Antlr 初识语法分析器生成工具 Antlr
Posted @SmartSi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Antlr 初识语法分析器生成工具 Antlr相关的知识,希望对你有一定的参考价值。

Antlr 版本:4.9.3
1. Antlr 简介
Antlr 是一款强大的语法分析器生成工具,可用于读取、处理、执行以及翻译结构化的文本或二进制文件。被广泛应用于学术领域和工业生产实践,是众多语言、工具和框架的基石。Twitter 搜索使用 Antlr 进行语法分析,每天处理超过20亿次查询;Hadoop 生态系统中的 Hive、Pig、数据仓库和分析系统所使用的语言都用到了 Antlr;Lex Machina 将 Antlr 用于分析法律文本;Oracle 公司在 SQL 开发者 IDE 和迁移工具中使用了 Antlr;NetBeans 公司的 IDE 使用 Antlr 来解析 C++;Hibernate 对象-关系映射框架(ORM)使用 Antlr 来处理 HQL 语言。
除了这些鼎鼎大名的项目之外,还可以利用 Antlr 构建各种各样的实用工具,如配置文件读取器、遗留代码转换器、维基文本渲染器,以及 JSON 解析器。一门语言的正式描述称为语法(grammar),Antlr 能够为该语言生成一个语法分析器,并自动建立语法分析树,一种描述语法与输入文本匹配关系的数据结构。Antlr 也能够自动生成树的遍历器,这样你就可以访问树中的节点,执行自定义的业务逻辑代码。
2. 安装 Antlr
Antlr 是用 Java 编写的,因此需要首先安装 Java。Antlr 运行所需的 Java 版本为 1.6 或者更高版本。安装 Antlr 前,需要检查自己的 Java 版本,如果低版本的 Java 安装高版本的 Antlr4,使用时会报如下类似的错误:
Exception in thread "main" java.lang.UnsupportedClassVersionError: org/antlr/v4/Tool has been compiled by a more recent version of the Java Runtime (class file version 55.0), this version of the Java Runtime only recognizes class file versions up to 52.0
详细请查阅 Antlr4 xxx has been compiled by a more recent version of the Java Runtime
通过如下命令检查 Java 版本:
localhost:opt wy$ java -version
java version "1.8.0_161"
Java(TM) SE Runtime Environment (build 1.8.0_161-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
可以看到我们安装的 Java 版本为 1.8 版本,所以我们选择 4.9.3 版本的 Antlr(antlr-4.9.3-complete.jar)进行安装。然后把它放在合适的位置即可,在这我们放在 /opt/antlr 目录下。该 jar 包包含了运行 Antlr 的工具以及编译、执行 Antlr 产生识别程序所依赖的全部运行库。简而言之,Antlr 工具将语法文件转换成可以识别该语法文件所描述语言的程序。例如,给定一个识别 JSON 的语法,Antlr 工具将会根据该语法生成一个程序,此程序可以通过 Antlr 运行库来识别输入的 JSON。
如果是通过命令行运行,需要修改 /etc/profile 文件来设置 CLASSPATH 环境变量:
# Antlr
export CLASSPATH=".:/opt/antlr/antlr-4.9.3-complete.jar:$CLASSPATH"
设置好环境变量,Java 就能够找到 Antlr 工具和运行库。
CLASSPATH 中的 ‘.’ 非常关键,代表当前目录。如果没有它,Java 编译器和 Java 虚拟机就无法加载当前目录的 class 文件。
有几种方式可以检查 Antlr 的安装是否正确,第一种是通过不带参数的 Antlr 命令行工具,第二种是通过 java -jar 来直接运行 Antlr 的 jar 包,第三种是直接调用 org.antlr.v4.Tool 类:
// 使用 java -jar
localhost:opt wy$ java -jar /opt/antlr/antlr-4.9.3-complete.jar
ANTLR Parser Generator Version 4.9.3
-o ___ specify output directory where all output is generated
-lib ___ specify location of grammars, tokens files
-atn generate rule augmented transition network diagrams
-encoding ___ specify grammar file encoding; e.g., euc-jp
...
// 直接调用 org.antlr.v4.Tool
localhost:opt wy$ java org.antlr.v4.Tool
ANTLR Parser Generator Version 4.9.3
-o ___ specify output directory where all output is generated
-lib ___ specify location of grammars, tokens files
-atn generate rule augmented transition network diagrams
-encoding ___ specify grammar file encoding; e.g., euc-jp
...
如果出现上述信息,表示你的 Antlr 已经安装成功了。
如果每次都手动输入这些 java 命令是一件令人痛苦的事情,所以最好通过别名(alias)或者 shell 脚本的方式来运行。在这我们通过别名的方法来运行:
alias antlr4='java -jar /opt/antlr/antlr-4.9.3-complete.jar'
现在我们可以直接运行 antlr4 命令了:
localhost:opt wy$ antlr4
ANTLR Parser Generator Version 4.9.3
-o ___ specify output directory where all output is generated
-lib ___ specify location of grammars, tokens files
-atn generate rule augmented transition network diagrams
-encoding ___ specify grammar file encoding; e.g., euc-j
3. 实战
3.1 定义语法文件
首先我们需要定义一个 Helo.g4 的语法文件,语法规则如下所示:
grammar Hello; // 定义一个名为 Hello 的语法
r : 'hello' ID; // 定义一个语法规则:匹配一个关键词 hello 和一个紧随其后的标识符
ID : [a-z]+; // 匹配小写字母组成的标识符
WS: [ \\t\\r\\n]+ -> skip; // 忽略空格、Tab、换行以及\\r
注意的是 .g4 的文件名称必须与语法的名称保持一致,否则会抛出类似如下的异常:
error(8): hello.g4:1:8: grammar name Hello and file name hello.g4 differ
3.2 生成程序
接下来对 Hello.g4 语法文件运行 Antlr4 命令,编译生成了很多以 Hello 开头的文件:
localhost:Hello wy$ antlr4 Hello.g4
localhost:Hello wy$ ll
total 6928
drwxr-xr-x 13 wy staff 442 12 30 20:22 ./
drwxrwxrwx 56 667 staff 1904 12 30 10:31 ../
-rw-r--r-- 1 wy staff 250 12 30 20:22 Hello.g4
-rw-r--r-- 1 wy staff 308 12 30 20:22 Hello.interp
-rw-r--r-- 1 wy staff 27 12 30 20:22 Hello.tokens
-rw-r--r-- 1 wy staff 1304 12 30 20:22 HelloBaseListener.java
-rw-r--r-- 1 wy staff 1055 12 30 20:22 HelloLexer.interp
-rw-r--r-- 1 wy staff 3562 12 30 20:22 HelloLexer.java
-rw-r--r-- 1 wy staff 27 12 30 20:22 HelloLexer.tokens
-rw-r--r-- 1 wy staff 536 12 30 20:22 HelloListener.java
-rw-r--r-- 1 wy staff 3854 12 30 20:22 HelloParser.java
-rw-r--r--@ 1 wy staff 3508089 12 30 11:11 antlr-4.9.3-complete.jar
antlr4 是
java -jar /opt/antlr/antlr-4.9.3-complete.jar命令的别名
通过在语法文件上运行 Antlr4 命令来生成 Java 源文件,除此之外还需要运行 javac *.java 来编译 Antlr 生成的 Java 代码:
localhost:Hello wy$ javac *.java
localhost:Hello wy$ ll
total 6976
drwxr-xr-x 18 wy staff 612 12 30 20:23 ./
drwxrwxrwx 56 667 staff 1904 12 30 10:31 ../
-rw-r--r-- 1 wy staff 250 12 30 20:22 Hello.g4
-rw-r--r-- 1 wy staff 308 12 30 20:22 Hello.interp
-rw-r--r-- 1 wy staff 27 12 30 20:22 Hello.tokens
-rw-r--r-- 1 wy staff 794 12 30 20:23 HelloBaseListener.class
-rw-r--r-- 1 wy staff 1304 12 30 20:22 HelloBaseListener.java
-rw-r--r-- 1 wy staff 3722 12 30 20:23 HelloLexer.class
-rw-r--r-- 1 wy staff 1055 12 30 20:22 HelloLexer.interp
-rw-r--r-- 1 wy staff 3562 12 30 20:22 HelloLexer.java
-rw-r--r-- 1 wy staff 27 12 30 20:22 HelloLexer.tokens
-rw-r--r-- 1 wy staff 304 12 30 20:23 HelloListener.class
-rw-r--r-- 1 wy staff 536 12 30 20:22 HelloListener.java
-rw-r--r-- 1 wy staff 869 12 30 20:23 HelloParser$RContext.class
-rw-r--r-- 1 wy staff 4377 12 30 20:23 HelloParser.class
-rw-r--r-- 1 wy staff 3854 12 30 20:22 HelloParser.java
-rw-r--r--@ 1 wy staff 3508089 12 30 11:11 antlr-4.9.3-complete.jar
或者使用
javac -cp /opt/antlr/antlr-4.9.3-complete.jar *.java命令运行
3.3 运行
对 Hello.g4 运行 Antlr 工具命令生成了一个由 HelloParser.java 和 HelloLexer.java 组成的、可以运行的语法识别程序,不过我们还缺一个 main 程序来触发这个语言识别过程。Antlr 在运行库中提供了一个名为 TestRig 调试工具。它可以详细列出一个语言类应用程序在匹配输入文本过程中的信息,这些输入文本可以来自文件或者标准输入。TestRig 使用 Java 的反射机制来调用编译后的识别程序。org.antlr.v4.runtime.misc 包下的 TestRig 已经标记为 @Deprecated,现在已经转移至 org.antlr.v4.gui 包下。跟定义 antlr4 别名类似,我们也为 org.antlr.v4.gui.TestRig 命令的运行定义一个别名:
alias antlr4-test='java org.antlr.v4.gui.TestRig'
TestRig 有点像是 main 方法,接收一个语法名和一个起始规则名作为参数,此外,还接收其他参数,通过这些参数我们可以指定输出的内容。假设我们希望展示识别过程中生成的词法符号。可以通过 antlr4-test 命令来测试 Hello 语法:
localhost:Hello wy$ antlr4-test Hello r -tokens
hello world
[@0,0:4='hello',<'hello'>,1:0]
[@1,6:10='world',<ID>,1:6]
[@2,12:11='<EOF>',<EOF>,2:0]
首先输入上述 antlr4-test Hello r -tokens 命令,回车,然后输入 hello world,回车。这个时候,你必须手动输入文件结束符 ctrl+d (UNIX 系统)来阻止程序继续读取标准输入,否则程序将什么都不做,静静等待你的下一步输入。由于 antlr4-test 命令使用了 -tokens 选项,一旦识别程序读取到全部的输入内容,TestRig 就会打印出全部的词法符号的列表。每行输出代表了一个词法符号,其中包含了该词法符号的全部信息。例如,[@1,6:10='world',<ID>,1:6] 表明,这个词法符号位于第二个位置(从 0 开始计数),由输入文本的第 6 个到第 10 个位置之间的字符组成(包含第6个和第10个,同样从 0 开始计数);包含的文本内容是 world;词法符号类型是 ID;位于输入文本的第一行、第6个位置处。
我们还可以通过如下命令可视化的树形结构展示语法分析树:
localhost:Hello wy$ antlr4-test Hello r -gui
hello world
^D
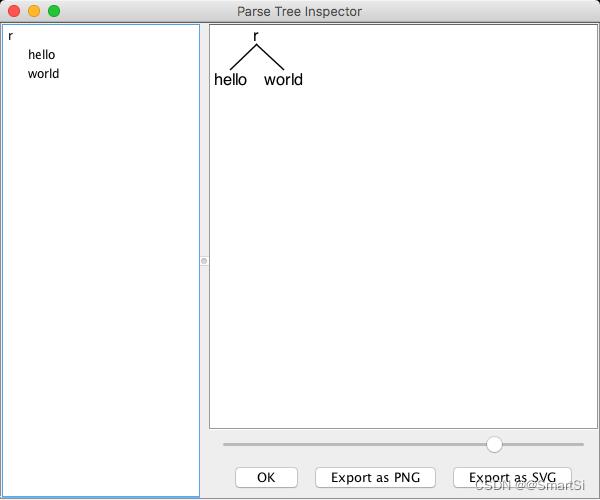
- 参考:《Antlr4 权威指南》
以上是关于Antlr 初识语法分析器生成工具 Antlr的主要内容,如果未能解决你的问题,请参考以下文章
Hive 源码解读 Driver 将 HQL 语句转换为 AST
Hive 源码解读 Driver 将 HQL 语句转换为 AST