linux-云服务器数据盘挂载失败导致进入维护模式
Posted 小肥的胖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux-云服务器数据盘挂载失败导致进入维护模式相关的知识,希望对你有一定的参考价值。
已经在华为云、AWS上面吃过这个亏了,老这样可不好,心怦怦跳的。
- 华为云是由于服务器升级配置后重启,数据盘名称变化导致进入维护模式。
- AWS则是由于重启后没有挂载上数据盘,手动编辑
/etc/fstab文件错误导致进入维护模式。
究其原因,就是因为/etc/fstab中的内容错误,导致服务器进入维护模式,此时无法通过ssh远程登录。目前知道两种方式解决:
1、自救。能够通过云服务器商提供的方式可以连接到服务器后台,同时拥有root账号,进入维护模式修改/etc/fstab文件后重启。
2、曲线自救。无法登录到服务器A后台,此时需要同区域另一台服务器B,在B服务器上将A服务器的系统盘挂载为数据盘,修改/path/to/mount/etc/fstab文件,修改后服务器A重新挂载上系统盘再启动。
3、提桶跑路,已经干了一件stupid的事情了,不要再干一件了。
自救
华为云服务器,挂载了200G的数据盘,在服务器升级配置后重启,但服务器远程不上,从华为云提供的VNC,用root账号登录维护模式,结果发现是因为配置在/etc/fstab中的数据盘没有挂载起来导致的。

查看磁盘列表,要挂载的/dev/vdb(200G那个)变成了/dev/sdb:
# fdisk -l
Disk /dev/sdb: 214.7 GB, 214748364800 bytes, 419430400 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/sda: 42.9 GB, 42949672960 bytes, 83886080 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x00063f90
Device Boot Start End Blocks Id System
/dev/sda1 * 2048 83886079 41942016 83 Linux
在/etc/fstab中写的内容是挂载/dev/vdb:
# cat /etc/fstab
UUID=fc1ecf74-b8b4-44e6-9178-1d9c6e64d7f1 / ext4 defaults 1 1
/dev/vdb /opt/wecon ext4 defaults 0 2
再看之前的操作记录,确实当时挂的是/dev/vdb没错:
# history | grep ext4
339 2022-06-07 16:35:55 root mkfs.ext4 /dev/vdb
341 2022-06-07 16:36:07 root mount -t ext4 /dev/vdb /opt/wecon
2212 2022-06-20 21:57:32 root history | grep ext4
所以怀疑这个设备名变了,找到华为云的人工服务,确实是这样的。
不建议采用在“/etc/fstab”直接指定设备名(比如/dev/vdb1)的方法,因为云中设备的顺序编码在关闭或者开启云服务器过程中可能发生改变,例如/dev/vdb1可能会变成/dev/vdb2,可能会导致云服务器重启后不能正常运行。
解决方法就是用磁盘的UUID来取代设备名,通过blkid获取设备的UUID:
blkid /dev/vdb
/dev/db1: UUID="0b3040e2-1367-4abb-841d-ddb0b92693df" TYPE="ext4"
然后在/etc/fstab中配置后重启系统:
# cat /etc/fstab
UUID=fc1ecf74-b8b4-44e6-9178-1d9c6e64d7f1 / ext4 defaults 1 1
UUID=0b3040e2-1367-4abb-841d-ddb0b92693df /opt/wecon ext4 defaults 0 2
曲线自救
同样的情况,发生在AWS,很显然我的实例不支持登录后台的方式,也没装会话管理器:
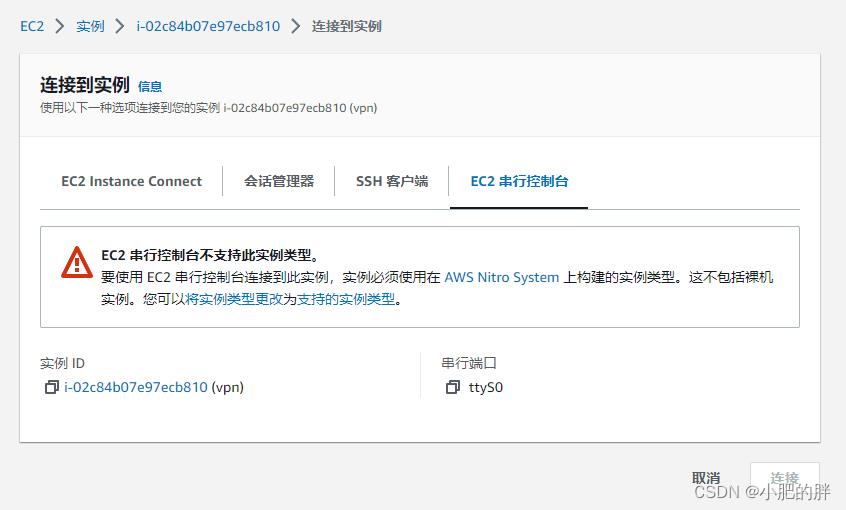
唯一能做的就是从系统日志这里查看确实进入了维护模式,这个时候就只能曲线自救了。
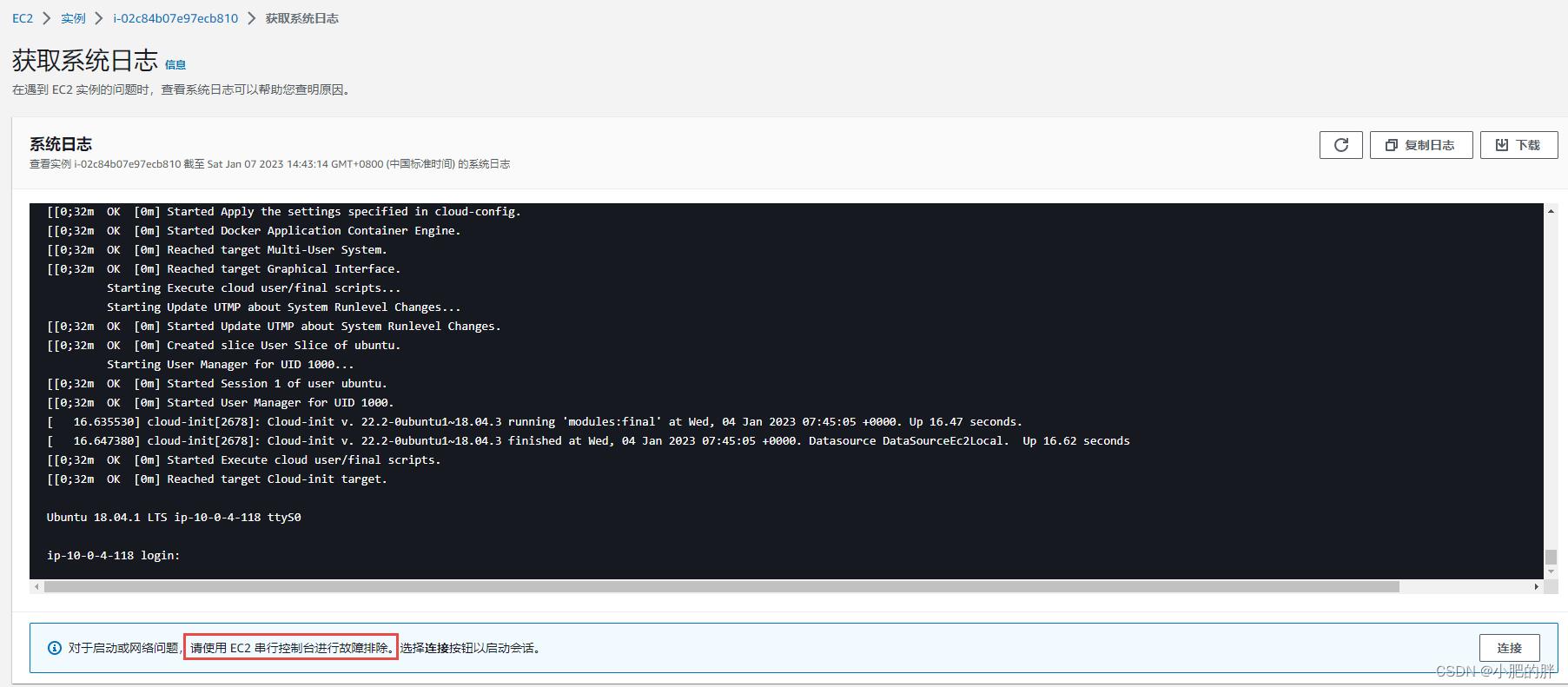
1、进入AWS EC2 实例页面,将处于紧急模式的实例A关机,将实例A的系统盘A(AWS中系统盘名称为/dev/sda1)分离。
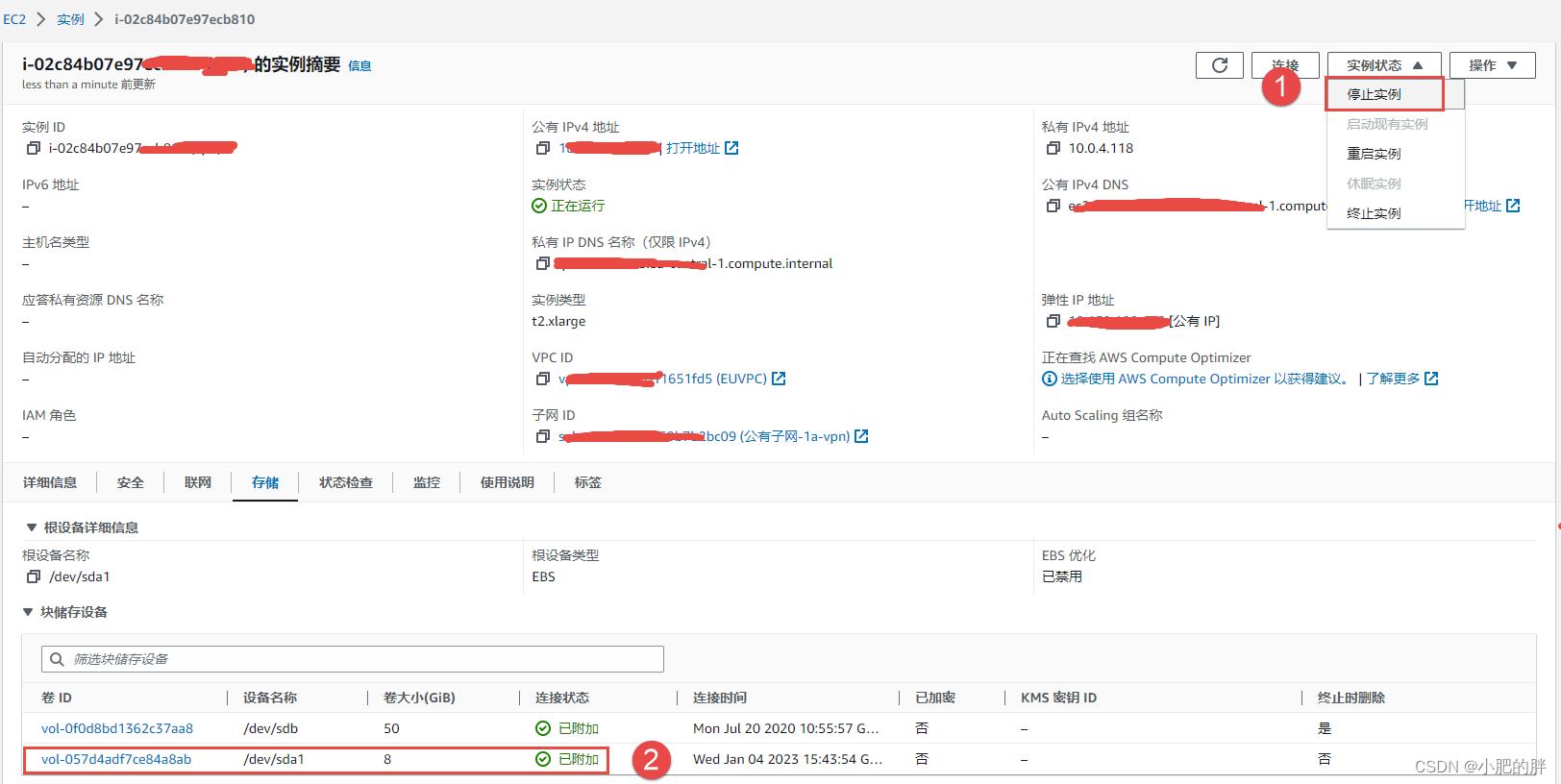
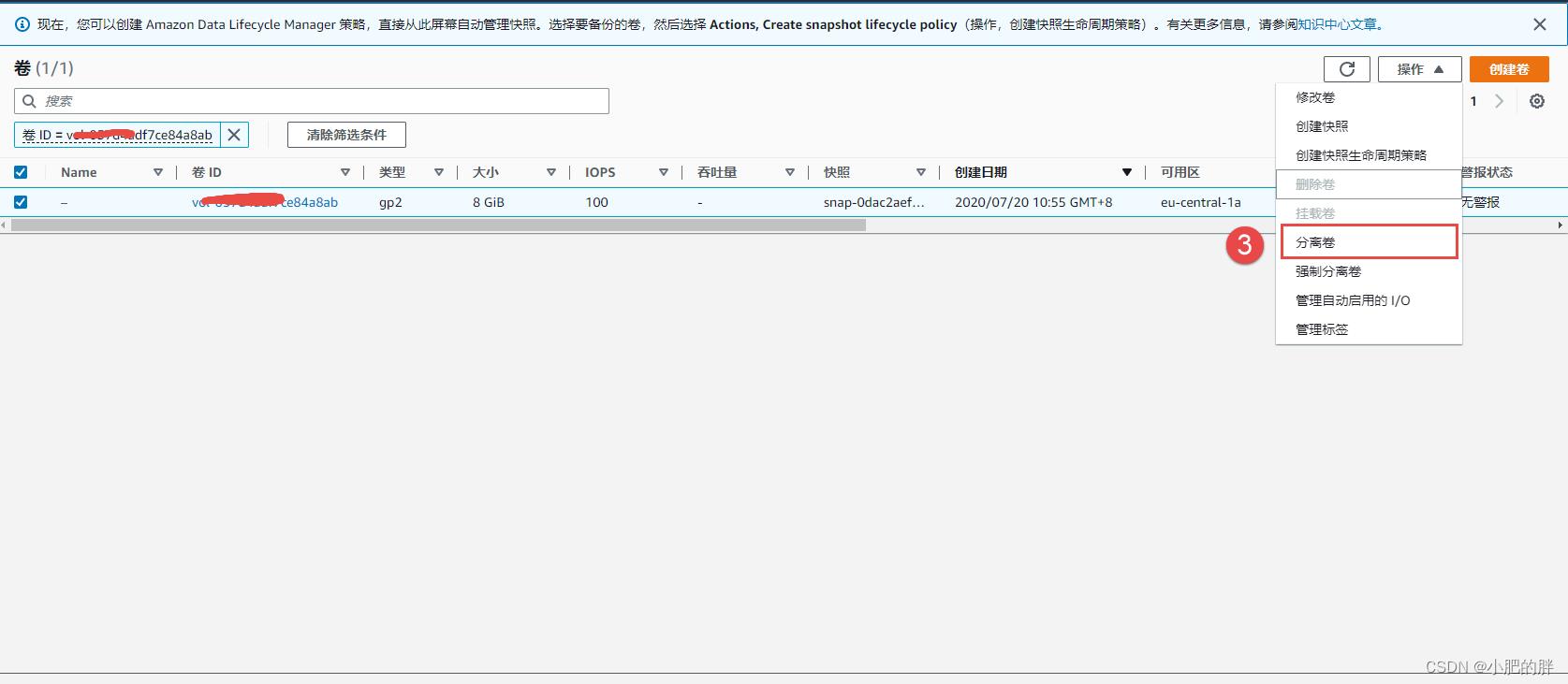
2、进入AWS EC2 实例页面,创建一个和实例A同区域的救援实例B。
3、进入AWS EC2 卷页面,将刚刚分离的系统盘A,挂载为实例B的数据盘B。
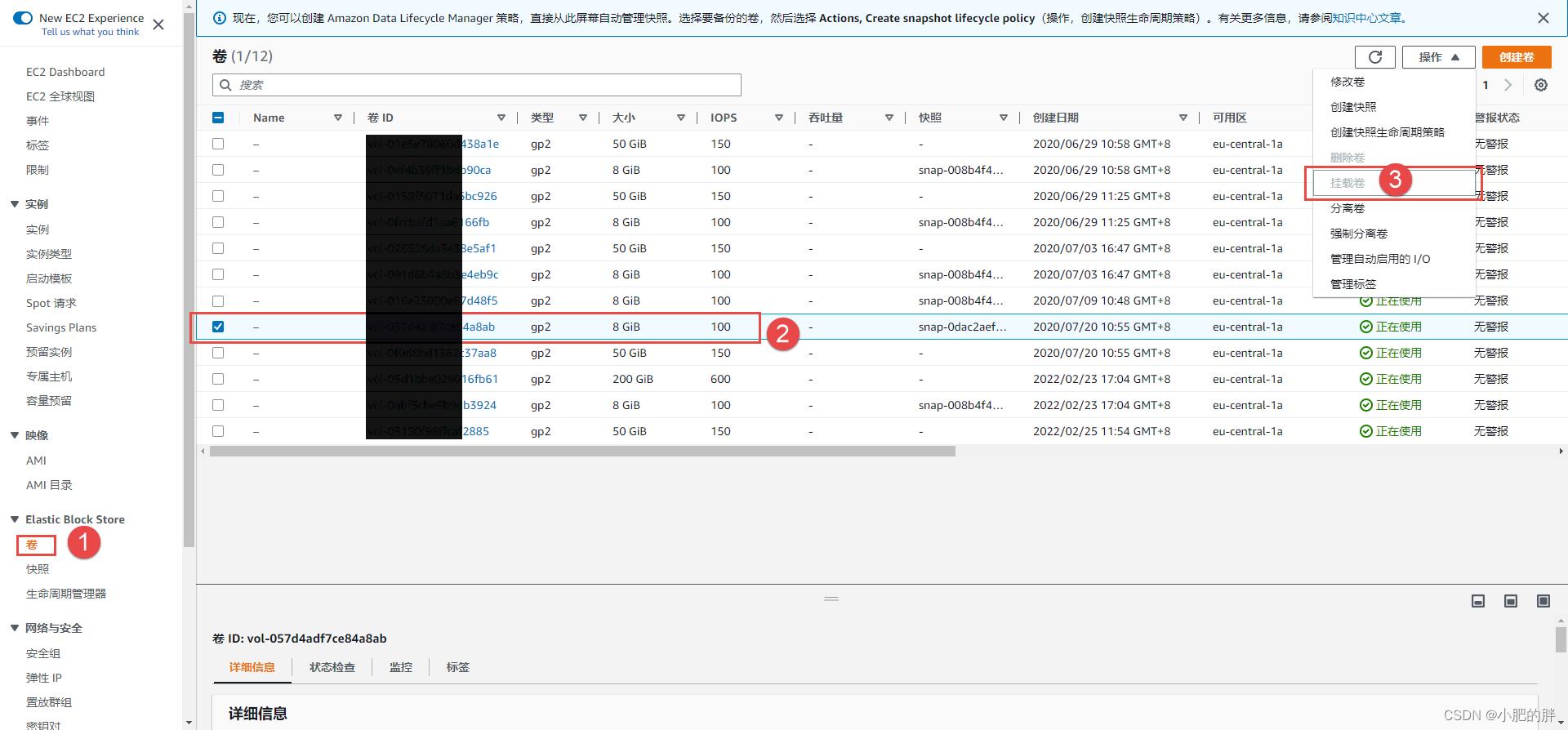
4、将实例B开机并ssh远程登录实例B进行操作。
用命令挂载数据盘B:
mkdir /mnt/rescue
mount /dev/xvdf /mnt/rescue
根据需要编辑数据盘B中的etc/fstab文件:
vi /mnt/rescue/etc/fstab
修改完成后,卸载数据盘B:
sudo umount /mnt/rescue
5、进入AWS EC2 实例页面,将实例B关机,数据盘B重新挂载为实例A的系统盘,启动的实例A就OK了。
关于fstab文件
cat /etc/fstab
LABEL=cloudimg-rootfs / ext4 defaults,discard 0 0
# 磁盘文件格式为ext4,默认参数,
UUID=91579631-dff2-4e3b-8d33-1da1f9ef6dc1 /mnt1 ext4 defaults 0 2
# 自动探测文件系统,默认参数,设备不存在也不报错
#UUID=91579631-dff2-4e3b-8d33-1da1f9ef6dc1 /mnt1 auto defaults,nofail 0 0
参考man fstab。
- 第一列:设备名、UUID、LABEL。一般用UUID,设备名可能会变化。
- 第二列:挂载点,设备挂载在哪个目录下。
- 第三列:磁盘文件系统的格式。一般是ext4、xfs之类的,有一个可选项是auto,当无法确定的时候可以填auto,让系统自动检测。
- 第四列:挂载参数,多个选项的情况下以逗号分割。
参考man 8 mount中FILESYSTEM-INDEPENDENT MOUNT OPTIONS一节,部分文件系统无关的选项如下:
Async/sync: 设置是否为同步方式运行,默认为async
auto/noauto: 当下载mount -a 的命令时,此文件系统是否被主动挂载。默认为auto
rw/ro: 是否以以只读或者读写模式挂载
exec/noexec: 限制此文件系统内是否能够进行”执行”的操作
user/nouser: 是否允许用户使用mount命令挂载
suid/nosuid: 是否允许SUID的存在
nofail: 即使设备不存在也不报错
defaults: 同时具有rw,suid,dev,exec,auto,nouser,async等默认参数的设置
......
参考man 8 mount中FILESYSTEM-SPECIFIC MOUNT OPTIONS一节,查看特定文件系统相关的选项。
- 第五列:能否被dump备份命令作用,dump是一个用来作为备份的命令。通常这个参数的值为0或者1
- 0:不要做dump备份
- 1:要每天进行dump的操作
- 2:不定日期的进行dump操作
- 第六列:是否检验扇区,开机的过程中,系统默认会以fsck检验我们系统是否为完整。
- 0:不要检验
- 1:最早检验(一般根目录会选择最早检验)
- 2:1级别检验完成之后进行检验
参考
- 华为云 - 设置开机自动挂载磁盘分区
- 排查 EC2 Linux 实例处于紧急模式的问题 (amazon.com)
- 什么?加块磁盘就开不开机了? - 知乎 (zhihu.com)
- linux中的/etc/fstab文件 (loadingok.com)
以上是关于linux-云服务器数据盘挂载失败导致进入维护模式的主要内容,如果未能解决你的问题,请参考以下文章