Flink初识Flink快速又灵巧
Posted 大数据指北
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink初识Flink快速又灵巧相关的知识,希望对你有一定的参考价值。

文章目录
一、Flink的引入
随着大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop、Storm, 以及后来的Spark,他们都有着各自专注的应用场景。尤以Spark掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。
Spark的火热或多或少的掩盖了其他分布式计算的系统身影。与此同时,新生代王者Flink,也就在这个时候默默的发展着。
在国外一些社区,有很多人将大数据的计算引擎分成了4代,当然,也有很多人不会认同。我们先姑且这么认为和讨论。
- 1 首先第一代的计算引擎,无疑就是 Hadoop 承载的 MapReduce。
这里大家应该都不会对 MapReduce 陌生,它将计算分为两个阶段,分别为 Map和Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个Job 的串联,以完成一个完整的算法,例如迭代计算。由于这样的弊端,催生了支持 DAG 框架的产生。
- 2 支持 DAG 的框架被划分为第二代计算引擎。
如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别, 不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。
- 3 Spark 为代表的第三代的计算引擎。
第三代计算引擎的特点主要是Job内部的DAG支持,以及强调的实时计算(微批处理)。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的Job。随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和SQL等的支持。
- 4 Flink 的诞生就被归在了第四代。
这应该主要表现在Flink对流计算的支持,以及更一步的实时性上面达到真正意义上的实时。当然 Flink 也可以支持Batch的任务,以及DAG的运算。
Flink是Apache基金会旗下的一个开源大数据处理框架。 在各个互联网企业以及需求实时计算的地方都被广泛的重视。
特别以阿里为代表的一线互联网都在全力投入,为Fink社区贡献了巨大的源码。
为何Flink为受到如此青睐呢?>为何Flink为受到如此青睐呢?
带着疑问我们一步一步往下走,揭开Flink的神秘面纱…
二、Flink的起源和设计理念
1.起源
Flink 起源于一个叫作 Stratosphere 的项目,它是由 3 所地处柏林的大学和欧洲其他一些大学在 2010~2014 年共同进行的研究项目,由柏林理工大学的教授沃克尔·马尔科(Volker Markl)领衔开发。
在德语中,flink一词表示“快速、灵巧”。项目的 logo 是一只彩色的松鼠,当然了,这不仅是因为 Apache 大数据项目对动物的喜好(是否联想到了 Hadoop、Hive?),更是因为松鼠这种小动物完美地体现了“快速、灵巧”的特点。
大数据组件里每一个logo都是极具意义的。大象Logo的Hadoop,“Hadoop这个名字,实际上是Doug Cutting儿子的黄色玩具大象的名字,也表示着对于自己孩纸的爱。
Flink也如此具有特色,快速,灵巧的小松鼠就是其意思所在。

Flink的目标对于海量数据的的处理,要快速和灵活。
它就像一列高速行进的列车,向我们呼啸而来,朝着未来更实时、更稳定的大数据处理奔去。
这辆通向未来的车,我们上车可以迟,但一定不要错过。
2.设计流程
Flink 的官网主页地址:https://flink.apache.org/
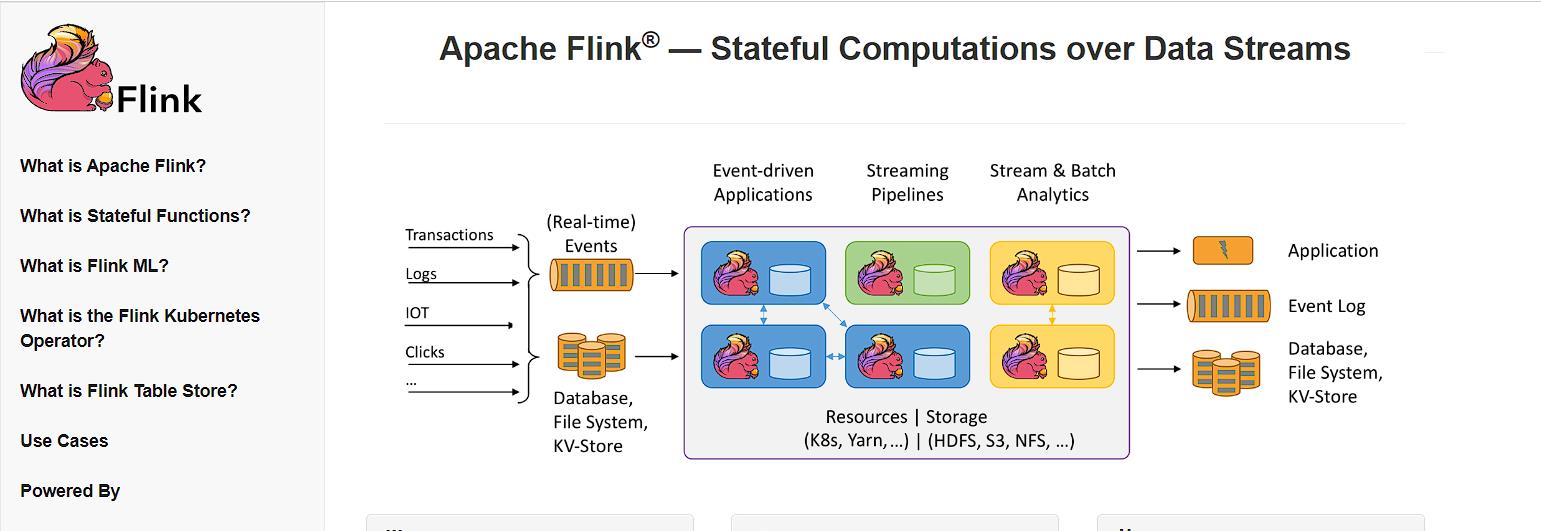
在官网的主页顶部,我们可以看到Flink的核心目标:
Stateful Computations over Data Streams
数据流上的有状态计算。
具体而言:Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
那么如何理解有状态计算呢?
有状态计算是指在程序计算过程中,在Flink程序内部存储计算产生的中间结果,并提供给后续Function或算子计算结果使用。
(比如,小明去车站坐大巴,大巴限载50人,小明上车后正好50人,于是发车了。这种人数的计算就是前面49个人数存储起来,加上小明1人,正好50人)
Flink 框架处理流程
Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
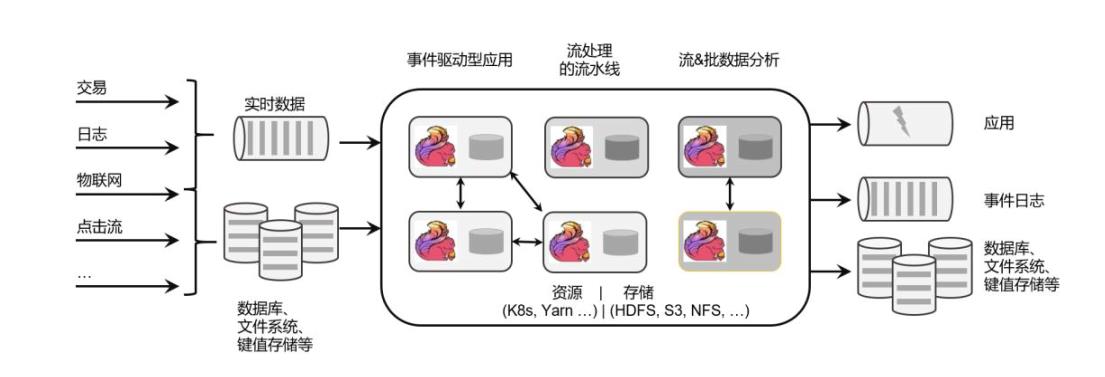
这里有很多专业词汇,我们从中至少可以提炼出一些容易理解的信息:Flink 是一个“框架”,是一个数据处理的“引擎”;既然是“分布式”,当然是为了应付大规模数据的应用场景了;另外,Flink 处理的是数据流。
所以,Flink 是一个流式大数据处理引擎。 而“内存执行速度”和“任意规模”,突出了 Flink 的两个特点:速度快、可扩展性强——这说的自然就是小松鼠的“快速”和“灵巧”了。
祝各位终有所成,收获满满 !!!
以上是关于Flink初识Flink快速又灵巧的主要内容,如果未能解决你的问题,请参考以下文章