SQL语句中count和count的区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL语句中count和count的区别相关的知识,希望对你有一定的参考价值。
SQL语句中count和count没有区别。表示返回匹配指定条件的行数。
SQL COUNT() 语法:
1、SQL COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入),如:SELECT COUNT(column_name) FROM table_name。
2、SQL COUNT(*) 函数返回表中的记录数,如:SELECT COUNT(*) FROM table_name。
3、SQL COUNT(DISTINCT column_name) 函数返回指定列的不同值的数目,如:SELECT COUNT(DISTINCT column_name) FROM table_name。
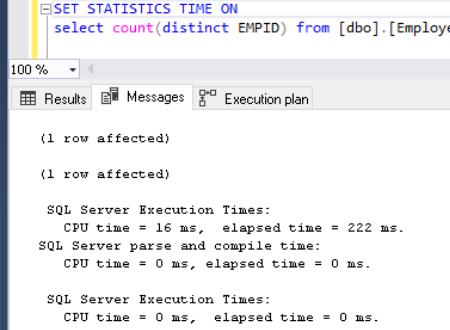
扩展资料:
COUNT和 DISTINCT 经常被合起来使用,目的是找出表格中有多少笔不同的数据 (至于这些数据实际上是什么并不重要)。COUNT(DISTINCT column_name) 语法适用于 ORACLE 和 Microsoft SQL Server,但是无法用于 Microsoft Access。
COUNT(column_name) 语法返回的数目是检索表中的这个字段的非空行数,不统计这个字段值为null的记录。而COUNT(*) 语法返回的数目是包括为null的记录。
参考技术A从SQL语句中count(0)和count(1)用法并无实质上差异。
SQL语句中COUNT函数是返回一个查询的记录数。
COUNT(expr), COUNT(*),一列中的值数(如果将一个列名指定为 expr)或表中的行数或组中的行值(如果指定 *)。COUNT(expr) 忽略空值,但 COUNT(*) 在计数中包含它们 。
SQL语句中COUNT函数括号中可以填写任何实数,能正常使用。
以下代码COUNT函数括号中使用实数>
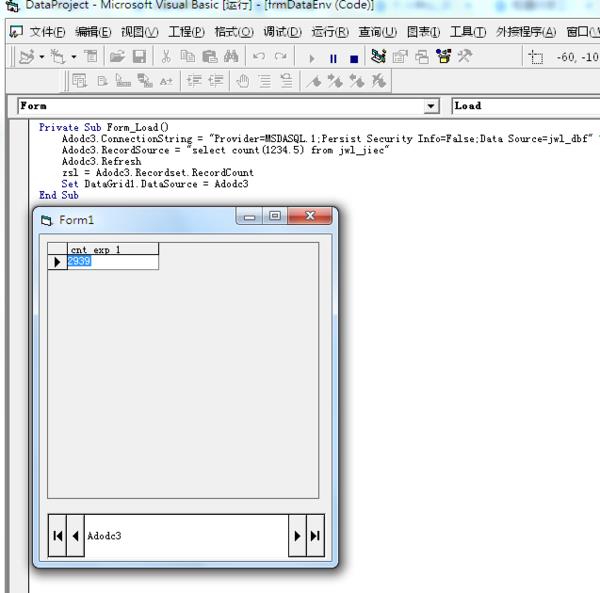
Private Sub Form_Load()
Adodc3.ConnectionString = "Provider=MSDASQL.1;Persist Security Info=False;Data Source=jwl_dbf" '/count(备件代码) as sj
Adodc3.RecordSource = "select count(1234.5) from jwl_jiec"
Adodc3.Refresh
zsl = Adodc3.Recordset.RecordCount
Set DataGrid1.DataSource = Adodc3
End Sub
运行界面如下:
SQL中 count(*)和count的对比,区别
执行效果:
1. count(1) and count(*)
当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了!
从执行计划来看,count(1)和count(*)的效果是一样的。 但是在表做过分析之后,count(1)会比count(*)的用时少些(1w以内数据量),不过差不了多少。
如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。
因为count(*),自动会优化指定到那一个字段。所以没必要去count(1),用count(*),sql会帮你完成优化的 因此:count(1)和count(*)基本没有差别!
2. count(1) and count(字段)
两者的主要区别是
(1) count(1) 会统计表中的所有的记录数,包含字段为null 的记录。
(2) count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
转自:http://www.cnblogs.com/Dhouse/p/6734837.html
count(*) 和 count(1)和count(列名)区别
执行效果上:
count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
执行效率上:
列名为主键,count(列名)会比count(1)快
列名不为主键,count(1)会比count(列名)快
如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*)
如果有主键,则 select count(主键)的执行效率是最优的
如果表只有一个字段,则 select count(*)最优。
转自:http://eeeewwwqq.iteye.com/blog/1972576
实例分析
mysql> create table counttest(name char(1), age char(2));
Query OK, 0 rows affected (0.03 sec)
mysql> insert into counttest values
-> (\'a\', \'14\'),(\'a\', \'15\'), (\'a\', \'15\'),
-> (\'b\', NULL), (\'b\', \'16\'),
-> (\'c\', \'17\'),
-> (\'d\', null),
->(\'e\', \'\');
Query OK, 8 rows affected (0.01 sec)
Records: 8 Duplicates: 0 Warnings: 0
mysql> select * from counttest;
+------+------+
| name | age |
+------+------+
| a | 14 |
| a | 15 |
| a | 15 |
| b | NULL |
| b | 16 |
| c | 17 |
| d | NULL |
| e | |
+------+------+
8 rows in set (0.00 sec)
mysql> select name, count(name), count(1), count(*), count(age), count(distinct(age))
-> from counttest
-> group by name;
+------+-------------+----------+----------+------------+----------------------+
| name | count(name) | count(1) | count(*) | count(age) | count(distinct(age)) |
+------+-------------+----------+----------+------------+----------------------+
| a | 3 | 3 | 3 | 3 | 2 |
| b | 2 | 2 | 2 | 1 | 1 |
| c | 1 | 1 | 1 | 1 | 1 |
| d | 1 | 1 | 1 | 0 | 0 |
| e | 1 | 1 | 1 | 1 | 1 |
+------+-------------+----------+----------+------------+----------------------+
5 rows in set (0.00 sec)
额外参考资料:http://blog.csdn.net/lihuarongaini/article/details/68485838
以上是关于SQL语句中count和count的区别的主要内容,如果未能解决你的问题,请参考以下文章