kaggle (自杀分析)
Posted 刘润森!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kaggle (自杀分析)相关的知识,希望对你有一定的参考价值。
今天无聊又看看kaggle ,看中了一个自杀分析数据集
通道地址:
https://www.kaggle.com/russellyates88/suicide-rates-overview-1985-to-2016
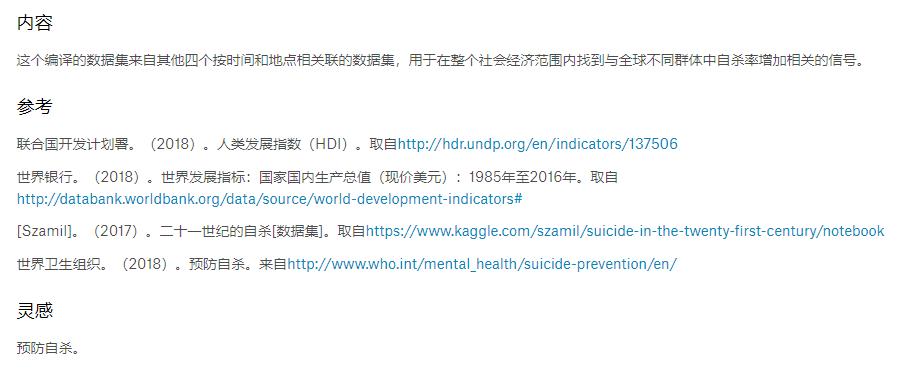

看来这个是大家都看过的数据集
来来,刷起来
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
%pylab inline
data = pd.read_csv('../input/suicide-rates-overview-1985-to-2016/master.csv')
data = data.drop(['country-year','HDI for year'],axis=1)
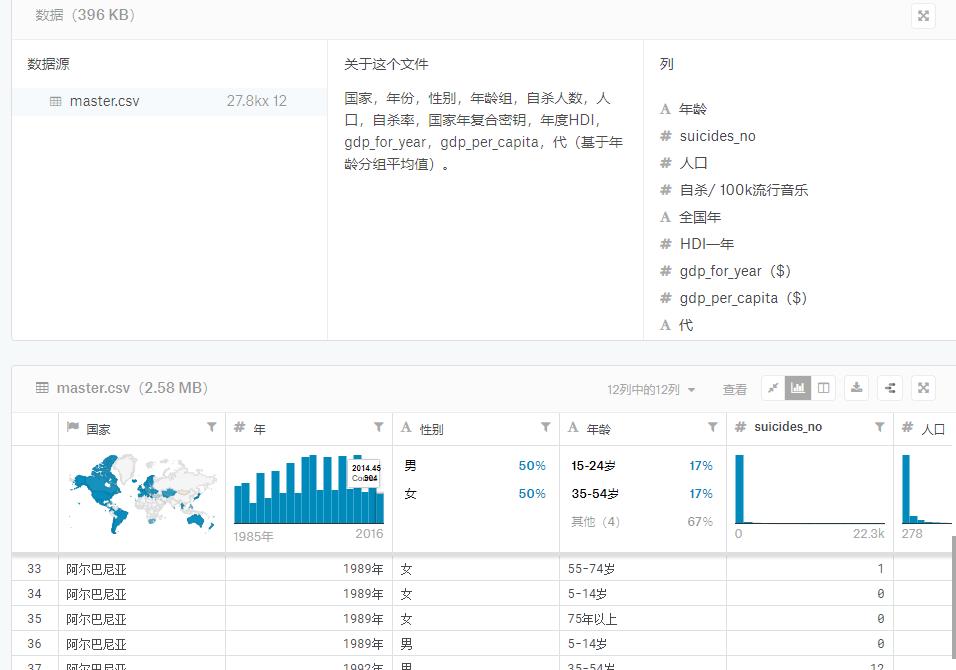
print(data.shape)
data.head()
(27820, 10)

data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 27820 entries, 0 to 27819
Data columns (total 10 columns):
country 27820 non-null object
year 27820 non-null int64
sex 27820 non-null object
age 27820 non-null object
suicides_no 27820 non-null int64
population 27820 non-null int64
suicides/100k pop 27820 non-null float64
gdp_for_year ($) 27820 non-null object
gdp_per_capita ($) 27820 non-null int64
generation 27820 non-null object
dtypes: float64(1), int64(4), object(5)
memory usage: 2.1+ MB
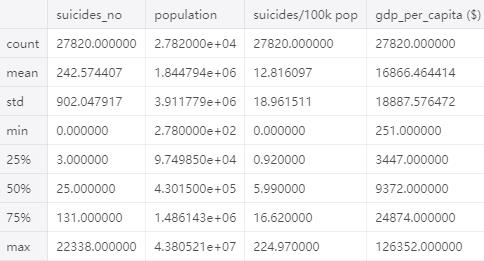
data[['suicides_no','population','suicides/100k pop','gdp_per_capita ($)']].describe()
我觉得好这是最好的数据分析 (还增加的数据集来在地图中展示)
在这里,您可以看到此数据集中缺少国家的地图。这是一个重要的信息,我们可以认为这些国家的自杀情况很糟糕。
应该注意,我们的数据集是偏移的,并不是完全客观的
from IPython.display import Image
Image('../input/country/missed countries.png')

31年的自杀人数。请注意,并非所有国家都包括在此列表中!这是非常重要的。
suic_sum = pd.DataFrame(data['suicides_no'].groupby(data['country']).sum())
suic_sum = suic_sum.reset_index().sort_index(by='suicides_no',ascending=False)
most_cont = suic_sum.head(8)
fig = plt.figure(figsize=(20,10))
plt.title('Count of suicides for 31 years.')
sns.set(font_scale=2)
sns.barplot(y='suicides_no',x='country',data=most_cont,palette="Blues_d")
plt.xticks(rotation=45)
plt.ylabel('');
plt.xlabel('')
plt.tight_layout()

from mpl_toolkits.basemap import Basemap
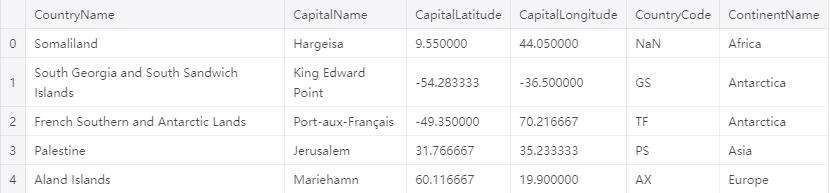
concap = pd.read_csv('../input/world-capitals-gps/concap.csv')
concap.head()
def reg(x):
if x=='Russia':
res = 'Russian Federation'
else:
res=x
return res
concap['CountryName'] = concap['CountryName'].apply(reg)
data_full = pd.merge(concap[['CountryName', 'CapitalName', 'CapitalLatitude', 'CapitalLongitude']],\\
suic_sum,left_on='CountryName',right_on='country')
在地图上考虑一下。我要提醒你,许多大(按人口)国家不包括在这个数据集中。
def mapWorld(col1,size2,title3,label4,metr=100,colmap='hot'):
m = Basemap(projection='mill',llcrnrlat=-60,urcrnrlat=70,\\
llcrnrlon=-110,urcrnrlon=180,resolution='c')
m.drawcoastlines()
m.drawcountries()
m.drawparallels(np.arange(-90,91.,30.))
m.drawmeridians(np.arange(-90,90.,60.))
lat = data_full['CapitalLatitude'].values
lon = data_full['CapitalLongitude'].values
a_1 = data_full[col1].values
if size2:
a_2 = data_full[size2].values
else: a_2 = 1
m.scatter(lon, lat, latlon=True,c=a_1,s=metr*a_2,linewidth=1,edgecolors='black',cmap=colmap, alpha=1)
cbar = m.colorbar()
cbar.set_label(label4,fontsize=30)
plt.title(title3, fontsize=30)
plt.show()
sns.set(font_scale=1.5)
plt.figure(figsize=(15,15))
mapWorld(col1='suicides_no', size2=False,title3='Suicide count',label4='',metr=300,colmap='viridis')
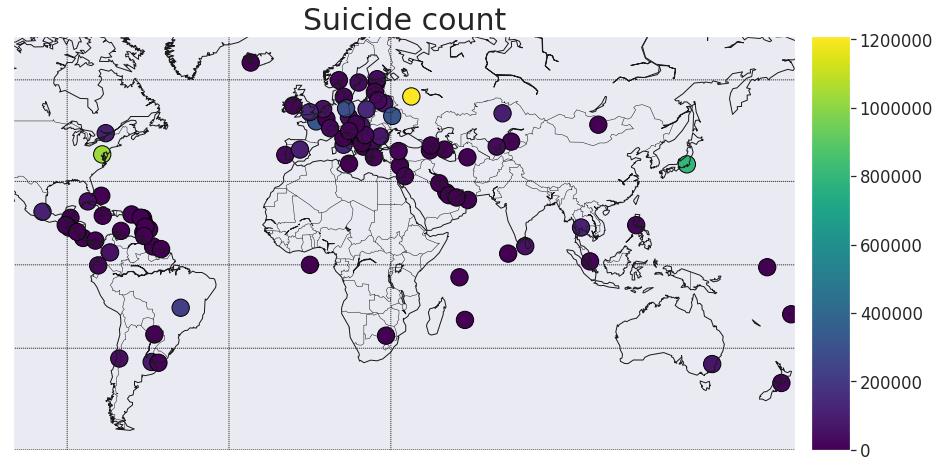
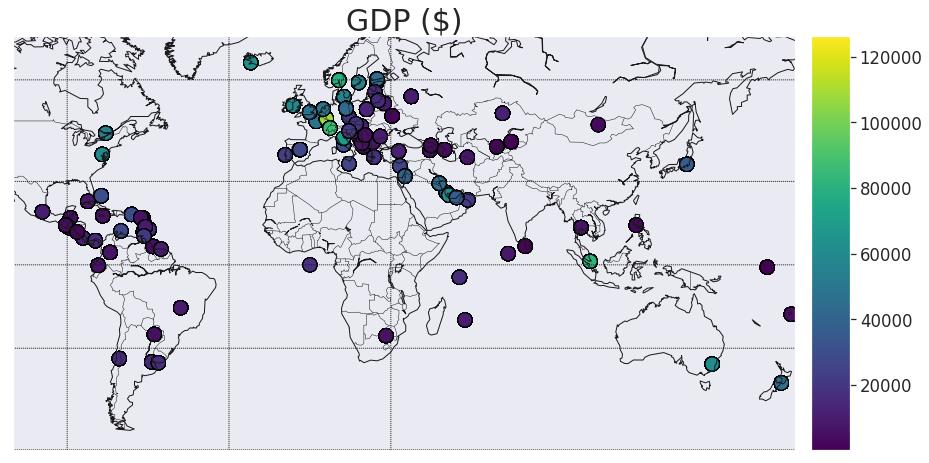
与地图比较-人均GDP(美元)
data_full = pd.merge(concap[['CountryName', 'CapitalName', 'CapitalLatitude', 'CapitalLongitude']],\\
data,left_on='CountryName',right_on='country')
plt.figure(figsize=(15,15))
mapWorld(col1='gdp_per_capita ($)', size2=False,title3='GDP ($)',label4='',metr=200,colmap='viridis')
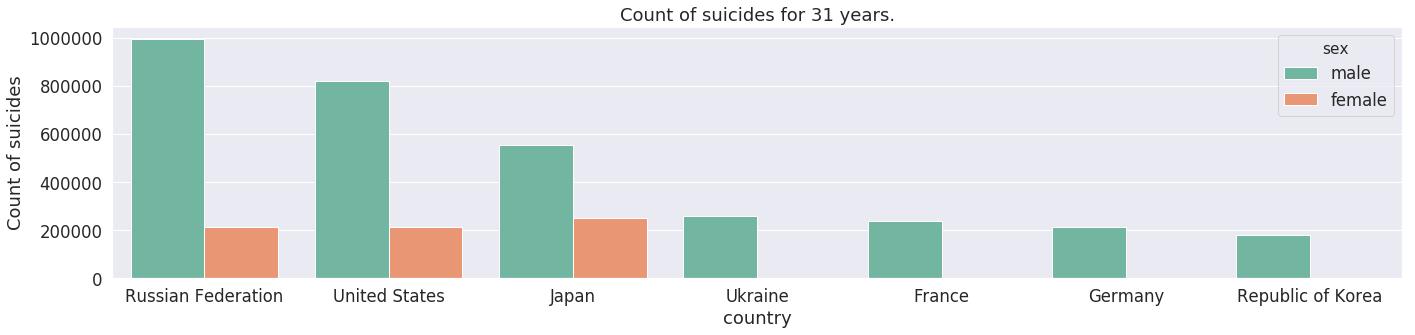
考虑具有性别差异的相同条形图:
suic_sum_m = data['suicides_no'].groupby([data['country'],data['sex']]).sum()
suic_sum_m = suic_sum_m.reset_index().sort_index(by='suicides_no',ascending=False)
most_cont_m = suic_sum_m.head(10)
most_cont_m.head(10)
fig = plt.figure(figsize=(20,5))
plt.title('Count of suicides for 31 years.')
sns.set(font_scale=1.5)
sns.barplot(y='suicides_no',x='country',hue='sex',data=most_cont_m,palette='Set2');
plt.ylabel('Count of suicides')
plt.tight_layout()
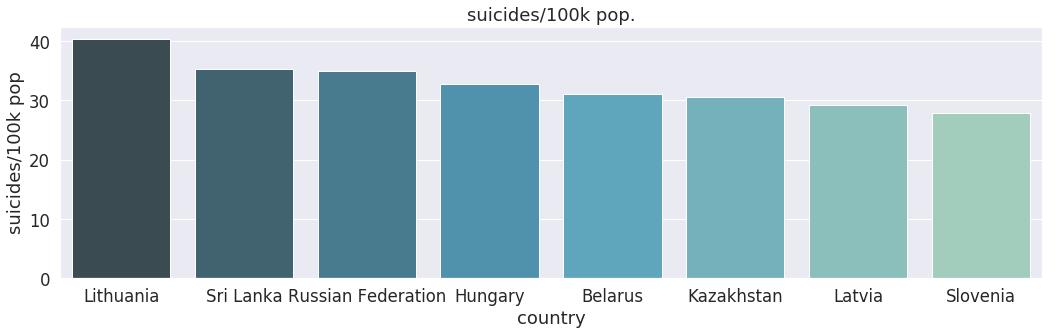
将此与统计数据进行比较-自杀/10万人。
suic_mean = pd.DataFrame(data['suicides/100k pop'].groupby(data['country']).mean())
suic_mean = suic_mean.reset_index()
suic_mean_most = suic_mean.sort_index(by='suicides/100k pop',ascending=False).head(8)
fig = plt.figure(figsize=(15,5))
plt.title('suicides/100k pop.')
#sns.set(font_scale=1.5)
sns.barplot(y='suicides/100k pop',x='country',data=suic_mean_most,palette="GnBu_d");
plt.ylabel('suicides/100k pop')
plt.tight_layout()
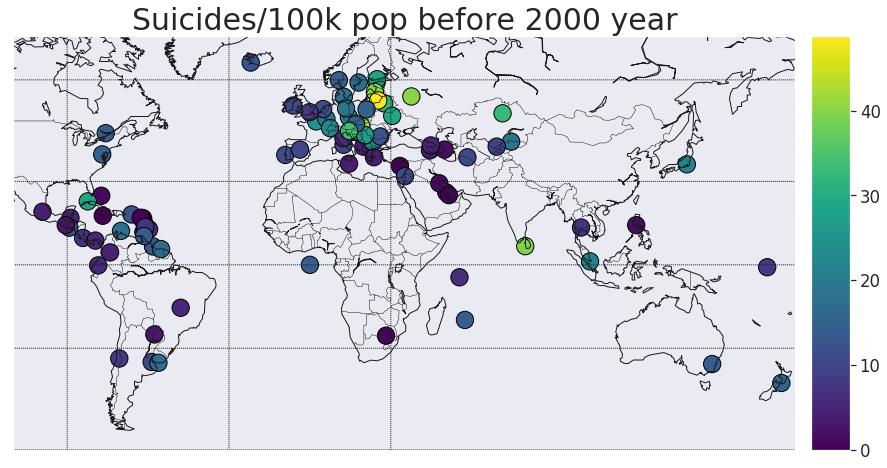
让我们将数据分为旧数据和新数据:
data_past = data[data['year']<2000]
suic_mean = pd.DataFrame(data_past['suicides/100k pop'].groupby(data_past['country']).mean())
suic_mean = suic_mean.reset_index()
data_full = pd.merge(concap[['CountryName', 'CapitalName', 'CapitalLatitude', 'CapitalLongitude']],\\
suic_mean,left_on='CountryName',right_on='country')
plt.figure(figsize=(15,15))
mapWorld(col1='suicides/100k pop', size2=False,title3='Suicides/100k pop before 2000 year',label4='',metr=300,colmap='viridis')
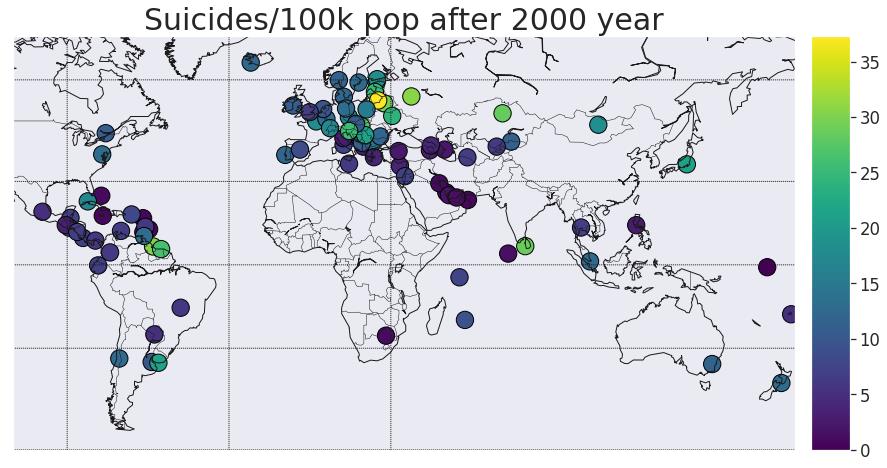
data_last = data[data['year'] > 2000]
suic_mean = pd.DataFrame(data_last['suicides/100k pop'].groupby(data_last['country']).mean())
suic_mean = suic_mean.reset_index()
data_full = pd.merge(concap[['CountryName', 'CapitalName', 'CapitalLatitude', 'CapitalLongitude']],\\
suic_mean,left_on='CountryName',right_on='country')
plt.figure(figsize=(15,15))
mapWorld(col1='suicides/100k pop', size2=False,title3='Suicides/100k pop after 2000 year',label4='',metr=300,colmap='viridis')
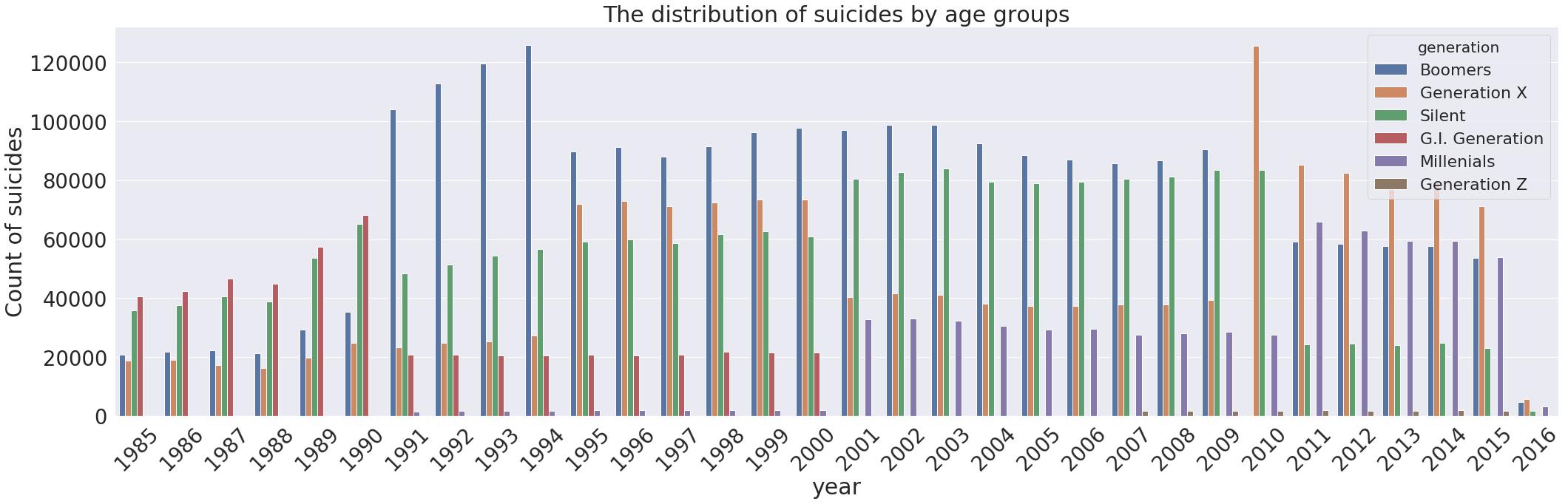
在这里,我们可以看到按年份分布的自杀人数:
suic_sum_yr = pd.DataFrame(data['suicides_no'].groupby(data['year']).sum())
suic_sum_yr = suic_sum_yr.reset_index().sort_index(by='suicides_no',ascending=False)
most_cont_yr = suic_sum_yr
fig = plt.figure(figsize=(30,10))
plt.title('Count of suicides for years.')
sns.set(font_scale=2.5)
sns.barplot(y='suicides_no',x='year',data=most_cont_yr,palette="OrRd");
plt.ylabel('Count of suicides')
plt.xlabel('')
plt.xticks(rotation=45)
plt.tight_layout()

什么是最多的年龄?
suic_sum_yr = pd.DataFrame(data['suicides_no'].groupby([data['generation'],data['year']]).sum())
suic_sum_yr = suic_sum_yr.reset_index().sort_index(by='suicides_no',ascending=False)
most_cont_yr = suic_sum_yr
fig = plt.figure(figsize=(30,10))
plt.title('The distribution of suicides by age groups')
sns.set(font_scale=2)
sns.barplot(y='suicides_no',x='year',hue='generation',data=most_cont_yr,palette='deep');
plt.ylabel('Count of suicides')
plt.xticks(rotation=45)
plt.tight_layout()
data_new = data[data['year']<2000]
title_map = 'Generation suicides before 2000 year'
data_gener = pd.DataFrame(data_new['suicides_no'].groupby([data_new['generation'],data_new['country']]).sum()).reset_index()
age_max = pd.DataFrame(data_gener['suicides_no'].groupby(data_gener['country']).max()).reset_index()
gen_full = pd.merge(age_max,data_gener,left_on=['suicides_no','country'],right_on=['suicides_no','country'])
data_full = pd.merge(concap[['CountryName', 'CapitalName', 'CapitalLatitude', 'CapitalLongitude']],\\
gen_full,left_on='CountryName',right_on='country')
data_full.dropna(inplace=True)
def gener(x):
dic_t = 'Generation X':100,'Silent':200,'G.I. Generation':300,'Boomers':400,'Millenials':500,'Generation Z':600
return dic_t[x]
data_full.generation = data_full.generation.apply(gener)
print(" Generation X:100 \\n Silent:200 \\n G.I. Generation:300 \\n Boomers:400 \\n Millenials:500 \\n Generation Z:600")
plt.figure(figsize=(15,15))
mapWorld(col1='generation', size2='suicides_no', title3=title_map,label4='',metr=0.01,colmap='viridis')
Generation X:100
Silent:200
G.I. Generation:300
Boomers:400
Millenials:500
Generation Z:600
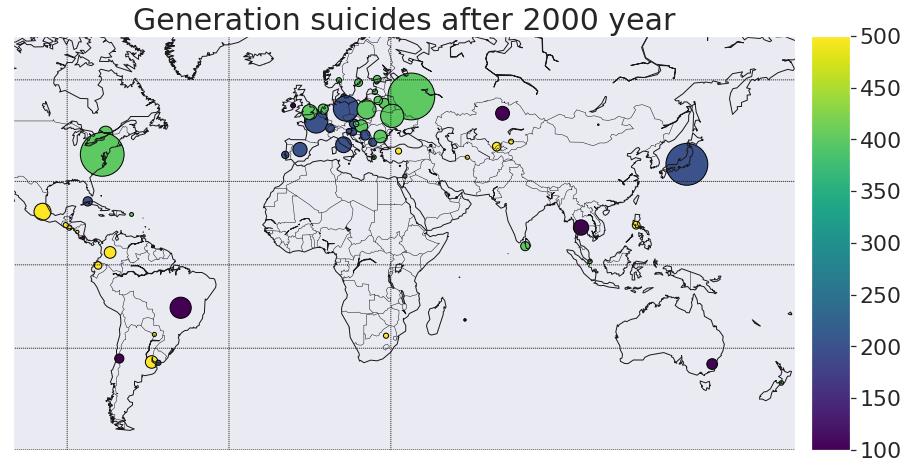
data_new = data[data['year']>=2000]
title_map = 'Generation suicides after 2000 year'
data_gener = pd.DataFrame(data_new['suicides_no'].groupby([data_new['generation'],data_new['country']]).sum()).reset_index()
age_max = pd.DataFrame(data_gener['suicides_no'].groupby(data_gener['country']).max()).reset_index()
gen_full = pd.merge(age_max,data_gener,left_on=['suicides_no','country'],right_on=['suicides_no','country'])
data_full = pd.merge(concap[['CountryName', 'CapitalName', 'CapitalLatitude', 'CapitalLongitude']],\\
gen_full,left_on='CountryName',right_on='country')
data_full.dropna(inplace=True)
def gener(x):
dic_t = 'Generation X':100,'Silent':200,'G.I. Generation':300,'Boomers':400,'Millenials':500,'Generation Z':600
return dic_t[x]
data_full.generation = data_full.generation.apply(gener)
print(" Generation X:100 \\n Silent:200 \\n G.I. Generation:300 \\n Boomers:400 \\n Millenials:500 \\n Generation Z:600")
plt.figure(figsize=(15,15))
mapWorld(col1='generation', size2='suicides_no', title3=title_map,label4='',metr=0.01,colmap='viridis')

来源
俄罗斯的不到21岁的大佬,果断follow了

在kaggle 果然有很多牛人
以上是关于kaggle (自杀分析)的主要内容,如果未能解决你的问题,请参考以下文章