GBDT几问
Posted Jarlene
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GBDT几问相关的知识,希望对你有一定的参考价值。
GBDT几问
本篇文章主要介绍GBDT基本原理以及一些细节性的东西,这些东西更多在面试使用,或者对于二次创新使用,主要内容有以下几个方面:
如果读者对以上各个方面都很熟悉,那么恭喜你已经成功掌握GBDT了。
Boosting算法Bagging算法介绍
在正式开讲GBDT之前,我先熟悉一下江湖中传说的集成学习的两个派系,分别是Boosting和Bagging。所谓的集成学习主要是通过学习多个弱学习器结合组合策略组成强学习以达到“多个臭皮匠顶个诸葛亮”的作用。集成学习中最典型的两个代表就是Boosting家族和Bagging家族。Boosting家族最典型的代码属于AdaBoosting以及提升树(典型的GBDT)。Bagging家族最典型的代表是Random Forest(随机森林,以下简称RF)。
以下两张图片可以清楚描述Boosting和Bagging的差异:Boosting中的弱学习器之间存在依赖关系,这也是GBDT为什么不能并行的原因。

Bagging算法
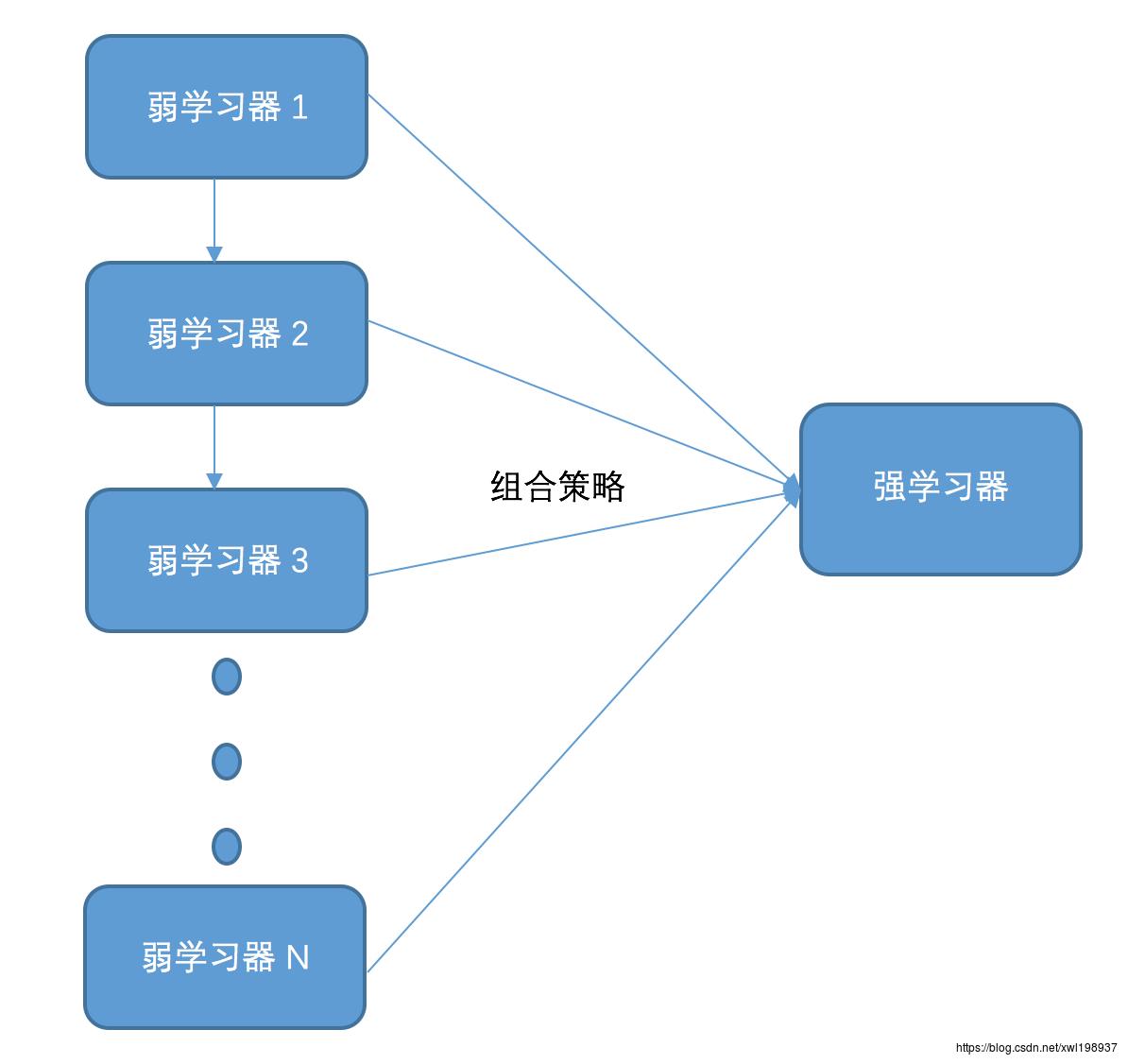
Boosting算法
GBDT基本原理
GBDT基本原理是 通过多轮迭代,每轮迭代产生一个弱分类器(利用cart回归树构建),每个分类器在上一轮分类器的残差基础上进行训练。
数学语言描述:利用前一轮迭代的学习器 ft−1(x) f t − 1 ( x ) 以及损失 L(y,ft−1(x)) L ( y , f t − 1 ( x ) ) 构建一棵cart回归树弱学习器模型 ht(x) h t ( x ) 使得本次迭代的损失 L(y,ft(x))=L(y,ft−1(x)+ht(x)) L ( y , f t ( x ) ) = L ( y , f t − 1 ( x ) + h t ( x ) ) 最小。
GBDT的思想可以用一个通俗的例子解释,假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小。
正如前面提到的GBDT每轮迭代都采用的是损失拟合的方法,但是如何拟合呢?针对这个问题,大牛Freidman提出了用损失函数的负梯度来拟合本轮损失的近似值,进而拟合一个CART回归树。第t轮的第i个样本的损失函数的负梯度表示:
ctj=argmin⏟c∑xi∈RtjL(yi,ft−1(xi)+c) c t j = a r g m i n ⏟ c ∑ x i ∈ R t j L ( y i , f t − 1 ( x i ) + c ) 这样我们就得到本轮的cart回归树拟合函数: ht(x)=∑j=1JctjI(x∈Rtj) h t ( x ) = ∑ j = 1 J c t j I ( x ∈ R t j ) 最终得到本轮的学习器: ft(x)=ft−1(x)+ht(x) f t ( x ) = f t − 1 ( x ) + h t ( x ) 这就是通过损失函数的负梯度来拟合误差的办法。
对弱分类器的要求一般是足够简单,并且是低方差和高偏差的。因为训练的过程是通过降低偏差来不断提高最终分类器的精度。
主要优点:
- 可以灵活处理各种类型的数据,包括连续值和离散值。
- 在相对少的调参时间情况下,预测的准备率也可以比较高。这个是相对SVM来说的。
- 使用一些健壮的损失函数,对异常值的
以上是关于GBDT几问的主要内容,如果未能解决你的问题,请参考以下文章