Spark - RDD 的分区和Shuffle
Posted 小毕超
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark - RDD 的分区和Shuffle相关的知识,希望对你有一定的参考价值。
一、RDD 的分区
前面在学习 MapReduces 的时候就提到分区,在RDD中同样也存在分区的概念,本质上都是为了提高并行度,从而提高执行的效率,那在 Spark 中的分区该怎么设置呢?
首先分区不是越多越好,太多意味着任务数太多,调度任务也会耗时从而导致总体耗时增多,分区数太少的话,会导致一些节点分配不到任务,而某个分区数据量又大导致数据倾斜问题。
因此官方推荐的分区数是:partitionNum = (executor-cores * num-executor) * (2~3)
在 Spark 中可以通过创建 RDD 时指定分区的数量,比如:
var rdd = sc.textFile("D:/test/input", 5)
也可以通过 repartition 算子,动态调整分区的数量:
rdd = rdd.repartition(8)
或者使用 coalesce 算子修改分区数:
rdd = rdd.coalesce(numPartitions = 2, shuffle = false)
repartition 算子本质上就是 coalesce(numPartitions, shuffle = true)
如果 shuffle 参数指定为 false,运行计划中不会有 ShuffledRDD,也就没有 shuffled 过程,如果是增大分区,此时是一种宽依赖,如果 shuffle 参数指定为 false ,可以发现分区数不会发生变化,比如:
var rdd = sc.parallelize(1 to 100, 6)
println(rdd.getNumPartitions)
rdd = rdd.coalesce(numPartitions = 8, shuffle = false)
println(rdd.getNumPartitions)
此时分区数无法增大:
分区规则:
在 Spark 中的默认分区规则有两种,分别是RangePartitioner(范围分区),HashPartitioner(Hash分区),同样也支持自定义分区。
HashPartitioner 只作用于Key-Value类型的RDD,根据 key 的 hashCode 值和分区数求余,确定具体那个分区。
RangePartitioner 将一定范围内的数映射到某一个分区内,尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,一个分区中的元素肯定都是比另一个分区内的元素小或者大,但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。
自定义分区的话需要继承 Partitioner ,并在 getPartition 中接收数据给出具体分区数,如:
object PartitionerTest
case class MyPartition(numPartition: Int) extends Partitioner
//分区数
override def numPartitions: Int =
numPartition
//具体分区
override def getPartition(key: Any): Int =
val v = key.toString.toInt
if (v < 3)
0
else if (v >= 3 && v < 5)
1
else
2
def main(args: Array[String]): Unit =
val conf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val rdd = sc.parallelize(Seq(1, 2, 3, 4, 5, 2, 3), 2)
println(rdd.getNumPartitions)
val rdd1 = rdd.map((_, 1)).partitionBy(MyPartition(3))
println(rdd1.getNumPartitions)
二、RDD 的 Shuffle
分区的主要作用是用来实现并行计算,但是往往在进行数据处理的时候,例如 reduceByKey 等聚合操作时, 需要把 Key 相同的 Value 拉取到一起进行计算, 这个时候有可能这些 Key 相同的 Value 会坐落于不同的分区,为了让不同分区相同 Key 的数据都在 reduceByKey 的同一个 reduce 中处理,需要执行一个 all-to-all 的操作,在不同的分区之间拷贝数据, 必须跨分区聚集相同 Key 的所有数据,这个过程即 Shuffle 。
Spark 中的 Shuffle 有 Hash base shuffle 和 Sort base shuffle 以及 tungsten-sort shuflle ,默认使用的是 Sort base shuffle , Hash base shuffle 已经过时废弃。
Hash base shuffle:

大致的原理是分桶, 假设 Reducer 的个数为 R, 那么每个 Mapper 有 R 个桶,按照 Key 的 Hash 将数据映射到不同的桶中, Reduce 找到每一个 Mapper 中对应自己的桶拉取数据。
假设 Mapper 的个数为 M, 整个集群的文件数量是 M * R, 如果有 1000 个 Mapper 和 Reducer,则会生成 1000000 个文件, 这个量是非常巨大的。
Sort base shuffle:
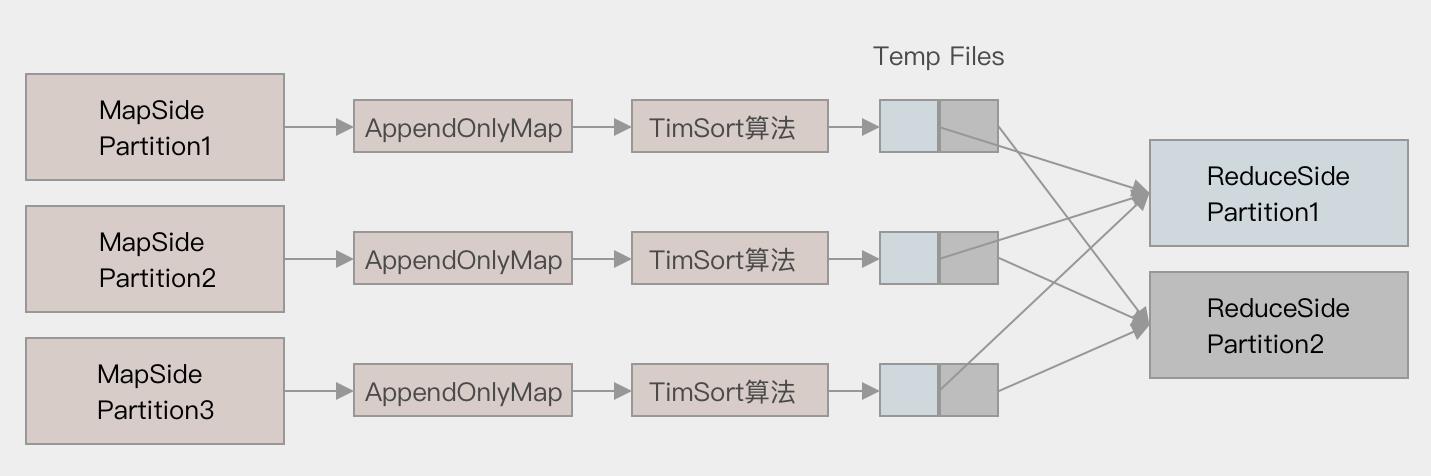
对于 Sort base shuffle ,Map 侧将数据全部放入一个叫做 AppendOnlyMap 的组件中,同时可以在这个特殊的数据结构中做聚合操作,然后通过一个类似于 MergeSort 的排序算法 TimSort 对 AppendOnlyMap 底层的 Array 排序,先按照 Partition ID 排序, 后按照 Key 的 HashCode 排序,最终每个 Map Task 生成一个 输出文件,Reduce Task 来拉取自己对应的数据,可以大幅度减少所产生的中间文件,从而能够更好的应对大吞吐量的场景,在 Spark 1.2 以后, 已经默认采用这种方式。
tungsten-sort:
与sort类似,tungsten-sort使用了堆外内存管理机制,内存使用效率更高。
修改默认的 Sort base shuffle 为 tungsten-sort :
conf.set("spark.shuffle.manager","tungsten-sort");
以上是关于Spark - RDD 的分区和Shuffle的主要内容,如果未能解决你的问题,请参考以下文章