Redis并发问题(雪崩击穿穿透)
Posted 恒哥~Bingo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis并发问题(雪崩击穿穿透)相关的知识,希望对你有一定的参考价值。
前言
Redis作为目前最火的NoSQL数据库,在大量互联网企业作为重要的核心技术,Redis作为数据库的缓存,在高并发情况下也会出现各种问题,下面我们来了解这些问题以及解决方案,这些也是程序员面试时的高频问题。
Redis的并发问题
Redis一般用于做数据库的缓存,作用:
- 提升性能
- 为数据库挡住大量并发
基本使用流程:
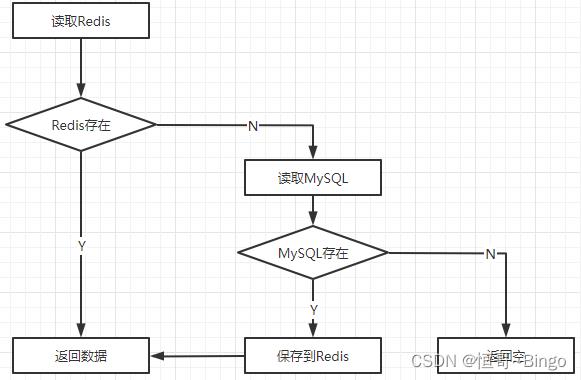
- 先从Redis查询数据
- Redis存在就直接返回
- Redis没有再查询数据库
- 数据库有就保存到Redis中,返回数据
- 数据库没有就返回空
Redis在高并发情况下可能出现的问题:
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 雪崩,Redis出现问题,导致缓存不能命中,直接访问数据库导致数据库宕机 | 1. Redis服务器宕机或重启 2. 大量热点数据同时过期 | 1. 搭建Redis集群 2. 将热点数据的过期时间设置为随机值,避免同时过期 |
| 击穿,大量并发访问Redis,同时穿过Redis,直接访问数据库导致数据库宕机 | 线程的高并发,前面线程还没有将数据保存到Redis中,其它线程就进入Redis进行查询 | 通过锁机制,对Redis操作进行同步 DCL 双检锁 |
| 穿透,大量并发查询数据库中没有的数据,Redis中没有,请求直接打到数据库,导致宕机 | 数据库中没有,Redis中没有保存,直接查询数据库 | 1. 将数据库中没有的数据,在Redis保存空数据,给空数据设置超时 2. 使用布隆过滤器,过滤掉不存在的数据 |
测试案例
创建Person表,实体类如下
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Person implements Serializable
@TableId(type = IdType.AUTO)
private Integer id;
private String name;
private Integer age;
private String gender;
Mapper代码
public interface PersonMapper extends BaseMapper<Person>
Service代码
public interface IPersonService extends IService<Person>
/**
* 按id查询人员
* @param id
* @return
*/
Person getPersonById(Long id);
@Slf4j
@Service
public class PersonServiceImpl extends ServiceImpl<PersonMapper, Person> implements IPersonService
public static final String PREFIX = "Person:";
@Autowired
private PersonMapper personMapper;
@Autowired
private RedisTemplate<String,Object> redisTemplate;
@Override
public Person getPersonById(Long id)
//先查询redis
Person person = (Person) redisTemplate.opsForValue().get(PREFIX + id);
if (person == null)
log.info("Reids没有,查询数据库");
//如果reids没有,就查询数据库
person = personMapper.selectById(id);
//如果数据库中存在,就保存到redis中,返回对象
if (person != null)
log.info("数据库查询到,保存数据到Redis ",person);
redisTemplate.opsForValue().set(PREFIX + id, person);
return person;
else
log.info("Reids有,返回数据",person);
//reids存在就直接返回
return person;
log.info("mysql不能存在,返回空");
return null;
Controller代码
@RestController
public class PersonController
@Autowired
private IPersonService personService;
@ApiOperation("按id查询人员")
@GetMapping("/person/id")
public ResponseEntity<Person> getPersonById(@PathVariable Long id)
return ResponseEntity.ok(personService.getPersonById(id));
Redis配置类
@Configuration
public class RedisConfig
@Bean
public RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory factory)
//创建reids模板对象
RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(factory);
//创建JSON的序列化器
Jackson2JsonRedisSerializer serializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objectMapper =new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
serializer.setObjectMapper(objectMapper);
//创建字符串序列化器
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
redisTemplate.setKeySerializer(stringRedisSerializer);
redisTemplate.setValueSerializer(serializer);
redisTemplate.setHashKeySerializer(stringRedisSerializer);
redisTemplate.setHashValueSerializer(serializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
多线程并发测试
JMeter是一个Java开发的压力测试工具,能够模拟多线程并发访问
使用步骤:
1) 添加线程组
2) 设置线程数
3) 给线程组加http请求
4) 配置http请求
5)添加监听结果树
6) 点击启动按钮进行测试,查询id为1的人,MySQL数据库有,redis没有
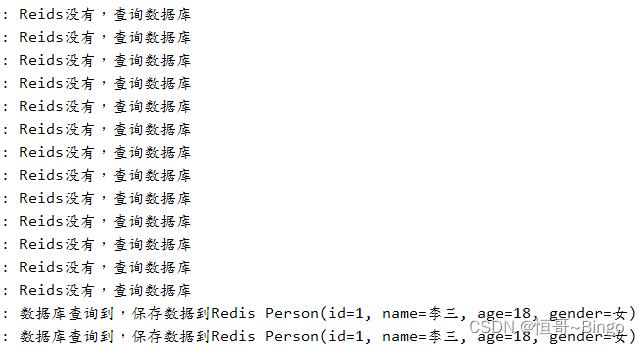
在高并发环境下,出现了大量线程直接访问数据库的情况。
原因是: 出现了缓存击穿
前面的线程查询Redis没有该数据,再查询数据库,然后再保存到Redis中。
在前面线程保存Redis成功之前,后面的线程就直接访问Redis,重复查询数据库,造成数据库压力过大。
解决缓存击穿
解决缓存击穿的方案是:给代码上锁
@Override
public Person getPersonById(Long id)
synchronized (this)
//先查询redis
Person person = (Person) redisTemplate.opsForValue().get(PREFIX + id);
if (person == null)
log.info("Reids没有,查询数据库");
//如果reids没有,就查询数据库
person = personMapper.selectById(id);
//如果数据库中存在,就保存到redis中,返回对象
if (person != null)
log.info("数据库查询到,保存数据到Redis ", person);
redisTemplate.opsForValue().set(PREFIX + id, person);
return person;
else
log.info("Reids有,返回数据", person);
//reids存在就直接返回
return person;
return null;
删除Redis中的数据,重新测试,可以看到解决了击穿问题:
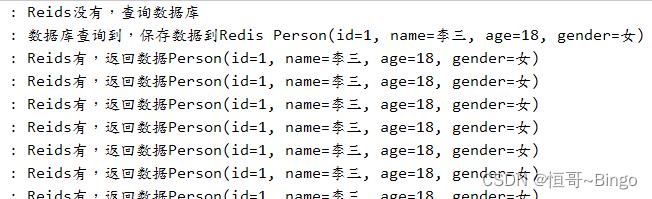
但是上面的代码存在问题:每个线程执行代码都会执行同步锁,效率太低
解决方案:双检锁(Double Check Lock)
@Override
public Person getPersonById(Long id)
//双检锁,先判断redis是否缓存了数据
Person person = (Person) redisTemplate.opsForValue().get(PREFIX + id);
//如果没有缓存,就执行同步代码
if(person == null)
synchronized (this)
//先查询redis
person = (Person) redisTemplate.opsForValue().get(PREFIX + id);
if (person == null)
log.info("Reids没有,查询数据库");
//如果reids没有,就查询数据库
person = personMapper.selectById(id);
//如果数据库中存在,就保存到redis中,返回对象
if (person != null)
log.info("数据库查询到,保存数据到Redis ", person);
redisTemplate.opsForValue().set(PREFIX + id, person);
return person;
else
log.info("Reids有,返回数据", person);
//reids存在就直接返回
return person;
return person;
解决缓存穿透
缓存穿透是查询数据库不存在的数据,空数据没有保存到Redis中,每次都会查询数据库
测试查询id为999的人,可以看到每次都查询了数据库
解决方案1: 把空数据保存到Redis中,设置过期时间,以免占用过多内存
@Override
public Person getPersonById(Long id)
//双检锁,先判断redis是否缓存了数据
Person person = (Person) redisTemplate.opsForValue().get(PREFIX + id);
//如果没有缓存,就执行同步代码
if(person == null)
synchronized (this)
//先查询redis
person = (Person) redisTemplate.opsForValue().get(PREFIX + id);
if (person == null)
log.info("Reids没有,查询数据库");
//如果reids没有,就查询数据库
person = personMapper.selectById(id);
//如果数据库中存在,就保存到redis中,返回对象
if (person != null)
log.info("数据库查询到,保存数据到Redis ", person);
redisTemplate.opsForValue().set(PREFIX + id, person);
return person;
else
//解决缓存穿透,数据库中不存在,保存空数据到Redis中,设置超时时间
redisTemplate.opsForValue().set(PREFIX + id,new Person(),20, TimeUnit.SECONDS);
else
log.info("Reids有,返回数据", person);
//reids存在就直接返回
return person;
return person;
测试结果:数据库只做了一次查询,后面查询的是Redis的空数据
解决方案2: 使用布隆过滤器,过滤掉不存在的数据
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
总结为:布隆过滤器判断存在的数据不一定存在,布隆过滤器判断不存在的数据一定不存在
Redis本身就支持布隆过滤器的实现
Redission工具库,提供了基于Redis实现分布式工具,如:分布式锁、布隆过滤器、分布式原子类等
添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/org.redisson/redisson-spring-boot-starter -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.17.0</version>
</dependency>
配置类
@Configuration
public class RedissonConfig
@Bean
public RBloomFilter<String> bloomFilter()
Config config = new Config();
config.setTransportMode(TransportMode.NIO);
SingleServerConfig singleServerConfig = config.useSingleServer();
//可以用"rediss://"来启用SSL连接
singleServerConfig.setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
//创建布隆过滤器
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("person-filter");
//初始化
bloomFilter.tryInit(10000000L,0.03);
return bloomFilter;
Controller添加初始化布隆过滤器的接口,测试前需要先调用此接口给过滤器添加数据
private RBloomFilter<String> bloomFilter;
@ApiOperation("初始化人员过滤器")
@GetMapping("/person-filter")
public ResponseEntity<List<Person>> initPersonFilter()
List<Person> list = personService.list(null);
list.forEach(person -> bloomFilter.add(PersonServiceImpl.PREFIX + person.getId()););
return ResponseEntity.ok(list);
修改Service:使用布隆过滤器过滤掉数据库没有的数据
private RBloomFilter<String> bloomFilter;
@Override
public Person getPersonById(Long id)
//双检锁,先判断redis是否缓存了数据
Person person1 = (Person) redisTemplate.opsForValue().get(PREFIX + id);
//如果没有缓存,就执行同步代码
if(person1 == null)
//同步代码
synchronized (this)
//先查询redis
Person person = (Person) redisTemplate.opsForValue().get(PREFIX + id);
if (person == null)
//解决缓存穿透,布隆过滤器中不存在该键,直接返回
if(!bloomFilter.contains(PREFIX + id))
log.info("布隆过滤器没有,直接返回");
return null;
log.info("Reids没有,查询数据库");
//如果reids没有,就查询数据库
person = personMapper.selectById(id);
//如果数据库中存在,就保存到redis中,返回对象
if (person != null)
log.info("数据库查询到,保存数据到Redis");
redisTemplate.opsForValue().set(PREFIX + id, person);
return person;
else
log.info("Reids有,返回数据");
//reids存在就直接返回
return person;
return person1;
测试结果:布隆过滤器直接过滤掉数据库不存在的数据
Redis集群的搭建
Redis集群的分类:
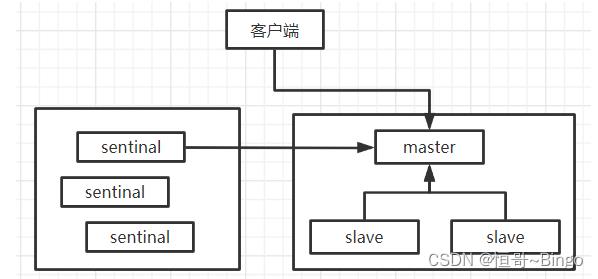
- 主从架构(主服务器负责写,从服务器负责读)
- 哨兵架构(哨兵服务器负责监控主服务器的状态,主服务器如果宕机,将从服务器提升为主)
- 集群架构(并发能力,可用性高于哨兵架构)
哨兵架构
集群架构
一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个,
集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽,该位置可能是集群中任意一台服务器
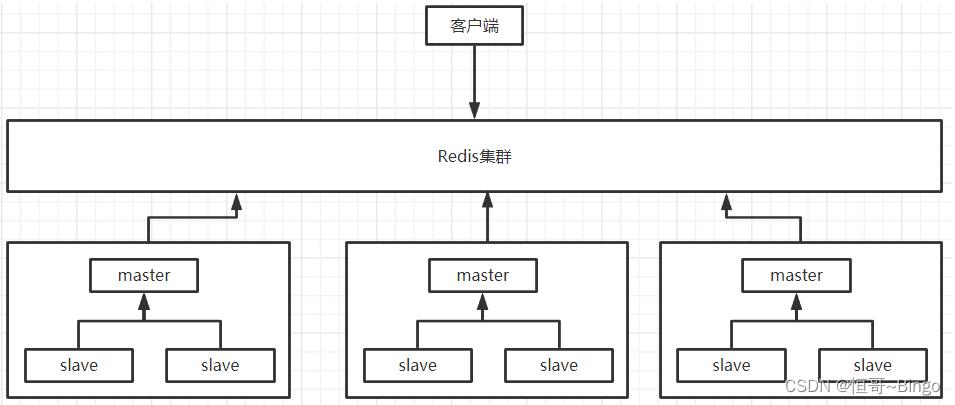
真正的集群:每个Redis安装到不同服务器上
伪集群:在一台机器上安装多个Redis实例
至少需要多少服务器:master的选举需要半数以上服务器投票支持,最少需要三台服务器
在虚拟机搭建伪集群的步骤:
每台服务器需要有一个备份,最少需要六台服务器
1)新建redis-cluster目录,新建redis01~redis06六个子目录
cd /usr/local
mkdir redis-cluster
cd redis-cluster
mkdir redis01
....
2)复制redis/src和redis.conf到redis01~redis06目录中
cd redis
cp -r src/* /usr/local/redis-cluster/redis01
cp reids.conf /usr/local/redis-cluster/redis01
....
3)修改redis.conf
daemonize yes
cluster-enabled yes
port 7001~~~~7006
4)在redis-cluster中创建启动脚本start.sh
cd redis01
./redis-server redis.conf
cd ..
cd redis02
./redis-server redis.conf
cd ..
cd redis03
./redis-server redis.conf
cd ..
cd redis04
./redis-server redis.conf
cd ..
cd redis05
./redis-server redis.conf
cd ..
cd redis06
./redis-server redis.conf
cd ..
5)启动redis实例
chmod +x start.sh
./start.sh
6)创建集群
/usr/local/redis/src/redis-cli --cluster create 192.168.223.223:7001 192.168.223.223:7002 192.168.223.223:7003 192.168.223.223:7004 192.168.223.223:7005 192.168.223.223:7006 --cluster-replicas 1
7)访问集群
/usr/local/redis/src/redis-cli -h 192.168.223.223 -c -p 7001
SpringBoot配置连接Redis集群
spring.redis.cluster.nodes=192.168.223.223:7001,192.168.223.223:7002,192.168.223.223:7003,192.168.223.223:7004,192.168.223.223:7005,192.168.223.223:7006
Redission的配置Redis集群
@Bean
public RBloomFilter<String> bloomFilter()
Config config = new Config();
config.setTransportMode(TransportMode.NIO);
//配置集群
ClusterServersConfig clusterServersConfig = config.useClusterServers();
clusterServersConfig.addNodeAddress(
"redis://192.168.223.223:7001","redis://192.168.223.223:7002","redis://192.168.223.223:7003",
"redis://192.168.223.223:7004", "redis://192.168.223.223:7005","redis://192.168.223.223:7006");
RedissonClient redisson = Redisson.create(config);
//创建布隆过滤器
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("person-filter");
//初始化
bloomFilter.tryInit(10000000L,0.03);
return bloomFilter;
以上是关于Redis并发问题(雪崩击穿穿透)的主要内容,如果未能解决你的问题,请参考以下文章