HBase源码分析之HRegion上MemStore的flsuh流程
Posted lipeng_bigdata
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase源码分析之HRegion上MemStore的flsuh流程相关的知识,希望对你有一定的参考价值。
了解HBase架构的用户应该知道,HBase是一种基于LSM模型的分布式数据库。LSM的全称是Log-Structured Merge-Trees,即日志-结构化合并-树。相比于Oracle普通索引所采用的B+树,LSM模型的最大特点就是,在读写之间采取一种平衡,牺牲部分读数据的性能,来大幅度的提升写数据的性能。通俗的讲,HBase写数据如此快,正是由于基于LSM模型,将数据写入内存和日志文件后即立即返回。
但是,数据始终在内存和日志中是不妥当的,首先内存毕竟是有限的稀缺资源,持续的写入会造成内存的溢出,而日志的写入仅是由于内存数据系统宕机或进程退出后立刻消失而采取的一种保护性措施,而不是作为最终的数据持久化。日志文件不能用来做最终持久化的另外一个原因,就是写入日志时仅仅是简单的追加(append),读数据时效率会非常非常的低。
MemStore的flush就是为了解决上述问题而采取的一种有效措施。关于B+树、LSM模型,读者可自行补脑。本文仅仅阐述HRegion上MemStore的flsuh流程,而关于何时发生flush等其他内容将在其他的博文中进行分析。
说了这么多,下面,就开始神奇的源码分析之旅吧~
先从宏观上对HRegion上fMemStore的flush流程有一个整体的把握。HRegion上flush的入口方法为flushCache(),其处理整体流程如图所示:
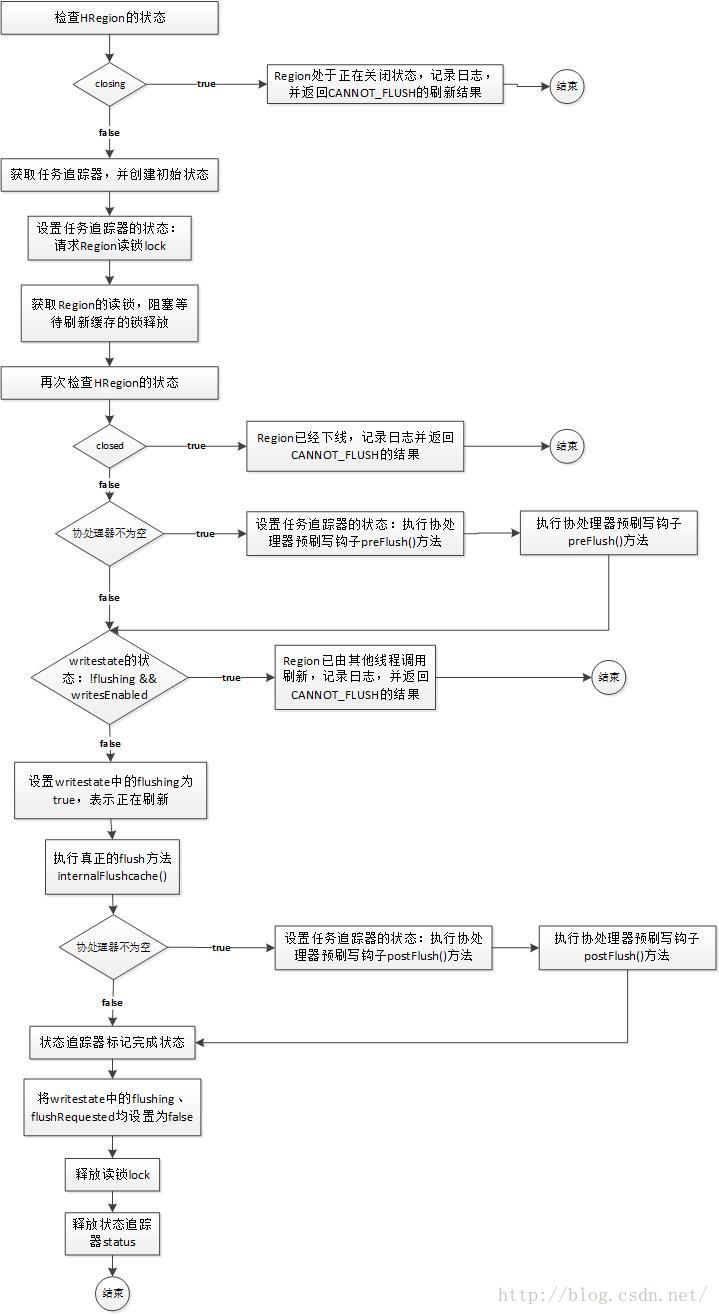
下面,我们看下HRegion上flushCache()方法,代码如下:
/**
* Flush the cache.
*
* When this method is called the cache will be flushed unless:
* <ol>
* <li>the cache is empty</li>
* <li>the region is closed.</li>
* <li>a flush is already in progress</li>
* <li>writes are disabled</li>
* </ol>
*
* <p>This method may block for some time, so it should not be called from a
* time-sensitive thread.
* 这个方法可能会阻塞一段时间,所以对时间敏感的线程不应该调用该方法。
*
* @return true if the region needs compacting
*
* @throws IOException general io exceptions
* @throws DroppedSnapshotException Thrown when replay of wal is required
* because a Snapshot was not properly persisted. The region is put in closing mode, and the
* caller MUST abort after this.
*/
public FlushResult flushcache() throws IOException
// fail-fast instead of waiting on the lock
// 快速失败,而不是等待锁
// 如果Region正处于关闭状态,记录日志,并返回CANNOT_FLUSH的刷新结果
if (this.closing.get())
String msg = "Skipping flush on " + this + " because closing";
LOG.debug(msg);
return new FlushResult(FlushResult.Result.CANNOT_FLUSH, msg);
// 获取任务追踪器,并创建初始状态
MonitoredTask status = TaskMonitor.get().createStatus("Flushing " + this);
// 设置任务追踪器的状态:请求Region读锁
status.setStatus("Acquiring readlock on region");
// block waiting for the lock for flushing cache
// 获取Region的读锁,阻塞等待刷新缓存的锁释放
/**
* 我的理解,这个lock锁好像是Region行为上的一个读写锁,加上这个锁,控制Region的整体行为,比如flush、compact、close等,
* flush和compact使用的是读锁,是一个共享锁,意味着flush和compact可以同步进行,但是不能执行close,因为close是写锁,
* 它是一个独占锁,一旦它占用锁,其他线程就不能发起flush、compact等操作,当然,close线程本身除外,因为Region在下线前要保证
* MemStore内的数据被flush到文件。
*/
lock.readLock().lock();
try
// 如果Region已经下线,记录日志并返回CANNOT_FLUSH的结果
if (this.closed.get())
String msg = "Skipping flush on " + this + " because closed";
LOG.debug(msg);
status.abort(msg);
return new FlushResult(FlushResult.Result.CANNOT_FLUSH, msg);
// 如果协处理器不为空
if (coprocessorHost != null)
// 设置任务追踪器的状态:执行协处理器预刷写钩子preFlush()方法
status.setStatus("Running coprocessor pre-flush hooks");
// 执行协处理器预刷写钩子preFlush()方法
coprocessorHost.preFlush();
if (numMutationsWithoutWAL.get() > 0)
numMutationsWithoutWAL.set(0);
dataInMemoryWithoutWAL.set(0);
synchronized (writestate)
if (!writestate.flushing && writestate.writesEnabled)
// 如果writestate不是flushing,且writestate的可以读取启用,将状态中的flushing设置为true,表示正在刷新
this.writestate.flushing = true;
else
// 否则记录日志,并返回CANNOT_FLUSH的结果
if (LOG.isDebugEnabled())
LOG.debug("NOT flushing memstore for region " + this
+ ", flushing=" + writestate.flushing + ", writesEnabled="
+ writestate.writesEnabled);
String msg = "Not flushing since "
+ (writestate.flushing ? "already flushing"
: "writes not enabled");
status.abort(msg);
return new FlushResult(FlushResult.Result.CANNOT_FLUSH, msg);
try
// 执行真正的flush
FlushResult fs = internalFlushcache(status);
// 刷新结束后,如果协处理器不为空,执行协处理器的钩子方法postFlush()
if (coprocessorHost != null)
status.setStatus("Running post-flush coprocessor hooks");
coprocessorHost.postFlush();
// 状态追踪器标记完成状态
status.markComplete("Flush successful");
// 返回刷新结果
return fs;
finally
synchronized (writestate)
// 将writestate中的flushing、flushRequested均设置为false
writestate.flushing = false;
this.writestate.flushRequested = false;
writestate.notifyAll();
finally
// 释放读锁
lock.readLock().unlock();
// 清空状态
status.cleanup();
1、首先需要判断下HRegion的状态,如果Region正处于关闭状态,记录日志,并返回CANNOT_FLUSH的刷新结果;
ps:这是大数据诸多框架,比如HDFS、HBase、Spark等绝大多数内部处理流程采取的一种通用的模式,判断涉及到的实体,比如HRegion、DataNode、DataXceiveServer等的状态,比如正在关闭closing、已经关闭closed等,目的是协调各实体协同工作,保障本处理流程是真实有效的。
2、获取任务追踪器,并创建初始状态:Flushing ****HRegion,初始化后的状态对象为MonitoredTask类型的status;
3、设置任务追踪器的状态:请求Region读锁:Acquiring readlock on region;
4、获取Region的读锁,阻塞等待刷新缓存的锁释放;
5、再次判断HRegion的状态,如果Region已经下线,记录日志并返回CANNOT_FLUSH的结果;
6、如果协处理器不为空:
6.1、设置任务追踪器的状态:执行协处理器预刷写钩子preFlush()方法:Running coprocessor pre-flush hooks;
6.2、执行协处理器预刷写钩子preFlush()方法;
7、如果writestate不是flushing,且writestate的可以读取启用,将状态中的flushing设置为true,表示正在刷新,否则记录日志,并返回CANNOT_FLUSH的结果;
8、调用internalFlushcache()方法,执行真正的flush;
9、刷新结束后,如果协处理器不为空,设置状态,即Running post-flush coprocessor hooks,并执行协处理器的钩子方法postFlush();
10、状态追踪器标记完成状态:Flush successful;
11、将writestate中的flushing、flushRequested均设置为false;
12、释放读锁,并清空状态追踪器的状态;
13、返回刷新结果。
至此,HRegion上MemStore的flush流程全部完毕,其中internalFlushcache()是其真正执行flush的核心方法,关于这部分我们将在下一篇文章中讲解。在此,只是概括下外围的整体流程。
关于上述流程,有以下几点需要单独说明下:
1、关于closing和closed标志位状态的判断
HRegion中,有两个关于关闭的状态标志位成员变量,分别定义如下:
final AtomicBoolean closed = new AtomicBoolean(false);
final AtomicBoolean closing = new AtomicBoolean(false);为什么需要两个状态标志位呢?我么知道,Region下线关闭时,需要处理一些诸如flush等的操作,所以一般比较耗时,那么在其下线关闭期间,我们不希望该Region再执行flsuh、compact等请求,所以,我们就需要两个标志位,一个表示正在关闭过程的closing,另外一个是已经关闭的closed。所以,flush、compact等流程的执行,都会去判断这两个状态位,确保flush和compact允许被执行。
2、关于读写锁的使用
HRegion中,保持了两把锁,分别定义如下:
// Used to guard closes 用于保护关闭
final ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
// Stop updates lock 停止更新锁
private final ReentrantReadWriteLock updatesLock = new ReentrantReadWriteLock();这两个锁均为ReentrantReadWriteLock类型的读写锁,其中,lock用于Region的close、compact、flush等的并发控制,它控制的是Region的整体行为,更具体的,compact()和flushCache()方法中,用的是lock的读锁--共享锁,而doClose()方法中,用的是lock的写锁--独占锁,这也就意味着,在Region下线,执行doClose()方法时,它必须等待compact()和flushCache()方法调用完,且一旦它获得了lock的写锁,后续Region将不会再执行Region的compact和flush,当然,doClose()内部仍然会在下线前flush掉它的memstore,同时共享锁业也实现了Region的flush和compact在理论上可以同时进行。而updatesLock则用于Region数据更新方面,在flush的核心方法internalFlushcache()中,则是使用的updatesLock的写锁。
3、关于写状态WriteState的使用
再来说下HRegion的另外一个成员变量writestate,它是HRegion的内部类WriteState类型的,这个类是一种协调刷新、合并与关闭操作的非常使用的数据结构。它的关键成员变量定义如下:
// Set while a memstore flush is happening.
// 当一个memstore刷新发生时设置
volatile boolean flushing = false;
// Set when a flush has been requested.
// 当一个刷新请求发生时设置
volatile boolean flushRequested = false;
// Number of compactions running.
// 合并进行的数目
volatile int compacting = 0;
// Gets set in close. If set, cannot compact or flush again.
// 如果被设置,将不再支持合并与刷新
volatile boolean writesEnabled = true;
// Set if region is read-only
// 如果Region只读时设置
volatile boolean readOnly = false;
// whether the reads are enabled. This is different than readOnly, because readOnly is
// static in the lifetime of the region, while readsEnabled is dynamic
// 读取是否启用。这是不同于只读的,因为只读是一生静态的,而readsEnabled是动态的
volatile boolean readsEnabled = true;其中,当一个flush发生或者正在进行时,flushing会被设置为true,而当一个flush请求发生时,flushRequested被设置为true。另外,还包含了合并进行的数目compatcing、可写状态writesEnabled、可读状态readsEnabled和只读状态readOnly等。
为什么要用这么一个数据结构来表示Region的状态呢?我们知道,HRegion代表了HBase表中按行切分的区域,在HRegion上,可能存在flush、compact等多种操作,使用单一的操作并不能很好的表达出HRegion的状态,所以作者构思出这么一个数据结构,协调fulsh、compact及其HRegion读写等状态。
好了,期待下一篇关于flush核心流程的介绍吧!
以上是关于HBase源码分析之HRegion上MemStore的flsuh流程的主要内容,如果未能解决你的问题,请参考以下文章