SMILEtrack:基于相似度学习的多目标跟踪
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SMILEtrack:基于相似度学习的多目标跟踪相关的知识,希望对你有一定的参考价值。
文章目录
摘要
论文链接:https://arxiv.org/pdf/2211.08824.pdf
多目标跟踪(MOT)在计算机视觉领域有着广泛的应用。基于检测的跟踪(TBD)是一种流行的多目标跟踪范式。TBD由第一步的目标检测、随后的数据关联、轨迹生成和更新组成。本文提出一种基于孪生网络的相似性学习模块(SLM)来提取重要的目标外观特征,并提出一种将目标运动和外观特征有效结合的方法。该设计加强了对物体运动和外观特征的建模,用于数据关联。设计了一种相似性匹配级联(SMC)用于SMILEtrack跟踪器的数据关联。SMILEtrack在MOTChallenge和MOT17测试集上分别取得了81.06 MOTA和80.5 IDF1的成绩。

1、简介
MOT是计算机视觉领域的一个研究热点,在视频理解中起着至关重要的作用。MOT的目标是估计每个目标的轨迹,并尝试将它们与视频序列中的每一帧关联起来。随着MOT的成功,它可以在社会上普遍使用,如车辆计算、计算机交互[25][12]、智能视频分析、自动驾驶等。基于TBD (Tracking-By-Detection)范式的多目标跟踪策略[1]、[27]、[26]是近年来主流且高效的多目标跟踪策略。根据检测结果进行跟踪,将问题分解为检测和关联两个步骤。在检测步骤中,我们需要在单个视频帧中定位感兴趣的目标,将每个目标链接到现有的轨迹,或在关联步骤中创建新的轨迹。然而,由于目标模糊、遮挡、场景复杂等问题,该方法仍然面临挑战。
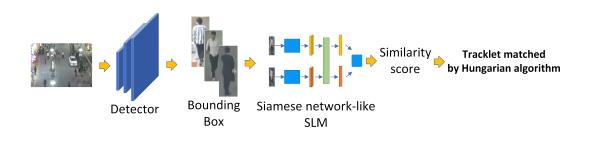
图1 SMILEtrack的流程图。SMILEtrack是一种类似孪生网络的架构,用于学习对象特征。
为实现跟踪系统,求解模型可分为独立检测与嵌入模型(SDE)和联合检测与嵌入模型(JDE)。该方法属于SDE;架构如图1所示。SDE至少需要两个功能组件:一个检测器和一个再识别模型。首先,检测器通过边界框在单帧中定位所有物体。然后,再识别模型将从每个边界框中提取物体的特征以生成嵌入。最后,将每个边界框关联到一个现有轨迹或创建一个新的轨迹。然而,SDE方法在使用两个独立的模型进行物体检测和嵌入提取时需要多次计算,因此无法达到实时推理速度。由于检测器和重识别模型之间的特征不能共享,SDE方法在推理时需要将重识别模型应用于每个包围盒以提取嵌入。面对这一问题,一种可行的解决方案是将检测器与重识别模型相结合。JDE类别[26][32]在单次深度网络中结合了检测器和嵌入模型。只需对模型进行一次推理,即可同时输出检测结果和被检测框对应的外观嵌入。
尽管JDE的成功使得MOT任务取得了很好的精度结果,但我们认为JDE仍然存在一些问题。例如,不同组件之间的功能冲突。我们认为目标检测任务和目标再识别任务所需要的特征是完全不同的。用于目标检测任务的特征需要高层特征来识别目标属于哪个类别,而用于再识别任务的特征则需要更多的低层特征来区分同一类别的不同实例。因此,JDE中的共享特征模型会降低任务的性能。然而,正如我们前面提到的JDE的缺点,SDE可以克服这些缺点,在MOT方面仍然有很好的潜力。
近年来,基于注意力机制[24]的Transformer[24]被引入计算机视觉领域,并取得了优异的效果。在MOT问题中,大多数基于transformer的方法使用CNN + transformer框架。这意味着该模型首先通过CNN架构提取输入的图像特征,然后将这些特征映射塑造为transformer的输入。与基于检测的跟踪方法不同,基于transformer的跟踪方法通过将检测和数据关联部分结合起来实现跟踪结果。该方法不需要额外的轨迹匹配技术,只需一个模型即可直接输出轨迹的身份和位置。尽管基于transformer的方法在特征注意力方面取得了突出的结果,但在将整个图像输入到transformer架构时,其推理速度仍有一定的限制。
为了生成高质量的检测结果和目标外观,采用TBD模型SDE来解决JDE中存在的特征冲突问题。然而,大多数特征描述子不能很好地区分不同物体之间的外观特征。为了解决这个问题,我们提出了SMILEtrack,它结合了一个检测器和一个类似孪生网络的相似性学习模块(SLM)。受视觉transformer[6]的启发,利用SLM中的注意力机制和图像切片机制,创建了一个图像切片注意力块(ISA)。此外,我们创建了一个相似性匹配级联SMC,用于匹配视频中每个帧之间的对象。该系统的大致过程如下:首先,利用PRB[4]检测器预测目标边界框位置;在获得对象边界框后,我们通过SMC将边界框与轨迹关联。
我们的工作贡献总结如下:
-
提出了一个单独的检测和嵌入模型,名为SMILEtrack,以及相似性学习模块(SLM),该模块使用类似孪生网络的架构来学习每个对象之间的相似性。
-
针对SLM中的特征提取部分,构建了图像切片注意力块(Image Slicing Attention Block, ISA),利用图像切片方法和transformer的注意力机制来学习物体特征。
-
为了完成轨迹匹配部分,我们建立了相似匹配级联(SMC)来关联每帧中的每个边界框。
2、相关工作
2.1、Tracking-by-Detection
基于tbd的算法已经在MOT问题中取得了相当大的成功,是MOT框架中最流行的算法。TBD方法的主要任务是将视频中各帧之间的检测结果关联起来,完成多目标检测系统。整个工作大致可以分为两部分。
2.1.1、检测方法
Faster R-CNN[18]是一个两级检测器;它使用VGG-16作为骨干,即区域建议网络(RPN)来检测边界框。SSD[11]使用锚机制代替RPN;在每个特征图上设置不同大小的锚点以提高检测质量。YOLO系列[15][16][17][2]是一种利用特征金字塔网络(feature pyramid network, FPN)解决目标检测中的多尺度问题的单阶段方法,在速度和精度上都具有突出的性能。虽然基于锚点的检测器可以取得很好的性能,但仍然存在一些由锚点引起的问题。例如,基于锚点的检测器难以按情况调整锚点的某些超参数,并且在训练部分计算锚点的交并比(IOU)需要大量的时间和内存。为了克服这些问题,无锚点检测器是另一种选择。角网络[9]是一种无锚点的方法;它利用热图和角池化而不是锚点来预测目标的左上角和右下角,然后匹配这两个点来生成对象的边界框。与CornerNet相比,CenterNet[34]通过中心池化和级联角点池化直接预测目标的中心点。YOLOX将YOLO系列从基于锚点的检测器转变为无锚点检测器。同时,采用解耦头来提高检测的准确性。
2.1.2、数据关联方法
在MOT系统中,需要解决物体遮挡、场景拥挤、运动模糊等问题。因此,需要仔细对待数据关联的方法。SORT[1]算法首先根据目标在当前帧的位置利用卡尔曼滤波器预测目标的未来位置,然后通过计算现有目标检测框与预测边界框之间的IOU距离生成分配代价矩阵。最后利用匈牙利算法匹配赋值代价矩阵。SORT算法虽然具有较快的推理速度,但由于它不关心目标的外观信息,因此无法处理长期遮挡问题或快速运动的目标。
为了解决遮挡问题,Deep SORT[27]应用预训练的CNN模型提取目标的边界框外观特征,然后利用外观特征计算目标轨迹与待检测目标之间的相似度。最后采用匈牙利算法完成分配。这种方法可以有效地减少ID开关的数量,但在深度排序中检测模型和特征提取模型是分离的,导致推理速度远不能达到实时性。针对这一问题,JDE[26]将检测器和嵌入模型结合在一个one-shot网络中,可以实时运行,且与两阶段方法的精度相当。FairMOT[32]展示了锚点带来的不公平性,采用基于CenterNet的无锚点方法,在MOT17[14]等多个数据集上取得了较大的性能提升。然而,JDE模型存在构件间特性冲突等问题。
而[21]和[22]算法则摒弃了目标外观特征,仅利用高性能的检测器和运动信息完成跟踪。尽管这些方法可以在MOTChallenge基准中达到最先进的性能和高推理速度,但我们认为,这部分是由于MOTChallenge基准数据集中运动模式的简单性。此外,在较拥挤的场景中,未参考目标外观特征会导致目标跟踪精度较差。
2.2、Tracking-by-Attention
随着transformer在目标检测方面的成功应用,Trackformer[13]在DETR的基础上,将MOT问题转换为集合预测问题,并增加了目标查询和自回归轨迹查询用于目标跟踪。TransTrack[23]基于可变形DETR构建,具有两个解码器,一个用于当前帧检测,另一个用于前一帧检测。通过匹配两个解码器之间的检测框来完成跟踪问题。TransCenter[29]是一种基于点的跟踪,为利用transformer的MOT提出了一个具有多尺度输入图像的密集查询特征图。
3、方法
在本节中,我们将介绍SMILEtrack模型的细节,包括相似性学习模块(SLM)和用于每帧框关联的相似性匹配级联(SMC)。
3.1、体系结构概述
图2描述了SMILEtrack的整体架构。我们的框架可以分为以下步骤。(1)检测物体位置:为了定位目标物体的位置,我们采用PRB作为检测器。(2)数据关联:MOT问题是通过关联相邻帧中的每个对象来实现的。在得到PRB[4]生成的检测结果后,计算每一帧之间的运动相似度矩阵和外观相似度矩阵,并将这两个矩阵的代价矩阵结合到匈牙利算法中求解线性分配问题。
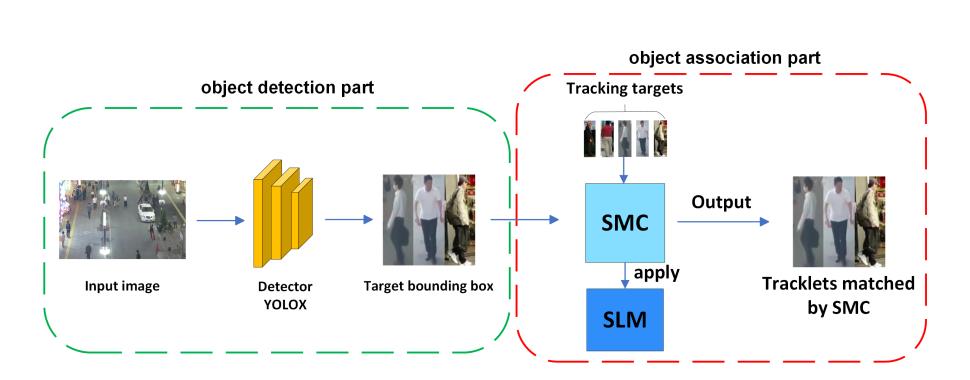
图2 SMILEtrack架构由两部分组成:(1)目标检测和(2)目标关联。
为了达到鲁棒的跟踪质量,目标的外观信息是必不可少的。许多跟踪方法都考虑了目标的外观信息。例如,DeepSORT应用由简单CNN构建的深度外观描述符来提取目标外观特征。虽然外观描述子可以提取有用的外观特征,但我们抱怨外观描述子不能很好地区分不同物体之间的外观特征。为了提取更具判别力的外观特征,提出了一种类似孪生网络架构的相似性学习模块SLM。SLM的细节如图3所示。
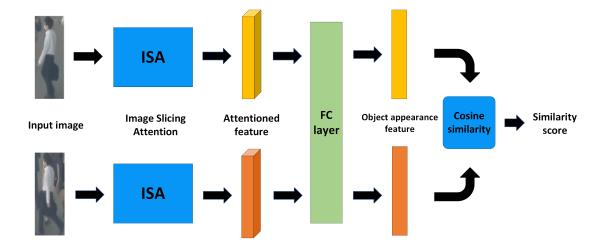
图3 相似度学习模块SLM的完整架构。
对于SLM的输入,我们将两幅不同的图像同时放入SLM中。它们都将通过 3.2.1节中的ISA特征提取器,该特征提取器在两个图像之间共享参数。稍后将更详细地介绍ISA的体系结构。在提取输入图像的特征后,使用全连接层对特征进行集成。为了学习一种鲁棒的能够区分不同目标的外观特征,采用余弦相似度距离计算两幅图像之间的相似度。相同对象之间的相似度分数应该尽可能高;否则,不同对象之间的相似度分数应该接近于零。
3.2.1、图像切片注意(ISA)块
为了产生可靠的外观特征,一个优秀的特征提取器是必不可少的。虽然变压器在特征增强方面表现突出,但我们认为在跟踪系统中加入完整的编码器-解码器架构对于模型计算和参数大小来说过于繁重。受VIT的启发,我们构建了一个ISA,该ISA应用了图像切片技术和特征提取的注意机制。ISA的详细体系结构如图4所示。
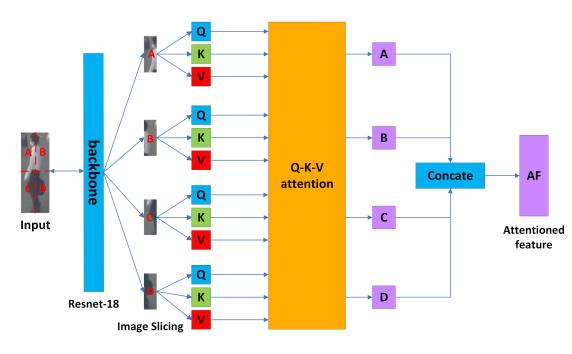
图4 完整的图像切片注意力块架构—ISA。对输入图像应用图像切片,我们将其划分为左上角部分,右上角部分,左下角部分,右下角部分。
最后,将特征切片序列 S = S A ∼ S D S= \\left\\S_A \\sim S_D\\right\\ S=SA∼SD作为注意力块的输入。
3.2.3、Q-K-V注意力块
标准transformer擅长处理序列之间的长期复杂依赖关系,如自然语言处理。transformer中最重要的部分是注意力块。transformer通过将查询打包到矩阵Q中来计算注意力函数,也将键和值打包到矩阵K和v中。注意力块的计算表示为
Attention ( Q , K , V ) = softmax ( Q K T d k ) V (2) \\operatornameAttention(Q, K, V)=\\operatornamesoftmax\\left(\\fracQ K^T\\sqrtd_k\\right) V \\tag2 Attention(Q,K,V)=softmax(dkQKT)V(2)
其中
d
k
d_k
dk为关键向量的维数。为了为注意力块生成查询、键和值,我们为图像切片产生的每个切片应用一个接一个的全连接层。每个切片在通过Q-K-V注意力块后都有一个输出
S
i
S_i
Si。我们通过Q-K-V注意力块将每个切片
S
=
S
A
∼
S
D
S= \\left\\S_A \\sim S_D\\right\\
S=SA∼SD的输出表示为以下等式:
S
A
=
S
A
(
Q
S
1
,
K
S
1
,
V
S
1
)
+
C
A
(
Q
S
1
,
K
S
2
,
V
S
2
)
+
C
A
(
Q
S
1
,
K
S
3
,
V
S
3
)
+
C
A
(
Q
S
1
,
K
S
4
,
V
S
4
)
S
B
=
S
A
(
Q
S
2
,
K
S
2
,
V
S
2
)
+
C
A
(
Q
S
2
,
K
S
1
,
V
S
1
)
+
C
A
(
Q
S
2
,
K
S
3
,
V
S
3
)
+
C
A
(
Q
S
2
,
K
S
4
,
V
S
4
)
S
C
=
S
A
(
Q
S
3
,
K
S
3
,
V
S
3
)
+
C
A
(
Q
S
3
,
K
S
1
,
V
S
1
)
+
C
A
(
Q
S
3
,
K
S
2
,
V
S
2
)
+
C
A
(
Q
S
3
,
K
S
4
,
V
S
4
)
S
D
=
S
A
(
Q
S
4
,
K
S
4
,
V
S
4
)
+
C
A
(
Q
S
4
,
K
S
1
,
V
S
1
)
+
C
A
(
Q
S
4
,
K
S
2
,
V
S
2
)
+
C
A
(
Q
S
4
,
K
S
3
,
V
S
3
)
(3)
\\beginaligned S_A & =S A\\left(Q_S 1, K_S 1, V_S 1\\right)+C A\\left(Q_S 1, K_S 2, V_S 2\\right) \\\\ & +C A\\left(Q_S 1, K_S 3, V_S 3\\right)+C A\\left(Q_S 1, K_S 4, V_S 4\\right) \\\\ S_B & =S A\\left(Q_S 2, K_S 2, V_S 2\\right)+C A\\left(Q_S 2, K_S 1, V_S 1\\right) \\\\ & +C A\\left(Q_S 2, K_S 3, V_S 3\\right)+C A\\left(Q_S 2, K_S 4, V_S 4\\right) \\\\ S_C & =S A\\left(Q_S 3, K_S 3, V_S 3\\right)+C A\\left(Q_S 3, K_S 1, V_S 1\\right) \\\\ & +C A\\left(Q_S 3, K_S 2, V_S 2\\right)+C A\\left(Q_S 3, K_S 4, V_S 4\\right) \\\\ S_D & =S A\\left(Q_S 4, K_S 4, V_S 4\\right)+C A\\left(Q_S 4, K_S 1, V_S 1\\right) \\\\ & +C A\\left(Q_S 4, K_S 2, V_S 2\\right)+C A\\left(Q_S 4, K_S 3, V_S 3\\right) \\endaligned \\tag3
SASBSCSD=SA(QS1,KS1,VS1)+CA(QS1,KS2,VS2)+CA(QS1,KS3,V