《Natural Language Processing with PyTorch》 Chapter 2: A Quick Tour of Traditional NLP 笔记
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Natural Language Processing with PyTorch》 Chapter 2: A Quick Tour of Traditional NLP 笔记相关的知识,希望对你有一定的参考价值。
《Natural Language Processing with PyTorch》 Chapter 2: A Quick Tour of Traditional NLP 笔记
这本书

本章的笔记里面涉及的理论内容在我记录的西湖大学张岳老师的introduction那个笔记里面基本都有提及,不过这篇主要是利用spaCy和NLTK做了一些实践
文章目录
- 《Natural Language Processing with PyTorch》 Chapter 2: A Quick Tour of Traditional NLP 笔记
- Corpora(语料库), Tokens, and Types
- Unigrams, Bigrams, Trigrams, …, N-grams
- Lemmas and Stems 基本词形和词根
- Categorizing Sentences and Documents
- Categorizing Words: POS Tagging 词性标注
- Categorizing Spans: Chunking and Named Entity Recognition
- Structure of Sentences
- Word Senses and Semantics 词义和语义
- Summary
- 参考资料
-
The goal of the chapter
-
Review some traditional NLP concepts and methods,书的后面部分主要讲深度学习
-
NLP & CL
We only focus on NLP in this book, but we may incorporate ideas from CL as necessary.
- Natural language processing (NLP, introduced in the previous chapter) and computa‐ tional linguistics (CL) are two areas of computational study of human language.
- NLP : NLP aims to develop methods for solving practical problems involving language, such as information extraction, automatic speech recognition, machine translation, sentiment analysis, question answering, and summarization.
- CL : CL employs computational methods to understand properties of human language.
这本书的文笔感觉不错哈哈哈,我练练转述顺便学习一下原来的表达
-
In literature(文献中), it is common to see a crossover of methods and researchers, from CL to NLP and vice versa(反之亦然).(It is common for CL and NLP to borrow methods and ideas from each other. )
Lessons from CL about language can be used to inform priors in NLP(指导NLP中的先验知识), and statistical and machine learning methods from NLP can be applied to answer questions CL seeks to answer.
🤔CL can provide insight into language that can be applied to NLP,and NLP’s statistical and machine learning techniques can be used to answer questions in CL
In fact, some of these questions have ballooned into disciplines of their own(演变成自己的学科), like phonology(音系学), morphology(形态学), syntax(句法学), semantics(语义学), and
pragmatics.(语用学)
- Natural language processing (NLP, introduced in the previous chapter) and computa‐ tional linguistics (CL) are two areas of computational study of human language.
Corpora(语料库), Tokens, and Types
-
All NLP methods begin with a text dataset, also called a corpus (plural: corpora).
Given the heavy machine learning focus of this book, we freely interchange the terms corpus and dataset throughout.
-
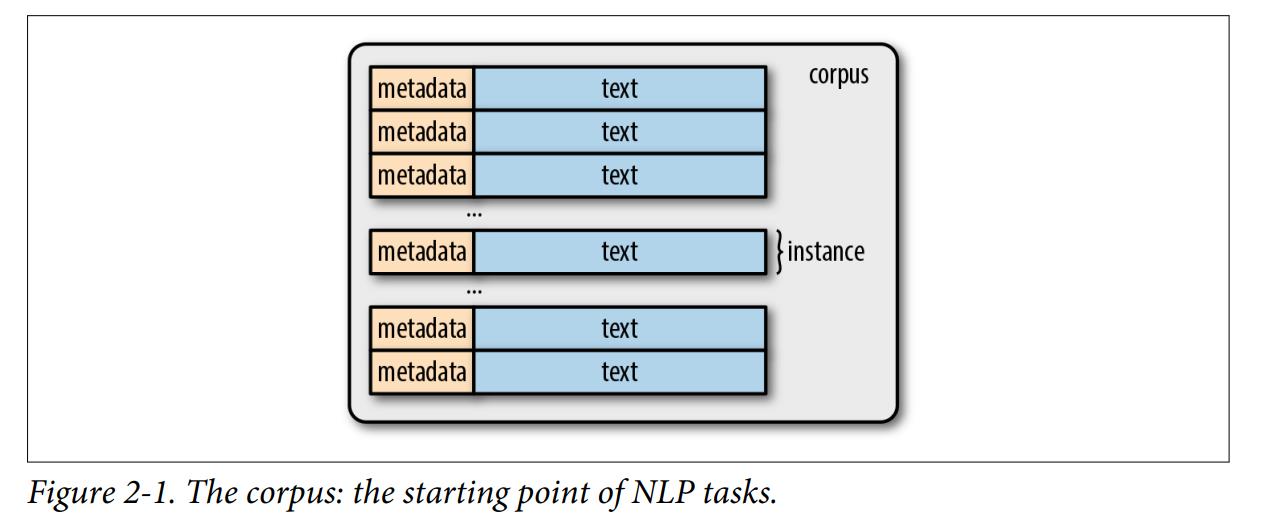
A corpus usually contains raw text (in ASCII or UTF-8) and any metadata associated with the text. The raw text is a sequence of characters (bytes), but most times it is useful to group those characters into contiguous(相邻的) units called tokens. In English, tokens correspond to words and numeric sequences separated by white-space characters or punctuation.
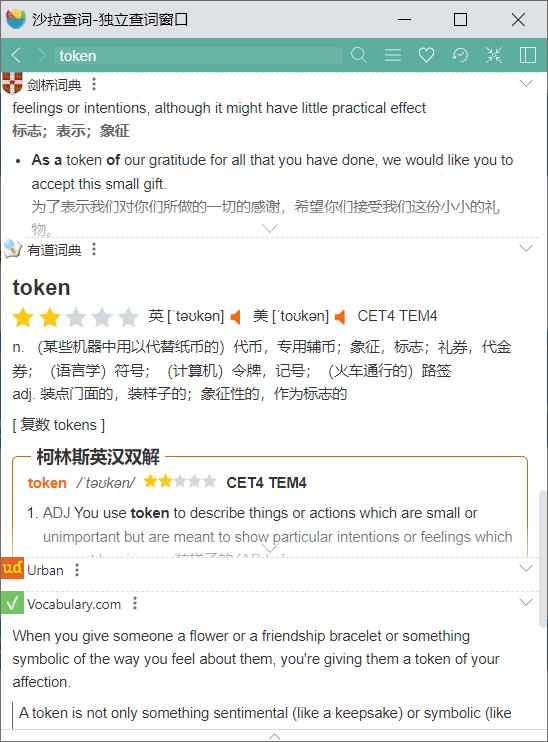
token的意思 ,不知道怎样用中文翻译更加准确一些 , token 是自然语言处理中用于对文本进行分析的最小单元,通常是文本中的单词或标点符号
In NLP, a token is a unit of analysis, such as a word or punctuation mark, in a text. Tokenization(符号化?) is the process of breaking a text into tokens. For example, the sentence “I went to the store.” might be tokenized into the following list of tokens: [“I”, “went”, “to”, “the”, “store”, “.”]
-
The metadata could be any auxiliary (辅助的) piece of information associated with the text, like identifiers, labels, and timestamps. In machine learning parlance(术语,说法), the text along with its metadata is called an instance or data point. The corpus is a collection of instances.
-
Types are unique tokens present in a corpus. The set of all types in a corpus is its vocabulary or lexicon. Words can be distinguished as content words and stopwords. Stopwords such as articles(冠词) and prepositions(介词) serve mostly a grammatical purpose, like filler holding the content words(例如填充内容词).
lexicon [ˈleksɪˌkɑn] 字典;(某语言或学科、某人或群体使用的)全部词汇
In NLP, stop words are words that are very common in a language and do not have much meaning on their own. They are often removed from texts in order to facilitate the analysis of the remaining words. Stop words are usually high-frequency words such as “the,” “a,” “and,” “is,” and “are,” and are often considered to be “noise” in the text.
For example, if you are trying to perform sentiment analysis on a text, stop words might not provide much information about the overall sentiment of the text. Therefore, it is common to remove stop words from the text before performing further analysis.
Different NLP tasks may have different sets of stop words, and it is also possible to customize the list of stop words for a particular task or language.
Tokenization
-
The process of breaking a text down into tokens is called tokenization.
-
For example, there are six tokens in the Esperanto sentence “Maria frapis la verda sorĉistino.” Tokenization can become more complicated than simply splitting text based on non‐ alphanumeric (非字母)characters, as is demonstrated in Figure 2-2.
Translation: “Mary slapped the green witch.”(Mary拍了拍绿色女巫) We use this sentence as a running example in this chapter. We acknowledge the example is rather violent, but our use is a hat-tip(致敬) to the most famous artificial intelligence textbook of our times (Russell and Norvig, 2016), which also uses this sentence as a running example.

-
For agglutinative languages like Turkish(像土耳其语这样的聚合语言), splitting on whitespace and punctuation might not be sufficient, and more specialized techniques might be warranted.(有必要)
agglutinative :(of a language) forming words predominantly by agglutination, rather than by inflection or by using isolated elements. Examples include Hungarian, Turkish, Korean, and Swahili
-
It may be possible to entirely circumvent( [ˈsɜrkəmˌvent],规避) the issue of tokenization in some neural network models by representing text as a stream of bytes; this becomes very important for agglutinative languages.
用NLTK、spaCy进行tokenization

grunt work:乏味的重活
spaCy
spaCy is a free, open-source library for natural language processing (NLP) in Python. It is designed to help developers build applications that process and analyze large volumes of text efficiently. spaCy provides tools for tasks such as tokenization (breaking text into individual words and punctuation), part-of-speech tagging (identifying the part of speech of each word), and named entity recognition (identifying named entities in a text, such as people, organizations, and locations). It also includes pre-trained machine learning models that can be used for tasks such as text classification, summarization, and translation. spaCy is widely used in industry and academia(学术界) for a variety of NLP tasks.
-
书上给的代码
import spacy nlp = spacy.load('en') text = "Mary, don’t slap the green witch" print([str(token) for token >in nlp(text.lower())])有两个问题,一个是下面那个">"是笔误?
另一个是
spacy.load('en')
-
解决方法一,按照提示里面的 创建blank model
import spacy nlp = spacy.blank("en") text = "Mary, don’t slap the green witch" print([str(token) for token in nlp(text.lower())]) """ """运行结果:
['mary', ',', 'do', 'n’t', 'slap', 'the', 'green', 'witch'] -
解决方法二
去官网看了看

于是在终端里面输入
python -m spacy download en_core_web_sm
import spacy
nlp2 = spacy.load("en_core_web_sm")
text = "Mary, don’t slap the green witch"
print([str(token) for token in nlp2(text.lower())])
"""
这段代码将使用 spaCy 库将文本 "Mary, don’t slap the green witch" 转换为小写并分词。
首先,它导入了 spaCy 库。然后,它使用 spacy.load() 函数加载了英文模型 "en_core_web_sm"。接下来,它创建了一个 nlp2 变量,并将其初始化为英文模型。
然后,它定义了一个文本字符串 "Mary, don’t slap the green witch"。接着,它使用 nlp2() 函数将文本转换为小写,并使用列表推导式将其分词。最后,它使用 print() 函数打印分词后的结果。
因此,这段代码的输出应该是将文本分词后的结果,例如:['mary', ',', 'do', "n't", 'slap', 'the', 'green', 'witch']。
"""
得到相同结果
NLTK
NLTK, or Natural Language Toolkit, is a free, open-source library for natural language processing (NLP) in Python. It is designed to help developers build applications that can analyze and understand human language. NLTK provides tools for tasks such as tokenization (breaking text into individual words and punctuation), part-of-speech tagging (identifying the part of speech of each word), and named entity recognition (identifying named entities in a text, such as people, organizations, and locations). It also includes a large collection of texts in a variety of languages, as well as tools for working with these texts, such as text corpora and lexical resources. NLTK is widely used in academia and industry for a variety of NLP tasks.
-
推特的那个例子
from nltk.tokenize import TweetTokenizer tweet=u"Snow White and the Seven Degrees#MakeAMovieCold@midnight:-)" tokenizer = TweetTokenizer() print(tokenizer.tokenize(tweet.lower())) """ 这段代码使用 NLTK 库的 TweetTokenizer 类将文本 "Snow White and the Seven Degrees#MakeAMovieCold@midnight:-)" 转换为小写并进行分词。 首先,它导入了 NLTK 库中的 TweetTokenizer 类。然后,它定义了一个 tweet 字符串,并创建了一个 tokenizer 变量,并将其初始化为 TweetTokenizer 类的实例。 接下来,它使用 tokenize() 方法将 tweet 字符串转换为小写,并使用分词器进行分词。最后,它使用 print() 函数打印分词后的结果。 因此,这段代码的输出应该是将文本分词后的结果,例如:['snow', 'white', 'and', 'the', 'seven', 'degrees', '#makeamoviecold', '@midnight', ':-)']。 """运行结果:
['snow', 'white', 'and', 'the', 'seven', 'degrees', '#makeamoviecold', '@midnight', ':-)']
Unigrams, Bigrams, Trigrams, …, N-grams
N-grams are fixed-length (n) consecutive token sequences occurring in the text.
N-grams是指在文本中出现的固定长度(n)的连续token序列
A bigram(二元词组) has two tokens, a unigram(一元词组) one.
-
Generating n-grams from a text is straightforward enough 👇
def n_grams(text, n): """ takes tokens or text and returns a list of n-grams """ return [text[i:i+n] for i in range(len(text)-n+1)] cleaned = ['mary', ',',"n't",'slap', 'the', 'green', 'witch', '.'] print(n_grams(cleaned, 3))运行结果:
[['mary', ',', "n't"], [',', "n't", 'slap'], ["n't", 'slap', 'the'], ['slap', 'the', 'green'], ['the', 'green', 'witch'], ['green', 'witch', '.']] -
这是手写的,那如何用spacy或者nltk实现呢
-
spaCy
import spacy nlp = spacy.load('en_core_web_sm') def n_grams(text, n): doc = nlp(text) ngrams = [] for i in range(len(doc)-n+1): ngrams.append(doc[i:i+n]) return ngrams bigrams = n_grams("I am a cat", 2) print(bigrams) bigrams_text = [bigram.text for bigram in bigrams] print(bigrams_text)[I am, am a, a cat] ['I am', 'am a', 'a cat'] -
nltk
import nltk def n_grams(text, n): tokens = nltk.word_tokenize(text) ngrams = [] for i in range(len(tokens)-n+1): ngrams.append(tokens[i:i+n]) return ngrams bigrams = n_grams("I am a cat", 2) print(bigrams) bigrams_text = [' '.join(bigram) for bigram in bigrams] print(bigrams_text)[['I', 'am'], ['am', 'a'], ['a', 'cat']] ['I am', 'am a', 'a cat']一开始用NLTK遇到这个报错:
"name": "LookupError",This error is usually caused by a missing or outdated NLTK data package.
To fix this error, you will need to download the necessary data package by running the following command in your Python environment:
nltk.download('punkt')This will download the
punktdata package, which contains the necessary data for the NLTK word tokenizer.After downloading the data package, try running the code again. It should now be able to create the n-grams as expected.
确实下完了就解决了

-
-
For some situations in which the subword information itself carries useful information, one might want to generate character n-grams. For example, the suffix(后缀) “-ol” in “methanol” (甲醇)indicates it is a kind of alcohol; if your task involved classifying organic compound(有机化合物) names, you can see how the subword information captured by n-grams can be useful. In such cases, you can reuse the same code, but treat every character n-gram as a token.
Lemmas and Stems 基本词形和词根
lemma
In natural language processing (NLP), a lemma (also known as a base form or dictionary form) is the base form of a word that is used to represent all of its inflected forms. For example, the lemma of the word “jumps” is “jump”, the lemma of the word “running” is “run”, and the lemma of the word “better” is “good”.
Lemmatization is the process of reducing a word to its base form, which is useful for many NLP tasks such as text classification, information retrieval, and machine translation. By converting all inflected forms of a word to its lemma, you can reduce the dimensionality of your text data and eliminate some of the noise caused by variations in word form.
-
Lemmas are root forms of words. Consider the verb fly. It can be inflected into many different words—flow, flew, flies, flown, flowing, and so on—and fly is the lemma for all of these seemingly different words. Sometimes, it might be useful to reduce the tokens to their lemmas to keep the dimensionality of the vector representation low(可以降低向量表示的维度). This reduction is called lemmatization(这种简化称为词形还原)
-
spaCy
spaCy, for example, uses a predefined dictionary, called WordNet, for extracting lemmas, but lemmatization can be framed as a machine learning problem requiring an understanding of the morphology of the language.
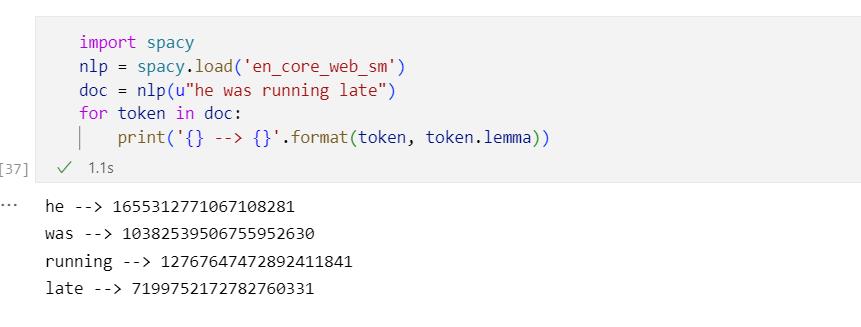
import spacy nlp = spacy.load('en_core_web_sm') doc = nlp(u"he was running late") for token in doc: print(' --> '.format(token, token.lemma_))输出结果
he --> he was --> be running --> run late --> late好奇那个lemma_ ,我改成lemma之后输出的是这样
-
NLTK
需要先
nltk.download('wordnet')|
WordNet is a large lexical database of English, developed at Princeton University. It groups English words into sets of synonyms 同义词 (synsets), provides short, general definitions, and records the various semantic relations between these synonym sets. WordNet can be used to help disambiguate word meanings and to generate human-readable text.The
WordNetLemmatizerclass is a lemmatizer that uses the WordNet database to lookup lemmas for words. It is part of thenltk.stemmodule in the Natural Language Toolkit (NLTK) library.To use the
WordNetLemmatizer, you will need to have the WordNet data package installed in your Python environment. You can install the package by running the following command:nltk.download('wordnet')Once the data package is installed, you can create a
WordNetLemmatizerobject and use itslemmatizemethod to lemmatize words in your text.import nltk from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer() text = "he was running late" tokens = nltk.word_tokenize(text) lemmas = [lemmatizer.lemmatize(token) for token in tokens] print(lemmas) """ Note that the lemmatizer may not always produce the expected results, as it relies on the part of speech tags of the words to determine their lemma. In the example above, the lemmatizer has lemmatized "was" as "wa" because it has been tagged as a verb rather than a noun. """运行结果:
['he', 'wa', 'running', 'late']-
那么我想还原was为be怎么做 ?
import nltk from nltk.stem import WordNetLemmatizer from nltk.corpus import wordnet lemmatizer = WordNetLemmatizer() text = "he was running late" tokens = nltk.word_tokenize(text) lemmas = [lemmatizer.lemmatize(token, wordnet.VERB) for token in tokens] print(lemmas)To lemmatize the word “was” as “be” using the
WordNetLemmatizer, you will need to provide the part of speech of the word as an additional argument to thelemmatizemethod.The
lemmatizemethod takes two arguments: the word to be lemmatized and its part of speech. The part of speech should be specified using a tag from the WordNet part of speech tags, which are different from the Penn Treebank tags used by thepos_tagfunction.This code would output the following list of lemmas:
['he', 'be', 'run', 'late'].Note that the lemmatizer may not always produce the expected results, as it relies on the part of speech tags of the words to determine their lemma. In the example above, the lemmatizer has lemmatized “was” as “be” because it has been tagged as a verb rather than a noun.
-
stems
To understand the difference between stemming and lemmatization, consider the word “geese.” Lemmatization produces “goose,” whereas stemming produces “gees.”
Stemming is the poor-man’s lemmatization. It involves the use of handcrafted rules to strip endings of words to reduce them to a common form called stems. Popular stemmers often implemented in open source packages include the Porter and Snow‐ ball stemmers.
书上没给示例,我去找找
-
NLTK
To perform stemming using the Porter stemmer in NLTK, you can use the
PorterStemmerclass from thenltk.stem.portermodule.Here is an example of how you could use the Porter stemmer to stem a list of words:
from nltk.stem.porter import PorterStemmer stemmer = PorterStemmer() words = ['run', 'running', 'ran', 'runs', 'easily'] stems = [stemmer.stem(word) for word in words] print(stems)This code would output the following list of stems:
['run', 'run', 'ran', 'run', 'easili'].You can also use the Snowball stemmer, which is a more advanced stemmer that supports multiple languages. To use the Snowball stemmer in NLTK, you can use the
SnowballStemmerclass from thenltk.stem.snowballmodule.Here is an example of how you could use the Snowball stemmer to stem a list of words:
import nltk from nltk.stem.snowball import SnowballStemmer stemmer = SnowballStemmer('english') words = ['run', 'running', 'ran', 'runs', 'easily'] stems = [stemmer.stem(word) for word in words] print(stems)This code would output the same list of stems as the Porter stemmer:
['run', 'run', 'ran', 'run', 'easili'] -
spaCy
查到的结果是spaCy没有直接用于stemming的包

Categorizing Sentences and Documents
-
Categorizing or classifying documents is probably one of the earliest applications of NLP.
-
The TF and TF-IDF representations are immediately useful for classifying and categorizing longer chunks of text such as documents or sentences. Problems such as assigning topic labels, predicting sentiment of reviews, filtering spam emails, language identification, and email triaging(邮件分类) can be framed as supervised document classification problems. (Semi-supervised versions, in which only a small labeled dataset is used, are incredibly useful, but that topic is beyond the scope of this book.)
Triaging is the process of prioritizing tasks or issues based on their importance or urgency. In software development, triaging often refers to the process of reviewing and prioritizing bug reports and feature requests in order to determine which ones should be addressed first.
The goal of triaging is to ensure that resources are focused on the most important tasks and that important issues are addressed in a timely manner. In software development, this can help to ensure that bugs are fixed and features are implemented efficiently, resulting in a better product for users.
Email triaging is the process of reviewing and organizing incoming emails in order to prioritize and respond to them in an efficient manner. This can involve sorting emails into different categories based on their importance or relevance, marking them as read or unread, or moving them to different folders or labels.
Categorizing Words: POS Tagging 词性标注
We can extend the concept of labeling from documents to individual words or tokens. A common example of categorizing words is part-of-speech (POS) tagging.
-
spaCy示例 Part-of-speech tagging
import spacy nlp = spacy.load('en_core_web_sm') doc = nlp(u"Mary slapped the green witch.") for token in doc: print(' - '.format(token, token.pos_))Mary - PROPN slapped - VERB the - DET green - ADJ witch - NOUN . - PUNCTThe
.pos_attribute returns the part-of-speech (POS) tag of a token, which indicates the role that the token plays in a sentence. In this example, the POS tags are abbreviations in the Penn Treebank POS tag set.PROPN: proper nounVERB: verbDET: determiner 限定词(置于名词前起限定作用,如 the、some、my 等)ADJ: adjectiveNOUN: nounPUNCT: punctuation
Categorizing Spans: Chunking and Named Entity Recognition
Chunking
Chunking是指将文本中的单词或短语分类为更大的结构,而Named Entity Recognition是指识别文本中的实体,如人名、地名、机构名等
Chunking in NLP is the process of taking a sequence of words and breaking it down into smaller chunks or phrases. This can be done by identifying nouns, verbs, adjectives etc., which are then grouped together to form meaningful units that make up sentences. Chunking helps with tasks such as Named Entity Recognition (NER), where entities like people’s names or locations need to be identified from text data.
Shallow parsing, also known as chunking or light parsing, is a natural language processing technique that involves extracting partial syntactic(句法) structure from a text. Shallow parsing typically involves identifying noun phrases and verb phrases in a sentence, but it does not provide a complete syntactic analysis of the sentence.
Shallow parsing is a less computationally intensive approach to syntactic analysis than full parsing, which involves extracting the complete syntactic structure of a sentence. It is often used as a preprocessing step for tasks such as information extraction and text classification, where a complete syntactic analysis is not necessary.
Shallow parsing can be performed using a variety of tools and techniques, including regular expressions, rule-based systems, and machine learning-based approaches. In Python, the Natural Language Toolkit (NLTK) library provides tools for performing shallow parsing, such as the
nltk.chunkmodule and thenltk.ne_chunkfunction.
Often, we need to label a span of text; that is, a contiguous multitoken boundary. For example, consider the sentence, “Mary slapped the green witch.” We might want to identify the noun phrases (NP) and verb phrases (VP) in it, as shown here: [NP Mary] [VP slapped] [the green witch]. This is called chunking or shallow parsing. Shallow parsing aims to derive higher-order units composed of the grammatical atoms, like nouns, verbs, adjectives, and so on.
It is possible to write regular expressions over the part-of-speech tags to approximate shallow parsing if you do not have data to train models for shallow parsing.
Fortunately, for English and most extensively spoken languages, such data and pretrained models exist.
-
An example of shallow parsing using spaCy
import spacy nlp = spacy.load('en_core_web_sm') doc = nlp(u"Mary slapped the green witch.") for chunk in doc.noun_chunks: print (' - '.format(chunk, chunk.label_))Mary - NP the green witch - NP -
我再用NLTK试试
import nltk from nltk.chunk import RegexpParser # Define a grammar for noun phrases grammar = r"NP: <DT>?<JJ>*<NN>" # Create a chunk parser cp = RegexpParser(grammar) # Tokenize and POS tag the text text = "The quick brown fox jumps over the lazy dog." tokens = nltk.word_tokenize(text) pos_tags = nltk.pos_tag(tokens) # Perform shallow parsing chunks = cp.parse(pos_tags) # Print the chunks print(chunks)Here, the grammar defines a noun phrase (NP) as a sequence of determiners (DT), adjectives (JJ), and nouns (NN). The
RegexpParseruses this grammar to identify noun phrases in the text and create a tree representation of the chunks.(S (NP The/DT quick/JJ brown/NN) (NP fox/NN) jumps/VBZ over/IN (NP the/DT lazy/JJ dog/NN) ./.)These are part-of-speech (POS) tags, which are abbreviations that indicate the role that a word plays in a sentence. In the code above , the POS tags are in the Penn Treebank POS tag set, which is a widely used POS tag set that consists of 46 tags.
Here is a list of the POS tags used in the code, along with their meanings:
DT: determinerJJ: adjectiveNN: nounVBZ: verb, 3rd person singular presentIN: preposition
The
RegexpParseruses these POS tags to identify noun phrases in the text according to the grammar that is defined.
NER
Another type of span that’s useful is the named entity. A named entity is a string mention of a real-world concept like a person, location, organization, drug name, and so on.书上给的例子

还是用那俩包来试试
-
NLTK,需要先
nltk.download('maxent_ne_chunker') nltk.download('words')


然后
import nltk
# Tokenize and POS tag the text
text = "John Smith works for Google in London."
tokens = nltk.word_tokenize(text)
pos_tags = nltk.pos_tag(tokens)
# Use the NE chunker to extract named entities
chunker = nltk.ne_chunk(pos_tags)
# Print the named entities and their labels
for tree in chunker:
if hasattr(tree, 'label'):
print(tree.label(), ' '.join(leaf[0] for leaf in tree.leaves()))
PERSON John
PERSON Smith
GPE Google
GPE London
In named entity recognition (NER), GPE stands for “geopolitical entity.” It is a label used to identify named entities that represent geopolitical entities, such as countries, cities, and states.
-
spaCy
import spacy nlp = spacy.load('en_core_web_sm') # Tokenize and tag the text text = "John Smith works for Google in London." doc = nlp(text) # Extract named entities and their labels for ent in doc.ents: print(ent.text, ent.label_)John Smith PERSON Google ORG London GPE
Structure of Sentences
-
Whereas shallow parsing identifies phrasal(短语的) units, the task of identifying the relationship between them is called parsing.
下图展示了成分分析(constituent parse)
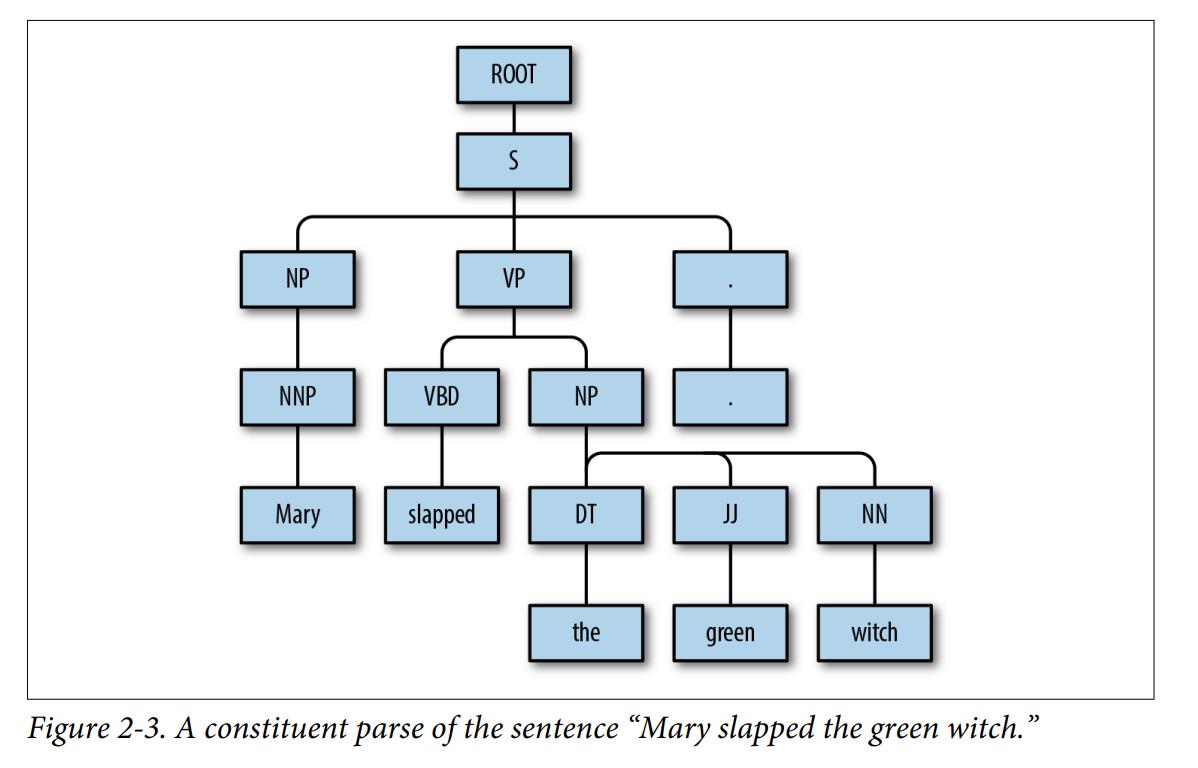
-
Another, possibly more useful, way to show relationships is using dependency parsing.

-
书上没给例子,不过还是来实践一下
-
NLTK 查资料查到是要用Stanford的一个工具 Stanford-CoreNLP-API-in-NLTK
https://stackoverflow.com/a/33808164/18159372
去GitHub上面照着配置的教程做
cd ~ wget http://nlp.stanford.edu/software/stanford-corenlp-full-2018-02-27.zip unzip stanford-corenlp-full-2018-02-27.zip cd stanford-corenlp-full-2018-02-27 java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer \\ -preload tokenize,ssplit,pos,lemma,ner,parse,depparse \\ -status_port 9000 -port 9000 -timeout 15000 &再接着给的demo做
from nltk.parse import CoreNLPParser parser = CoreNLPParser(url='http://localhost:9000') list(parser.parse('What is the airspeed of an unladen swallow ?'.split()))但是遇到了这个问题, 原因难道是我用的是codespace???

先是去看了GitHub的issue,我查connection,没有查到我想要的

-
emm 好像一下子解决不了,先摆了… 看spaCy
-
-
spaCy
- 官方文档DependencyParser
Word Senses and Semantics 词义和语义
-
Words have meanings, and often more than one. The different meanings of a word are called its senses. WordNet, a long-running lexical resource project from Princeton University, aims to catalog the senses of all (well, most) words in the English lan‐ guage, along with other lexical relationships.(普林斯顿大学的WordNet项目旨在编目英语中所有(大多数)单词的词义以及其他词汇关系)
-
The decades of effort that have been put into projects like WordNet are worth availing yourself of, even in the presence of modern approaches.
-
Word senses can also be induced from the context—automatic discovery of word senses from text was actually the first place semi-supervised learning was applied to NLP.
-
书上脚注给了个网站:BabelNet | 最大的多语言百科全书式的字典和语义网络
这个网站有点意思
Summary
In this chapter, we reviewed some basic terminology and ideas in NLP that should be handy in future chapters. This chapter covered only a smattering(略知)of what traditional NLP has to offer. We omitted significant aspects of traditional NLP because we want to allocate the bulk(主体) of this book to the use of deep learning for NLP.
It is, however, important to know that there is a rich body of NLP research work that doesn’t use neural networks, and yet is highly impactful (i.e., used extensively in building pro‐ duction systems). The neural network–based approaches should be considered, in many cases, as a supplement(补充)and not a replacement for traditional methods. Experienced practitioners often use the best of both worlds to build state-of-the-art systems.
然后书上列出了一些学习traditional NLP的推荐的资料
参考资料
以上是关于《Natural Language Processing with PyTorch》 Chapter 2: A Quick Tour of Traditional NLP 笔记的主要内容,如果未能解决你的问题,请参考以下文章