Redis为什么这么快 - 秒杀面试官系列
Posted 「已注销」
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis为什么这么快 - 秒杀面试官系列相关的知识,希望对你有一定的参考价值。
原文地址:码农在新加坡的个人博客
前言
Redis作为非关系型内存数据库,只要是一个互联网公司都会使用到。Redis相关的问题可以说是面试必问的。
而作为一个程序员,尤其是一个后端程序员,如果你会Redis,毫不夸张地说,面试通过率可以增加50%。
你肯定听说过:Redis很快,有多快呢?
首先,Redis有多快?它的单机QPS可达100K。
我们先来看看Redis官网的性能基准数据。
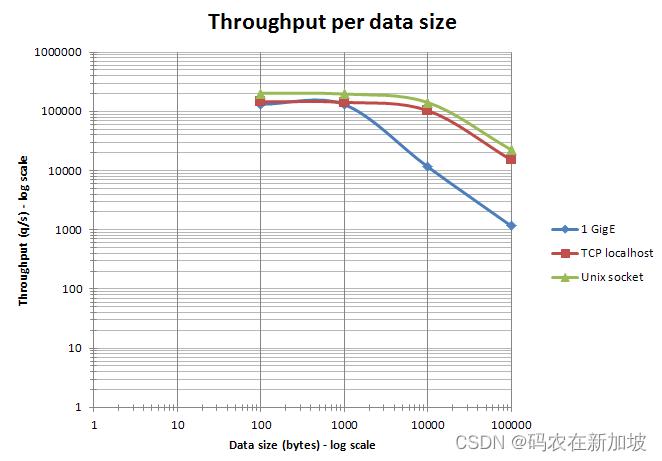
Redis在数据大小为1000 byte的时候能达到100K以上的QPS。
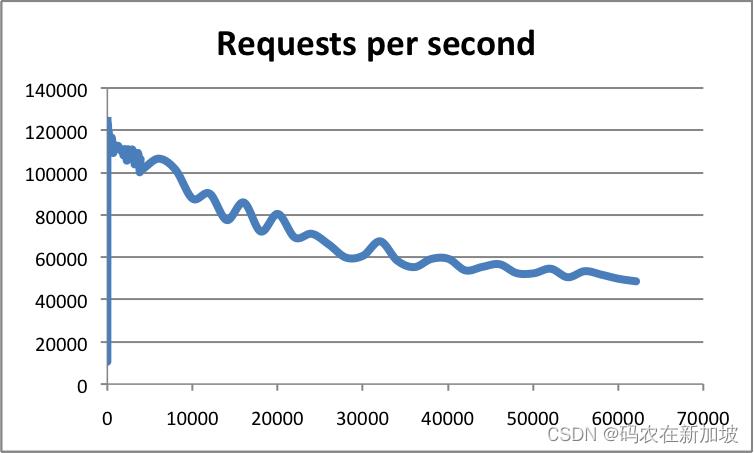
同时在6K个同时连接的时候依旧能保持50K以上的QPS。
而在同等机器配置下的mysql的QPS大概在2k ~ 4k左右。
所以Redis作为内存数据库优势就出来了。
Redis为什么这么快
面试官:Redis为什么这么快。
你:因为它是基于内存的。
面试官:还有吗?
你:嗯,这个。。。
面试官:那你先回去等通知吧。
这篇文章就带你理解Redis为什么这么快,让你面试不再卡壳。
Redis这么快有至少4个原因。
- 基于内存
- IO多路复用
- 单线程模型
- 高效的自定义数据结构
基于内存
我们来看看计算器硬件的运算速度。硬件的速度是金字塔模型,最慢的是机械硬盘,处理速度大概为1-10毫秒,最快的是寄存器,处理速度为0.3纳秒。
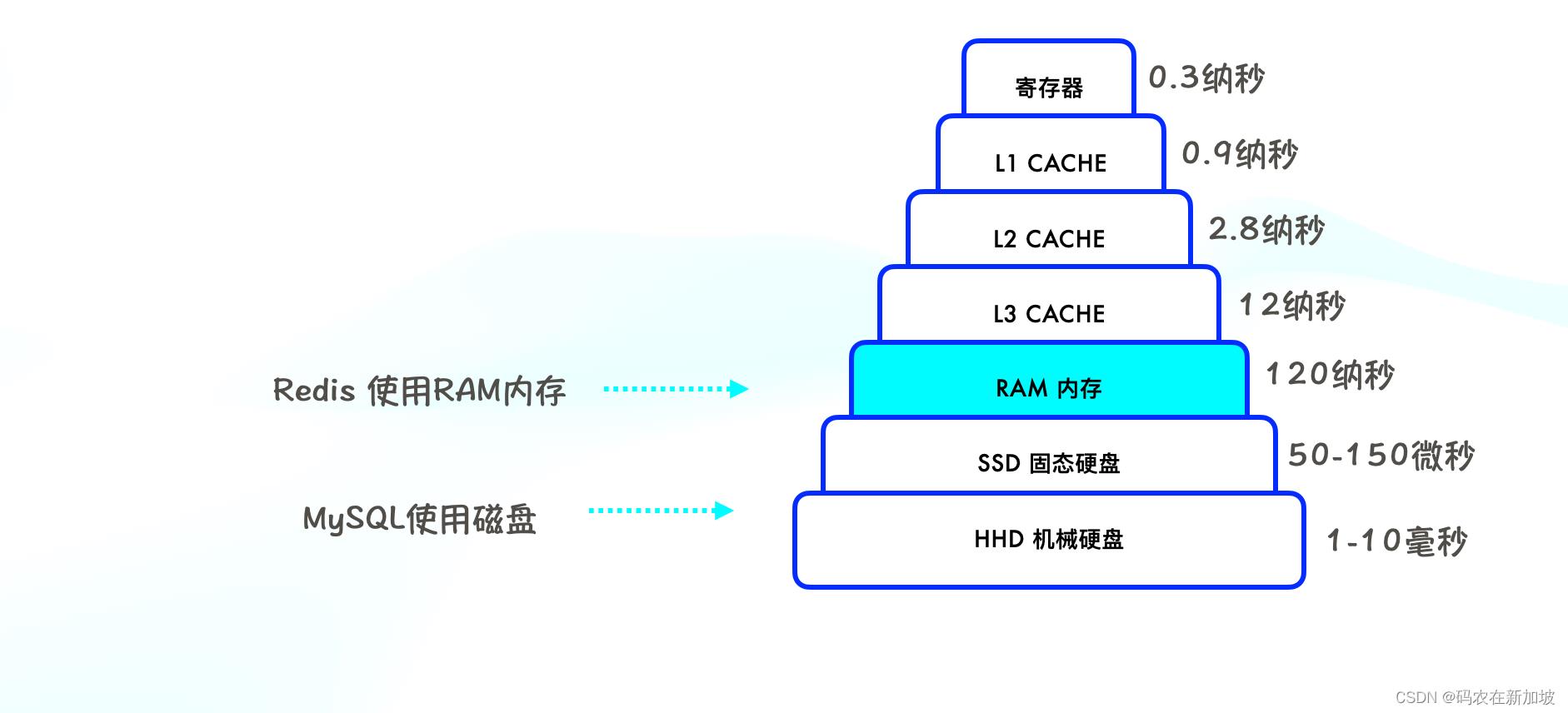
而Redis使用RAM内存储存的数据库。相对于数据存在磁盘的数据库,比如MySQL,就省去磁盘磁盘I/O的消耗。MySQL等磁盘数据库,需要建立索引来加快查询效率。
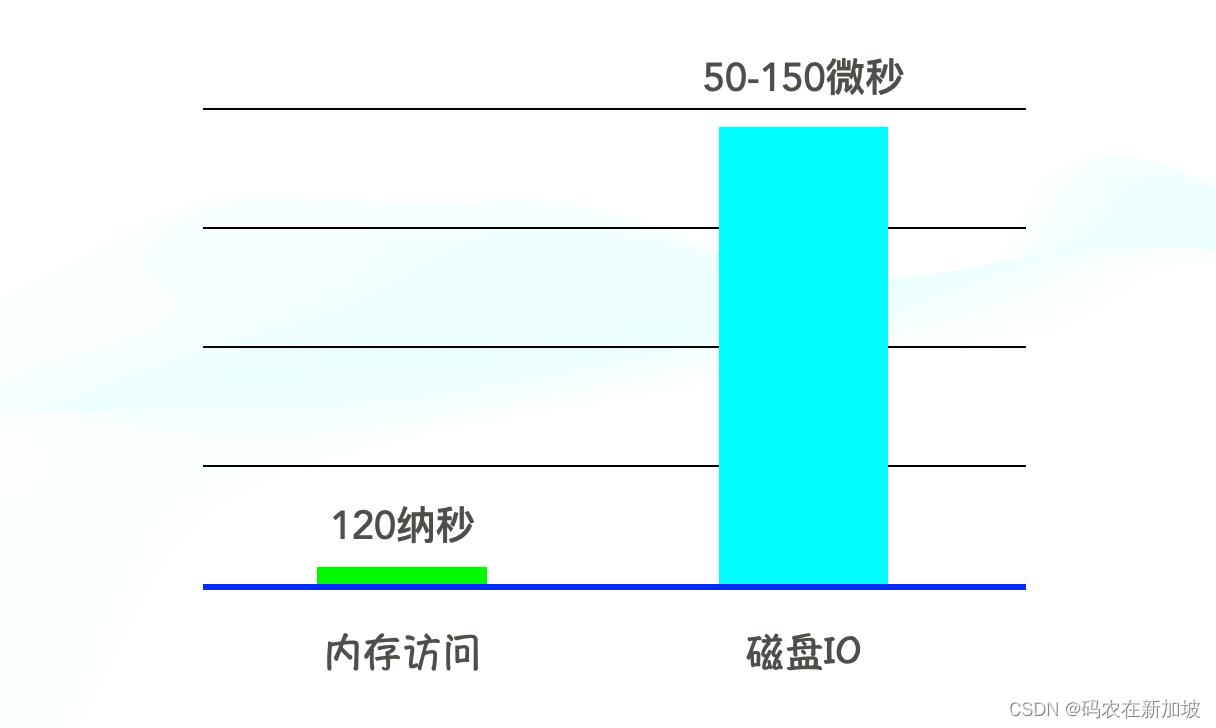
像Redis这样把数据存在内存中,读写都直接对数据库进行操作,天然地就比硬盘数据库少了到磁盘读取数据的这一步,而这一步恰恰是计算机处理I/O的瓶颈所在。
这也就是为什么Redis的QPS能达到100K,而同等配置下的MySQL的单机性能只有~4K的原因。
IO多路复用
什么是I/O多路复用?
IO多路复用其实就是一种同步IO模型,它实现了一个线程可以监视多个文件描述符;一旦某个文件描述符就绪,就能够通知应用程序进行相应的读写操作。
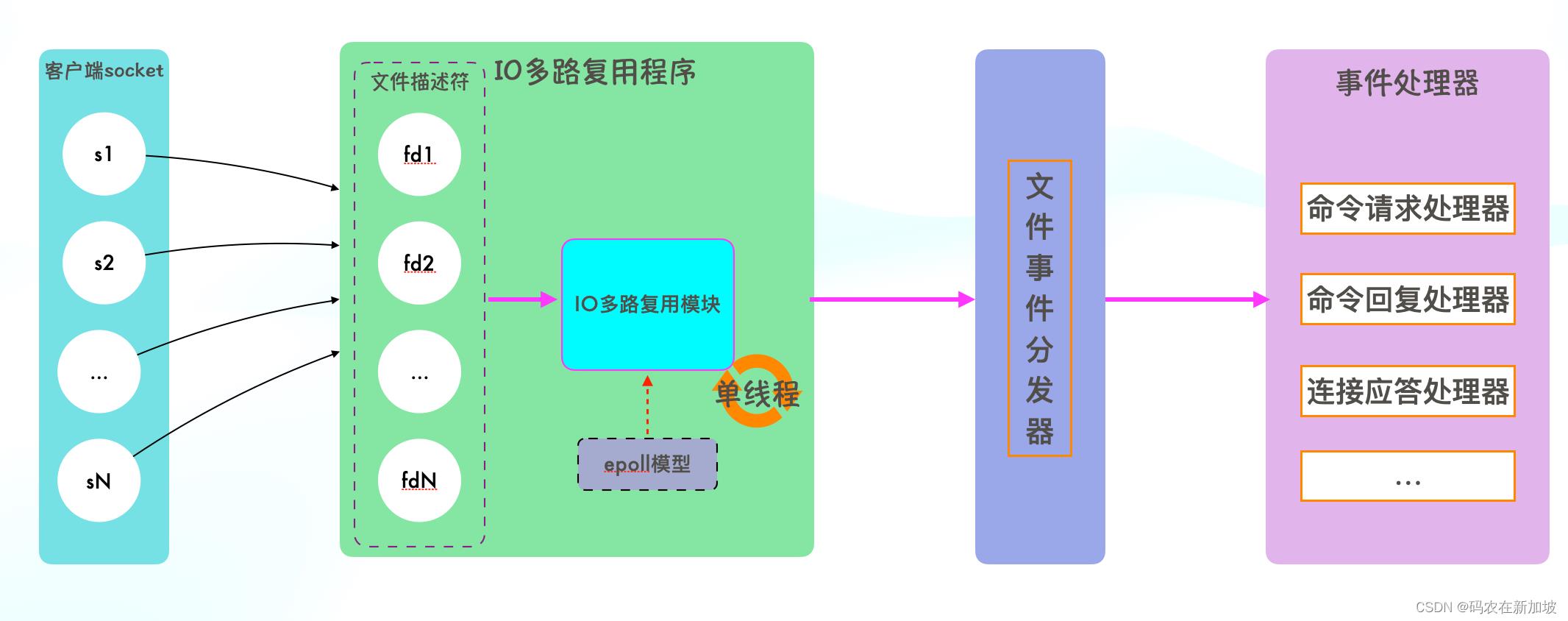
redis的网络事件处理器是基于Reactor模式,又叫做文件事件处理器。
文件事件处理器使用I/O多路复用来同时监听多个套接字,并根据套接字执行的任务关联到不同的事件处理器。
文件事件以单线程方式运行,但通过使用I/O多路复用程序来监听多个套接字,文件事件处理器实现了高性能的网络通信模型。
Redis 在处理客户端的请求时,包括接收(socket读)、解析、执行、发送(socket 写) 等都由一个顺序串行的主线程处理,这就是所谓的单线程。
单线程模型
然后我们讲讲单线程模型。
Redis为什么使用单线程,以及是不是真的单线程呢?
Redis官网说了为什么使用单线程:
It’s not very frequent that CPU becomes your bottleneck with Redis, as usually Redis is either memory or network bound.
一句话解释就是:因为CPU不是Redis的瓶颈,Redis的瓶颈是内存和网络带宽。
线程之间的轮换以及上下文切换是需要花费很多时间的。
单线程模型在这种情况下可以省去上下文切换和加锁的开销。
那Redis是不是单线程呢?
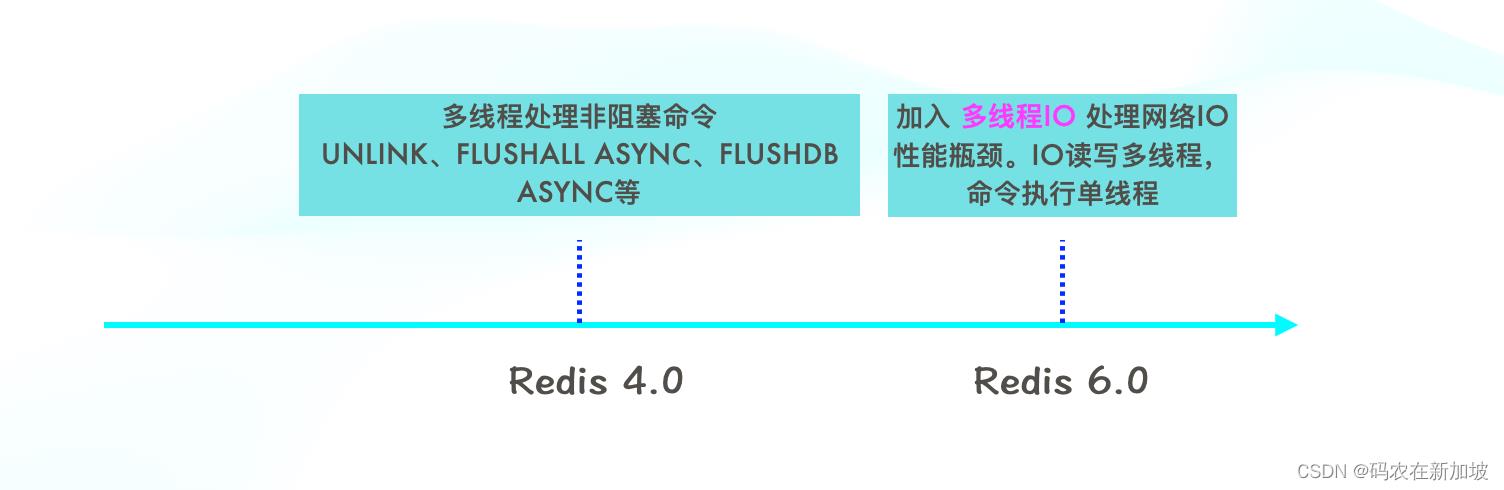
2017年6月,Redis发布Redis 4.0,除了主处理线程,还会有一些线程来处理一些非阻塞命令,
比如 UNLINk,FLUSHALL ASYNC,FLUSHDB ASYNC等非阻塞删除操作。
2020年5月,Redis发布Redis 6.0, 支持多线程IO来接收,发送和解析命令,具体的执行命令仍然是单线程的。
所以Redis主要的命令处理一直都是单线程的。
高效数据结构
上面我们说到的都是硬件层和系统层上Redis的支持或者优化。
下面我们讲讲Redis本身逻辑层面快的原因:它高效的数据结构。
Redis中的数据结构是专门进行设计的;
如果你对Redis有一点点了解,那么你一定能说出来,Redis有5种基本数据结构。
- String (字符串)
- Hash (散列)
- List (列表)
- Set (集合)
- ZSet/Sorted Set (有序集合)
实际上Redis还有几种高级数据结构可能你如果知道会让面试官眼前一亮:
- Geo (地理空间)
- Bitmap (位操作)
- Hyperloglog (基数统计)
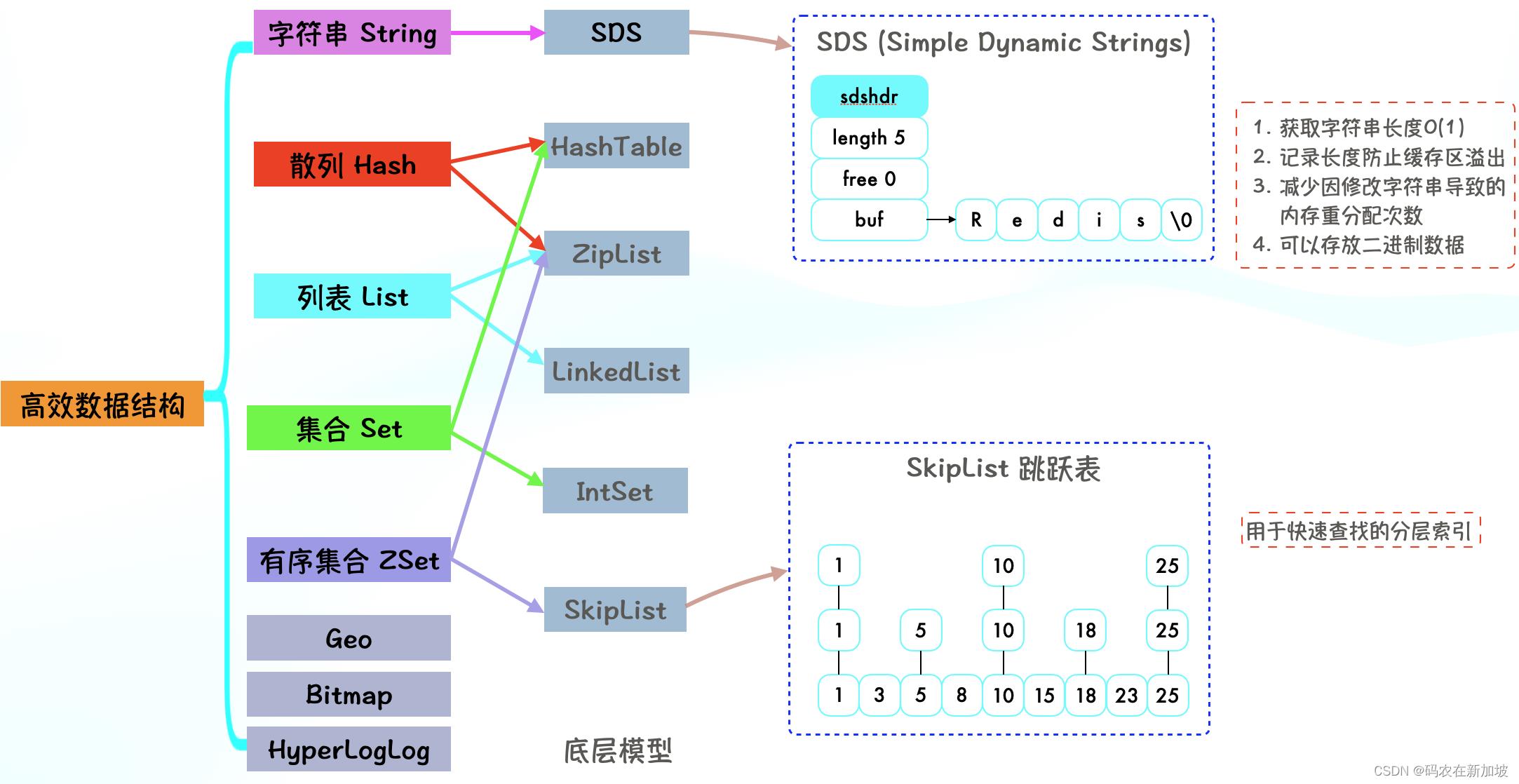
这些数据结构的实现还通常不止一种,会根据你的操作的数据长度或者类型自动切换底层模型。
其中Redis使用了这些底层模型作为数据结构的实现:
- SDS 简单动态字符串
- HashTable
- ZipList
- LinkedList
- IntSet
- SkipList
而每一种数据结构都会使用多种底层结构模型来实现。
由于这些数据结构和底层模型的复杂性,每一个都可以单独制作一篇视频讲解,我这里就简单说一下其中的两种。
SDS
String数据结构使用SDS底层实现,SDS是简单动态字符串。
它有个数据结构名字叫sdshdr,里面有三个属性。
- length: 记录字符串的长度
- free: 记录字符串未使用的空间的长度
- buf,char类型的数组,保存字符,以空字符
\\0结尾。
它相对于C语言字符串有以下好处:
- 获取字符串长度时间复杂度为O(1)
- 记录长度防止缓存区溢出
- 减少因修改字符串导致的内存重分配次数
- 可以存放二进制数据
SkipList
SkipList是有序集合 ZSet的底层实现之一,ZSet是我们做排行榜经常使用的数据结构。
Redis使用了SkipList,用于快速查找的分层索引,方便范围查找。
Redis使用SkipList而不是用平衡树的主要原因有:
- 平衡树不适合范围查找,
- 平衡树的插入和删除引发子树调整,逻辑复杂,SkipList相对简单很多
- 平衡树每个节点包含两个指针,SkipList平均不到2个指针,内存上更有优势。
所以我们可以看到,Redis的每一个设计,都是非常优秀的,充分的利用了硬件,网络,线程和内存。所以Redis才会这么快。
后续
由于篇幅限制,关于Redis数据结构的部分我也只能简单描述下,后续我会花时间和精力来做一整套的Redis教程,带你完善你的Redis技能栈,轻松通过面试,斩获Offer。欢迎关注我获取最新更新吧。
<全文完>
以上是关于Redis为什么这么快 - 秒杀面试官系列的主要内容,如果未能解决你的问题,请参考以下文章