RBF网络
Posted zbxzc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RBF网络相关的知识,希望对你有一定的参考价值。
RBF (Radial Basis Function)可以看作是一个高维空间中的曲面拟合(逼近)问题,学习是为了在多维空间中寻找一个能够最佳匹配训练数据的曲面,然后来一批新的数据,用刚才训练的那个曲面来处理(比如分类、回归)。RBF的本质思想是反向传播学习算法应用递归技术,这种技术在统计学中被称为随机逼近。RBF里的basis function(径向基函数里的基函数)就是在神经网络的隐单元里提供了提供了一个函数集,该函数集在输入模式(向量)扩展至隐空间时,为其构建了一个任意的“基”。这个函数集中的函数就被称为径向基函数。
非rbf与非线性回归的区别在于:rbf是不知道数学模型的,而非线性回归则是知道数学模型的,比如知道数据服从某种函数分布,只是系数不知道而已。
核函数与径向基函数
注意核函数是一回事,径向基函数是另一回事。核函数表示的是高维空间里由于向量内积而计算出来的一个函数表达式。而径向基函数是一类函数,径向基函数是一个它的值(y)只依赖于变量(x)距原点距离的函数,即  ;也可以是距其他某个中心点的距离,即
;也可以是距其他某个中心点的距离,即 。也就是说,可以选定径向基函数来当核函数,譬如SVM里一般都用高斯径向基作为核函数,但是核函数不一定要选择径向基这一类函数。
。也就是说,可以选定径向基函数来当核函数,譬如SVM里一般都用高斯径向基作为核函数,但是核函数不一定要选择径向基这一类函数。
总结一下核函数就是:在原样本空间中非线性问题,我们希望通过一种映射把他映射到高维空间里使问题变得线性。然后在高维空间里使用我们的算法就能解决问题。
线性变换的基本理论(Cover, 1965):
1.一个模式分类问题如果映射到一个高维空间将会比映射到一个低维空间更可能实现线性可分;
2. 隐空间的维数越高,逼近就越精确。
如果提供的样本线性不可分,结果很简单,线性分类器的求解程序会无限循环,永远也解不出来。而将数据映射到高维空间后,往往就可分了。
几种径向基函数
1. Gauss(高斯)函数:
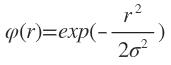
2. 反演S型函数:
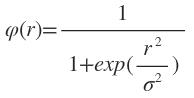
3. 拟多二次函数:
σ 称为基函数的扩展常数或宽度, σ越小,径向基函数的宽度越小,基函数就越有选择性。
RBF网络的结构
RBF神经网络一般为3层,即输入层,隐藏层,输出层。
输入层由一些感知单元组成,它们将网络与外界环境连接起来;第二层是网络中仅有的一个隐层,它的作用是从输入空间到隐层空间之间进行非线性变换,在大多数情况下,隐层空间有较高的维数;输出层是线性的,它为作用于输入层的激活模式提供响应。
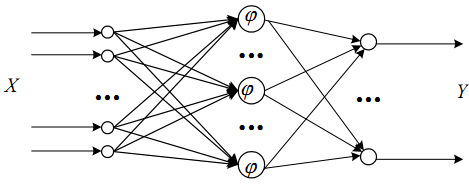
隐含层的每个节点就是就是空间中的一个基底,经过线性组合加权以后就变成了输出。
RB![]() F网络的工作原理
F网络的工作原理
函数逼近:
以任意精度逼近任一连续函数。一般函数都可表示成一组基函数的线性组合,RBF网络相当于用隐层单元的输出构成一组基函数,然后用输出层来进行线性组合,以完成逼近功能。
分类:
解决非线性可分问题。RBF网络用隐层单元先将非线性可分的输入空间设法变换到线性可分的特征空间(通常是高维空间),然后用输出层来进行线性划分,完成分类功能。
RBF学习的三个参数
①基函数的中心
②方差(扩展常数)
③隐含层与输出层间的权值
当采用正归化RBF网络结构时,隐节点数即样本数,基函数的数据中心即为样本本身,参数设计只需考虑扩展常数和输出节点的权值。
当采用广义RBF网络结构时,RBF网络的学习算法应该解决的问题包括:如何确定网络隐节点数,如何确定各径向基函数的数据中心及扩展常数,以及如何修正输出权值。
①基函数的中心
1.中心从样本输入中选取
一般来说,样本密集的地方中心点可以适当多些,样本稀疏的地方中心点可以少些;若数据本身是均匀分布的,中心点也可以均匀分布。总之,选出的数据中心应具有代表性。径向基函数的扩展常数是根据数据中心的散布而确定的,为了避免每个径向基函数太尖或太平,一种选择方法是将所有径向基函数的扩展常数设为
2.中心自组织选取
常采用各种动态聚类算法对数据中心进行自组织选择,在学习过程中需对数据中心的位置进行动态调节。常用的方法是K-means聚类,其优点是能根据各聚类中心之间的距离确定各隐节点的扩展常数。由于RBF网的隐节点数对其泛化能力有极大的影响,所以寻找能确定聚类数目的合理方法,是聚类方法设计RBF网时需首先解决的问题。除聚类算法外,还有梯度训练方法、资源分配网络(RAN)等
两个步骤:①无监督的自组织学习阶段
其任务是用自组织聚类方法为隐层节点的径向基函数确定合适的数据中心,并根据各中心之间的距离确定隐节点的扩展常数。一般采用Duda和Hart1973年提出的
k-means聚类算法
②有监督学习阶段
其任务是用有监督学习算法训练输出层权值,一般采用梯度法进行训练
3.有监督选取中心法
4.正交最小二乘法等
②方差(扩展常数)
各聚类中心确定后,可根据各中心之间的距离确定对应径向基函数的扩展常数。
则扩展常数可取为
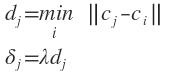
λ为重叠系数
③隐含层与输出层间的权值
权值的学习可以用LMS学习算法或伪逆法。
注意:①LMS算法的输入为RBF网络隐含层的输出
②RBF网络输出层的神经元只是对隐含层神经元的输出加权和。
用LMS方法求解
用伪逆方法求解
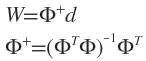
d是期望响应
奇异矩阵或非方阵的矩阵不存在逆矩阵。
以上是关于RBF网络的主要内容,如果未能解决你的问题,请参考以下文章