《Go语言精进之路,从新手到高手的编程思想方法和技巧1》读书笔记和分享
Posted 尚墨1111
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Go语言精进之路,从新手到高手的编程思想方法和技巧1》读书笔记和分享相关的知识,希望对你有一定的参考价值。
Go语言精进之路,从新手到高手的编程思想、方法和技巧
读书分享
1 本书定位
新手——>高手,深入学习层面
-
编程思维:Go的设计哲学,用Go思维写Go
-
实践技巧:改善Go代码质量(Go语言标准库和优秀Go开源库的项目结构、代码风格、实现、接口、并发、错误处理等)
2 本书内容总览
1、熟知Go的一切
- go的诞生和演进、语言版本
- go的设计哲学
- go的原生编程思维
2、项目结构、代码风格与标识符命名
- go典型项目结构
- 格式化源码gofmt
- go命名惯例
3、声明、类型、语句与控制结构
- 变量声明形式、无类型常量、iota实现枚举常量、零值可用的类型、复合字面值作为初值构造器
- 切片、map、strings实现原理及使用
- 包导入、表达式求值顺序、代码块和作用域
- 控制语句惯用法
4、函数与方法
- init函数、函数、defer
- 方法、接口的方法
- 变长参数
5、接口
- 接口变量的内部表示
- 定义小接口
- 避免使用空接口作为参数类型
- 使用接口解耦
6、并发编程
- 优先考虑并发设计、了解goroutinue调度原理、go并发模型
- channel、sync、stomic包
7、错误处理
- 常见策略
- if err!=nil
- panic
3 选择本书的原因
需求:
- 终于,代码可以工作了,一看代码烂的像坨屎
- 实际上线使用,又发现一堆新的bug,逻辑漏洞、没有涵盖的情况、代码bug,不断迭代修复…
总结:
- 代码规范性、简洁性
- 整体结构,go文件放在哪个文件夹下面才能很好的保证
- 代码实现,优雅且高效,简单且易读
- 代码复用,什么时候需要抽象出新的方法,使代码不会臃肿冗余,抽象出的代码应该放在哪里
- 代码解耦,涉及的设计模式、代码的组合、代码的抽象
4 小收获分享
第7-12条 真的不知道咋命名
Go标准库代码:简单且一致,利用上下文辅助命名
- 能用一个单词命名就不要使用单词组合
- 能用单个字母表示,就不用完整的字母
strings.Reader() //[good]
strings.StringReader() //[bad]
变量、类型、函数、方法
- 循环、条件变量多用单个字母(保持一致性)
- 方法、参数、返回值多以单个单词
- 函数、类型多以多个单词
- 声明与使用越近越好
userSlice []*User [bad] // 变量名字不要带类型信息
users []*User [good]
for i,v := range s // 利用上下文,让短名字携带更多信息
t := time.Now()
b := make([]byte,10)
声明一致性,声明聚类、就近原则
var(
a = 1
f = float32(3.14) // VS f float32 = 3.14
)
零值可用
var temp []int
temp = append(temp,2)// 切片零值可用
var m map[string]int
m = make(map[string]int,0) // map零值不可用
推荐使用field:value 的复合字面值进行结构体、map构造
p := &pipe
wrCh:xxxx,
rdCh:xxx,
第13-19条 能用——怎么用更好
切片:尽量使用cap参数创建切片,动态扩容
var num []int
num := make([]int,23)
map:判断key是否存在 comma ok
if v, ok := Task[username]; !ok
//
string的构造方法
s + "hello",最直观
fmt.Sprintf("%s%s",s,"hello"),性能最差,可构造多种不同变量构建字符串
strings.join(s,"hello"),平均性能佳
strings.Builder(),能预估最终字符串长度时效率最高
bytes.Buffer(bytes),类似join
turn to 第19条
turn to 17条
5 个人总结
- 每一条的内容都可以深挖,要真的掌握,需要更多的实践和思考
- 多熟悉go的各种工具包,能知道、需要的时候可以用、可以知道更好的方法
- 阅读源码:加深使用理解,参考代码风格、实现方式
- 深挖:
- 基本语法的灵活运用、函数、方法、接口
- 集合类深入理解:数组、切片、map
- 高并发:goroutine、channel、sync、automic
- 内存管理
第一部分 熟知 Go 语言的一切
第 1 条 了解 Go 语言的诞生与演进
一只由 Rob Pike 的夫人 Renee French 设计的地鼠,从此地鼠成为世界各地 Go 程序员的象征。
第 2 条 选择适当的 Go 语言版本
2018 年 8 月 25 日,Go 1.11 版本发布。Go 1.11 是 Russ Cox 在 GopherCon 2017 大会上发表题为 “Toward Go 2” 的演讲之后的第一个 Go 版本,它与 Go 1.5 版本一样也是具有里程碑意义的版本,因为它引入了新的 Go 包管理机制:Go module。
第 3 条 理解 Go 语言的设计哲学
3.1 追求简单,少即是多
Go 设计者推崇 “最小方式” 思维,即一件事情仅有一种方式或数量尽可能少的方式去完成
3.2 偏好组合,正交解耦
Go 语言遵从的设计哲学也是组合。Go 语言提供的最为直观的组合的语法元素是类型嵌入,实现功能的垂直扩展。
“高内聚、低耦合” 是软件开发领域亘古不变的管理复杂性的准则。Go 在语言设计层面也将这一准则发挥到极致。Go 崇尚通过组合的方式将正交的语法元素组织在一起来形成应用程序骨架,接口就是在这一哲学下诞生的语言精华。
3.3 原生并发,轻量高效
goroutine 各自执行特定的工作,通过 channel+select 将 goroutine 组合连接起来。goroutine 调度器进行CPU调度,并发的存在鼓励程序员在程序设计时进行独立计算的分解,而对并发的原生支持让 Go 语言更适应现代计算环境。
3.4 面向工程,“自带电池”
Go 在标准库中提供了各类高质量且性能优良的功能包,其中的 net/http、crypto/xx、encoding/xx 等包充分迎合了云原生时代关于 API/RPC Web 服务的构建需求。 gofmt 统一了 Go 语言的编码风格。
第 4 条 使用 Go 语言原生编程思维来写 Go 代码
命名使用单字母,特定场景能理解,例如循环里的 i,遍历 map 的 k,v
要善用并发去解决问题,利用并发解决问题的思维需加强
func Generate(ch chan<- int)
for i := 2; ; i++
ch <- i
func Filter(in <-chan int, out chan<- int, prime int)
for
i := <-in
if i%prime != 0
out <- i
fmt.Printf("prime=%d,i=%d\\n", prime, i)
println("Filter over")
func main()
ch := make(chan int)
go Generate(ch)
for i := 0; i < 10; i++
prime := <-ch
print(prime, "\\n")
ch1 := make(chan int)
go Filter(ch, ch1, prime)
ch = ch1
第二部分 项目结构、代码风格与标识符命名
第 5 条 使用得到公认且广泛使用的项目结构,Go 语言典型项目结构
cmd 目录:存放项目要构建的可执行文件对应的 main 包的源文件。
pkg 目录:存放项目自身要使用并且同样也是可执行文件对应 main 包要依赖的库文件。
Makefile:这里的 Makefile 是项目构建工具所用脚本的 “代表”,它可以代表任何第三方构建工具所用的脚本。
go.mod 和 go.sum:Go 语言包依赖管理使用的配置文件。
vendor 目录(可选):vendor 是 Go 1.5 版本引入的用于在项目本地缓存特定版本依赖包的机制。
第 6 条 提交前使用 gofmt 格式化源码
gofmt、 goimports、 将 gofmt/goimports 与 IDE 或编辑器工具集成
第 7 条 使用 Go 命名惯例对标识符进行命名
Go 命名惯例选择了简洁命名 + 注释辅助解释的方式,而不是一个长长的名字。
- 对包导出标识符命名时,在名字中不要再包含包名,比如:strings.Reader VS strings.StringReader
- 变量名字中不要带有类型信息
- 变量声明与使用之间的距离越近越好,或者在第一次使用变量之前声明该变量。
- 利用上下文环境,让最短的名字携带足够多的信息,t代表time、b代表byte、i代表index,v代表value
- 常量使用多单词组合,如defaultMaxMemory
- 函数、类型多以多单词的复合词进行命名。
- 接口,Go 语言的惯例是用 “方法名 + er” 命名。比如:Reader、Writer
第三部分 声明、类型、语句与控制结构
第 8 条 使用一致的变量声明形式
要想做好代码中变量声明的一致性,需要明确要声明的变量是包级变量还是局部变量、是否要延迟初始化、是否接受默认类型、是否为分支控制变量,并结合聚类和就近原则。
显式声明推荐方式
- var a = int32 (17)
- var f = float32 (3.14)
第 9 条 使用无类型常量简化代码
Go 的无类型常量恰恰就拥有像字面值这样的特性,该特性使得无类型常量在参与变量赋值和计算过程时无须显式类型转换,从而达到简化代码的目的
第 10 条 使用 iota 实现枚举常量
iota 是 Go 语言的一个预定义标识符,它表示的是 const 声明块(包括单行声明)中每个常量所处位置在块中的偏移值(从零开始)。
- 位于同一行的 iota 即便出现多次,其值也是一样的
- 如果要略过 某个iota值,_ = itota,操作
第 11 条 尽量定义零值可用的类型
零值可用,如切片

第 12 条 使用复合字面值作为初值构造器
Go 推荐使用 field:value 的复合字面值形式对 struct 类型变量进行值构造


第13条 了解切片实现原理并高效使用
切片的底层结构是数组,相当于数组的描述符(array、len、cap)
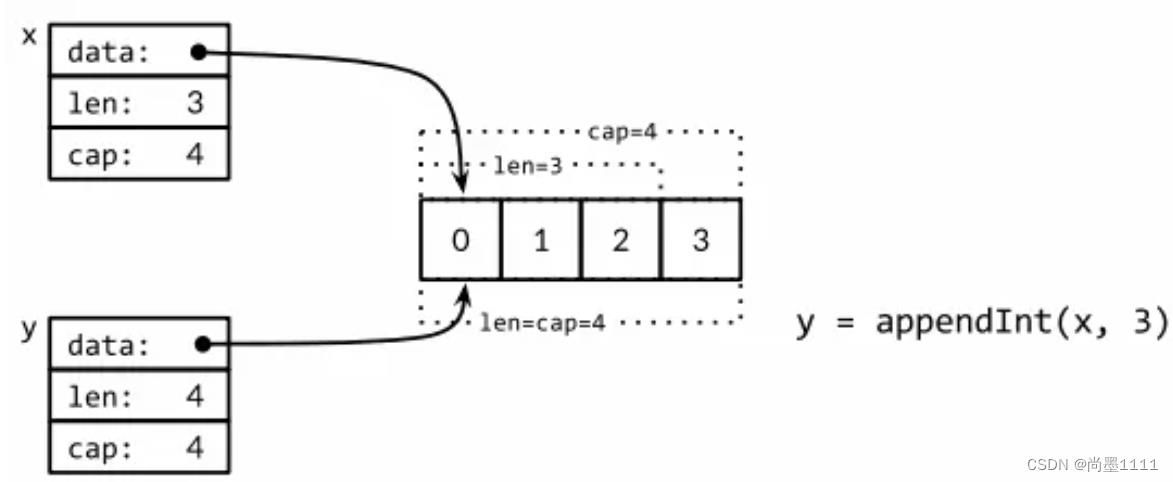
初始零值,零值可用
createData := make(map[string]interface) var verifyTemp *entity.ConvergeTaskStatics动态扩容:
defects := make([]model.Defect, 0) defects = append(defects, defect) snapshots := make([]string, 0) snapshots = append(snapshots, path)
- 注意:一旦切片cap触碰数组的上界,再对切片进行append操作,切片会创建新的数组与原数组解除绑定
- 如果能预估出切片底层数组元素数量,尽量使用cap参数创建切片,减少动态扩容带来的性能消耗
第14条 了解map实现原理并高效使用
- 不支持零值可用,未赋值未nil,使用报panic
var m map[string]int m["key"] = 1 //panic:assignment to entry in nil map
- 增删查改的操作,遍历无序
- 注意查key不存在会默认返回零值,此时无法确定对应的key是否存在,使用comma ok用法读取map中的值
if v, ok := TaskStatics[staticInVer.UserName]; !ok //
- map的内部实现与java类似,map扩容,非线程安全不支持并发写
- 同样为减少频繁扩容带来的损耗,建议使用cap参数创建map
第15条 了解strings实现原理并高效使用
- string只读,进行切片之后会创建新的底层存储,切片修改对原string没有影响
- 标准库:strings、strconv
- 内部表示,底层的描述符
type stringStruct struct str unsafe.Pointer len int
- string的构造方法
s + "hello",最直观 fmt.Sprintf("%s%s",s,"hello"),性能最差,可构造多种不同变量构建字符串 strings.join(s,"hello"),平均性能佳 strings.Builder(),能预估最终字符串长度时效率最高 bytes.Buffer(bytes),类似join
第16条 go语言的包导入
import后的部分是路径
编译过程使用的是编译单元所依赖的包源码
包源码搜索路径:基本搜索路径GOROOT/GOPATH/module-aware+包导入路径import
第17条 理解GO语言表达式的求值顺序
n0,n1 = 1,2
n0,n1 = n0+n1,n0
包级变量初始化按照变量声明顺序进行,每一轮寻找ready for initialization
var ( a = c + b b = f() _ = f() c = f() d = 3 ) func f() int d++ return d func main() fmt.Println(a,b,c,d)
1、第一阶段:等号两端表达式求值,上述问题中,只有右端有n0+n1和n0两个表达式,因此直接将值带入,得到求值结果。求值后,语句可以看成:n0, n1 = 3, 1;
2、第二阶段:赋值。n0 =3, n1 = 1
第18条 理解Go语言代码块和作用域
第19条 了解Go语言控制语句惯用法及使用注意事项
- 使用 if 控制语句时应遵循“快乐路径”原则,“快乐路径”即成功逻辑的代码执行路径。原则要求:
- 当出现错误时,快速返回;
- 成功逻辑不要嵌入 if-else 语句中;
- “快乐路径”的执行逻辑在代码布局上始终靠左,这样读者可以一眼看到该函数的正常逻辑流程;
- “快乐路径”的返回值一般在函数最后一行。
扁平,可读性强 func doSomething() error if 错误逻辑1// 出现错误时快速返回 return err 成功逻辑2// 成功逻辑不要嵌入 if-else 语句中; if 错误逻辑2 return err 成功逻辑2 嵌套,可读性不佳 func doSomething() error if 成功逻辑1 if 成功逻辑2 return err else // 错误逻辑1 else // 错误逻辑2
- for range的坑
迭代变量在 for range 的每次循环中都会被重用,参与循环的是数组的副本
var m = [...]int1, 2, 3, 4, 5 for i, v := range m' // 这样使用 for i, v := range &m
第四部分 函数与方法
第20条 在init函数中检查包级变量的初始状态
导包遵循深度优先,把所有依赖的加载
init函数做包级数据的初始化和初始状态检查工作
第21条 让自己习惯于函数是一等公民
函数可以像普通整型值一样被创建和使用
第22条 使用defer让函数更简洁、更健壮
待释放的资源个数很多,defer让资源释放优雅且不易出错
第23条 理解方法的本质以选择正确的receiver类型
绑定方法,建议绑定指针类型
func(reveiver T\\*T)MethodName(参数列表)(返回值列表)
第24条 方法集合决定接口实现
隐式的接口实现方式
- T 的方法集合 = reveiver为T
- *T 的方法集合 = receiver为 T 和 *T的方法
// CheckCollectTask 检查采集上传数据 func (a *appCollectTaskSrvStruct) CheckCollectTask()接口嵌接口,实现复杂功能的组合,当有重名接口的时候就近原则,也可以使用别名
第25条 了解变长参数函数的妙用
现状:很少使用变长参数设计实现函数或方法
func fmt.Println(a ...interface) (n int, err error) func append(slice []Type,elems ...Type) []Type
- 利用变长参数实现函数重载
- 实现功能选项(现在多用的option封装参数)
第五部分 接口
第26条 了解接口类型变量的内部表示
type iface struct //有方法的接口类型 tab *itab data unsafe.Pointer type eface struct // 无方法的接口类型 _type *_type // 存储接口的信息 data unsafe.Pointer空接口类型变量:只有在 _type 和 data 所指数据内容一致的情况下,两个空接口类型变量之间才能画等号
第27条 尽量定义小接口
接口越小,抽象程度越高,越易于实现、复用,越偏向业务层,抽象难度越高
type Reader interface Read(...)先抽象出接口,再拆分小接口
第28条 尽量避免使用空接口作为函数参数类型
空接口没有任何入参的信息,避开类型检查,导致运行时才发现问题
第29条 使用接口作为程序水平组合的连接点
深入理解接口的组合逻辑,使用垂直组合、水平组合
第30条 使用接口提高代码的可测试性
抽取接口,让接口称为代码与单元测试的桥梁(TDD)
第六部分 并发编程
第31条 优先考虑并发设计
并发关乎结构(生产线条数),并行关乎执行(执行人数)
进行代码执行单元的分解,代码=代码片段的组合,每个片段并发执行
第32条 了解goroutine的调度原理
G-P-M调度模型
- G保存Goroutine的运行堆栈,即并发任务状态。G并非执行体,每个G需要绑定到P才能被调度执行。
- 对G来说,P相当于CPU核,G只有绑定到P(在P的local runq中)才能被调度。对M来说,P提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)
- M:OS线程抽象,负责调度任务,和某个P绑定,从P中不断取出G,切换堆栈并执行
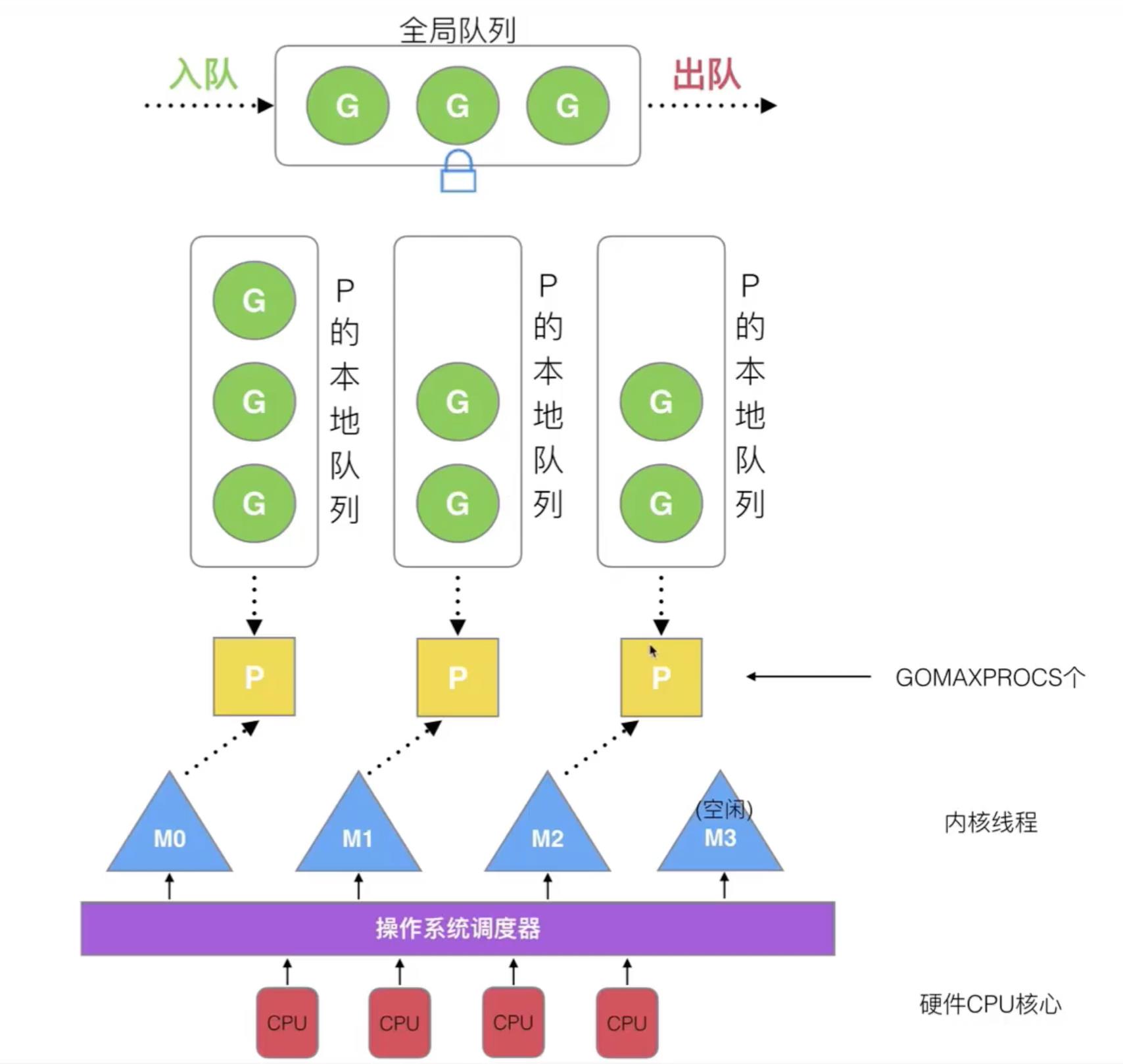
第33条 掌握Go并发模型和常见并发模型
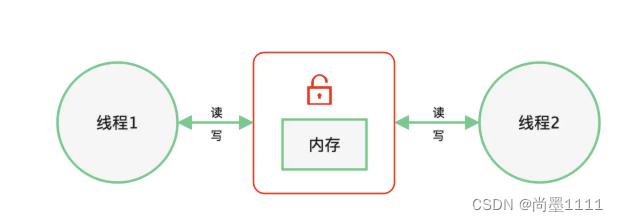
- 基于共享内存
- 基于通信顺序进程模型 CSP
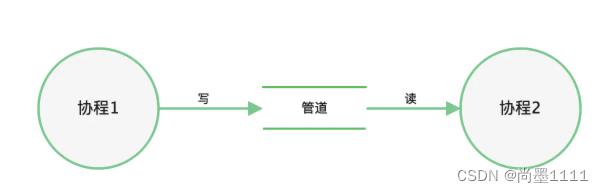
- goroutine,对应P,封装数据的处理逻辑,作为基本执行单元
- channel,用于goroutine的通信和同步
- select,协调多路channel
第34条 了解channel的妙用
- channel + select
- 无缓冲channel在信号传递、替代锁同步的应用
- 有缓冲channel在消息对列、计数信号的应用
第35条 了解sync包的正确用法
第36条 使用atomic包实现伸缩性更好的并发读取
第七部分 错误处理
第37条 了解错误处理的四种策略
- 构造错误值:error.New,fmt.Errorf
DatabaseError error = errors.New("数据库错误,请联系开发人员") ServerError error = errors.New("服务器错误,请联系开发人员")
- 透明错误处理策略:只要一发生错误就进入错误处理逻辑,降低错误与错误处理之间的耦合
err := doSomething() if err != nil return err
- 错误哨兵策略,swtich + 自定义err 判断选择路径
- 错误值类型检视策略,获取更多的错误值上下文信息
err.(type) errors.As(err,&错误类型) // 判断两个err是否一致 errors.Is(err,错误类型)
- 错误行为特征检视策略,公共接口定义的错误信息 net.Error
type Error interface error Timeout() bool Temporary() bool
第38条 尽量优化反复出现的 if err != nil
显示错误处理是go的特点
- 改善视觉呈现
- 减少重复次数
- 重构
- check/handle机制,另外封装成函数
- 使用内置error
第39条 不要使用panic进行正常的错误处理
尽可能少使用panic
典型应用
- 断言角色,提示潜在bug,
switch 表达式 case 1: case 2: panic xxx //代码逻辑不会走到这里,但是走到了这里,说明有潜在bug
- 简化错误处理逻辑(check/hadle机制)
- 使用recover捕获panic,防止goroutinue意外退出 http server
理解panic的输出栈帧信息,帮助快速定位bug
以上是关于《Go语言精进之路,从新手到高手的编程思想方法和技巧1》读书笔记和分享的主要内容,如果未能解决你的问题,请参考以下文章