现代的缓存设计方案:Window-TinyLFU
Posted 凌桓丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了现代的缓存设计方案:Window-TinyLFU相关的知识,希望对你有一定的参考价值。
文章目录
前导知识
- 位图与布隆过滤器的概念以及实现
- LRU缓存机制(Least Recently Used)
- LFU缓存机制(Least Frequently Used)
- TinyLFU: A Highly Efficient Cache Admission Policy
本篇博客仅介绍算法原理,实现原理参考文末代码中的注释。
传统缓存的置换算法
LRU
当我们提到缓存置换算法时,第一反应想到的就是 LRU(Least Recently Used) 算法。LRU 的原理很简单,就是将最不常用的数据淘汰出缓存。
虽然这种方法非常简单有效,但是我们发现 LRU 在淘汰缓存时仅仅依据上一次使用时间这一维度。那其就会存在这样一个问题,大量访问低频的数据突发到来,就会把高频数据给淘汰出缓存。 这里举一个简单的例子:
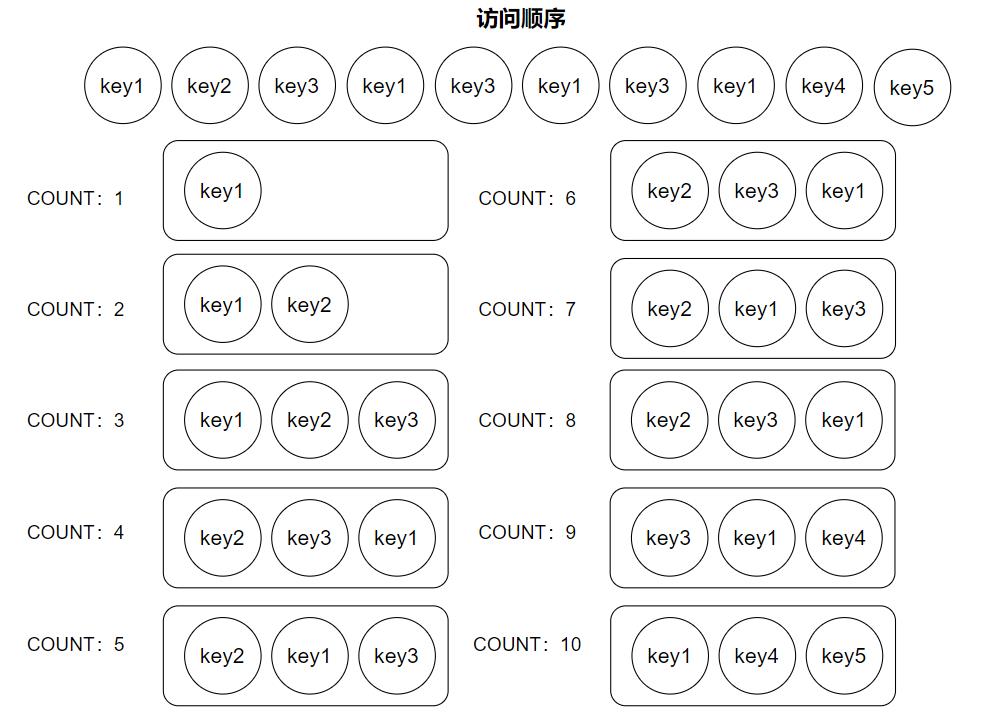
如上图所示,尽管 key3 访问次数较多,但由于 LRU 仅使用时间作为维度,因此当只出现一次的新数据 key4 和 key5 到来时它仍然被淘汰出缓存。而这违背了我们缓存原本的目的:缓存高频数据以降低下层(数据库、文件系统等)查询负担。
为了解决这个问题,我们就必须提到 LFU。
LFU
LFU(Least Frequently Used)算法在 LRU 的基础记录了每个 key 的访问频次。其依据访问频次来作为淘汰的依据,原理如下:如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,将命中频次最少的数据淘汰。
LFU 解决了 LRU 中低频数据淘汰高频数据的问题,但是以频次作为淘汰依据,又带来了新的问题。
- 曾经的高频数据始终占据缓存,即使已经很有没有访问该 key 的请求。
- 突发的稀疏流量由于频次较低,无法占据缓存。(导致短期内大量的数据库查询)
- 需要对每一个数据维护一个计数器,占用了大量的空间。
TinyLFU
TinyLRU 通过引入 Count-Min Sketch 算法来解决 LFU 面临的其中两个问题:
- LFU 需要大量空间来统计频次信息(哈希计数)
- LFU 存在高频旧数据长期不被淘汰(保鲜机制)
下面就来介绍一下 Count-Min Sketch 算法的核心原理。
哈希计数
在 LFU 中我们需要统计每一个 key 的访问频次,这时就需要使用一个整型或者长整型来存储这个计数。但是,我们真的需要这么大的空间来计数吗?在很多情况下,即使是热点数据也并不会被过多的访问,那么我们能否将进一步的压缩计数所占据的存储空间呢?
在之前的博客中我介绍过一种利用位图来进行计数的场景:
通常我们在使用位图时,由于一个位的值只有 0 或 1 ,因此大部分情况下用其来做一些 bool 类型的状态标记(例如数据是否存在、用户是否登录等场景)。而如果我们将每个数据所占据的位数扩大,就可以标记更多的状态。
假设我们认为缓存中一个 key 被访问 15 次即作为高频数据,那么我们是不是能利用 4 个 bit 位来标记一项数据?这样就能够将原先的 32/64 bit 压缩至 4 bit,大大的减少了计数占据的空间。
此时我们将一个 32 位的 int 划分为 8 个 4 bit 计数器,通过计算出数值对应的 int 下标以及其在 int 中偏移的位置,再加上位操作,就可以实现这样的计数。伪代码如下:
std::vector<int> _bits;
int get(int num) const
int countIndex = num / 8;
int countOffset = num % 8 * 4;
return (_bits[countIndex] >> countOffset) & 0x7;
//增加计数
void increment(int num)
int countIndex = num / 8;
int countOffset = num % 8 * 4;
int value = (_bits[countIndex] >> countOffset) & 0x7;
if (value < 15)
_bits[countIndex] += (1 << countOffset);
哈希冲突的处理
既然采用了哈希,就必定会出现冲突的风险,那我们该如何去处理这个问题呢?
我们可以对同一个 key 设置多个计数器,将同一个 key 用不同的哈希函数(或者同一个哈希函数用不同 seed)映射到多个计数器中。然后选取其中最小的值作为计数的结果返回。(防止某些计数器中计数被其他 key 影响而带来的结果偏大)
问题:这样做能保证结果的准确性吗?
答案是不能,我们只能得到一个近似的结果。因为我们最终应用的地方是缓存,我们唯一需要得到的结论就是访问是否高频,而不关心其准确的访问次数是多少,因此在这种场景下我们能够容忍结果的存在一定的偏差。
伪代码如下:
//增加计数
long long seedArr[];
void Increment(key)
//在每个计数器中使用不同的哈希进行计数,防止冲突
for (auto& cmRow : cmRows)
cmRow.Increment(hash(key, seedArr[i]))
//遍历多个计数器,选取其中最小的一个计数返回
int getCountMin(hash)
for (auto& cmRow : cmRows)
value = cmRows.get(hash)
if(min > value)
min = value
return min;
保鲜机制
LFU 所存在的一大问题就是,其仅仅使用频次作为淘汰的维度,因此即使有些数据已经很久没有使用,当由于其具有较高的访问频次而无法被淘汰出缓存。
为了解决这一问题,我们就需要定期去降低一些较老数据的频次(例如设定访问阈值,当访问次数达到阈值时触发保鲜),伪代码如下:
void get(key, value)
......
访问总频次++;
if(访问总频次 < 保鲜阈值)
//频次减半
countMinSketch.reset();
访问总频次 = 0;
......
通过这种定期的保鲜机制,就能够防止数据在缓存中大量驻留。
Window-TinyLFU
虽然 TinyLFU 已经足够优秀,但是它仍然没有解决突发稀疏流量的问题,因为稀疏流量频次较低,始终无法在缓存中占据一席之地。但这时我们再思考一下,这不正是 LRU 解决的问题吗?如果我们在 TinyLRU 中再集合一个 LRU,是不是就完美的解决这个问题了?这也就是其名字中 Window 的由来,其正是 TinyLFU 中集合的一个 Window-LRU 缓存。
架构设计
比起之前的算法,W-TinyLFU 要复杂的多,其架构图如下:

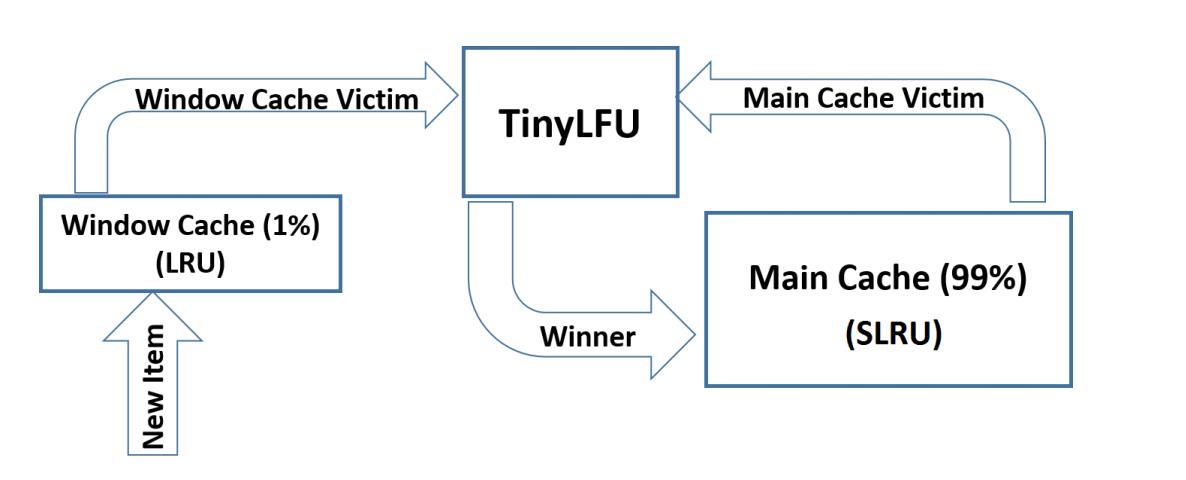
其架构主要由以下几部分组成
- Window LRU:窗口 LRU 缓存,用于存放突发稀疏流量。
- BloomFilter:布隆过滤器,用于避免不必要的缓存置换。
- CountMin Sketch:用于记录缓存的访问次数。
- Segmented LRU:主缓存,用于存储多次命中的数据(即高频次)。分为 peotected 区和 probation 区。
当数据进来时,首先访问的是最前端的窗口缓存 W-LRU,这个缓存占据总大小的 1%,主要用于存储突发的稀疏流量。
紧接着,就到了 TinyLFU 中 BloomFilter 与 CountMin Sketch 的部分。其主要用来记录缓存是否第一次访问,以及记录缓存命中的次数。
主缓存 SLRU 则存储访问频次较高的数据,占用空间 99%,其主要分为两个区域:protected 和 probation。probation 区即非热门数据区(命中一次),其占据主缓存大小的 20%,而 protected 则是热门缓存区(命中两次及以上),其占用了主缓存大小的 80%。
protected 与 probation 的数据是怎样流动的呢?
我们在进行 put 操作时,数据只能被放入 probation。只有在 probation 中 get 命中缓存时,才会将数据转移到 protected 中。此时我们会将新数据与 protected 末尾的数据进行位置交换。
执行流程
查询
- 记录访问频次,如果达到阈值,则触发保鲜机制(清空布隆过滤器,CountMin Sketch 访问减半),避免旧缓存长期驻留。
- CountMin Sketch 对访问计数。
- 在全局 hashMap(用于标记缓存存储区域) 中查询缓存是否存在,如果不存在则返回 false。
- 根据缓存所在区域,进入对应的 s-lru 或 w-lru 中查询。
写入
- 如果 w-lru 未满,则将数据写入后返回。如果满了,继续下一步。
- 如果 s-lru 未满,则将数据写入后返回。如果满了,继续下一步。
- 首先查找布隆过滤器,如果新 key 从未出现过,则不可能将老节点淘汰出去,此时在布隆过滤器中记录访问后返回。
- 如果新 key 出现过,则此时在 CountMin Sketch 查询新 key 与 s-lru 的最后一个节点的访问频次。保留两者中访问频次最高的。
代码实现
我用 C++ 实现了一个 Window-TinyLFU 的 demo,github 地址如下:Window-TinyLFU-Cache
具体的代码实现如下,关键处步骤都已写上注释。
Window-LRU
enum SEGMENT_ZONE
PROBATION,
PROTECTION
;
template<typename T>
struct LRUNode
public:
uint32_t _key;
T _value;
uint32_t _conflict; //在key出现冲突时的辅助hash值
bool _flag; //用于标记在缓存中的位置
explicit LRUNode(uint32_t key = -1, const T& value = T(), uint32_t conflict = 0, bool flag = PROBATION)
: _key(key)
, _value(value)
, _conflict(conflict)
, _flag(flag)
;
template<typename T>
class LRUCache
public:
typedef LRUNode<T> LRUNode;
explicit LRUCache(size_t capacity)
: _capacity(capacity)
, _hashmap(capacity)
std::pair<LRUNode, bool> get(const LRUNode& node)
auto res = _hashmap.find(node._key);
if (res == _hashmap.end())
return std::make_pair(LRUNode(), false);
//获取数据的位置
typename std::list<LRUNode>::iterator pos = res->second;
LRUNode curNode = *pos;
//将数据移动到队首
_lrulist.erase(pos);
_lrulist.push_front(curNode);
res->second = _lrulist.begin();
return std::make_pair(curNode, true);
std::pair<LRUNode, bool> put(const LRUNode& node)
bool flag = false; //是否置换数据
LRUNode delNode;
//数据已满,淘汰末尾元素
if (_lrulist.size() == _capacity)
delNode = _lrulist.back();
_lrulist.pop_back();
_hashmap.erase(delNode._key);
flag = true;
//插入数据
_lrulist.push_front(node);
_hashmap.insert(make_pair (node._key, _lrulist.begin()));
return std::make_pair(delNode, flag);
size_t capacity() const
return _capacity;
size_t size() const
return _lrulist.size();
private:
size_t _capacity;
//利用哈希表来存储数据以及迭代器,来实现o(1)的get和put
std::unordered_map<int, typename std::list<LRUNode>::iterator> _hashmap;
//利用双向链表来保存缓存使用情况,并保证o(1)的插入删除
std::list<LRUNode> _lrulist;
;
Segment-LRU
template<typename T>
class SegmentLRUCache
public:
typedef LRUNode<T> LRUNode;
explicit SegmentLRUCache(size_t probationCapacity, size_t protectionCapacity)
: _probationCapacity(probationCapacity)
, _protectionCapacity(protectionCapacity)
, _hashmap(probationCapacity + protectionCapacity)
std::pair<LRUNode, bool> get(LRUNode& node)
//找不到则返回空
auto res = _hashmap.find(node._key);
if (res == _hashmap.end())
return std::make_pair(LRUNode(), false);
//获取数据的位置
typename std::list<LRUNode>::iterator pos = res->second;
//如果查找的值在PROTECTION区中,则直接移动到首部
if (node._flag == PROTECTION)
_protectionList.erase(pos);
_protectionList.push_front(node);
res->second = _protectionList.begin();
return std::make_pair(node, true);
//如果是PROBATION区的数据,如果PROTECTION还有空位,则将其移过去
if (_protectionList.size() < _probationCapacity)
node._flag = PROTECTION;
_probationList.erase(pos);
_protectionList.push_front(node);
res->second = _protectionList.begin();
return std::make_pair(node, true);
//如果PROTECTION没有空位,此时就将其最后一个与PROBATION当前元素进行交换位置
LRUNode backNode = _protectionList.back();
std::swap(backNode._flag, node._flag);
_probationList.erase(_hashmap[node._key]);
_protectionList.erase(_hashmap[backNode._key]);
_probationList.push_front(backNode);
_protectionList.push_front(node);
_hashmap[backNode._key] = _probationList.begin();
_hashmap[node._key] = _protectionList.begin();
return std::make_pair(node, true);
std::pair<LRUNode, bool> put(LRUNode& newNode)
//新节点放入PROBATION段中
newNode._flag = PROBATION;
LRUNode delNode;
//如果还有剩余空间就直接插入
if (_probationList.size() < _probationCapacity || size() < _probationCapacity + _protectionCapacity)
_probationList.push_front(newNode);
_hashmap.insert(make_pair(newNode._key, _probationList.begin()));
return std::make_pair(delNode, false);
//如果没有剩余空间,就需要淘汰掉末尾元素,然后再将元素插入首部
delNode = _probationList.back();
_hashmap.erase(delNode._key);
_probationList.pop_back();
_probationList.push_front(newNode);
_hashmap.insert(make_pair(newNode._key, _probationList.begin()));
return std::make_pair(delNode, true);
std::pair<LRUNode, bool> victim()
//如果还有剩余的空间,就不需要淘汰
if (_probationCapacity + _protectionCapacity > size())
return std::make_pair(LRUNode(), false);
//否则淘汰_probationList的最后一个元素
return std::make_pair(_probationList.back(), true);
int size() const
return _protectionList.size() + _probationList.size();
private:
size_t _probationCapacity;
size_t _protectionCapacity;
std::unordered_map<int, typename std::list<LRUNode>::iterator> _hashmap;
std::list<LRUNode> _probationList;
std::list<LRUNode> _protectionList;
;
BloomFilter
class BloomFilter
public:
explicit BloomFilter(size_t capacity, double fp)
: _bitsPerKey((getBitsPerKey(capacity, fp) < 32 ? 32 : _bitsPerKey) + 31)
, _hashCount(getHashCount(capacity, _bitsPerKey))
, _bits(_bitsPerKey, 0)
//如果哈希函数的数量超过上限,此时准确率就非常低
if (_hashCount > MAX_HASH_COUNT)
_hashCount = MAX_HASH_COUNT;
void put(uint32_t hash)
int delta = hash >> 17 | hash << 15;
for (int i = 0; i < _hashCount; i++)
int bitPos = hash % _bitsPerKey;
_bits[bitPos / 32] |= (1 << (bitPos % 32));
hash += delta;
bool contains(uint32_t hash) const
//参考leveldb的做法,通过delta来打乱哈希值,模拟进行多次哈希函数
int delta = hash >> 17 | hash << 15; //右旋17位,打乱哈希值
int bitPos = 0;
for (int i = 0; i < _hashCount; i++)
bitPos = hash % _bitsPerKey;
if ((_bits[bitPos / 32] & (1 << (bitPos % 32))) == 0)
return false;
hash += delta;
return true;
bool allow(uint32_t hash)
if (contains(hash) == false)
put(hash);
return false;
return true;
void clear()
for (auto& it : _bits)
it = 0;
private:
size_t _bitsPerKey;
size_t _hashCount;
std::vector<int> _bits;
static const int MAX_HASH_COUNT = 30;
int getBitsPerKey(int capacity, double fp) const
return std::ceil(-1 * capacity * std::log(fp) / std::pow(std::log(2), 2));
int getHashCount(int capacity, int bitsPerKey) const
return std::round(std::log(2) * bitsPerKey / double(capacity));
;
CountMin-Sketch
class CountMinRow
public:
explicit CountMinRow(size_t countNum)
: _bits((countNum < 8 ? 8 :以上是关于现代的缓存设计方案:Window-TinyLFU的主要内容,如果未能解决你的问题,请参考以下文章