深入浅出SpringCloud原理及实战「Netflix系列之Hystrix」针对于限流熔断组件Hystrix的请求合并机制实现原理分析
Posted 洛神灬殇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入浅出SpringCloud原理及实战「Netflix系列之Hystrix」针对于限流熔断组件Hystrix的请求合并机制实现原理分析相关的知识,希望对你有一定的参考价值。
[每日一句]
也许你度过了很糟糕的一天,但这并不代表你会因此度过糟糕的一生。
[温馨提示]
承接上一篇文章🏹「【深入浅出SpringCloud原理及实战】「Netflix系列之Hystrix」针对于限流熔断组件Hystrix的Command创建和执行实现原理分析
-
在这里推荐给大家martinfowler的熔断器介绍和权威指南,有兴趣的小伙伴们可以研究一下哈。
-
主要介绍相关:官网说明
-
关于 【Hystrix如何运行的介绍】的介绍
[背景介绍]
-
分布式系统的规模和复杂度不断增加,随着而来的是对分布式系统可用性的要求越来越高。在各种高可用设计模式中,【熔断、隔离、降级、限流】是经常被使用的。而相关的技术,Hystrix本身早已算不上什么新技术,但它却是最经典的技术体系!。
-
Hystrix以实现熔断降级的设计,从而提高了系统的可用性。
-
Hystrix是一个在调用端上,实现断路器模式,以及隔舱模式,通过避免级联故障,提高系统容错能力,从而实现高可用设计的一个Java服务组件库。
-
Hystrix实现了资源隔离机制
请求合并的作用场景和原理
Hystrix请求合并用于应对服务器的高并发场景,通过合并请求,减少线程的创建和使用,降低服务器请求压力,提高在高并发场景下服务的吞吐量和并发能力
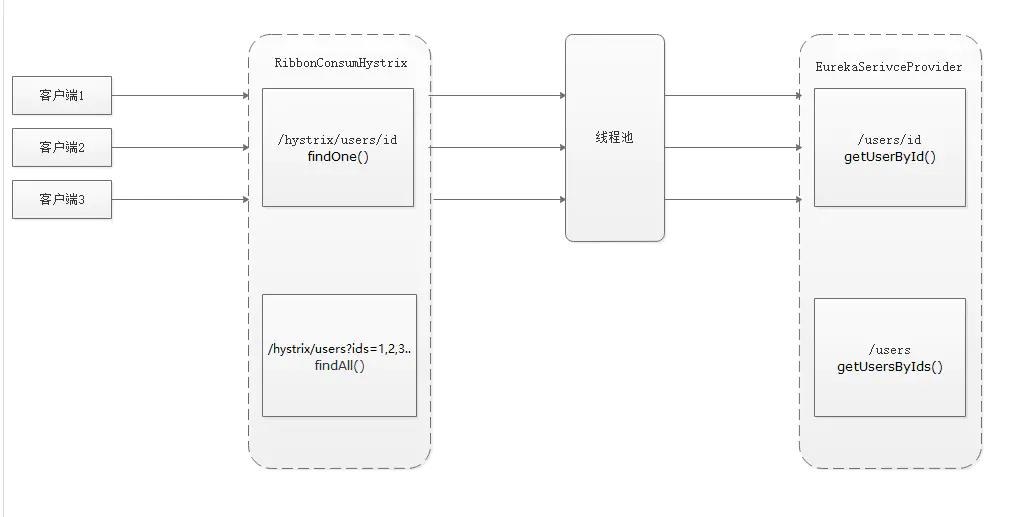
在正常的分布式请求中,客户端发送请求,服务器在接受请求后,向服务提供者发送请求获取数据,这种模式在高并发的场景下就会导致线程池有大量的线程处于等待状态,从而导致响应缓慢,同时线程池的资源也是有限的,每一个请求都分配一个资源,也是无谓的消耗了很多服务器资源,在这种场景下我们可以通过使用hystrix的请求合并来降低对提供者过多的访问,减少线程池资源的消耗,从而提高系统的吞吐量和响应速度。
如下图,采用请求合并后的服务模式
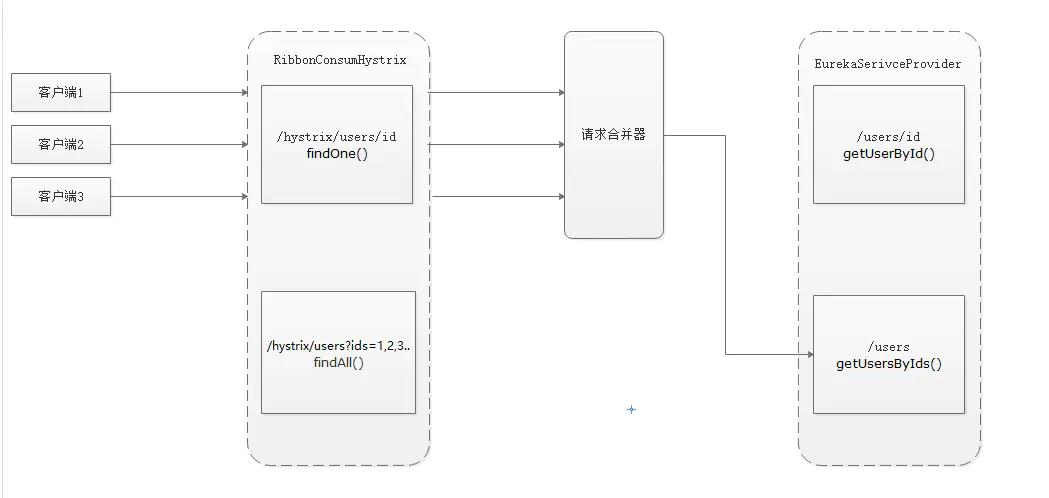
请求合并可以通过构建类和添加注解的方式实现,这里我们先说通过构建合并类的方式实现请求合并
-
请求合并的实现包含了两个主要实现类,一个是合并请求类,一个是批量处理类,合并请求类的作用是收集一定时间内的请求,将他们传递的参数汇总。
-
然后调用批量处理类,通过向服务调用者发送请求获取批量处理的结果数据,最后在对应的request方法体中依次封装获取的结果,并返回回去
请求合并
-
可以在HystrixCommand之前放置一个『请求合并器』(HystrixCollapser为请求合并器的抽象父类),该合并器可以将多个发往同一个后端依赖服务的请求合并成一个。
-
Hystrix请求合并用于应对服务器的高并发场景,通过合并请求,减少线程的创建和使用,降低服务器请求压力,提高在高并发场景下服务的吞吐量和并发能力
下图展示了在两种场景(未增加『请求合并器』和增加『请求合并器』)下,线程和网络连接数量(假设所有请求在一个很小的时间窗口内,例如 10ms,是『并发』的):
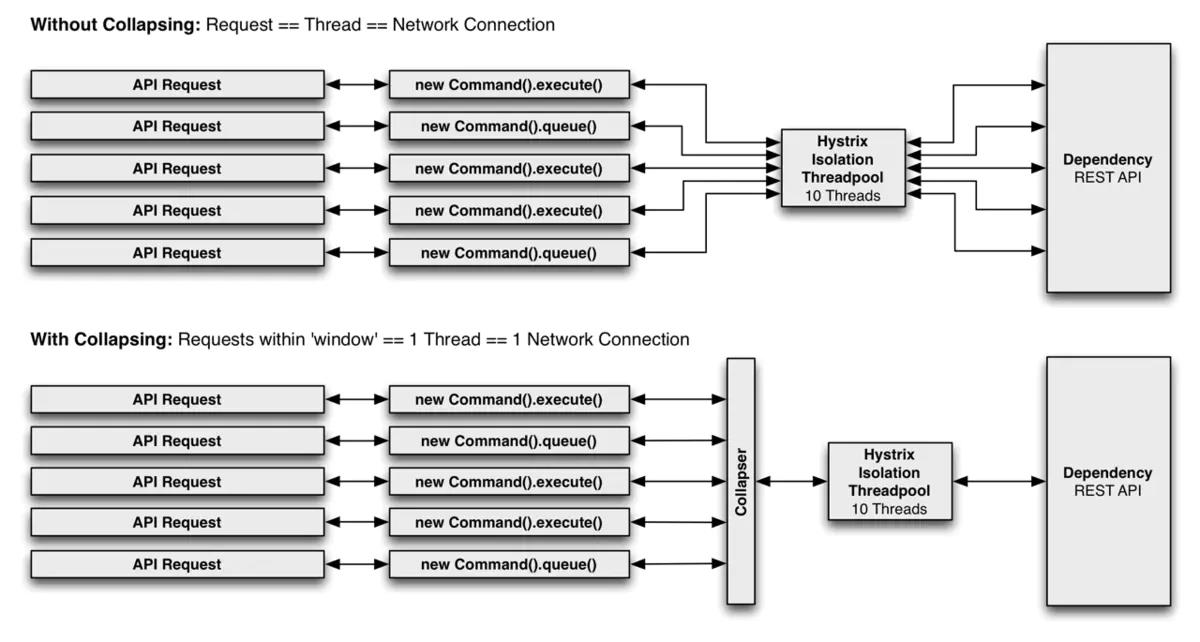
为什么要使用请求合并?
在并发执行HystrixCommand时,利用请求合并能减少线程和网络连接数量。
通过使用HystrixCollapser,Hystrix能自动完成请求的合并,开发者不需要对现有代码做批量化的开发。
全局上下文(适用于所有Tomcat线程)
理想情况下,合并过程应该发生在系统全局层面,这样用户发起的,由Tomcat线程执行的所有请求都能被执行合并操作。
例如,有这样一个需求,用户需要获取电影评级,而这些数据需要系统请求依赖服务来获取,对依赖服务的请求使用HystrixCommand进行包装,并增加了请求合并的配置,这样,当同一个JVM中其他线程需要执行同样的请求时,Hystrix会将这个请求同其他同样的请求合并,只产生一个网络请求。
注意:合并器会传递一个HystrixRequestContext对象到合并的网络请求中,因此,下游系统需要支持批量化,以使请求合并发挥其高效的特点。
用户请求上下文(适用于单个 Tomcat 线程)
如果给HystrixCommand只配置成针对单个用户进行请求合并,则 Hystrix 只会在单个 Tomcat 线程(即请求)中进行请求合并。
例如,如果用户想加载 300 个视频对象的书签,请求合并后,Hystrix 会将原本需要发起的 300 个网络请求合并到一个。
对象模型和代码复杂度
很多时候,当你创建一个对象模型,适用于对象的消费者逻辑,结果发现这个模型会导致生产者无法充分利用其拥有的资源。
例如,这里有一个包含300个视频对象的列表,需要遍历这个列表,并对每一个对象调用getSomeAttribute()方法,这是一个显而易见的对象模型,但如果简单处理的话,可能会导致300 次的网络请求(假设getSomeAttribute()方法内需要发出网络请求),每一个网络请求可能都会花上几毫秒(显然,这种方式非常容易拖慢系统)。
当然,你也可以要求用户在调用getSomeAttribute()之前,先判断一下哪些视频对象真正需要请求其属性。
你可以将对象模型进行拆分,从一个地方获取视频列表,然后从另一个地方获取视频的属性。
但这些实现会导致API非常丑陋,且实现的对象模型无法完全满足用户使用模式。 并且在企业级开发时,很容易因为开发者的疏忽导致错误或者不够高效,因为不同的开发者可能有不同的请求方式,这样一个地方的优化不足以保证在所有地方都会有优化。
通过将合并逻辑下沉到Hystrix层,不管你如何设计对象模型,或者以何种方式去调用依赖服务,又或者开发者是否意识到这些逻辑需要不需要进行优化,这些都不需要考虑,因为Hystrix能统一处理。
getSomeAttribute()方法能放在它最适合的位置,并且能以最适合的方式被调用,Hystrix 的请求合并器会自动将请求合并到合并时间窗口内。
请求合并带来的额外开销
请求合并会导致依赖服务的请求延迟增高(该延迟为等待请求的延迟),延迟的最大值为合并时间窗口大小。
若某个请求耗时的中位数是 5ms,合并时间窗口为 10ms,那么在最坏情况下(注:合并时间窗口开启时发起请求),请求需要消耗 15ms 才能完成。通常情况下,请求不太可能恰好在合并时间窗口开启时发起,因此,请求合并带来的额外开销应该是合并时间窗口的一般,在此例中是 5ms。
请求合并带来的额外开销是否值得,取决于将要执行的命令,高延迟的命令相比较而言不会有太大的影响。同时,缓存 Key 的选择也决定了在一个合并时间窗口内能『并发』执行的命令数量:如果一个合并时间窗口内只有 1~2 个请求,将请求合并显然不是明智的选择。
事实上,如果单线程循环调用同一个依赖服务的情况下,如果将请求合并,会导致这个循环成为系统性能的瓶颈,因为每一个请求都需要等待 10ms 的合并时间周期。
然而,如果一个命令具有高并发度,并且能批量处理多个,甚至上百个的话,请求合并带来的性能开销会因为吞吐量的极大提升而基本可以忽略,因为 Hystrix 会减少这些请求所需的线程和网络连接数量。
请求合并器的执行流程
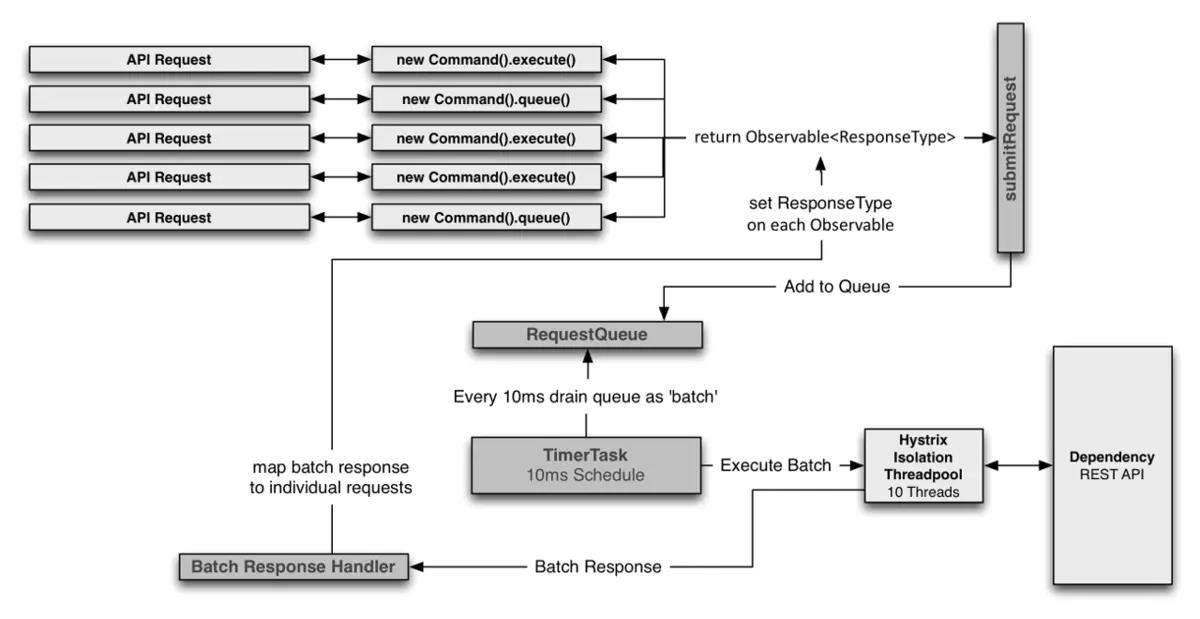
请求合并类的具体实现
public class UserCollapseCommand extends
HystrixCollapser<List<UserInfo>,UserInfo,Integer>
private CacheServiceImpl service;
private Integer userId;
/**
* 构造方法,主要是用来设置合并器的时间,多长时间合并一次请求
* @param cacheService 调用的服务
* @param userId 单次需要传递的业务id
*/
public UserCollapseCommand(CacheServiceImpl cacheService, Integer
userId)
super(Setter.withCollapserKey(HystrixCollapserKey.Factory.asKey("userCollapseCommand")).
andCollapserPropertiesDefaults(HystrixCollapserProperties.Setter().withTimerDelayInMilliseconds(100)));
this.service = cacheService;
this.userId = userId;
@Override
public Integer getRequestArgument()
return userId;
/**
* 获取传入的业务参数集合,调用执行方法执行批量请求
* @param collapsedRequests
* @return
*/
@Override
protected HystrixCommand<List<UserInfo>> createCommand(Collection<CollapsedRequest<UserInfo, Integer>> collapsedRequests)
System.out.println("HystrixCommandHystrixCommand========>");
//按请求数声名UserId的集合
List<Integer> userIds = new ArrayList<>(collapsedRequests.size());
//通过请求将100毫秒中的请求参数取出来装进集合中
userIds.addAll(collapsedRequests.stream().map(CollapsedRequest::getArgument).collect(Collectors.toList()));
//返回UserBatchCommand对象,自动执行UserBatchCommand的run方法
HystrixCommand<List<UserInfo>> a=new UserBatchCommand(service, userIds);
return a;
/**
* 返回请求的执行结果,并根据对应的request将结果返回到对应的request相应体中
* 通过循环所有被合并的请求依次从批处理的结果集中获取对应的结果
* @param userInfos 这里是批处理后返回的结果集
* @param collection 所有被合并的请求
*/
@Override
protected void mapResponseToRequests(List<UserInfo> userInfos, Collection<CollapsedRequest<UserInfo, Integer>> collection)
int count = 0 ;
for(CollapsedRequest<UserInfo,Integer> collapsedRequest : collection)
//从批响应集合中按顺序取出结果
UserInfo user = userInfos.get(count++);
//将结果放回原Request的响应体内
collapsedRequest.setResponse(user);
-
通过创建构造方法来设置合并器的收集时间,也就是合并器一次收集客户端请求的时间是多久
-
然后通过收集请求器获取在这段时间内收集的所有请求参数,在传递给批量执行程序去批量执行,
-
mapResponseToRequests方法获取返回的结果,并根据对应的request请求将结果返回到对应的request请求中
批量处理类
public class UserBatchCommand extends HystrixCommand<List<UserInfo>>
private static final Logger LOGGER = LoggerFactory.getLogger(UserBatchCommand.class);
private CacheServiceImpl service;
private List<Integer> ids;
public UserBatchCommand(CacheServiceImpl cacheService, List<Integer> ids)
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("ExampleGroup")).
andCommandKey(HystrixCommandKey.Factory.asKey("GetValueForKey")));
this.service =cacheService ;
this.ids = ids;
/**
* 调用批量处理的方法
* @return
*/
@Override
protected List<UserInfo> run()
List<UserInfo> users = service.findAll(ids);
return users;
/**
* Fallback回调方法,如果没有会报错
*/
@Override
protected List<UserInfo> getFallback()
System.out.println("UserBatchCommand的run方法,调用失败");
return null;
API调用实现请求合并
/**
- 模拟合并请求测试(非注解)
- 这里通过
*/
@GetMapping("/collapse")
public void collapseTest()
System.out.println("==========>collapseTest方法执行了");
HystrixRequestContext context = HystrixRequestContext.initializeContext();
try
Future<UserInfo> f1 = new UserCollapseCommand(cacheService, 1).queue();
Future<UserInfo> f2 = new UserCollapseCommand(cacheService, 2).queue();
Future<UserInfo> f3 = new UserCollapseCommand(cacheService, 3).queue();
Thread.sleep(3000);
Future<UserInfo> f4 = new UserCollapseCommand(cacheService, 5).queue();
Future<UserInfo> f5 = new UserCollapseCommand(cacheService, 6).queue();
UserInfo u1 = f1.get();
UserInfo u2 = f2.get();
UserInfo u3 = f3.get();
UserInfo u4 = f4.get();
UserInfo u5 = f5.get();
System.out.println(u1.getName());
System.out.println(u2.getName());
System.out.println(u3.getName());
System.out.println(u4.getName());
System.out.println(u5.getName());
catch (Exception e)
e.printStackTrace();
finally
context.close();
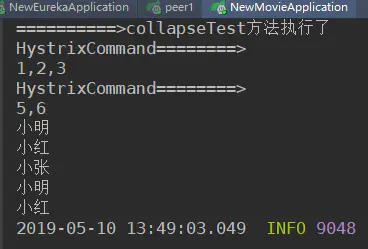
请求结果
以上是关于深入浅出SpringCloud原理及实战「Netflix系列之Hystrix」针对于限流熔断组件Hystrix的请求合并机制实现原理分析的主要内容,如果未能解决你的问题,请参考以下文章