Linux进程管理及作业控制的启动进程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux进程管理及作业控制的启动进程相关的知识,希望对你有一定的参考价值。
参考技术A键入需要运行的程序的程序名,执行一个程序,其实也就是启动了一个进程。在Linux系统中每个进程都具有一个进程号,用于系统识别和调度进程。启动一个进程有两个主要途径:手工启动和调度启动,后者是事先进行设置,根据用户要求自行启动。 由用户输入命令,直接启动一个进程便是手工启动进程。但手工启动进程又可以分为很多种,根据启动的进程类型不同、性质不同,实际结果也不一样,下面分别介绍。
1. 前台启动
这或许是手工启动一个进程的最常用的方式。一般地,用户键入一个命令“ls –l”,这就已经启动了一个进程,而且是一个前台的进程。这时候系统其实已经处于一个多进程状态。或许有些用户会疑惑:我只启动了一个进程而已。但实际上有许多运行在后台的、系统启动时就已经自动启动的进程正在悄悄运行着。还有的用户在键入“ls –l”命令以后赶紧使用“ps –x”查看,却没有看到ls进程,也觉得很奇怪。其实这是因为ls这个进程结束太快,使用ps查看时该进程已经执行结束了。如果启动一个比较耗时的进程:
find / -name fox.jpg
然后再把该进程挂起,使用ps查看,就会看到一个find进程在里面。
2. 后台启动
直接从后台手工启动一个进程用得比较少一些,除非是该进程甚为耗时,且用户也不急着需要结果的时候。假设用户要启动一个需要长时间运行的格式化文本文件的进程。为了不使整个shell在格式化过程中都处于“瘫痪”状态,从后台启动这个进程是明智的选择。
[例1]
$ troff –me notes > note_form &
[1] 4513
$
由上例可见,从后台启动进程其实就是在命令结尾加上一个&号。键入命令以后,出现一个数字,这个数字就是该进程的编号,也称为PID,然后就出现了提示符。用户可以继续其他工作。
上面介绍了前、后台启动的两种情况。实际上这两种启动方式有个共同的特点,就是新进程都是由当前shell这个进程产生的。也就是说,是shell创建了新进程,于是就称这种关系为进程间的父子关系。这里shell是父进程,而新进程是子进程。一个父进程可以有多个子进程,一般地,子进程结束后才能继续父进程;当然如果是从后台启动,那就不用等待子进程结束了。
一种比较特殊的情况是在使用管道符的时候。例如:
nroff -man ps.1|grep kill|more
这时候实际上是同时启动了三个进程。请注意是同时启动的,所有放在管道两边的进程都将被同时启动,它们都是当前shell的子程序,互相之间可以称为兄弟进程。
以上介绍的是手工启动进程的一些内容,作为一名系统管理员,很多时候都需要把事情安排好以后让其自动运行。因为管理员不是机器,也有离开的时候,所以有些必须要做的工作而恰好管理员不能亲自操作,这时候就需要使用调度启动进程了。 有时候需要对系统进行一些比较费时而且占用资源的维护工作,这些工作适合在深夜进行,这时候用户就可以事先进行调度安排,指定任务运行的时间或者场合,到时候系统会自动完成这一切工作。
要使用自动启动进程的功能,就需要掌握以下几个启动命令。
at命令
用户使用at命令在指定时刻执行指定的命令序列。也就是说,该命令至少需要指定一个命令、一个执行时间才可以正常运行。at命令可以只指定时间,也可以时间和日期一起指定。需要注意的是,指定时间有个系统判别问题。比如说:用户现在指定了一个执行时间:凌晨3:20,而发出at命令的时间是头天晚上的20:00,那么究竟是在哪一天执行该命令呢?如果用户在3:20以前仍然在工作,那么该命令将在这个时候完成;如果用户3:20以前就退出了工作状态,那么该命令将在第二天凌晨才得到执行。下面是at命令的语法格式:
at [-V] [-q 队列] [-f 文件名] [-mldbv] 时间
at -c 作业 [作业...]
at允许使用一套相当复杂的指定时间的方法,实际上是将POSIX.2标准扩展了。它可以接受在当天的hh:mm(小时:分钟)式的时间指定。如果该时间已经过去,那么就放在第二天执行。当然也可以使用midnight(深夜),noon(中午),teatime(饮茶时间,一般是下午4点)等比较模糊的词语来指定时间。用户还可以采用12小时计时制,即在时间后面加上AM(上午)或者PM(下午)来说明是上午还是下午。
也可以指定命令执行的具体日期,指定格式为month day(月 日)或者mm/dd/yy(月/日/年)或者dd.mm.yy(日.月.年)。指定的日期必须跟在指定时间的后面。
上面介绍的都是绝对计时法,其实还可以使用相对计时法,这对于安排不久就要执行的命令是很有好处的。指定格式为:now + count time-units ,now就是当前时间,time-units是时间单位,这里可以是 minutes(分钟)、hours(小时)、days(天)、weeks(星期)。count是时间的数量,究竟是几天,还是几小时,等等。
还有一种计时方法就是直接使用today(今天)、tomorrow(明天)来指定完成命令的时间。下面通过一些例子来说明具体用法。
[例2] 指定在今天下午5:30执行某命令。假设现在时间是中午12:30,1999年2月24日,其命令格式如下:
at 5:30pm
at 17:30
at 17:30 today
at now + 5 hours
at now + 300 minutes
at 17:30 24.2.99
at 17:30 2/24/99
at 17:30 Feb 24
以上这些命令表达的意义是完全一样的,所以在安排时间的时候完全可以根据个人喜好和具体情况自由选择。一般采用绝对时间的24小时计时法可以避免由于用户自己的疏忽造成计时错误的情况发生,例如上例可以写成:
at 17:30 2/24/99
这样非常清楚,而且别人也看得懂。
对于at命令来说,需要定时执行的命令是从标准输入或者使用-f选项指定的文件中读取并执行的。如果at命令是从一个使用su命令切换到用户shell中执行的,那么当前用户被认为是执行用户,所有的错误和输出结果都会送给这个用户。但是如果有邮件送出的话,收到邮件的将是原来的用户,也就是登录时shell的所有者。
[例3]
$ at -f work 4pm + 3 days
在三天后下午4点执行文件work中的作业。
$ at -f work 10am Jul 31
在7月31日上午10点执行文件work中的作业。
在任何情况下,超级用户都可以使用这个命令。对于其他用户来说,是否可以使用就取决于两个文件:/etc/at.allow和/etc/at.deny。如果/etc/at.allow文件存在的话,那么只有在其中列出的用户才可以使用at命令;如果该文件不存在,那么将检查/etc/at.deny文件是否存在,在这个文件中列出的用户均不能使用该命令。如果两个文件都不存在,那么只有超级用户可以使用该命令;空的/etc/at.deny文件意味着所有的用户都可以使用该命令,这也是默认状态。
下面对命令中的参数进行说明。
-V 将标准版本号打印到标准错误中。
-q queue 使用指定的队列。队列名称是由单个字母组成,合法的队列名可以由a-z或者A-Z。a队列是at命令的默认队列。
-m 作业结束后发送邮件给执行at命令的用户。
-f file 使用该选项将使命令从指定的file读取,而不是从标准输入读取。
-l atq命令的一个别名。该命令用于查看安排的作业序列,它将列出用户排在队列中的作业,如果是超级用户,则列出队列中的所有工作。
命令的语法格式如下:
atq [-V] [-q 队列] [-v]
-d atrm 命令的一个别名。该命令用于删除指定要执行的命令序列,语法格式如下:
atrm [-V] 作业 [作业...]
-c 将命令行上所列的作业送到标准输出。
[例4] 找出系统中所有以txt为后缀名的文件,并且进行打印。打印结束后给用户foxy发出邮件通知取件。指定时间为十二月二十五日凌晨两点。
首先键入:
$ at 2:00 12/25/99
然后系统出现at>提示符,等待用户输入进一步的信息,也就是需要执行的命令序列:
at> find / -name “*.txt”|lpr
at> echo “foxy:All texts have been printed.You can take them over.Good day!River” |mail -s ”job done” foxy
输入完每一行指令然后回车,所有指令序列输入完毕后,使用组合键结束at命令的输入。这时候屏幕将出现如下信息:
warning:command will be executed using /bin/sh.
job 1 at 1999-12-25 02:00
提醒用户将使用哪个shell来执行该命令序列。 实际上如果命令序列较长或者经常被执行的时候,一般都采用将该序列写到一个文件中,然后将文件作为at命令的输入来处理。这样不容易出错。
例5] 上面的例子可以修改如下:
将命令序列写入到文件/tmp/printjob,语句为:
$ at -f /tmp/printjob 2:00 12/25/99
这样一来,at命令将使用文件中的命令序列,屏幕显示如下:
Warning:command will be executed using /bin/sh.
job 2 at 1999-12-25 02:00
当然也可以采用以下命令:
$ at< /tmp/printjob 2:00 12/25/99
来完成同样的任务。也就是使用输入重定向的办法将文件定向为命令输入。
batch命令
batch 用低优先级运行作业,该命令几乎和at命令的功能完全相同,唯一的区别在于,at命令是在指定时间,很精确的时刻执行指定命令;而batch却是在系统负载较低,资源比较空闲的时候执行命令。该命令适合于执行占用资源较多的命令。
batch命令的语法格式也和at命令十分相似,即
batch [-V] [-q 队列] [-f 文件名] [-mv] [时间]
具体的参数解释请参考at命令。一般地说,不用为batch命令指定时间参数,因为batch本身的特点就是由系统决定执行任务的时间,如果用户再指定一个时间,就失去了本来的意义。
[例6] 使用例4,键入:
$ batch
at> find / -name *.txt|lpr
at> echo “foxy:All texts have been printed.You can take them over.Good day!River” |mail -s ”job done” foxy
现在这个命令就会在合适的时间进行了,进行完后会发回一个信息。
仍然使用组合键来结束命令输入。而且batch和at命令都将自动转入后台,所以启动的时候也不需要加上&符号。
cron命令
前面介绍的两条命令都会在一定时间内完成一定任务,但是要注意它们都只能执行一次。也就是说,当指定了运行命令后,系统在指定时间完成任务,一切就结束了。但是在很多时候需要不断重复一些命令,比如:某公司每周一自动向员工报告头一周公司的活动情况,这时候就需要使用cron命令来完成任务了。
实际上,cron命令是不应该手工启动的。cron命令在系统启动时就由一个shell脚本自动启动,进入后台(所以不需要使用&符号)。一般的用户没有运行该命令的权限,虽然超级用户可以手工启动cron,不过还是建议将其放到shell脚本中由系统自行启动。
首先cron命令会搜索/var/spool/cron目录,寻找以/etc/passwd文件中的用户名命名的crontab文件,被找到的这种文件将载入内存。例如一个用户名为foxy的用户,它所对应的crontab文件就应该是/var/spool/cron/foxy。也就是说,以该用户命名的crontab文件存放在/var/spool/cron目录下面。cron命令还将搜索/etc/crontab文件,这个文件是用不同的格式写成的。
cron启动以后,它将首先检查是否有用户设置了crontab文件,如果没有就转入“休眠”状态,释放系统资源。所以该后台进程占用资源极少。它每分钟“醒”过来一次,查看当前是否有需要运行的命令。命令执行结束后,任何输出都将作为邮件发送给crontab的所有者,或者是/etc/crontab文件中MAILTO环境变量中指定的用户。
上面简单介绍了一些cron的工作原理,但是cron命令的执行不需要用户干涉;需要用户修改的是crontab中要执行的命令序列,所以下面介绍crontab命令。
crontab命令
crontab命令用于安装、删除或者列出用于驱动cron后台进程的表格。也就是说,用户把需要执行的命令序列放到crontab文件中以获得执行。每个用户都可以有自己的crontab文件。下面就来看看如何创建一个crontab文件。
在/var/spool/cron下的crontab文件不可以直接创建或者直接修改。crontab文件是通过crontab命令得到的。现在假设有个用户名为foxy,需要创建自己的一个crontab文件。首先可以使用任何文本编辑器建立一个新文件,然后向其中写入需要运行的命令和要定期执行的时间。
然后存盘退出。假设该文件为/tmp/test.cron。再后就是使用crontab命令来安装这个文件,使之成为该用户的crontab文件。键入:
crontab test.cron
这样一个crontab 文件就建立好了。可以转到/var/spool/cron目录下面查看,发现多了一个foxy文件。这个文件就是所需的crontab 文件。用more命令查看该文件的内容可以发现文件头有三行信息:
#DO NOT EDIT THIS FILE -edit the master and reinstall.
#(test.cron installed on Mon Feb 22 14:20:20 1999)
#(cron version --$Id:crontab.c,v 2.13 1994/01/17 03:20:37 vivie Exp $)
大概意思是:
#切勿编辑此文件——如果需要改变请编辑源文件然后重新安装。
#test.cron文件安装时间:14:20:20 02/22/1999
如果需要改变其中的命令内容时,还是需要重新编辑原来的文件,然后再使用crontab命令安装。
可以使用crontab命令的用户是有限制的。如果/etc/cron.allow文件存在,那么只有其中列出的用户才能使用该命令;如果该文件不存在但cron.deny文件存在,那么只有未列在该文件中的用户才能使用crontab命令;如果两个文件都不存在,那就取决于一些参数的设置,可能是只允许超级用户使用该命令,也可能是所有用户都可以使用该命令。
crontab命令的语法格式如下:
crontab [-u user] file
crontab [-u user]-l|-r|-e
第一种格式用于安装一个新的crontab 文件,安装来源就是file所指的文件,如果使用“-”符号作为文件名,那就意味着使用标准输入作为安装来源。
-u 如果使用该选项,也就是指定了是哪个具体用户的crontab 文件将被修改。如果不指定该选项,crontab 将默认是操作者本人的crontab ,也就是执行该crontab 命令的用户的crontab 文件将被修改。但是请注意,如果使用了su命令再使用crontab 命令很可能就会出现混乱的情况。所以如果是使用了su命令,最好使用-u选项来指定究竟是哪个用户的crontab文件。
-l 在标准输出上显示当前的crontab。
-r 删除当前的crontab文件。
-e 使用VISUAL或者EDITOR环境变量所指的编辑器编辑当前的crontab文件。当结束编辑离开时,编辑后的文件将自动安装。
[例7]
# crontab -l #列出用户目前的crontab。
10 6 * * * date
0 */2 * * * date
0 23-7/2,8 * * * date
#
在crontab文件中如何输入需要执行的命令和时间。该文件中每行都包括六个域,其中前五个域是指定命令被执行的时间,最后一个域是要被执行的命令。每个域之间使用空格或者制表符分隔。格式如下:
minute hour day-of-month month-of-year day-of-week commands
第一项是分钟,第二项是小时,第三项是一个月的第几天,第四项是一年的第几个月,第五项是一周的星期几,第六项是要执行的命令。这些项都不能为空,必须填入。如果用户不需要指定其中的几项,那么可以使用*代替。因为*是统配符,可以代替任何字符,所以就可以认为是任何时间,也就是该项被忽略了。在表4-1中给出了每项的合法范围。
表4-1 指定时间的合法范围
时间
合法值
minute 00-59
hour 00-23,其中00点就是晚上12点
day-of-month
01-31
month-of-year
01-12
day-of-week
0-6,其中周日是0
这样用户就可以往crontab 文件中写入无限多的行以完成无限多的命令。命令域中可以写入所有可以在命令行写入的命令和符号,其他所有时间域都支持列举,也就是域中可以写入很多的时间值,只要满足这些时间值中的任何一个都执行命令,每两个时间值中间使用逗号分隔。
[例8]
5,15,25,35,45,55 16,17,18 * * * command
这就是表示任意天任意月,其实就是每天的下午4点、5点、6点的5 min、15 min、25 min、35 min、45 min、55 min时执行命令。
[例9]
在每周一,三,五的下午3:00系统进入维护状态,重新启动系统。那么在crontab 文件中就应该写入如下字段:
00 15 * * 1,3,5 shutdown -r +5
然后将该文件存盘为foxy.cron,再键入crontab foxy.cron安装该文件。
[例10]
每小时的10分,40分执行用户目录下的innd/bbslin这个指令:
10,40 * * * * innd/bbslink
[例11]
每小时的1分执行用户目录下的bin/account这个指令:
1 * * * * bin/account
[例12]
每天早晨三点二十分执行用户目录下如下所示的两个指令(每个指令以;分隔):
20 3 * * * (/bin/rm -f expire.ls logins.bad;bin/expire>expire.1st)
[例13]
每年的一月和四月,4号到9号的3点12分和3点55分执行/bin/rm -f expire.1st这个指令,并把结果添加在mm.txt这个文件之后(mm.txt文件位于用户自己的目录位置)。
12,55 3 4-9 1,4 * /bin/rm -f expire.1st>> m.txt
[例14]
我们来看一个超级用户的crontab文件:
#Run the ‘atrun’ program every minutes
#This runs anything that’s due to run from ‘at’.See man ‘at’ or ‘atrun’. 0,5,10,15,20,25,30,35,40,45,50,55 * * * * /usr/lib/atrun
40 7 * * * updatedb
8,10,22,30,39,46,54,58 * * * * /bin/sync
进程的挂起及恢复命令bg、fg
作业控制允许将进程挂起并可以在需要时恢复进程的运行,被挂起的作业恢复后将从中止处开始继续运行。只要在键盘上按,即可挂起当前的前台作业。
[例15]
$ cat >
< ctrl+z>
text.file [1] + stopped cat > text.file
$ jobs [1]+ stopped cat >text.file
在键盘上按后,将挂起当前执行的命令cat。使用jobs命令可以显示shell的作业清单,包括具体的作业、作业号以及作业当前所处的状态。
恢复进程执行时,有两种选择:用fg命令将挂起的作业放回到前台执行;用bg命令将挂起的作业放到后台执行。
[例16]
用户正在使用Emacs,突然需要查看系统进程情况。就首先使用组合键将Emacs进程挂起,然后使用bg命令将其在后台启动,这样就得到了前台的操作控制权,接着键入“ps –x”查看进程情况。查看完毕后,使用fg命令将Emacs带回前台运行即可。其命令格式为:
< ctrl+z>
$ bg emacs
$ ps –x
$ fg emacs
默认情况下,fg和bg命令对最近停止的作业进行操作。如果希望恢复其他作业的运行,可以在命令中指定要恢复作业的作业号来恢复该作业。例如:
$ fg 1
cat > text.file
灵活使用上述命令,将给自己带来很大的方便。
Linux进程及作业管理
内核的功用:进程管理、文件系统、网络功能、内存管理、驱动程序、安全功能
Process: 运行中的程序的一个副本,存在生命周期
Linux内核存储进程信息的固定格式:task struct
多个任务的的task struct组件的链表:task list
进程创建:
init
父子关系
进程:都由其父进程创建
进程优先级:
0-139:
1-99:实时优先级
100-139:静态优先级(数字越小,优先级越高)
Nice值:-20,19
进程内存:
Page Frame: 页框,用存储页面数据
存储Page
MMU:Memory Management Unit
IPC: Inter Process Communication
同一主机上:
signal、shm: shared memory、semerphor
不同主机上:
rpc: remote procecure call、socket:
Linux内核:抢占式多任务
进程类型:
守护进程: 在系统引导过程中启动的进程,跟终端无关的进程
前台进程:跟终端相关,通过终端启动的进程
Note:也可把在前台启动的进程送往后台,以守护模式运行
进程状态:
运行态:running
就绪态:ready
睡眠态:
可中断:interruptable
不可中断:uninterruptable
停止态:暂停于内存中,但不会被调度,除非手动启动之;stopped
僵死态:zombie
进程的分类:
CPU-Bound
IO-Bound
Linux进程查看及管理的工具:pstree, ps, pidof, pgrep, top, htop, glance, pmap, vmstat, dstat, kill, pkill, job, bg, fg, nohup
pstree命令:
pstree - display a tree of processes
ps: process state
ps - report a snapshot of the current processes
Linux系统各进程的相关信息均保存在/proc/PID目录下的各文件中
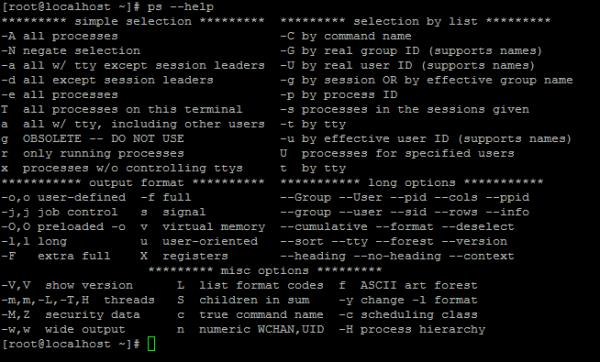
ps [OPTION]...
选项:支持两种风格
常用组合:aux
u: 以用户为中心组织进程状态信息显示
a: 与终端相关的进程
x: 与终端无关的进程
~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
VSZ: Virtual memory SiZe,虚拟内存集
RSS: ReSident Size, 常驻内存集
STAT:进程状态
R:running
S: interruptable sleeping
D: uninterruptable sleeping
T: stopped
Z: zombie
+: 前台进程
l: 多线程进程
N:低优先级进程
<: 高优先级进程
s: session leader
常用组合:-ef
-e: 显示所有进程
-f: 显示完整格式程序信息
常用组合:-eFH
-F: 显示完整格式的进程信息
-H: 以进程层级格式显示进程相关信息
常用组合:-eo, axo
-eo pid,tid,class,rtprio,ni,pri,psr,pcpu,stat,comm
axo stat,euid,ruid,tty,tpgid,sess,pgrp,ppid,pid,pcpu,comm
ni: nice值
pri: priority,优先级
psr: processor, CPU
rtprio: 实时优先级
pgrep, pkill:
pgrep [options] pattern
pkill [options] pattern
-u uid: effective user
-U uid: real user
-t terminal: 与指定终端相关的进程
-l: 显示进程名
-a: 显示完整格式的进程名
-P pid: 显示其父进程为此处指定的进程的进程列表
pidof:
根据进程名获取其PID
top:
有许多内置命令:
排序:
P:以占据的CPU百分比
M:占据内存百分比
T:累积占据CPU时长
首部信息显示:
uptime信息:l命令
tasks及cpu信息:t命令
cpu分别显示:1 (数字)
memory信息:m命令
退出命令:q
修改刷新时间间隔:s
终止指定进程:k
选项:
-d #: 指定刷新时间间隔,默认为3秒
-b: 以批次方式
-n #: 显示多少批次
htop命令:
选项:
-d #: 指定延迟时间
-u UserName: 仅显示指定用户的进程
-s COLOMN: 以指定字段进行排序
命令:
s: 跟踪选定进程的系统调用
l: 显示选定进程打开的文件列表
a:将选定的进程绑定至某指定CPU核心
t: 显示进程树
vmstat命令:
vmstat [options] [delay [count]]
procs:
r:等待运行的进程的个数
b:处于不可中断睡眠态的进程个数;(被阻塞的队列的长度)
memory:
swpd: 交换内存的使用总量
free:空闲物理内存总量
buffer:用于buffer的内存总量
cache:用于cache的内存总量
swap:
si:数据进入swap中的数据速率(kb/s)
so:数据离开swap中的数据速率(kb/s)
io:
bi:从块设备读入数据到系统的速率;(kb/s)
bo: 保存数据至块设备的速率
system:
in: interrupts, 中断速率
cs: context switch, 进程切换速率
cpu:
us、sy、id、wa、st
选项:
-s: 显示内存的统计数据
pmap命令:
pmap - report memory map of a process
pmap [options] pid [...]
-x: 显示详细格式的信息;
另外一种实现:
# cat /proc/PID/maps
glances命令:
glances [-bdehmnrsvyz1] [-B bind] [-c server] [-C conffile] [-p port] [-P password] [--password] [-t refresh] [-f file] [-o output]
内建命令:
a Sort processes automatically l Show/hide logs
c Sort processes by CPU% b Bytes or bits for network I/O
m Sort processes by MEM% w Delete warning logs
p Sort processes by name x Delete warning and critical logs
i Sort processes by I/O rate 1 Global CPU or per-CPU stats
d Show/hide disk I/O stats h Show/hide this help screen
f Show/hide file system stats t View network I/O as combination
n Show/hide network stats u View cumulative network I/O
s Show/hide sensors stats q Quit (Esc and Ctrl-C also work)
y Show/hide hddtemp stats
常用选项:
-b: 以Byte为单位显示网卡数据速率
-d: 关闭磁盘I/O模块
-f /path/to/somefile: 设定输入文件位置
-o {HTML|CSV}:输出格式
-m: 禁用mount模块
-n: 禁用网络模块
-t #: 延迟时间间隔
-1:每个CPU的相关数据单独显示
C/S模式下运行glances命令:
服务模式:
glances -s -B IPADDR
IPADDR: 指明监听于本机哪个地址
客户端模式:
glances -c IPADDR
IPADDR:要连入的服务器端地址
dstat命令:
dstat [-afv] [options..] [delay [count]]
-c: 显示cpu相关信息
-C #,#,...,total
-d: 显示disk相关信息
-D total,sda,sdb,...
-g:显示page相关统计数据
-m: 显示memory相关统计数据
-n: 显示network相关统计数据
-p: 显示process相关统计数据
-r: 显示io请求相关的统计数据
-s: 显示swapped相关的统计数据
--tcp
--udp
--unix
--raw
--socket
--ipc
--top-cpu:显示最占用CPU的进程
--top-io: 显示最占用io的进程
--top-mem: 显示最占用内存的进程
--top-lantency: 显示延迟最大的进程
kill命令:
向进程发送控制信号,以实现对进程管理
显示当前系统可用信号:
# kill -l
# man 7 signal
常用信号:
1) SIGHUP: 无须关闭进程而让其重读配置文件
2) SIGINT: 中止正在运行的进程;相当于Ctrl+c
9) SIGKILL: 杀死正在运行的进程
15) SIGTERM:终止正在运行的进程
18) SIGCONT
19) SIGSTOP
指定信号的方法:
(1) 信号的数字标识;1, 2, 9
(2) 信号完整名称;SIGHUP
(3) 信号的简写名称;HUP
向进程发信号:kill [-SIGNAL] PID...
终止“名称”之下的所有进程:killall [-SIGNAL] Program
Linux的作业控制
前台作业:通过终端启动,且启动后一直占据终端
后台作业:可以通过终端启动,但启动后即转入后台运行(释放终端)
如何让作业运行于后台?
(1) 运行中的作业:Ctrl+z
(2) 尚未启动的作业:# COMMAND &
此类作业虽然被送往后台运行,但其依然与终端相关;如果希望送往后台后,剥离与终端的关系:
# nohup COMMAND &
查看所有作业:
# jobs
作业控制:
# fg [[%]JOB_NUM]:把指定的后台作业调回前台
# bg [[%]JOB_NUM]:让送往后台的作业在后台继续运行
# kill [%JOB_NUM]:终止指定的作业
进程优先级调整:
静态优先级:100-139
进程默认启动时的nice值为0,优先级为120
nice命令:
nice [OPTION] [COMMAND [ARG]...]
renice命令:
renice [-n] priority pid...
查看:
ps axo pid,comm,ni
本文出自 “Ricky的技术博客” 博客,请务必保留此出处http://r1cky.blog.51cto.com/10646564/1773861
以上是关于Linux进程管理及作业控制的启动进程的主要内容,如果未能解决你的问题,请参考以下文章