Hive Count Distinct 优化
Posted @SmartSi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive Count Distinct 优化相关的知识,希望对你有一定的参考价值。

目前,Hive 底层使用 MapReduce 作为实际计算框架,SQL 的交互方式隐藏了大部分 MapReduce 的细节。这种细节的隐藏在带来便利性的同时,也对计算作业的调优带来了一定的难度。未经优化的 SQL 语句转化后的 MapReduce 作业,运行效率可能大大低于用户的预期。本文我们就来分析一个简单语句的优化过程。
日常统计场景中,我们经常会对一段时期内的字段进行去重并统计数量,SQL 语句类似于
SELECT COUNT(DISTINCT id)
FROM TABLE_NAME
WHERE ...;
这条语句是从一个表的符合 WHERE 条件的记录中统计不重复的 id 的总数。该语句转化为 MapReduce 作业后执行示意图如下,图中还列出了我们实验作业中 Reduce 阶段的数据规模:

由于引入了 DISTINCT,因此在 Map 阶段无法利用 Combine 对输出结果去重,必须将 id 作为 Key 输出,在 Reduce 阶段再对来自于不同 Map Task、相同 Key 的结果进行去重,计入最终统计值。
我们看到作业运行时的 Reduce Task 个数为1,对于统计大数据量时,这会导致最终 Map 的全部输出由单个的 Reduce Task 处理。这唯一的 Reduce Task 需要 Shuffle 大量的数据,并且进行排序聚合等处理,这使得它成为整个作业的 IO 和运算瓶颈。
经过上述分析后,我们尝试显式地增大 Reduce Task 个数来提高 Reduce 阶段的并发,使每一个 Reduce Task 的数据处理量控制在 2G 左右。具体设置如下:
# Hadoop1.x
set mapred.reduce.tasks=100;
# Hadoop2.x
set mapreduce.job.reduces=100;
调整后我们发现这一参数并没有影响实际 Reduce Task 个数,Hive 运行时输出 Number of reduce tasks determined at compile time: 1。原来 Hive 在处理 COUNT 这种全聚合计算时,会忽略用户指定的 Reduce Task 数,强制使用 1 个 Reduce。我们只能采用变通的方法来绕过这一限制。我们利用 Hive 对嵌套语句的支持,将原来一个 MapReduce 作业转换为两个作业,在第一阶段选出全部的非重复 id,在第二阶段再对这些已去重的 id 进行计数。这样在第一阶段我们可以通过增大 Reduce 的并发数,并发处理 Map 输出。在第二阶段,由于 id 已经去重,因此 COUNT(*) 操作在 Map 阶段不需要输出原 id 数据,只输出一个合并后的计数即可。这样即使第二阶段 Hive 强制指定一个 Reduce Task,极少量的 Map 输出数据也不会使单一的 Reduce Task 成为瓶颈。改进后的 SQL 语句如下:
SELECT COUNT(*)
FROM (
SELECT DISTINCT id
FROM TABLE_NAME
WHERE …
) t;
在实际运行时,我们发现 Hive 还对这两阶段的作业做了额外的优化。将第二个 MapReduce 作业 Map 中的 Count 过程移到了第一个作业的 Reduce 阶段。这样在第一阶段 Reduce 就可以输出计数值,而不是去重的全部 id。这一优化大幅地减少了第一个作业的 Reduce 输出 IO 以及第二个作业 Map 的输入数据量。最终在同样的运行环境下优化后的语句执行只需要原语句 20% 左右的时间。优化后的 MapReduce 作业流如下:
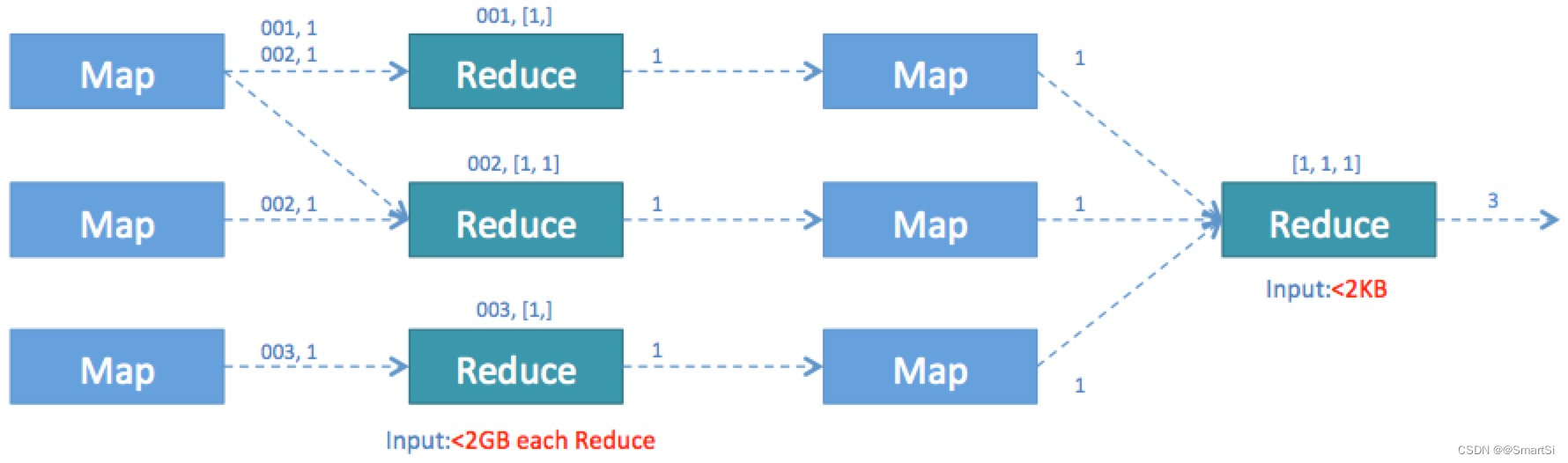
从上述优化过程我们可以看出,一个简单的统计需求,如果不理解 Hive 和 MapReduce 的工作原理,它可能会比优化后的执行过程多四、五倍的时间。我们在利用 Hive 简化开发的同时,也要尽可能优化 SQL 语句,提升计算作业的执行效率。
注:文中测试环境Hive版本为0.9
原文:http://bigdata-blog.net/2013/11/08/hive-sql%E4%BC%98%E5%8C%96%E4%B9%8B-count-distinct/
以上是关于Hive Count Distinct 优化的主要内容,如果未能解决你的问题,请参考以下文章