python深度学习之基于LSTM时间序列的股票价格预测
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python深度学习之基于LSTM时间序列的股票价格预测相关的知识,希望对你有一定的参考价值。
1.本文是一篇LSTM处理时间序列的案例
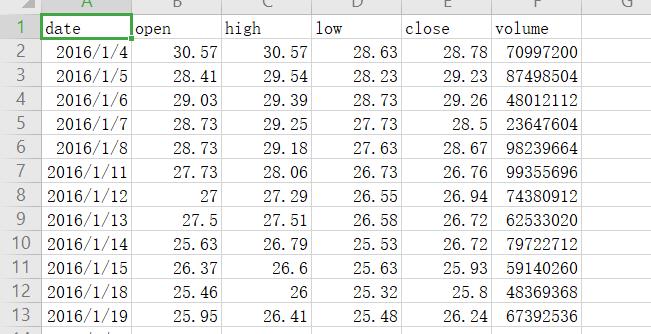
我们先来看看数据集,这里包含了一只股票的开盘价,最高价,最低价,收盘价,交易量的信息。
本文基于LSTM对收盘价(close)进行预测
2. 单维对单步的预测
我们这是用前n天的数据预测第n+1天的数据。
单维单步的蛤含义如下图,利用2天的数据预测第三天的数据。
trainX的形状为(5,2),trainY的形状为(5,1)

3.导入所需要的数据
#关于lstm对时间序列数据的预测
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
from tensorflow.keras import layers,Input,optimizers
#导入数据
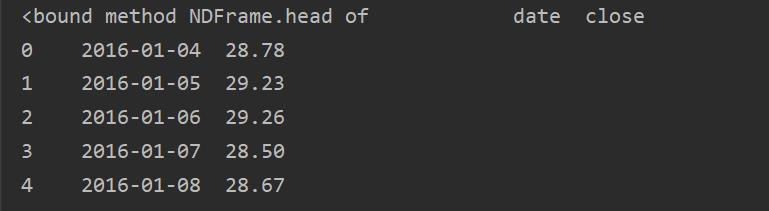
data=pd.read_csv(r'C:\\Users\\Administrator\\Desktop\\lstm_data\\zgpa_train.csv')#读取csv文件
df=pd.DataFrame(data,columns=['date','close'])#只取日期和收盘价两列
print(df.head)
数据如下:
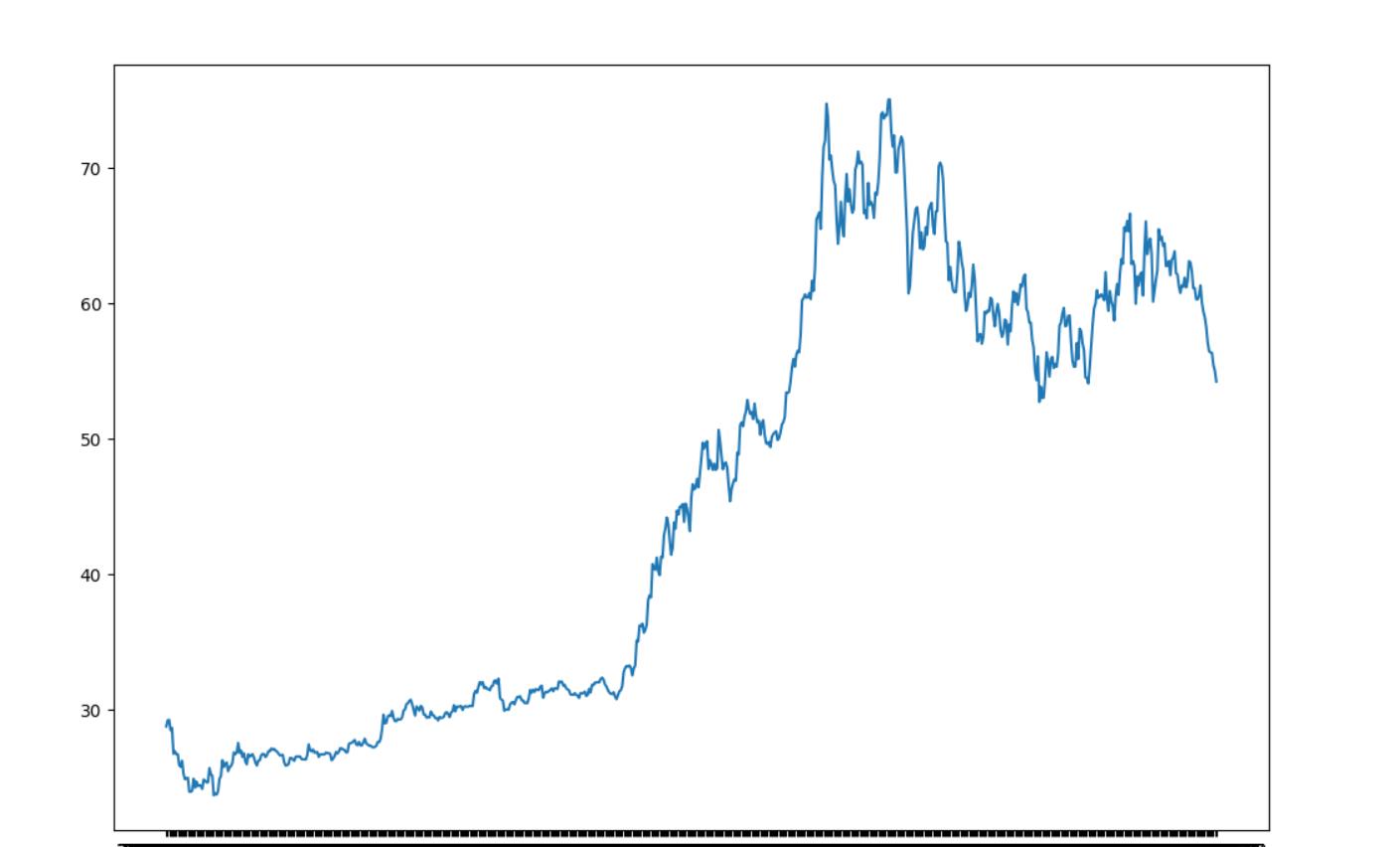
图像如下:
4.数据标准化
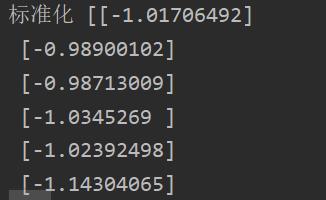
这里我们采用标准化。这里会是一个二维的数组。
st=StandardScaler()
dataset_st=st.fit_transform(dataset.reshape(-1,1))
print("标准化",dataset_st)
生成数据如下:
5.创建时间序列的函数
lookback的含义是指你用前几天的数据来预测下一天的数据,例如lookback=2,则是用前2天的数据来预测第三天的数据。
def data_set(dataset,lookback):#创建时间序列数据样本
dataX,dataY=[],[]#初始化训练集和测试集的列表
for i in range(len(dataset)-lookback-1):
a=dataset[i:(i+lookback)]
dataX.append(a)
dataY.append(dataset[i+lookback])
return np.array(dataX),np.array(dataY)#转化为数组输出
6.划分测试集和测试集
\\#划分训练集和测试集
train_size=int(len(dataset_st)*0.7)#百分之70训练集
test_size=len(dataset_st)-train_size#剩下的30的训练集
train,test=dataset_st[0:train_size],dataset_st[train_size:len(dataset_st)]#根据数量划分数据集
print(len(train))
print(len(test))
7.调用函数将数据集生成时间序列数据集
这里你可以设置lookback的大小1,2,3…
#根据划分的训练集测试集生成需要的时间序列样本数据
lookback=1
trainX,trainY=data_set(train,lookback)
testX,testY=data_set(test,lookback)
print('trianX:',trainX.shape,trainY.shape)
print(trainX)
8.建立LSTM的模型
这里我需要说明一下,我这里采用的是函数式构造流程,采用了2层lstm,1层全连接,1层dropout,最后连接了1层全连接预测。
LSTM的输入应该是 [samples, timesteps, features],我们采用Input函数最为数据输入的第一层,该函数将样本数据的维度作为大小,比如数据为(509,1,1)这里指含有509个样本数据,大小为1x1维,则input输入的参数即为1,1
#构建lstm模型,这里其实有个bug,可能是由于numpy的问题,这里的trainX是三维的(509,1,1),input不需要将样本数量输入,只需输入样本的维度(1,1)
input_shape=Input(shape=(trainX.shape[1],trainX.shape[2]))
lstm1=layers.LSTM(32,return_sequences=1)(input_shape)
print("lstm1:",lstm1.shape)
lstm2=layers.LSTM(64,return_sequences=0)(lstm1)
print("lstm2:",lstm2.shape)
dense1=layers.Dense(64,activation="relu")(lstm2)
print("dense:",dense1.shape)
dropout=layers.Dropout(rate=0.2)(dense1)
print("dropout:",dropout.shape)
ouput_shape=layers.Dense(1,activation="relu")(dropout)
lstm_model=tf.keras.Model(input_shape,ouput_shape)
lstm_model.compile(loss="mean_squared_error",optimizer="Adam",metrics=["mse"])#mse作为l损失函数,采用Adam作为寻优方式
history=lstm_model.fit(trainX,trainY,batch_size=32,epochs=10,validation_split=0.1,verbose=1)
lstm_model.summary()
9.做出预测,并进行反归一化,画出图像。
#预测测试集
predict_trainY=lstm_model.predict(trainX)
predict_testY=lstm_model.predict(testX)
#反标准化
#trainY=st.inverse_transform(predict_trainY)
testY_real=st.inverse_transform(testY)
testY_predict=st.inverse_transform(predict_testY)
#看一看数据形状
print("Y:",testY_predict,testY_predict.shape)
print("Y_real:",testY_real,testY_real.shape)
plt.figure(figsize=(12,8))
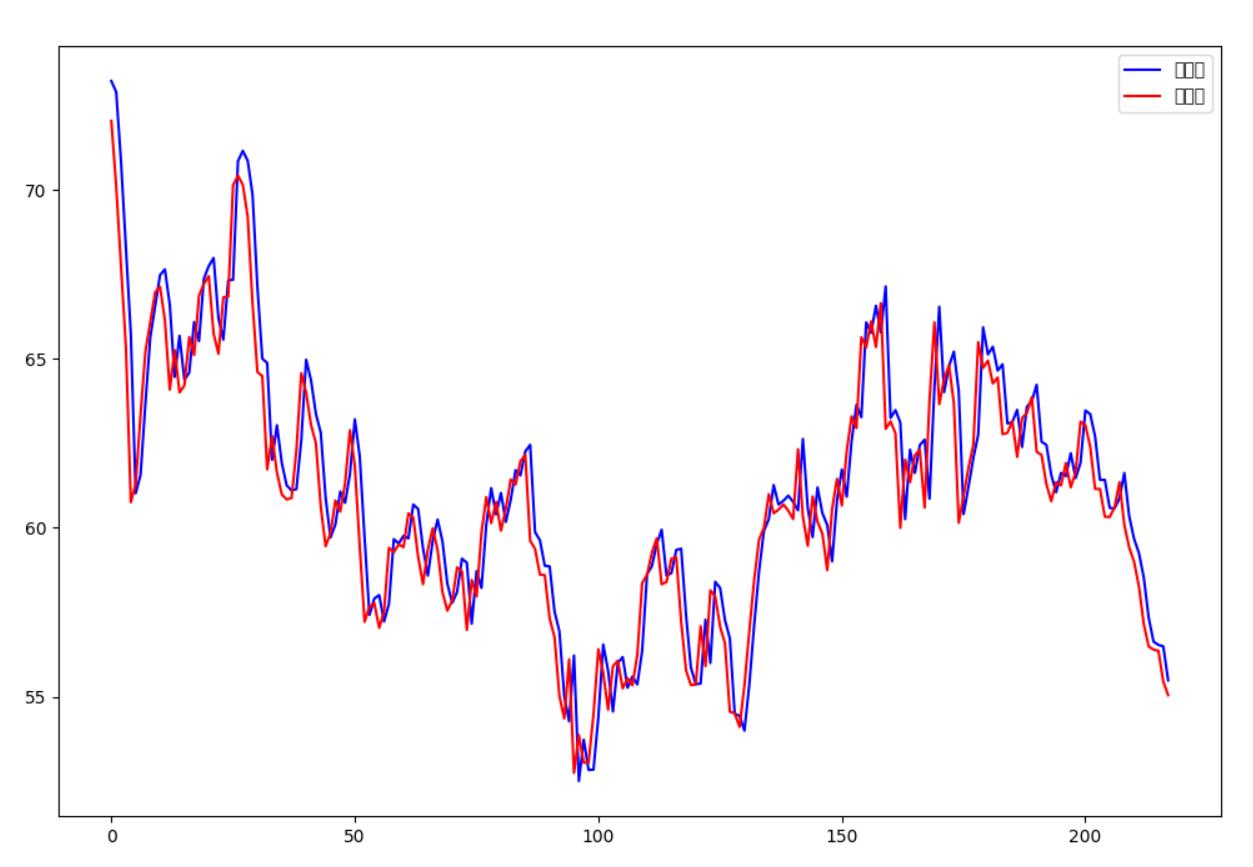
plt.plot(testY_predict,"b",label="预测值")
plt.plot(testY_real,"r",label="真实值")
plt.legend()
plt.show()
结果如下:其实会有一个问题,即预测滞后问题,可能是由于数据稳定性不够,后面做实验应该参考一些论文的解决方法。
更新于2022年02月18日:有很多同学反应一段一段看不懂,这里我就附上全部代码.
#关于lstm对时间序列数据的预测
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
from tensorflow.keras import layers,Input,optimizers
#导入数据
pd.set_option('display.unicode.east_asian_width',True)
data=pd.read_csv(r'C:\\Users\\Administrator\\Desktop\\lstm_data\\zgpa_train.csv')
df=pd.DataFrame(data,columns=['date','close'])
print(df.head)
#单维单步(用前(1,2,3,......)步预测后1步)
#创建数据集
dataset=df["close"].values
print(type(dataset))
# lookback=1
# print(len(dataset))
def data_set(dataset,lookback):#创建时间序列数据样本
dataX,dataY=[],[]
for i in range(len(dataset)-lookback-1):
a=dataset[i:(i+lookback)]
dataX.append(a)
dataY.append(dataset[i+lookback])
return np.array(dataX),np.array(dataY)
plt.figure(figsize=(12, 8))
x=df["date"]
y=df["close"]
plt.plot(x,y)
plt.show()
st = StandardScaler()
dataset_st = st.fit_transform(dataset.reshape(-1, 1))
print("标准化", dataset_st)
#数据标准化
#划分训练集和测试集
train_size=int(len(dataset_st)*0.7)
test_size=len(dataset_st)-train_size
train,test=dataset_st[0:train_size],dataset_st[train_size:len(dataset_st)]
print(len(train))
print(len(test))
#根据划分的训练集测试集生成需要的时间序列样本数据
lookback=1
trainX,trainY=data_set(train,lookback)
testX,testY=data_set(test,lookback)
print('trianX:',trainX.shape,trainY.shape)
print(trainX)
#构建lstm模型
input_shape=Input(shape=(trainX.shape[1],trainX.shape[2]))
lstm1=layers.LSTM(32,return_sequences=1)(input_shape)
print("lstm1:",lstm1.shape)
lstm2=layers.LSTM(64,return_sequences=0)(lstm1)
print("lstm2:",lstm2.shape)
dense1=layers.Dense(64,activation="relu")(lstm2)
print("dense:",dense1.shape)
dropout=layers.Dropout(rate=0.2)(dense1)
print("dropout:",dropout.shape)
ouput_shape=layers.Dense(1,activation="relu")(dropout)
lstm_model=tf.keras.Model(input_shape,ouput_shape)
lstm_model.compile(loss="mean_squared_error",optimizer="Adam",metrics=["mse"])
history=lstm_model.fit(trainX,trainY,batch_size=16,epochs=10,validation_split=0.1,verbose=1)
lstm_model.summary()
#预测测试集
predict_trainY=lstm_model.predict(trainX)
predict_testY=lstm_model.predict(testX)
#反标准化
#trainY=st.inverse_transform(predict_trainY)
testY_real=st.inverse_transform(testY)
testY_predict=st.inverse_transform(predict_testY)
print("Y:",testY_predict,testY_predict.shape)
print("Y222:",testY_real,testY_real.shape)
plt.figure(figsize=(12,8))
plt.plot(testY_predict,"b",label="预测值")
plt.plot(testY_real,"r",label="真实值")
plt.legend()
plt.show()
以上是关于python深度学习之基于LSTM时间序列的股票价格预测的主要内容,如果未能解决你的问题,请参考以下文章