spark必须要hadoop吗
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark必须要hadoop吗相关的知识,希望对你有一定的参考价值。
Spark的安装分为几种模式,其中一种是本地运行模式,只需要在单节点上解压即可运行,这种模式不需要依赖Hadoop 环境。运行 spark-shell
本地模式运行spark-shell非常简单,只要运行以下命令即可,假设当前目录是$SPARK_HOME
$ MASTER=local $ bin/spark-shell
MASTER=local就是表明当前运行在单机模式。如果一切顺利,将看到下面的提示信息:
Created spark context..
Spark context available as sc.
这表明spark-shell中已经内置了Spark context的变量,名称为sc,我们可以直接使用该变量进行后续的操作。
spark-shell 后面设置 master 参数,可以支持更多的模式,
我们在sparkshell中运行一下最简单的例子,统计在README.md中含有Spark的行数有多少,在spark-shell中输入如下代码:
scala>sc.textFile("README.md").filter(_.contains("Spark")).count
如果你觉得输出的日志太多,你可以从模板文件创建 conf/log4j.properties :
$ mv conf/log4j.properties.template conf/log4j.properties
然后修改日志输出级别为WARN:
log4j.rootCategory=WARN, console
如果你设置的 log4j 日志等级为 INFO,则你可以看到这样的一行日志 INFO SparkUI: Started SparkUI at http://10.9.4.165:4040,意思是 Spark 启动了一个 web 服务器,你可以通过浏览器访问http://10.9.4.165:4040来查看 Spark 的任务运行状态等信息。
pyspark
运行 bin/pyspark 的输出为:
$ bin/pyspark
Python 2.7.6 (default, Sep 9 2014, 15:04:36)
[GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.39)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Picked up JAVA_TOOL_OPTIONS: -Dfile.encoding=UTF-8
15/03/30 15:19:07 WARN Utils: Your hostname, june-mac resolves to a loopback address: 127.0.0.1; using 10.9.4.165 instead (on interface utun0)
15/03/30 15:19:07 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
15/03/30 15:19:07 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ / __/ _/
/__ / .__/\_,_/_/ /_/\_\ version 1.3.0
/_/
Using Python version 2.7.6 (default, Sep 9 2014 15:04:36)
SparkContext available as sc, HiveContext available as sqlCtx.
你也可以使用 IPython 来运行 Spark:
IPYTHON=1 ./bin/pyspark
如果要使用 IPython NoteBook,则运行:
IPYTHON_OPTS="notebook" ./bin/pyspark
从日志可以看到,不管是 bin/pyspark 还是 bin/spark-shell,他们都有两个内置的变量:sc 和 sqlCtx。
SparkContext available as sc, HiveContext available as sqlCtx
sc 代表着 Spark 的上下文,通过该变量可以执行 Spark 的一些操作,而 sqlCtx 代表着 HiveContext 的上下文。
spark-submit
在Spark1.0之后提供了一个统一的脚本spark-submit来提交任务。
对于 python 程序,我们可以直接使用 spark-submit:
$ mkdir -p /usr/lib/spark/examples/python$ tar zxvf /usr/lib/spark/lib/python.tar.gz -C /usr/lib/spark/examples/python$ ./bin/spark-submit examples/python/pi.py 10
对于 Java 程序,我们需要先编译代码然后打包运行:
$ spark-submit --class "SimpleApp" --master local[4] simple-project-1.0.jar
Spark 运行模式
Spark 的运行模式多种多样、灵活多变,部署在单机上时,既可以用本地模式运行,也可以用伪分布式模式运行,而当以分布式集群的方式部署时,也有众多的运行模式可以供选择,这取决于集群的实际情况,底层的资源调度既可以依赖于外部的资源调度框架,也可以使用 Spark 内建的 Standalone 模式。对于外部资源调度框架的支持,目前的实现包括相对稳定的 Mesos 模式,以及还在持续开发更新中的 Hadoop YARN 模式。
在实际应用中,Spark 应用程序的运行模式取决于传递给 SparkContext 的 MASTER 环境变量的值,个别模式还需要依赖辅助的程序接口来配合使用,目前所支持的 MASTER 环境变量由特定的字符串或 URL 所组成。例如:
Local[N]:本地模式,使用 N 个线程。
Local Cluster[Worker,core,Memory]:伪分布式模式,可以配置所需要启动的虚拟工作节点的数量,以及每个工作节点所管理的 CPU 数量和内存尺寸。
Spark://hostname:port:Standalone 模式,需要部署 Spark 到相关节点,URL 为 Spark Master 主机地址和端口。
Mesos://hostname:port:Mesos 模式,需要部署 Spark 和 Mesos 到相关节点,URL 为 Mesos 主机地址和端口。
YARN standalone/Yarn cluster:YARN 模式一,主程序逻辑和任务都运行在 YARN 集群中。
YARN client:YARN 模式二,主程序逻辑运行在本地,具体任务运行在 YARN 集群中。
运行 Spark
通过命令行运行 Spark ,有两种方式:bin/pyspark 和 bin/spark-shell。
运行 bin/spark-shell 输出的日志如下:
$ ./bin/spark-shell --master local
你可以从模板文件创建 conf/log4j.properties ,然后修改日志输出级别:
mv conf/log4j.properties.template conf/log4j.properties
修改 log4j.rootCategory 的等级为输出 WARN 级别的日志:
log4j.rootCategory=WARN, console
如果你设置的 log4j 日志等级为 INFO,则你可以看到这样的一行日志 INFO SparkUI: Started SparkUI at http://10.9.4.165:4040 ,意思是 Spark 启动了一个 web 服务器,你可以通过浏览器访问 http://10.9.4.165:4040 来查看 Spark 的任务运行状态。
从日志可以看到,不管是 bin/pyspark 还是 bin/spark-shell,他们都有两个内置的变量:sc 和 sqlCtx。
SparkContext available as sc, HiveContext available as sqlCtx
sc 代表着 Spark 的上下文,通过该变量可以执行 Spark 的一些操作,而 sqlCtx 代表着 HiveContext 的上下文。 参考技术A 本质上spark跟mapreduce一样都是计算框架
apache spark是通过hadoop yarn管理的,需要运行在hadoop集群上
网络编程-简单实现Hadoop RPC
一、我们应该如何去阅读一个大数据开源框架的源码
1. 阅读源码的思路
1.1 掌握其网络通信架构
我们应该都知道在大数据领域中,包含了很多大数据框架,例如Spark,Hadoop,Kafka,Zookeeper,Flink等,在这些组件当中,他们都是分布式的,我们想要阅读他们源码的时候,必须要明白分布式系统之间,他们是如何交互的,例如Spark之前采用的是akka,现在采用的Netty,kafka采用的是NIO等,也就不一一列举了,我们阅读源码的时候,如果不了解他们内部是如何通信的,那么我们根本无法知道他们的内部是如何工作的,所以掌握其通信架构是必须的,也是必然的
1.2 场景驱动
为什么要说场景驱动这个问题呢,因为我们在阅读一个开源框架源码的时候,例如Hadoop源码几百万行代码,我们一个个类去看的话,我相信,看不了一会,你就放弃了,根本不知道在看一些什么东西,但是场景驱动的方式可以帮助我们更加有效的去阅读,因为我们只关注其中的某一点,例如我就看NameNode启动的流程,DataNode的注册和心跳,这样我们就可以抛弃不看的,不重要的,只看我们需要的地方,这样我们既有兴趣,又能坚持的下来
二、Hadoop RPC
RPC是什么?
RPC(Remote Procedure Call)远程过程调用,用人话说,就是我们编写分布式系统的时候,可以本地调用远端的方法,这样我们编写代码的时候就和编写单机程序没有什么区别.也就是说客户端调用服务端的方法,方法的执行在服务端
1. 环境准备
Maven依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.0</version>
</dependency>
2. 代码实现
2.1 协议
/**
* Copyright (c) 2019 bigdata ALL Rights Reserved
* Project: learning
* Package: com.bigdata.hdfs.app
* Version: 1.0
*
* @author qingzhi.wu
* @date 2020/6/14 20:21
*/
public interface ClientProtocol {
long versionID = 1234;
void makeDir(String path);
}
2.2 服务端代码
/**
* Copyright (c) 2019 bigdata ALL Rights Reserved
* Project: learning
* Package: com.bigdata.hdfs.app
* Version: 1.0
*
* @author qingzhi.wu
* @date 2020/6/14 20:22
*/
public class NameNodeRpcServer implements ClientProtocol {
public static void main(String[] args) throws IOException {
RPC.Server server = new RPC.Builder(new Configuration())
.setBindAddress("localhost")
.setPort(9999)
.setProtocol(ClientProtocol.class)
.setInstance(new NameNodeRpcServer())
.build();
System.out.println("服务端启动");
server.start();
}
public void makeDir(String path) {
System.out.println("服务端:"+path);
}
}
2.3 客户端
/**
* Copyright (c) 2019 bigdata ALL Rights Reserved Project: learning Package: com.bigdata.hdfs.app
* Version: 1.0
*
* @author qingzhi.wu
* @date 2020/6/14 20:26
*/
public class DFSClient {
public static void main(String[] args) throws IOException {
ClientProtocol namenode =
RPC.getProxy(
ClientProtocol.class,
1234L,
new InetSocketAddress("localhost", 9999),
new Configuration());
namenode.makeDir("/usr/add");
System.out.println("已经向服务端发送请求");
}
}
2.4 测试运行
2.4.1 运行服务端
控制台打印的日志
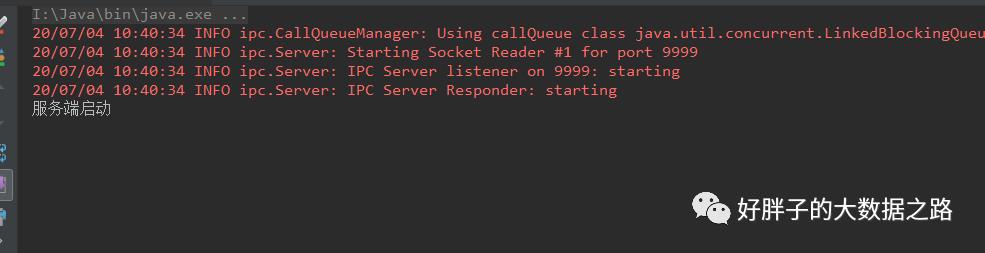
2.4.2 运行客户端
客户端控制台打印的日志
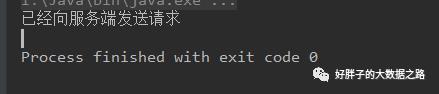
服务端控制台打印的日志

3. Hadoop RPC 总结
不同进程间的调用,客户端调用服务端的方法,方法的执行是在服务器
协议是什么呢,其实就是一个接口,当然这个接口里面必须有versionID字段(避免版本问题)
服务端是真正实现协议的一方
如何创建一个服务端
RPC.Server server = new RPC.Builder(new Configuration())
.setBindAddress("localhost")
.setPort(9999)
.setProtocol(ClientProtocol.class)
.setInstance(new NameNodeRpcServer())
.build();
客户端如何调用远端的方法
ClientProtocol namenode =
RPC.getProxy(
ClientProtocol.class,
1234L,
new InetSocketAddress("localhost", 9999),
new Configuration());
namenode.makeDir("/usr/add");
三、我们能不能自己写一个呢?
当然可以啦,我们是不是已经记住知道Rpc 就是客户端调用服务端的方法,方法的执行在服务端。
那么我们就可以根据这个来进行编写了呢。
个人技术实力有限,就是写着玩玩,勿喷!
ClientProtocol
package com.bigdata.tcp.hadooprpc.common;
/**
* Copyright (c) 2020 bigdata ALL Rights Reserved
* Project: learning
* Package: com.bigdata.tcp.hadooprpc.common
* Version: 1.0
*
* @author qingzhi.wu 2021/2/7 14:25
*/
public interface ClientProtocol extends Protocol{
void makeDir(String path);
}
Protocol
package com.bigdata.tcp.hadooprpc.common;
/**
* Copyright (c) 2020 bigdata ALL Rights Reserved
* Project: learning
* Package: com.bigdata.tcp.hadooprpc.common
* Version: 1.0
*
* @author qingzhi.wu 2021/2/7 14:33
*/
public interface Protocol {
}
Client
package com.bigdata.tcp.hadooprpc;
import com.bigdata.tcp.hadooprpc.common.ClientProtocol;
import com.bigdata.tcp.hadooprpc.server.RPC;
/**
* Copyright (c) 2020 bigdata ALL Rights Reserved
* Project: learning
* Package: com.bigdata.tcp.hadooprpc
* Version: 1.0
*
* @author qingzhi.wu 2021/2/7 14:27
*/
public class Client {
public static void main(String[] args) {
ClientProtocol clientProtocol = (ClientProtocol)
RPC.getProxy(ClientProtocol.class, "127.0.0.1", 9999);
clientProtocol.makeDir("/data");
}
}
ClientProtocolServiceProxy
package com.bigdata.tcp.hadooprpc;
import com.bigdata.tcp.hadooprpc.common.ClientProtocol;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.io.OutputStream;
import java.net.Socket;
/**
* Copyright (c) 2020 bigdata ALL Rights Reserved
* Project: learning
* Package: com.bigdata.tcp.hadooprpc
* Version: 1.0
*
* @author qingzhi.wu 2021/2/7 15:22
*/
public class ClientProtocolServiceProxy implements ClientProtocol {
private Socket socket = null ;
public ClientProtocolServiceProxy(String ip,int port){
try {
socket = new Socket(ip,port);
System.out.println(socket);
} catch (IOException e) {
e.printStackTrace();
}
}
public void makeDir(String path) {
OutputStream outputStream = null;
ObjectOutputStream oos = null;
try {
outputStream = socket.getOutputStream();
oos = new ObjectOutputStream(outputStream);
Message message = new Message();
message.setMethodName("makeDir");
message.setParam(path);
message.setClassName(ClientProtocol.class.getName());
oos.writeObject(message);
outputStream.close();
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Message
package com.bigdata.tcp.hadooprpc;
import java.io.Serializable;
/**
* Copyright (c) 2020 bigdata ALL Rights Reserved
* Project: learning
* Package: com.bigdata.tcp.hadooprpc
* Version: 1.0
*
* @author qingzhi.wu 2021/2/7 15:08
*/
public class Message implements Serializable {
private String className;
private String methodName;
private String param;
public Message() {
}
public Message(String className, String methodName, String param) {
this.className = className;
this.methodName = methodName;
this.param = param;
}
public String getClassName() {
return className;
}
public void setClassName(String className) {
this.className = className;
}
public String getMethodName() {
return methodName;
}
public void setMethodName(String methodName) {
this.methodName = methodName;
}
public String getParam() {
return param;
}
public void setParam(String param) {
this.param = param;
}
}
NamenodeRpcServer
package com.bigdata.tcp.hadooprpc;
import com.bigdata.tcp.hadooprpc.common.ClientProtocol;
import com.bigdata.tcp.hadooprpc.server.RPC;
/**
* Copyright (c) 2020 bigdata ALL Rights Reserved
* Project: learning
* Package: com.bigdata.tcp.hadooprpc
* Version: 1.0
*
* @author qingzhi.wu 2021/2/7 14:25
*/
public class NameNodeRpcServer implements ClientProtocol {
public static void main(String[] args) throws Exception {
RPC.Server server = new RPC.Builder().setBindAddress("127.0.0.1")
.setPort(9999)
.setProtocolClazz(ClientProtocol.class)
.setInstance(new NameNodeRpcServer()).build();
System.out.println("服务端启动");
server.start();
}
public void makeDir(String path) {
System.out.println(path);
}
}
RPC
package com.bigdata.tcp.hadooprpc.server;
import com.bigdata.tcp.hadooprpc.ClientProtocolServiceProxy;
import com.bigdata.tcp.hadooprpc.Message;
import com.bigdata.tcp.hadooprpc.common.ClientProtocol;
import com.bigdata.tcp.hadooprpc.common.Protocol;
import java.io.InputStream;
import java.io.ObjectInputStream;
import java.lang.reflect.Method;
import java.net.ServerSocket;
import java.net.Socket;
/**
* Copyright (c) 2020 bigdata ALL Rights Reserved
* Project: learning
* Package: com.bigdata.tcp.hadooprpc.server
* Version: 1.0
*
* @author qingzhi.wu 2021/2/7 14:30
*/
public class RPC {
public static Object getProxy(Class clazz,String ip,int port){
System.out.println(clazz);
System.out.println(ClientProtocol.class);
if (clazz.equals(ClientProtocol.class)){
return new ClientProtocolServiceProxy(ip,port);
}
return null;
}
public static class Server {
private String bindAddress;
private int port;
private Class protocolClazz;
private ClientProtocol instance;
private ServerSocket serverSocket;
private Server(Builder builder){
this.bindAddress = builder.bindAddress;
this.port = builder.port;
this.protocolClazz = builder.protocolClazz;
this.instance = (ClientProtocol) builder.instance;
}
public void start() throws Exception{
System.out.println(port);
serverSocket = new ServerSocket(port);
while (true){
Socket accept = serverSocket.accept();
InputStream inputStream = accept.getInputStream();
ObjectInputStream object = new ObjectInputStream(inputStream);
Message message = (Message)object.readObject();
System.out.println(message);
String className = message.getClassName();
//假装匹配一下
System.out.println(className);
System.out.println(protocolClazz.getName());
Class aClass = Class.forName(className);
if(instance instanceof ClientProtocol){
Method method = protocolClazz.getMethod(message.getMethodName(), String.class);
method.invoke(instance,message.getParam());
}
object.close();
inputStream.close();
}
}
}
public static class Builder{
private String bindAddress;
private int port;
private Class protocolClazz;
private Protocol instance;
public Builder setBindAddress(String addr){
this.bindAddress = addr;
return this;
}
public Builder setPort(int port) {
this.port = port;
return this;
}
public Builder setProtocolClazz(Class protocolClazz) {
this.protocolClazz = protocolClazz;
return this;
}
public Builder setInstance(ClientProtocol instance) {
this.instance = instance;
return this;
}
public Server build(){
return new Server(this);
}
}
}
谢谢大家的观看!
以上是关于spark必须要hadoop吗的主要内容,如果未能解决你的问题,请参考以下文章