-04 1e-04 2e-02
>
> p.adjust(p,method="fdr",length(p))
[1] 0.00045 0.00030 0.02000
>
> p*length(p)/rank(p)
[1] 0.00045 0.00030 0.02000
> length(p)
[1] 3
> rank(p)
[1] 2 1 3
sort(p)
[1] 1e-04 3e-04 2e-02
本文参考 http://www.bbioo.com/lifesciences/40-114656-1.html
线性回归--假设检验(F统计量P-value)
一、F检验解释
F检验(F-test),最常用的别名叫做联合假设检验(英语:joint hypotheses test),此外也称方差比率检验、方差齐性检验。它是一种在原假设(null hypothesis, H0)之下,统计值服从F-分布的检验。
二、线性回归基础:
通常对于一组特征数据和其标记值:(x1,y1),(x2,y2)......(xn,yn)在使用特征值对进行预测时,根据习惯,如果是连续的,则称这种操作或者技术为回归;如果是离散的,则通常称为分类。
线性回归模型可以描述为: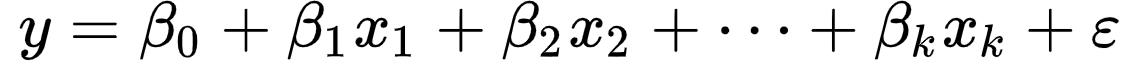 。
。
三、模型假设检验:
H0 :β1 =β2 =...=βk =0。
H1: 至少有一个 βi 不等于 0, i = 1,2,...,k。
Test statistics, F0 =(SSR/k)/ [SSE/(n-k-1)] ∼ F(k,n − k − 1)。
拒绝H0假设的条件α,如果|F|>F(1−α,1,n−k-1)。
四、举例:
根据数值SST = 3650.8,SSR = 1755.9,n=15,k =1,α = 0.05,求统计量F,判断是否可以拒绝0假设。
F0 = (SSR/k)/ [SSE/(n-k-1)] = = [(1755.9) / 1] / [(3650.8 - 1755.9) / (15 - 1- 1)] = 12.04
查表得到Fc = 4.667
F0 > Fc,拒绝假设
p-value < α,拒绝假设
以上是关于p-value&q-value&FDR的主要内容,如果未能解决你的问题,请参考以下文章