RDMA技术浅析
Posted yuanyun_elber
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RDMA技术浅析相关的知识,希望对你有一定的参考价值。
本章主要是集合了一些概念性的东西做了一些整理,后续会看一下RDMA的代码和实际使用的例子。
一、RDMA概述
传统内存访问需要通过CPU进行数据copy来移动数据,通过CPU将内存中的Buffer1移动到Buffer2中。DMA模式:可以同DMA Engine之间通过硬件将数据从Buffer1移动到Buffer2,而不需要操作系统CPU的参与,大大降低了CPU Copy的开销。

类似地,RDMA是一种host-offload, host-bypass技术,允许应用程序(包括存储)在它们的内存空间之间直接做数据传输。具有RDMA引擎的以太网卡(RNIC)--而不是host--负责管理源和目标之间的可靠连接。
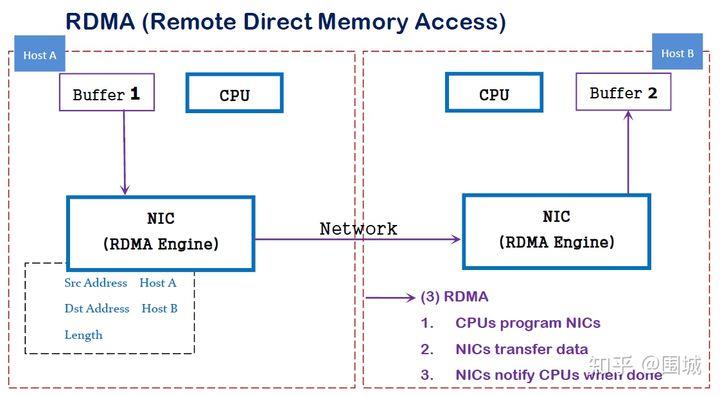
RDMA是一种新的直接内存访问技术,RDMA让计算机可以直接存取其他计算机的内存,而不需要经过处理器的处理。RDMA将数据从一个系统快速移动到远程系统的内存中,而不对操作系统造成任何影响。
在实现上,RDMA实际上是一种智能网卡与软件架构充分优化的远端内存直接高速访问技术,通过将RDMA协议固化于硬件(即网卡)上,以及支持Zero-copy和Kernel bypass这两种途径来达到其高性能的远程直接数据存取的目标。 使用RDMA的优势如下:
- 零拷贝(Zero-copy) - 应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下。数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
- 内核旁路(Kernel bypass) - 应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换。
- 不需要CPU干预(No CPU involvement) - 应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU。远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。远程主机的CPU的缓存(cache)不会被访问的内存内容所填充。
- 消息基于事务(Message based transactions) - 数据被处理为离散消息而不是流,消除了应用程序将流切割为不同消息/事务的需求。
- 支持分散/聚合条目(Scatter/gather entries support) - RDMA原生态支持分散/聚合。也就是说,读取多个内存缓冲区然后作为一个流发出去或者接收一个流然后写入到多个内存缓冲区里去。
二、 RDMA的使用场景
2019天猫双11成交额2684亿!再次刷新世界纪录,订单创新峰值达到54.4万笔/秒,单日数据处理量达到970PB。根据阿里巴巴集团CTO张建锋介绍,即使是在最为繁忙的零点前后,消费者也没有感受到任何抖动,能够顺畅购物,是因为阿里云的数据库、神龙架构、计算存储分离技术,以及最后一点:RDMA。
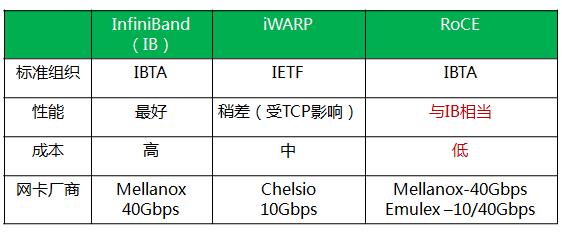
RDMA作为原生于Infiniband的技术,早期广泛用于高性能计算(High Performance Computing)机群。但是由于Infiniband和绝大多数互联网公司数据中心里面本来的Ethernet构架不匹配,而且实施起来成本也高,尤其是设备成本和运维成本,所以刚开始并不火。
RDMA最近在互联网圈火起来应得益于ROCE(RDMA over Converged Ethernet)的出现。但ROCE也不是哪里都好,因为它不是一个放之四海而皆准的通讯标准。ROCE虽然做到了兼容以太网,但是目前的RDMA还是不能直接兼容已有应用。而且RDMA缺少了类似于TCP的socket封装机制,很多事情变得复杂化了。比如你甚至需要考虑RDMA网卡缓存容量不够的问题。所以实现一个“通用的”RDMA扩展其实并不容易。
关于RDMA应用开发的问题,我们在后面的文章中会看到大概是一个什么样的方式。
RDMA的应用目前主要是和GPU、AI、K8S等结合起来。比如说GPU,计算机1的GPU可以直接访问计算机2的GPU内存。
三、RDMA的实现方案
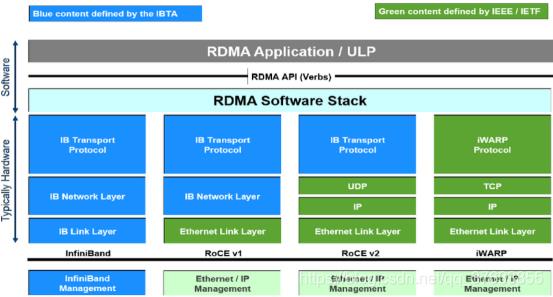
可以分成InfiniBand、ROCE、iWarp三种。
3.1 InfiniBand
作为最早实现RDMA的网络技术,IB(InfiniBand)网络凭借着从硬件到软件的全栈全场景的技术集成,可以天然支持RDMA技术,不过因为要用到专业的硬件设备(IB网络主流设备如图2所示。)所以在部署时需要承担比较高的成本。
这种方式普及程度不如Rocev2和iWarp了。可以看一下如下对比图,图上说ROCE和IB性能相当,还是有一些损失,毕竟人家是全套重新设计的,但是也可以看出IB和Roce相比优势不大。
RoCE相比于Infiniband,主要还是省钱。
至于iWARP,相比于RoCE协议栈更复杂,并且由于TCP的限制,只能支持可靠传输,即无法支持UD等传输类型。所以目前iWARP的发展并不如RoCE和Infiniband。
3.2 RoCEv2
这个应该是最重要的一种方式。
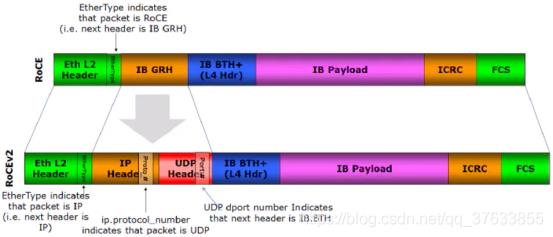
2010年4月,IBTA(infiniband trade association)发布了RoCE技术标准,此标准是作为Infiniband Architecture Specification的附加件发布的,所以也可称之为IBoE(InfiniBand over Ethernet)。如图1所示,RoCEv1标准是在以太链路层之上用IB网络层代替了TCP/IP网络层,所以这种技术并不支持IP路由功能。

因RoCEv1的数据帧不带IP头部,所以只能在同一网段内通信,无法实现IP路由功能。为了解决此问题,IBTA(infiniband trade association)于2014年提出了RoCE V2标准——扩展了RoCEv1,将GRH(Global Routing Header)换成UDP header +IP header,扩展后的帧结构如图5所示。
3.3 iWarp
和RoCEv2基于UDP不同,iWarp是基于TCP,协议上也会更为复杂一点,主要包括MPA/DDP/RDMAP三层子协议
相比RoCE,在大型组网的情况下,iWARP的大量TCP连接会消耗大量的额外内存资源,对系统规格要求更高。另外,在对流量的兼容层面上来讲RoCE支持组播,而iWARP还没有相关的标准定义。
四、 RDMA与DPDK联系和区别
相同点:
1)两者均为kernel bypass技术,可以减少中断次数,消除内核态到用户态的内存拷贝;
相异点:
1)DPDK是将协议栈上移到用户态,而RDMA是将协议栈下沉到网卡硬件,DPDK仍然会消耗CPU资源;
前者bypass 内核,后者bypass cpu。
2)DPDK的并发度取决于CPU核数,而RDMA的收包速率完全取决于网卡的硬件转发能力
3)DPDK在低负荷场景下会造成CPU的无谓空转,RDMA不存在此问题
4)DPDK用户可获得协议栈的控制权,可自主定制协议栈;RDMA则无法定制协议栈
以上是关于RDMA技术浅析的主要内容,如果未能解决你的问题,请参考以下文章