Flink Unaligned Checkpoint 在 Shopee 的优化和实践
Posted @SmartSi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink Unaligned Checkpoint 在 Shopee 的优化和实践相关的知识,希望对你有一定的参考价值。

目录
- Checkpoint 存在的问题
- Unaligned Checkpoint 原理介绍
- 大幅提升 UC 收益
- 大幅降低 UC 风险
- UC 在 Shopee 的生产实践和未来规划
Flink 做为大数据流计算的标杆,通过 Checkpoint 和 State 保证了 Exactly Once 语义。在生产实践中,Shopee 遇到了很多 Checkpoint 的问题,并尝试引入 Flink 的 Unaligned Checkpoint 去解决。但调研后发现效果与预期有一定差距,所以在内部版本对其进行了深度改进,并将大部分改进已经反馈给了 Flink 社区。
本文会介绍 Checkpoint 存在的问题、Unaligned Checkpoint 原理、Shopee 对 Unaligned Checkpoint 的改进、对 Flink 社区的贡献以及内部的实践和落地。
1. Checkpoint 存在的问题
1.1 Checkpoint 存在的技术问题
Flink 作业反压严重导致 Checkpoint 超时失败是 Flink 生产中普遍存在的问题,而持续的反压会造成长时间没有成功的 Checkpoint。
例如:外部查询或写入性能瓶颈、CPU 瓶颈、数据倾斜等在大促或高峰期常见的场景都会间接导致 Checkpoint 持续失败。
1.2 Checkpoint 持续失败对业务的影响
- 消费了半小时的 lag 数据,dev 发现这半小时任务的消费速率慢,达不到预期,想调大任务并行度并重启来提升消费能力。如果 Checkpoint 一直失败,则需要从半小时前的 Checkpoint 恢复,这半小时内消费过的数据会被重复消费,导致资源浪费和业务数据可能重复的风险。
- 当消费 lag 时,如果 tolerable-failed-checkpoints(容忍 CP 失败的次数默认是 0)太低,Flink job 可能进入死循环(消费 lag 导致 job 反压严重,反压严重导致 Checkpoint 超时失败,Checkpoint 失败导致 job 失败,job 失败导致消费更多的 lag),lag 永远不能消费完成。
- 无限容忍 Checkpoint 失败不是优雅的解决方案,如果容忍次数太高:
- 生产上的问题不能及时地被发现;
- 一些 Connector 在 Checkpoint 时会提交数据或文件。如果 Checkpoint 持续失败,这些数据或文件长时间不能被提交,它会导致数据延迟和事务超时。例如:Kafka Producer 事务超时会导致事务失败;
- 一旦作业重启,将有大量数据被重复消费。
- 业务高峰和大促与消费 lag 类似,会遇到相同的问题。
1.3 引入 Unaligned Checkpoint
基于上述背景,很多用户都希望在 Flink 任务有瓶颈(反压严重)时,Checkpoint 可以成功,所以 Flink 社区在 FLIP-76 中引入了 Unaligned Checkpoint 机制(下文简称 UC)。
2. Unaligned Checkpoint 原理介绍
2.1 UC 核心思路
反压严重时,Aligned Checkpoint(下文简称 AC)超时主要在于 Barrier 在数据流中排队。反压严重时,数据流动很慢导致 Barrier 流动很慢,最终导致 AC 超时。
UC 的核心思路是:当数据流动很慢时,Barrier 通过某些机制超越数据,从而使得 Barrier 可以快速地从 Source 一路超车到 Sink。
2.2 Task 的 UC 流程详解
假设当前 Task 上游 Task 并行度为 3,下游并行度为 2。UC 开始后 Task 的 3 个 InputChannel 会陆续收到上游发送的 Barrier。
如图所示,灰色框表示 buffer 中的一条条数据,InputChannel-0 先收到 Barrier,其他 InputChannel 还没收到 Barrier。
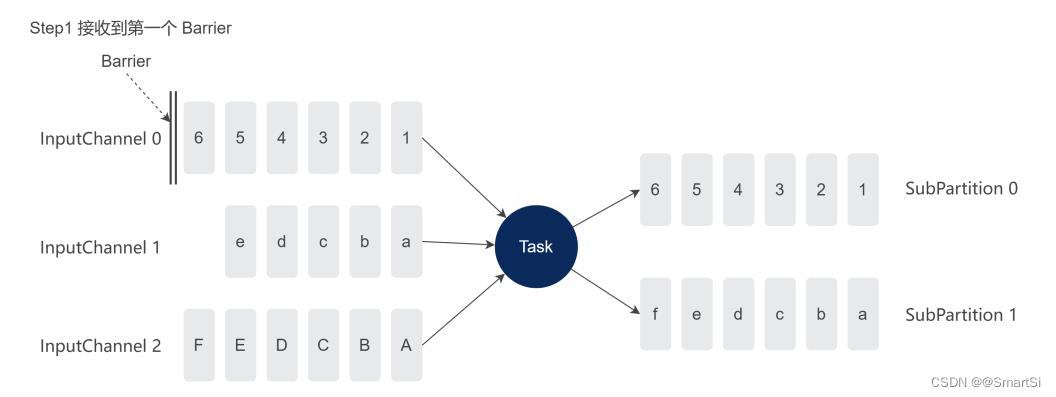
当某一个 InputChannel 接收到 Barrier 时,会直接开启 UC 的第一阶段,即:UC 同步阶段。注意:
- 只要有任意一个 Barrier 进入 Task 网络层的输入缓冲区,Task 直接开始 UC;
- 不用等其他 InputChannel 接收到 Barrier,也不需要处理完 InputChannel 内 Barrier 之前的数据。
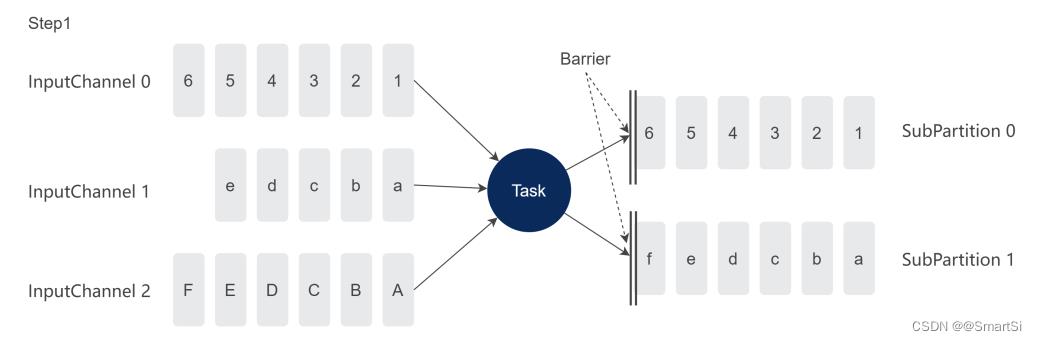
如下图所示,为了保证数据一致性,UC 同步阶段 Task 不能处理数据,同步阶段会做以下几个事情:
- Barrier 超车:发送 Barrier 到所有的 ResultSubPartition 的头部,超越所有的 input&output buffer,Barrier 可以被快速发到下游 Task;
- Buffer 进行快照:对所有超越的 input&output buffer 做快照;
- 调用算子的 snapshotState 方法;
- Flink 引擎对算子内部的 State 进行快照。

有几个注意事项:
- 做 UC 时,Barrier 超越的 buffer 数据直接被跳过了。为了保证数据不丢失,这些 buffer 需要跟 State 一起写到 HDFS,从 Checkpoint 恢复时,这些数据会被消费;
- 同步阶段 Task 不能处理数据,为了尽量减少阻塞的时间,同步阶段只是对 buffer 和状态数据进行一份引用,真正写数据到 HDFS 会通过异步完成;
- UC 同步阶段的最后两步与 AC 完全一致,对算子内部的 State 进行快照。
UC 同步阶段完成后,Task 继续处理数据,同时开启 UC 的第二个阶段:Barrier 对齐和 UC 异步阶段。异步阶段将同步阶段浅拷贝的 State 以及 buffer 写到 HDFS 中。
为什么 UC 还有 Barrier 对齐呢?
当 Task 开始 UC 时,有很多 InputChannel 没接收到 Barrier,这些 InputChannel 的 Barrier 之前可能还会有 network buffer 需要进行快照,所以 UC 第二阶段需要等所有 InputChannel 的 Barrier 都到达,且 Barrier 之前的 buffer 都需要快照。可以认为 UC 需要写三类数据到 HDFS 上:
- 同步阶段引用的所有 input&output buffer;
- 同步阶段引用的算子内部的 State;
- 同步阶段后其他 InputChannel Barrier 之前的 buffer。
- 异步阶段把这三部分数据全部写完后,将文件地址汇报给 JobManager,当前 Task 的 UC 结束。
注:理论上 UC 异步阶段的 Barrier 对齐会很快。如上述 Task 所示,Barrier 可以快速超越所有的 input&output buffer,优先发送 Barrier 给下游 Task,所以上游 Task 也类似:Barrier 超越上游所有的 buffer,快速发送给当前 Task。
2.3 UC 实践中的问题
当任意一个 Barrier 进入 Task 网络层的输入缓冲区时,Task 直接开始 UC。Barrier 快速超越所有的 buffer 被发送到下游,所以 UC 不受反压影响。理论上:无论反压有多严重,UC Barrier 都可以一路超车,快速从 Source 流到 Sink,每个 Task 都可以快速完成快照。
理论很美好,但我们在实际调研和任务使用过程中,发现 UC 效果达不到预期:
- 在很多场景,任务反压严重时,UC 仍然不能成功,导致 UC 预期收益大打折扣;
- UC 会显著增加写 HDFS 的文件数,对线上服务的稳定性有影响,增加了大范围应用的难度;
- UC 存在一些 bug。
后续部分会介绍上述问题,以及 Shopee 的解决方案和对社区的贡献。
3. 大幅提升 UC 收益
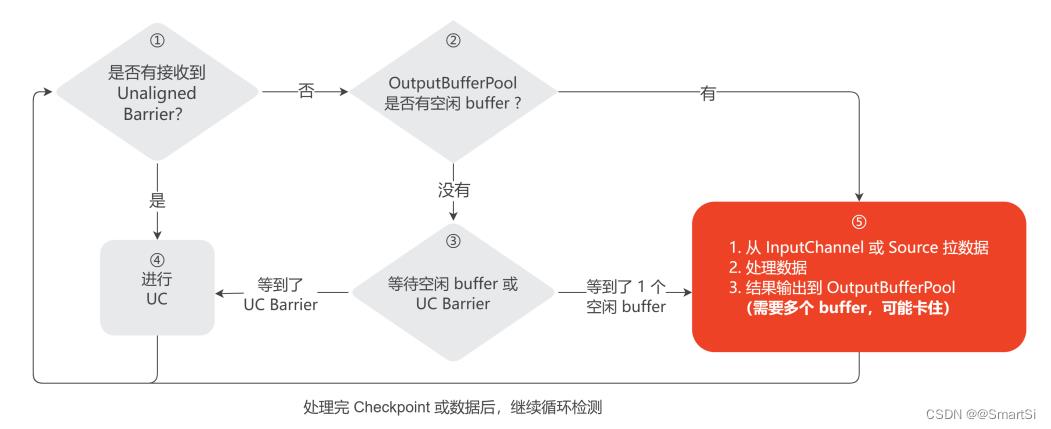
Task 在处理数据的过程中不能处理 Checkpoint,必须将当前处理的这条数据处理完并将结果写入到 OutputBufferPool 中,才会检查是否 InputChannel 有接收到 UC Barrier,如果有则开始 UC。
如果 Task 处理一条数据并写结果到 OutputBufferPool 超过 10 分钟,那么 UC 还是会超时。通常处理一条数据不会很慢,但写结果到 OutputBufferPool 可能会比较耗时。
从 OutputBufferPool 的视角来看,上游 Task 是生产者,下游 Task 是消费者。所以下游 Task 有瓶颈时,上游 Task 输出结果到 OutputBufferPool 会卡在等待 buffer,不能开始 UC。
为了解决这个问题,Flink 社区在 FLINK-14396 中引入了预留 buffer 的机制。解决思路是:Task 处理数据前检查 OutputBufferPool 是否有空闲的 buffer,如果没有空闲 buffer 则继续等待。详细流程如下图所示。

等 OutputBufferPool 中有空闲 buffer 了才去处理数据,来保证 Task 处理完数据后可以顺利地将结果写入到 OutputBufferPool 中,不会卡在第 5 步数据输出的环节。优化后如果没有空闲 buffer,Task 会卡在第 3 步等待空闲 buffer 和 UC Barrier 的环节,在这个环节当接收到 UC Barrier 时可以快速开始 UC。
3.1 处理一条数据需要多个 buffer 场景的提升
如下图所示,由于只预留了一个 buffer,当处理一条数据需要多个 buffer 的场景,Task 处理完数据输出结果到 OutputBufferPool 时可能仍然会卡在第 5 步,导致 Task 不能处理 UC。
例如:单条数据较大、flatmap、window 触发以及广播 watermark 都是处理一条数据需要多个 buffer 场景,这些场景下 Task 卡在第 5 步数据输出环节,导致 UC 表现不佳。解决这个问题的核心思路还是如何让 Task 不要卡在第 5 步而是卡在第 3 步的等待环节。
基于上述问题,Shopee 在 FLIP-227 提出了 overdraft(透支) buffer 的提议,思路是:处理数据过程中,如果 buffer 不足且 TaskManager 有空余的 network 内存,则当前 Task 的 OutputBufferPool 会向 TM 透支一些 buffer,从而完成第 5 步数据处理环节。
注:OutputBufferPool 一定是在没有空闲 buffer 时才会使用透支 buffer。所以一旦透支 buffer 被使用,Task 在进行下一轮第 3 步进入等待 Barrier 和空闲 buffer 的环节时,Task 会认为 OutputBufferPool 没有空闲 buffer,直到所有透支 buffer 都被下游 Task 消费完且 OutputBufferPool 至少有一个空闲 buffer 时,Task 才会继续处理数据。
默认 taskmanager.network.memory.max-overdraft-buffers-per-gate=5,即:Task 的每个 OutputBufferPool 可以向 TM 透支 5 个 buffer。引入透支 buffer 机制后,当 TM network 内存足够时,如果处理一条数据需要 5 个 buffer,则 UC 完全不会卡住。如果 TM 的 network 内存比较多,可以调大参数兼容更多的场景。
Flink-1.16 开始支持透支 buffer 的功能,涉及到的 JIRA 有:FLINK-27522、FLINK-26762、FLINK-27789。
3.2 Legacy Source 的提升
从数据的来源划分有两种 Task,SourceTask 和非 SourceTask:
- SourceTask 从外部组件读数据到 Flink Job 中,非 SourceTask 从 InputChannel 中读数据,数据来源于上游 Task。
- 非 SourceTask 从 InputChannel 读数据之前会对 OutputBufferPool 进行检查,有空闲 buffer 才会读取。SourceTask 从外部组件读取数据前如果不检查 OutputBufferPool 是否有空闲 buffer,则 UC 会表现不佳。
Flink 有两种 Source,分别是 Legacy Source 和新 Source:
- 新 Source 与 Task 的工作模式是拉的模式,即:Task 向 Source 拉数据,工作模式跟 InputChannel 类似,Task 会检查 OutputBufferPool 有空闲 buffer 后,再从 Source 中拉数据。
- Legacy Source 是推的模式,即:Legacy Source 从外部组件读到数据后直接往下游发送,当 OutputBufferPool 没有空闲 buffer 时,Legacy Source 就会卡住,不能正常处理 UC。
然而,我们生产环境几乎所有 Flink job 仍在使用 Legacy Source,由于 Legacy Source 已经被 Flink 社区废弃不再维护,所以 Shopee 内部对常用的 Legacy Source 做了改进。
改进思路与上述思路类似:Legacy Source 检查 OutputBufferPool 有空闲 buffer 后,再往下游发数据。
Flink 中最常用的 FlinkKafkaConsumer 其实就是 Legacy Source,所以业界很多 Flink 用户都仍在使用 Legacy Source。我们将内部改进版的 Legacy Source 分享到了 FLINK-26759。
4. 大幅降低 UC 风险
经过上述优化,反压严重时 UC 在 Legacy Source 和消费一条数据需要多个 buffer 的场景也可以快速成功,已经达到了一些 Flink 用户的预期效果,但 UC 仍然达不到大规模生产的标准。主要在于 UC 相比 AC 会写 network buffer 到 Checkpoint 中,所以引入了一些额外风险:
- 会写更多的文件到 HDFS,给 NameNode 造成额外压力;
- 数据的 schema 升级以后,如果序列化不兼容,则数据无法恢复;
- 当算子之间的连接发生变化时,算子之间的 buffer 数据无法恢复(例如:从 rebalance 改为 forward)。
4.1 无法顺利地从 AC 切换成 UC
用户希望既可以规避这些风险,又可以享受 UC 带来的收益,所以 Flink 社区引入了 Aligned checkpoint timeout 机制,即:默认 Checkpoint 是 AC,如果 AC 在指定时间内不能完成,则切换成 UC。
引入 AC timeout 机制后,UC 的风险并没有完全规避,只是在任务没有反压的情况下,仍然是 AC,不存在额外的风险。当反压严重 AC 会失败时,切换成 UC 来保证 Checkpoint 可以成功。
我们假设 AC timeout = 1min 且 Checkpoint timeout = 5min,即:Checkpoint 仍然以 AC 开始,AC 一分钟不能成功则切换成 UC,Checkpoint 总时长超过 5 分钟就会超时失败。
AC timeout 的发展总共有三个阶段,前两个阶段并达不到预期目标,即:1 分钟时间到了,Job 仍然不能从 AC 切换为 UC,甚至 5 分钟都不能切换成 UC 最终导致 Checkpoint 超时失败。我们可以带着目标去了解这三个阶段。
4.2 InputChannel 支持从 AC 切换为 UC
FLINK-19680 首次支持了 AC timeout 机制,第一阶段的原理是:每个 Task 从接收到第一个 Barrier 开始计时,如果 Task 内 AC Barrier 对齐时间超过 AC timeout,则当前 Task 从 AC 切换为 UC。
该机制存在的问题是:当 Job 的 Task 数较多,从 Source 到 Sink 要经过 10 个 Task。假设 10 个 Task 内部 Barrier 对齐时间都是 59 秒,则所有 Task 都不会切换成 UC,但 10 个 Task 都需要对齐,Checkpoint 总时长至少需要 590 秒(大于 5 分钟),所以最终 Checkpoint 仍然超时失败。
基于阶段一的问题,FLINK-23041 进行了改进,第二阶段的原理是:Barrier 中携带 Checkpoint 开始的时间戳,当 InputChannel 收到 Barrier 后,用当前系统时间减 Checkpoint 开始的时间表示 Checkpoint 已经过去多久了:
- 如果已经超过 1 分钟,直接切换成 UC;
- 如果少于 1 分钟,则用 1 分钟减 AC 已经消耗的时间,表示希望多久以后切换成 UC。设定一个定时器,时间到了,就会切换成 UC。
阶段二相比阶段一,解决了多个 Task 时间累加的问题,只要 InputChannel 接收到 Barrier,在指定时间内 AC 没有完成,就可以定时将 AC 切换成 UC。
4.3 Output buffer 支持从 AC 切换为 UC
阶段二完成后,可以认为 InputChannel 已经较好地支持了 AC 切换为 UC。但存在的问题也很明显,即:output buffer 不支持从 AC 切换为 UC。
如果任务反压严重,Barrier 在 output buffer 中排队,如果在 5 分钟内 Barrier 不能发送到下游 Task 的 InputChannel,则 Checkpoint 仍然会超时。
基于这个问题,Shopee 在 FLINK-27251 和 FLINK-28077 提出了支持 output buffer 从 AC 切换成 UC 的改进。设计思路是:
如果开启了 UC 且当前是 AC,则发送 Barrier 到 output buffer 的尾部。但过一会 AC 可能需要转换为 UC,所以需要设定一个定时器。
如果定时器时间到了 Barrier 还在 output buffer 中排队,则将 AC 转换为 UC:Barrier 超车到 output buffer 头部,且图中超越的浅蓝色 buffer 需要被快照写到 Checkpoint 中。

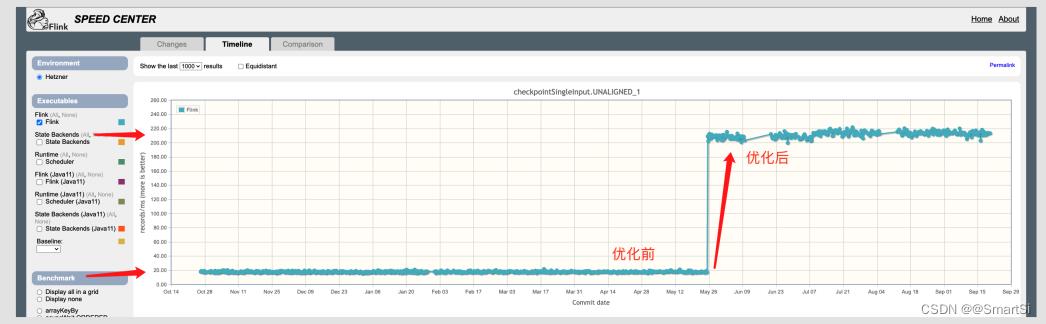
社区早期为 Checkpoint 设计了 Benchmark 用来评估 Checkpoint 的性能,如下图所示,该优化 merge 到 Flink master 分支后 UC 的性能提升了 11 倍。

4.4 UC 小文件合并
开启 AC timeout 机制后,Flink 可以做到反压不严重时使用 AC,反压严重时顺利切换成 UC。大大降低了 UC 的额外风险,也可以在反压严重时享受 UC 带来的收益。但在大规模生产中,仍然有风险。
默认 Flink 每个 Subtask 为 buffer 写一个文件,假设任务有 10 个 Task,每个 Task 并发为 1000,则 UC 可能会额外写 1 万个小文件。假设 Kafka 集群出现故障或瓶颈,大量 Flink Job 写 Kafka 慢,会导致大量 Flink 任务从 AC 切换成 UC。这种情况大量任务瞬间写数十万的小文件到 HDFS,可能导致 NameNode 雪崩。
为了解决小文件问题,Shopee 在 FLINK-26803 和 FLINK-28474 中提出了合并 UC 小文件的改进。
优化思路:多个 Task 共享同一个文件。每个 Task 不再单独创建文件,而是向 CheckpointStreamManager 获取文件流。
CheckpointStreamManager 会为 n 个 Task 分配一个文件,默认 channel-state.number-of-tasks-share-file=5,即:5 个 Task 共享一个 UC 文件,UC 文件个数就会减少 5 倍。多个 Task 同时写同一个文件会有线程安全问题,所以写文件时要对文件流进行加锁来保证多个 Task 串行写文件。
从生产经验上来看,大量的 UC 小文件在 1MB 以内,所以 20 个 Task 共享一个文件也是可以接受的。当然,如果 NN 压力非常小且 Flink Job 更追求写效率,可以设置该参数为 1,表示 Task 不共享 UC 文件。
当前 UC 小文件合并的功能我们还在给社区贡献中。
4.5 修复 network buffer 死锁
Shopee 对 UC 相关的贡献还包括:在 FLINK-22946 中解决了回收 network buffer 时的死锁问题。
5. UC 在 Shopee 的生产实践和未来规划
5.1 UC 生产实践
为了规避 UC 带来的额外风险,Shopee 内部将 aligned-checkpoint-timeout 设置为 1 分钟,表示任务反压不严重,如果 AC 可以在 1 分钟以内完成,则使用 AC。当反压严重 AC 在 1 分钟以内不能完成时,才切换为 UC。
Shopee Flink 平台的开发页面也增加了 UC 的开关,用户可以选择是否为作业开启 Unaligned Checkpoint,目前已有上百个 Flink 任务开启 UC,且目前使用 UC 的作业表现良好,反压时 UC 也可以成功。

5.2 UC 未来规划
我们会持续关注用户在 UC 上遇到的问题,待稳定运行数月后,可以考虑开启 AC timeout 的前提下为全量任务开启 UC。
Shopee 内部版本对 Flink 调度和 network 内存模块有较大改动,可以精确计算 TM 需要的 network 内存,未来会为 UC overdraft buffer 预留单独的内存。
以上是关于Flink Unaligned Checkpoint 在 Shopee 的优化和实践的主要内容,如果未能解决你的问题,请参考以下文章